 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MaSkel: A Model for Human Whole-body X-rays Generation from Human Masking Images
Apr 13, 2024
The human whole-body X-rays could offer a valuable reference for various applications, including medical diagnostics, digital animation modeling, and ergonomic design. The traditional method of obtaining X-ray information requires the use of CT (Computed Tomography) scan machines, which emit potentially harmful radiation. Thus it faces a significant limitation for realistic applications because it lacks adaptability and safety. In our work, We proposed a new method to directly generate the 2D human whole-body X-rays from the human masking images. The predicted images will be similar to the real ones with the same image style and anatomic structure. We employed a data-driven strategy. By leveraging advanced generative techniques, our model MaSkel(Masking image to Skeleton X-rays) could generate a high-quality X-ray image from a human masking image without the need for invasive and harmful radiation exposure, which not only provides a new path to generate highly anatomic and customized data but also reduces health risks. To our knowledge, our model MaSkel is the first work for predicting whole-body X-rays. In this paper, we did two parts of the work. The first one is to solve the data limitation problem, the diffusion-based techniques are utilized to make a data augmentation, which provides two synthetic datasets for preliminary pretraining. Then we designed a two-stage training strategy to train MaSkel. At last, we make qualitative and quantitative evaluations of the generated X-rays. In addition, we invite some professional doctors to assess our predicted data. These evaluations demonstrate the MaSkel's superior ability to generate anatomic X-rays from human masking images. The related code and links of the dataset are available at https://github.com/2022yingjie/MaSkel.
MedCLIP-SAM: Bridging Text and Image Towards Universal Medical Image Segmentation
Mar 29, 2024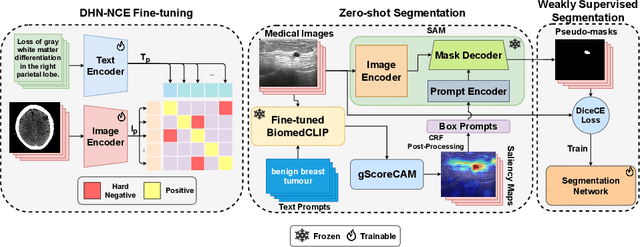
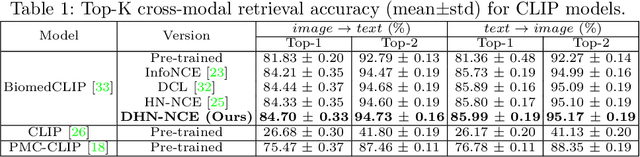
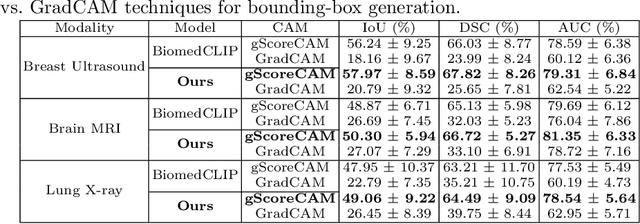

Medical image segmentation of anatomical structures and pathology is crucial in modern clinical diagnosis, disease study, and treatment planning. To date, great progress has been made in deep learning-based segmentation techniques, but most methods still lack data efficiency, generalizability, and interactability. Consequently, the development of new, precise segmentation methods that demand fewer labeled datasets is of utmost importance in medical image analysis. Recently, the emergence of foundation models, such as CLIP and Segment-Anything-Model (SAM), with comprehensive cross-domain representation opened the door for interactive and universal image segmentation. However, exploration of these models for data-efficient medical image segmentation is still limited, but is highly necessary. In this paper, we propose a novel framework, called MedCLIP-SAM that combines CLIP and SAM models to generate segmentation of clinical scans using text prompts in both zero-shot and weakly supervised settings. To achieve this, we employed a new Decoupled Hard Negative Noise Contrastive Estimation (DHN-NCE) loss to fine-tune the BiomedCLIP model and the recent gScoreCAM to generate prompts to obtain segmentation masks from SAM in a zero-shot setting. Additionally, we explored the use of zero-shot segmentation labels in a weakly supervised paradigm to improve the segmentation quality further. By extensively testing three diverse segmentation tasks and medical image modalities (breast tumor ultrasound, brain tumor MRI, and lung X-ray), our proposed framework has demonstrated excellent accuracy.
Mixture of Low-rank Experts for Transferable AI-Generated Image Detection
Apr 07, 2024Generative models have shown a giant leap in synthesizing photo-realistic images with minimal expertise, sparking concerns about the authenticity of online information. This study aims to develop a universal AI-generated image detector capable of identifying images from diverse sources. Existing methods struggle to generalize across unseen generative models when provided with limited sample sources. Inspired by the zero-shot transferability of pre-trained vision-language models, we seek to harness the nontrivial visual-world knowledge and descriptive proficiency of CLIP-ViT to generalize over unknown domains. This paper presents a novel parameter-efficient fine-tuning approach, mixture of low-rank experts, to fully exploit CLIP-ViT's potential while preserving knowledge and expanding capacity for transferable detection. We adapt only the MLP layers of deeper ViT blocks via an integration of shared and separate LoRAs within an MoE-based structure. Extensive experiments on public benchmarks show that our method achieves superiority over state-of-the-art approaches in cross-generator generalization and robustness to perturbations. Remarkably, our best-performing ViT-L/14 variant requires training only 0.08% of its parameters to surpass the leading baseline by +3.64% mAP and +12.72% avg.Acc across unseen diffusion and autoregressive models. This even outperforms the baseline with just 0.28% of the training data. Our code and pre-trained models will be available at https://github.com/zhliuworks/CLIPMoLE.
CosmicMan: A Text-to-Image Foundation Model for Humans
Apr 01, 2024We present CosmicMan, a text-to-image foundation model specialized for generating high-fidelity human images. Unlike current general-purpose foundation models that are stuck in the dilemma of inferior quality and text-image misalignment for humans, CosmicMan enables generating photo-realistic human images with meticulous appearance, reasonable structure, and precise text-image alignment with detailed dense descriptions. At the heart of CosmicMan's success are the new reflections and perspectives on data and models: (1) We found that data quality and a scalable data production flow are essential for the final results from trained models. Hence, we propose a new data production paradigm, Annotate Anyone, which serves as a perpetual data flywheel to produce high-quality data with accurate yet cost-effective annotations over time. Based on this, we constructed a large-scale dataset, CosmicMan-HQ 1.0, with 6 Million high-quality real-world human images in a mean resolution of 1488x1255, and attached with precise text annotations deriving from 115 Million attributes in diverse granularities. (2) We argue that a text-to-image foundation model specialized for humans must be pragmatic -- easy to integrate into down-streaming tasks while effective in producing high-quality human images. Hence, we propose to model the relationship between dense text descriptions and image pixels in a decomposed manner, and present Decomposed-Attention-Refocusing (Daring) training framework. It seamlessly decomposes the cross-attention features in existing text-to-image diffusion model, and enforces attention refocusing without adding extra modules. Through Daring, we show that explicitly discretizing continuous text space into several basic groups that align with human body structure is the key to tackling the misalignment problem in a breeze.
DI-Retinex: Digital-Imaging Retinex Theory for Low-Light Image Enhancement
Apr 04, 2024Many existing methods for low-light image enhancement (LLIE) based on Retinex theory ignore important factors that affect the validity of this theory in digital imaging, such as noise, quantization error, non-linearity, and dynamic range overflow. In this paper, we propose a new expression called Digital-Imaging Retinex theory (DI-Retinex) through theoretical and experimental analysis of Retinex theory in digital imaging. Our new expression includes an offset term in the enhancement model, which allows for pixel-wise brightness contrast adjustment with a non-linear mapping function. In addition, to solve the lowlight enhancement problem in an unsupervised manner, we propose an image-adaptive masked reverse degradation loss in Gamma space. We also design a variance suppression loss for regulating the additional offset term. Extensive experiments show that our proposed method outperforms all existing unsupervised methods in terms of visual quality, model size, and speed. Our algorithm can also assist downstream face detectors in low-light, as it shows the most performance gain after the low-light enhancement compared to other methods.
Tree Bandits for Generative Bayes
Apr 16, 2024In generative models with obscured likelihood, Approximate Bayesian Computation (ABC) is often the tool of last resort for inference. However, ABC demands many prior parameter trials to keep only a small fraction that passes an acceptance test. To accelerate ABC rejection sampling, this paper develops a self-aware framework that learns from past trials and errors. We apply recursive partitioning classifiers on the ABC lookup table to sequentially refine high-likelihood regions into boxes. Each box is regarded as an arm in a binary bandit problem treating ABC acceptance as a reward. Each arm has a proclivity for being chosen for the next ABC evaluation, depending on the prior distribution and past rejections. The method places more splits in those areas where the likelihood resides, shying away from low-probability regions destined for ABC rejections. We provide two versions: (1) ABC-Tree for posterior sampling, and (2) ABC-MAP for maximum a posteriori estimation. We demonstrate accurate ABC approximability at much lower simulation cost. We justify the use of our tree-based bandit algorithms with nearly optimal regret bounds. Finally, we successfully apply our approach to the problem of masked image classification using deep generative models.
How Deep Networks Learn Sparse and Hierarchical Data: the Sparse Random Hierarchy Model
Apr 16, 2024Understanding what makes high-dimensional data learnable is a fundamental question in machine learning. On the one hand, it is believed that the success of deep learning lies in its ability to build a hierarchy of representations that become increasingly more abstract with depth, going from simple features like edges to more complex concepts. On the other hand, learning to be insensitive to invariances of the task, such as smooth transformations for image datasets, has been argued to be important for deep networks and it strongly correlates with their performance. In this work, we aim to explain this correlation and unify these two viewpoints. We show that by introducing sparsity to generative hierarchical models of data, the task acquires insensitivity to spatial transformations that are discrete versions of smooth transformations. In particular, we introduce the Sparse Random Hierarchy Model (SRHM), where we observe and rationalize that a hierarchical representation mirroring the hierarchical model is learnt precisely when such insensitivity is learnt, thereby explaining the strong correlation between the latter and performance. Moreover, we quantify how the sample complexity of CNNs learning the SRHM depends on both the sparsity and hierarchical structure of the task.
Scaling (Down) CLIP: A Comprehensive Analysis of Data, Architecture, and Training Strategies
Apr 16, 2024This paper investigates the performance of the Contrastive Language-Image Pre-training (CLIP) when scaled down to limited computation budgets. We explore CLIP along three dimensions: data, architecture, and training strategies. With regards to data, we demonstrate the significance of high-quality training data and show that a smaller dataset of high-quality data can outperform a larger dataset with lower quality. We also examine how model performance varies with different dataset sizes, suggesting that smaller ViT models are better suited for smaller datasets, while larger models perform better on larger datasets with fixed compute. Additionally, we provide guidance on when to choose a CNN-based architecture or a ViT-based architecture for CLIP training. We compare four CLIP training strategies - SLIP, FLIP, CLIP, and CLIP+Data Augmentation - and show that the choice of training strategy depends on the available compute resource. Our analysis reveals that CLIP+Data Augmentation can achieve comparable performance to CLIP using only half of the training data. This work provides practical insights into how to effectively train and deploy CLIP models, making them more accessible and affordable for practical use in various applications.
InitNO: Boosting Text-to-Image Diffusion Models via Initial Noise Optimization
Apr 06, 2024Recent strides in the development of diffusion models, exemplified by advancements such as Stable Diffusion, have underscored their remarkable prowess in generating visually compelling images. However, the imperative of achieving a seamless alignment between the generated image and the provided prompt persists as a formidable challenge. This paper traces the root of these difficulties to invalid initial noise, and proposes a solution in the form of Initial Noise Optimization (InitNO), a paradigm that refines this noise. Considering text prompts, not all random noises are effective in synthesizing semantically-faithful images. We design the cross-attention response score and the self-attention conflict score to evaluate the initial noise, bifurcating the initial latent space into valid and invalid sectors. A strategically crafted noise optimization pipeline is developed to guide the initial noise towards valid regions. Our method, validated through rigorous experimentation, shows a commendable proficiency in generating images in strict accordance with text prompts. Our code is available at https://github.com/xiefan-guo/initno.
Pseudo-label Learning with Calibrated Confidence Using an Energy-based Model
Apr 15, 2024In pseudo-labeling (PL), which is a type of semi-supervised learning, pseudo-labels are assigned based on the confidence scores provided by the classifier; therefore, accurate confidence is important for successful PL. In this study, we propose a PL algorithm based on an energy-based model (EBM), which is referred to as the energy-based PL (EBPL). In EBPL, a neural network-based classifier and an EBM are jointly trained by sharing their feature extraction parts. This approach enables the model to learn both the class decision boundary and input data distribution, enhancing confidence calibration during network training. The experimental results demonstrate that EBPL outperforms the existing PL method in semi-supervised image classification tasks, with superior confidence calibration error and recognition accuracy.