 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePMG: Progressive Motion Generation via Sparse Anchor Postures Curriculum Learning
Apr 23, 2025In computer animation, game design, and human-computer interaction, synthesizing human motion that aligns with user intent remains a significant challenge. Existing methods have notable limitations: textual approaches offer high-level semantic guidance but struggle to describe complex actions accurately; trajectory-based techniques provide intuitive global motion direction yet often fall short in generating precise or customized character movements; and anchor poses-guided methods are typically confined to synthesize only simple motion patterns. To generate more controllable and precise human motions, we propose \textbf{ProMoGen (Progressive Motion Generation)}, a novel framework that integrates trajectory guidance with sparse anchor motion control. Global trajectories ensure consistency in spatial direction and displacement, while sparse anchor motions only deliver precise action guidance without displacement. This decoupling enables independent refinement of both aspects, resulting in a more controllable, high-fidelity, and sophisticated motion synthesis. ProMoGen supports both dual and single control paradigms within a unified training process. Moreover, we recognize that direct learning from sparse motions is inherently unstable, we introduce \textbf{SAP-CL (Sparse Anchor Posture Curriculum Learning)}, a curriculum learning strategy that progressively adjusts the number of anchors used for guidance, thereby enabling more precise and stable convergence. Extensive experiments demonstrate that ProMoGen excels in synthesizing vivid and diverse motions guided by predefined trajectory and arbitrary anchor frames. Our approach seamlessly integrates personalized motion with structured guidance, significantly outperforming state-of-the-art methods across multiple control scenarios.
MaSkel: A Model for Human Whole-body X-rays Generation from Human Masking Images
Apr 13, 2024The human whole-body X-rays could offer a valuable reference for various applications, including medical diagnostics, digital animation modeling, and ergonomic design. The traditional method of obtaining X-ray information requires the use of CT (Computed Tomography) scan machines, which emit potentially harmful radiation. Thus it faces a significant limitation for realistic applications because it lacks adaptability and safety. In our work, We proposed a new method to directly generate the 2D human whole-body X-rays from the human masking images. The predicted images will be similar to the real ones with the same image style and anatomic structure. We employed a data-driven strategy. By leveraging advanced generative techniques, our model MaSkel(Masking image to Skeleton X-rays) could generate a high-quality X-ray image from a human masking image without the need for invasive and harmful radiation exposure, which not only provides a new path to generate highly anatomic and customized data but also reduces health risks. To our knowledge, our model MaSkel is the first work for predicting whole-body X-rays. In this paper, we did two parts of the work. The first one is to solve the data limitation problem, the diffusion-based techniques are utilized to make a data augmentation, which provides two synthetic datasets for preliminary pretraining. Then we designed a two-stage training strategy to train MaSkel. At last, we make qualitative and quantitative evaluations of the generated X-rays. In addition, we invite some professional doctors to assess our predicted data. These evaluations demonstrate the MaSkel's superior ability to generate anatomic X-rays from human masking images. The related code and links of the dataset are available at https://github.com/2022yingjie/MaSkel.
Seismic Fault Segmentation via 3D-CNN Training by a Few 2D Slices Labels
May 20, 2021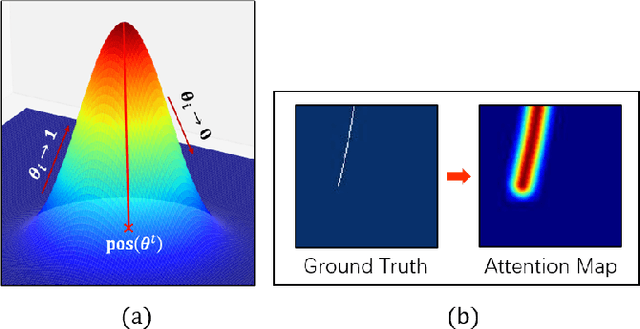
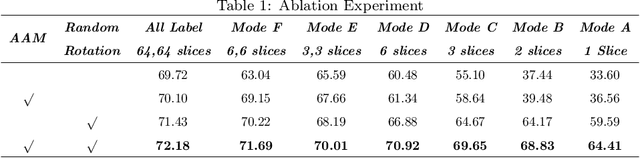
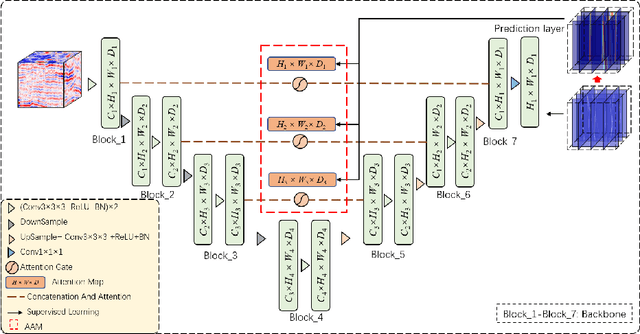
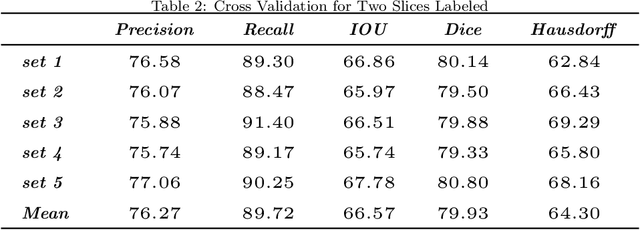
Detection faults in seismic data is a crucial step for seismic structural interpretation, reservoir characterization and well placement. Some recent works regard it as an image segmentation task. The task of image segmentation requires huge labels, especially 3D seismic data, which has a complex structure and lots of noise. Therefore, its annotation requires expert experience and a huge workload. In this study, we present {\lambda}-BCE and {\lambda}-smooth L1loss to effectively train 3D-CNN by some slices from 3D seismic data, so that the model can learn the segmentation of 3D seismic data from a few 2D slices. In order to fully extract information from limited data and suppress seismic noise, we propose an attention module that can be used for active supervision training and embedded in the network. The attention heatmap target is generated by the original label, and letting it supervise the attention module using the {\lambda}-smooth L1loss. The experiment proves the effectiveness of our loss function and attention module, it also shows that our method can extract 3D seismic features from a few 2D slices labels, and the segmentation effect achieves state-of-the-art. We only use 3.3% of the all labels, and we can achieve similar performance as using all labels. This work has been submitted to the IEEE for possible publication. Copyright may be transferred without notice, after which this version may no longer be accessible.