 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Bridging Vision and Language from the Video-to-Text Perspective: A Comprehensive Review
Mar 27, 2021
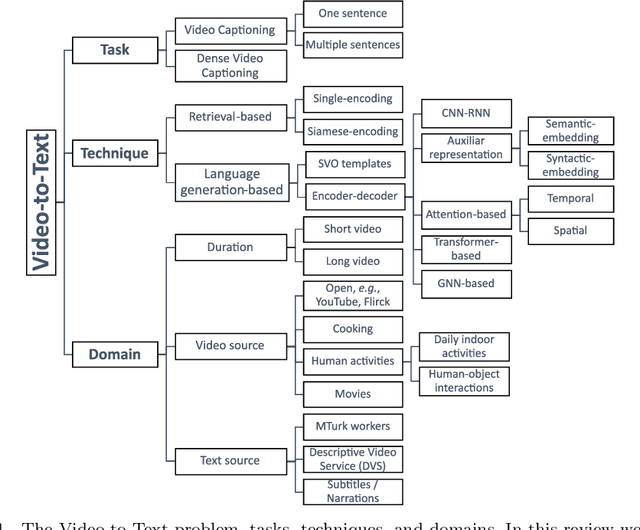
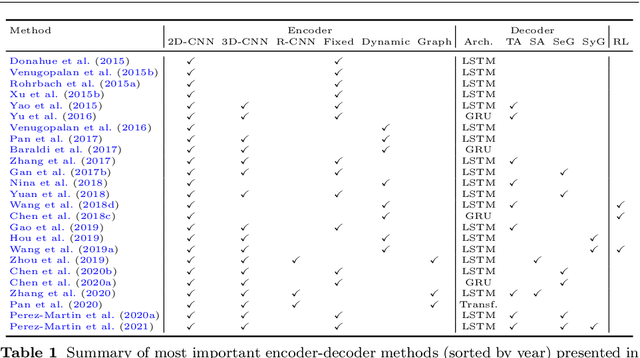
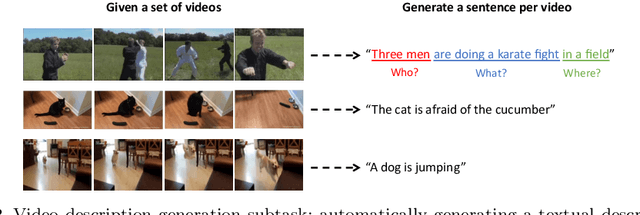
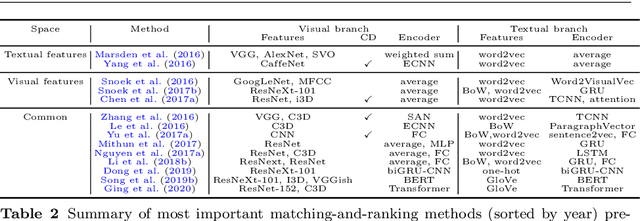
Research in the area of Vision and Language encompasses challenging topics that seek to connect visual and textual information. The video-to-text problem is one of these topics, in which the goal is to connect an input video with its textual description. This connection can be mainly made by retrieving the most significant descriptions from a corpus or generating a new one given a context video. These two ways represent essential tasks for Computer Vision and Natural Language Processing communities, called text retrieval from video task and video captioning/description task. These two tasks are substantially more complex than predicting or retrieving a single sentence from an image. The spatiotemporal information present in videos introduces diversity and complexity regarding the visual content and the structure of associated language descriptions. This review categorizes and describes the state-of-the-art techniques for the video-to-text problem. It covers the main video-to-text methods and the ways to evaluate their performance. We analyze how the most reported benchmark datasets have been created, showing their drawbacks and strengths for the problem requirements. We also show the impressive progress that researchers have made on each dataset, and we analyze why, despite this progress, the video-to-text conversion is still unsolved. State-of-the-art techniques are still a long way from achieving human-like performance in generating or retrieving video descriptions. We cover several significant challenges in the field and discuss future research directions.
Multi-Scale Cascading Network with Compact Feature Learning for RGB-Infrared Person Re-Identification
Dec 12, 2020
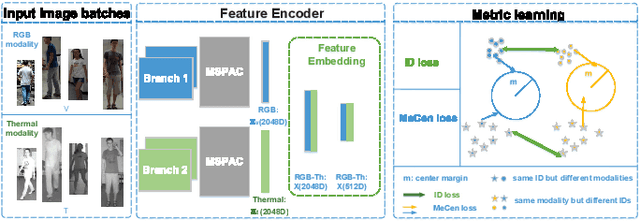
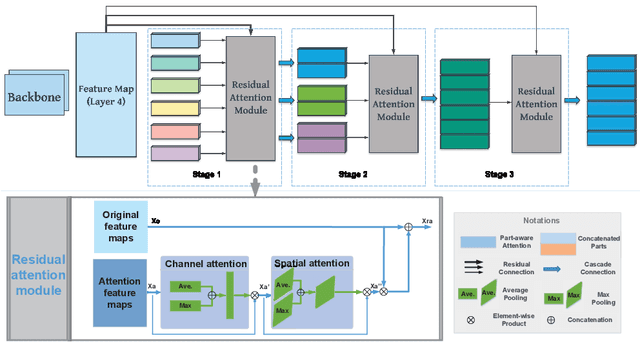
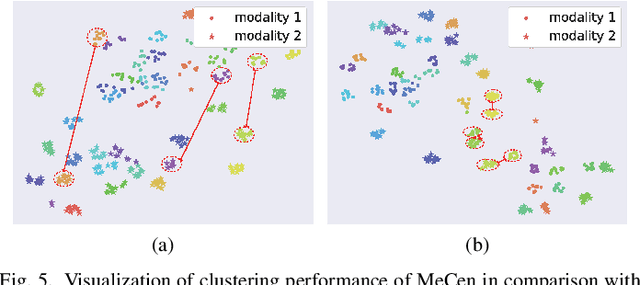
RGB-Infrared person re-identification (RGB-IR Re-ID) aims to match persons from heterogeneous images captured by visible and thermal cameras, which is of great significance in the surveillance system under poor light conditions. Facing great challenges in complex variances including conventional single-modality and additional inter-modality discrepancies, most of the existing RGB-IR Re-ID methods propose to impose constraints in image level, feature level or a hybrid of both. Despite the better performance of hybrid constraints, they are usually implemented with heavy network architecture. As a matter of fact, previous efforts contribute more as pioneering works in new cross-modal Re-ID area while leaving large space for improvement. This can be mainly attributed to: (1) lack of abundant person image pairs from different modalities for training, and (2) scarcity of salient modality-invariant features especially on coarse representations for effective matching. To address these issues, a novel Multi-Scale Part-Aware Cascading framework (MSPAC) is formulated by aggregating multi-scale fine-grained features from part to global in a cascading manner, which results in a unified representation containing rich and enhanced semantic features. Furthermore, a marginal exponential centre (MeCen) loss is introduced to jointly eliminate mixed variances from intra- and inter-modal examples. Cross-modality correlations can thus be efficiently explored on salient features for distinctive modality-invariant feature learning. Extensive experiments are conducted to demonstrate that the proposed method outperforms all the state-of-the-art by a large margin.
Real-time image-based instrument classification for laparoscopic surgery
Aug 01, 2018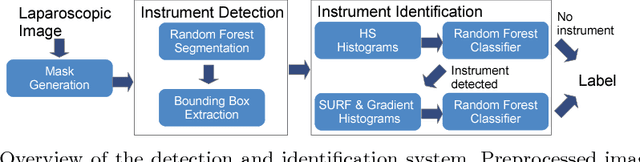
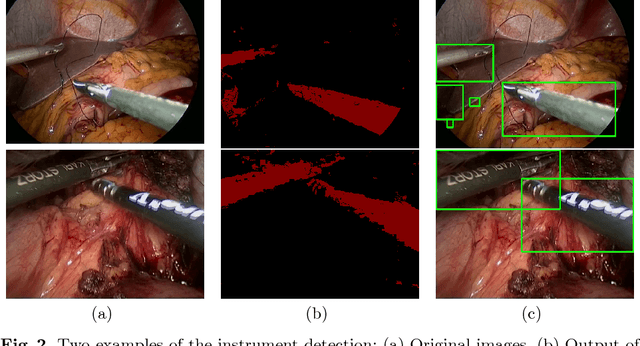


During laparoscopic surgery, context-aware assistance systems aim to alleviate some of the difficulties the surgeon faces. To ensure that the right information is provided at the right time, the current phase of the intervention has to be known. Real-time locating and classification the surgical tools currently in use are key components of both an activity-based phase recognition and assistance generation. In this paper, we present an image-based approach that detects and classifies tools during laparoscopic interventions in real-time. First, potential instrument bounding boxes are detected using a pixel-wise random forest segmentation. Each of these bounding boxes is then classified using a cascade of random forest. For this, multiple features, such as histograms over hue and saturation, gradients and SURF feature, are extracted from each detected bounding box. We evaluated our approach on five different videos from two different types of procedures. We distinguished between the four most common classes of instruments (LigaSure, atraumatic grasper, aspirator, clip applier) and background. Our method succesfully located up to 86% of all instruments respectively. On manually provided bounding boxes, we achieve a instrument type recognition rate of up to 58% and on automatically detected bounding boxes up to 49%. To our knowledge, this is the first approach that allows an image-based classification of surgical tools in a laparoscopic setting in real-time.
* Workshop paper accepted and presented at Modeling and Monitoring of Computer Assisted Interventions (M2CAI) (2015)
Improving the Classification of Rare Chords with Unlabeled Data
Dec 13, 2020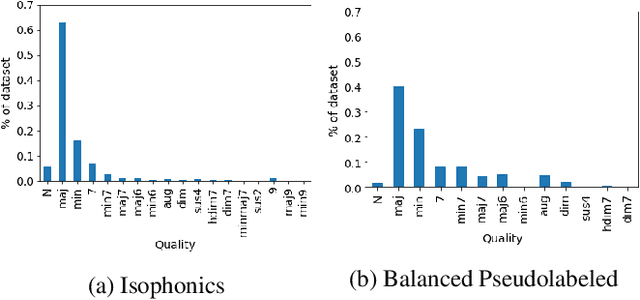

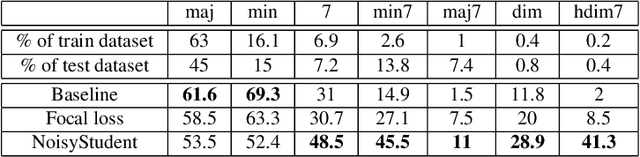
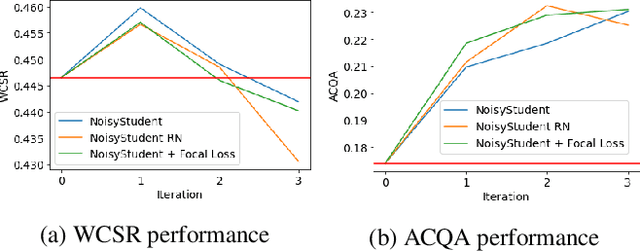
In this work, we explore techniques to improve performance for rare classes in the task of Automatic Chord Recognition (ACR). We first explored the use of the focal loss in the context of ACR, which was originally proposed to improve the classification of hard samples. In parallel, we adapted a self-learning technique originally designed for image recognition to the musical domain. Our experiments show that both approaches individually (and their combination) improve the recognition of rare chords, but using only self-learning with noise addition yields the best results.
Image-Text Multi-Modal Representation Learning by Adversarial Backpropagation
Dec 26, 2016
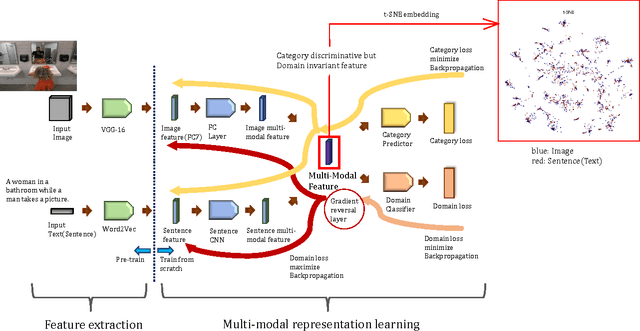

We present novel method for image-text multi-modal representation learning. In our knowledge, this work is the first approach of applying adversarial learning concept to multi-modal learning and not exploiting image-text pair information to learn multi-modal feature. We only use category information in contrast with most previous methods using image-text pair information for multi-modal embedding. In this paper, we show that multi-modal feature can be achieved without image-text pair information and our method makes more similar distribution with image and text in multi-modal feature space than other methods which use image-text pair information. And we show our multi-modal feature has universal semantic information, even though it was trained for category prediction. Our model is end-to-end backpropagation, intuitive and easily extended to other multi-modal learning work.
Camera Distance-aware Top-down Approach for 3D Multi-person Pose Estimation from a Single RGB Image
Aug 17, 2019
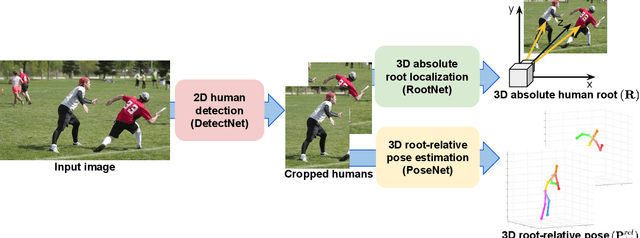
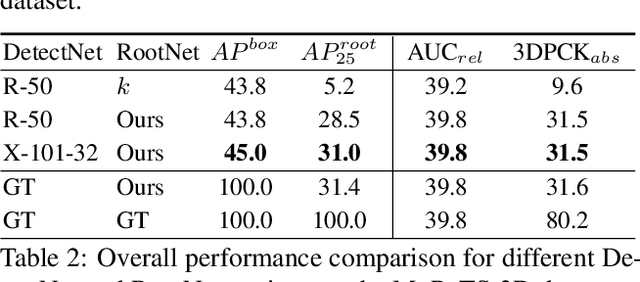
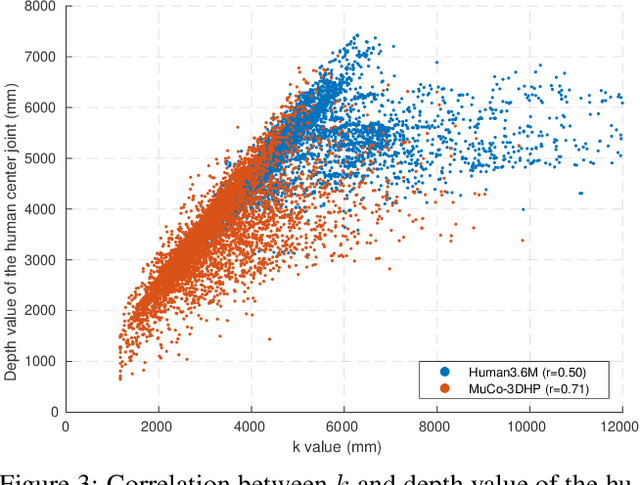
Although significant improvement has been achieved recently in 3D human pose estimation, most of the previous methods only treat a single-person case. In this work, we firstly propose a fully learning-based, camera distance-aware top-down approach for 3D multi-person pose estimation from a single RGB image. The pipeline of the proposed system consists of human detection, absolute 3D human root localization, and root-relative 3D single-person pose estimation modules. Our system achieves comparable results with the state-of-the-art 3D single-person pose estimation models without any groundtruth information and significantly outperforms previous 3D multi-person pose estimation methods on publicly available datasets. The code is available in https://github.com/mks0601/3DMPPE_ROOTNET_RELEASE , https://github.com/mks0601/3DMPPE_POSENET_RELEASE.
An Ultra Lightweight CNN for Low Resource Circuit Component Recognition
Oct 01, 2020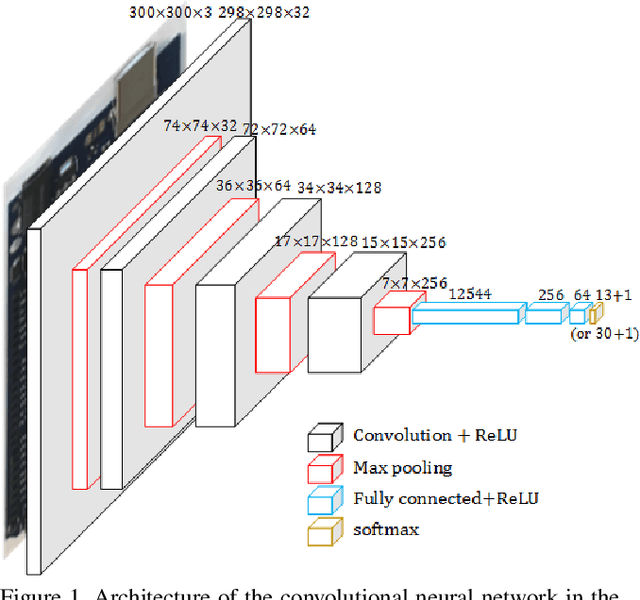
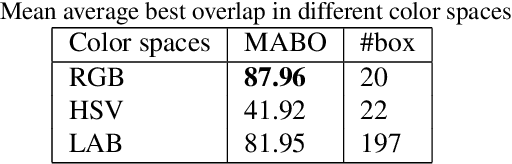
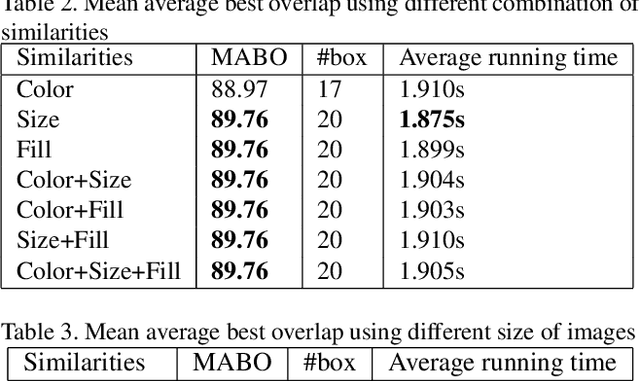
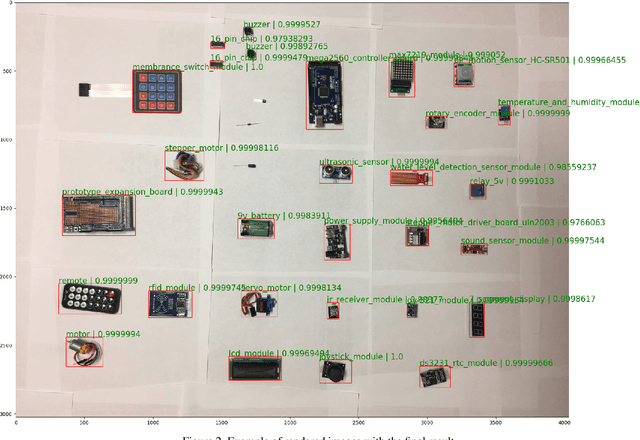
In this paper, we present an ultra lightweight system that can effectively recognize different circuit components in an image with very limited training data. Along with the system, we also release the data set we created for the task. A two-stage approach is employed by our system. Selective search was applied to find the location of each circuit component. Based on its result, we crop the original image into smaller pieces. The pieces are then fed to the Convolutional Neural Network (CNN) for classification to identify each circuit component. It is of engineering significance and works well in circuit component recognition in a low resource setting. The accuracy of our system reaches 93.4\%, outperforming the support vector machine (SVM) baseline (75.00%) and the existing state-of-the-art RetinaNet solutions (92.80%).
Anomaly localization by modeling perceptual features
Aug 12, 2020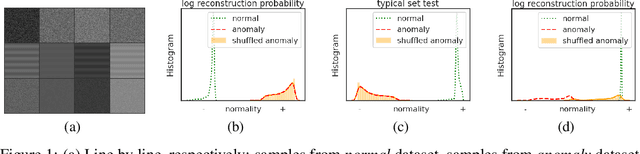
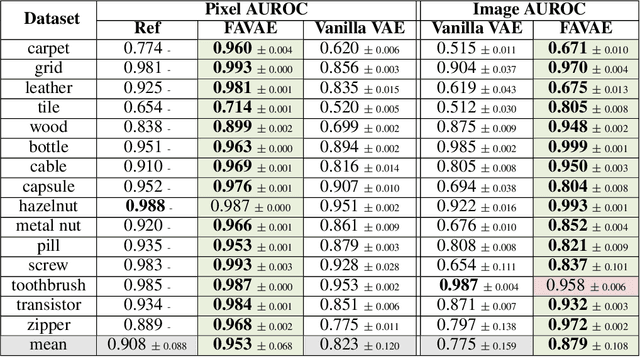
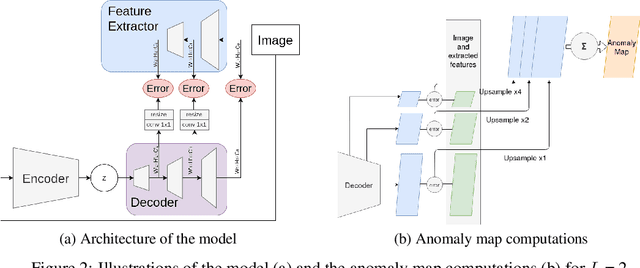

Although unsupervised generative modeling of an image dataset using a Variational AutoEncoder (VAE) has been used to detect anomalous images, or anomalous regions in images, recent works have shown that this method often identifies images or regions that do not concur with human perception, even questioning the usability of generative models for robust anomaly detection. Here, we argue that those issues can emerge from having a simplistic model of the anomaly distribution and we propose a new VAE-based model expressing a more complex anomaly model that is also closer to human perception. This Feature-Augmented VAE is trained by not only reconstructing the input image in pixel space, but also in several different feature spaces, which are computed by a convolutional neural network trained beforehand on a large image dataset. It achieves clear improvement over state-of-the-art methods on the MVTec anomaly detection and localization datasets.
NeRF--: Neural Radiance Fields Without Known Camera Parameters
Feb 19, 2021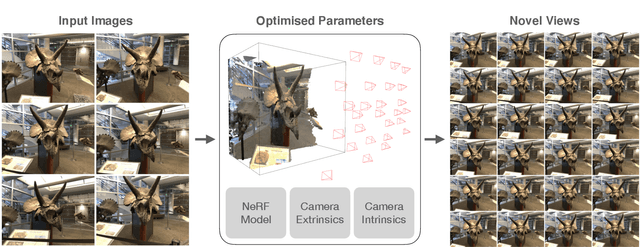
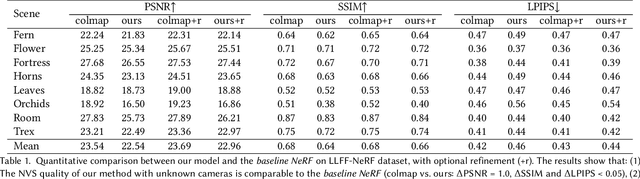
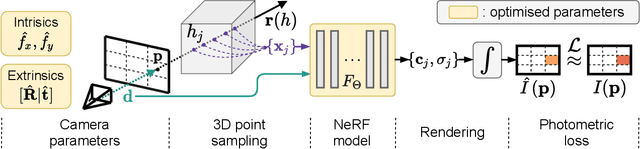
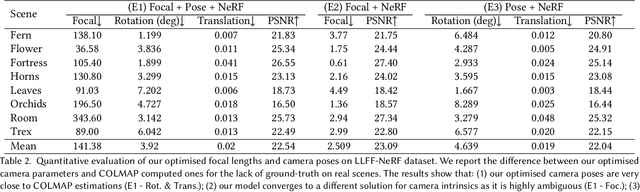
This paper tackles the problem of novel view synthesis (NVS) from 2D images without known camera poses and intrinsics. Among various NVS techniques, Neural Radiance Field (NeRF) has recently gained popularity due to its remarkable synthesis quality. Existing NeRF-based approaches assume that the camera parameters associated with each input image are either directly accessible at training, or can be accurately estimated with conventional techniques based on correspondences, such as Structure-from-Motion. In this work, we propose an end-to-end framework, termed NeRF--, for training NeRF models given only RGB images, without pre-computed camera parameters. Specifically, we show that the camera parameters, including both intrinsics and extrinsics, can be automatically discovered via joint optimisation during the training of the NeRF model. On the standard LLFF benchmark, our model achieves comparable novel view synthesis results compared to the baseline trained with COLMAP pre-computed camera parameters. We also conduct extensive analyses to understand the model behaviour under different camera trajectories, and show that in scenarios where COLMAP fails, our model still produces robust results.
A Novel Deep ML Architecture by Integrating Visual Simultaneous Localization and Mapping (vSLAM) into Mask R-CNN for Real-time Surgical Video Analysis
Apr 09, 2021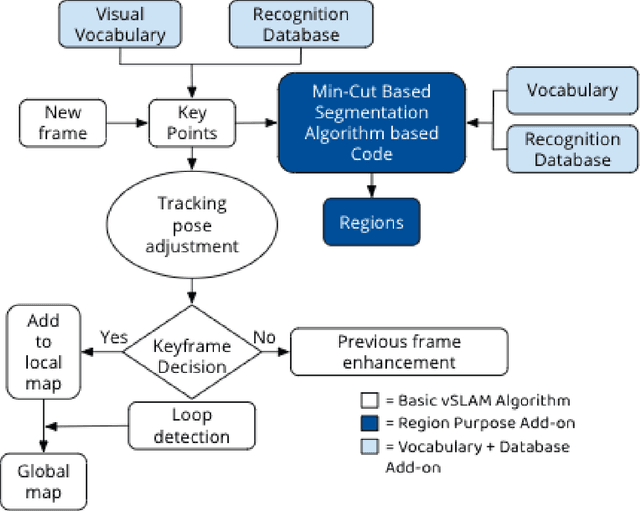
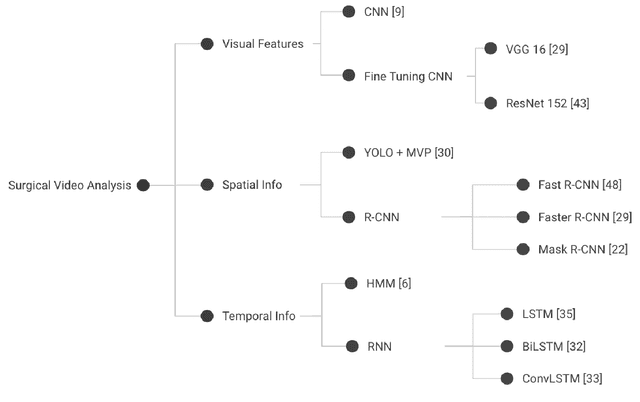
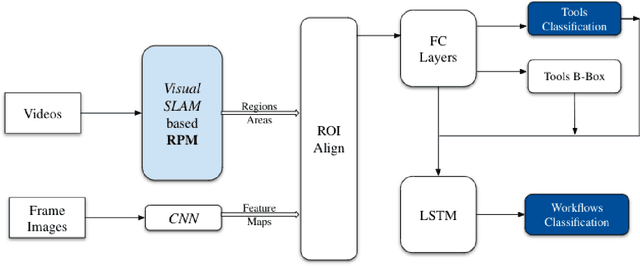
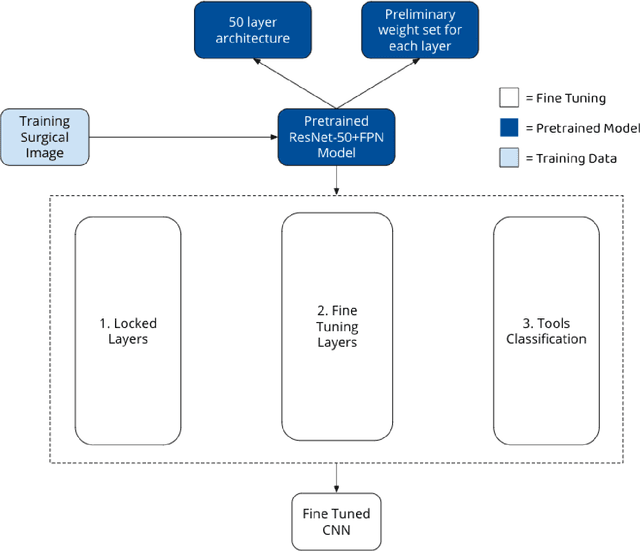
Seven million people suffer complications after surgery each year. With sufficient surgical training and feedback, half of these complications could be prevented. Automatic surgical video analysis, especially for minimally invasive surgery, plays a key role in training and review, with increasing interests from recent studies on tool and workflow detection. In this research, a novel machine learning architecture, RPM-CNN, is created to perform real-time surgical video analysis. This architecture, for the first time, integrates visual simultaneous localization and mapping (vSLAM) into Mask R-CNN. Spatio-temporal information, in addition to the visual features, is utilized to increase the accuracy to 96.8 mAP for tool detection and 97.5 mean Jaccard for workflow detection, surpassing all previous works via the same benchmark dataset. As a real-time prediction, the RPM-CNN model reaches a 50 FPS runtime performance speed, 10x faster than region based CNN, by modeling the spatio-temporal information directly from surgical videos during the vSLAM 3D mapping. Additionally, this novel Region Proposal Module (RPM) replaces the region proposal network (RPN) in Mask R-CNN, accurately placing bounding-boxes and lessening the annotation requirement. In principle, this architecture integrates the best of both worlds, inclusive of (1) vSLAM on object detection, through focusing on geometric information for region proposals and (2) CNN on object recognition, through focusing on semantic information for image classification; the integration of these two technologies into one joint training process opens a new door in computer vision. Furthermore, to apply RPM-CNN's real-time top performance to the real world, a Microsoft HoloLens 2 application is developed to provide an augmented reality (AR) based solution for both surgical training and assistance.