 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep learning with self-supervision and uncertainty regularization to count fish in underwater images
Apr 30, 2021
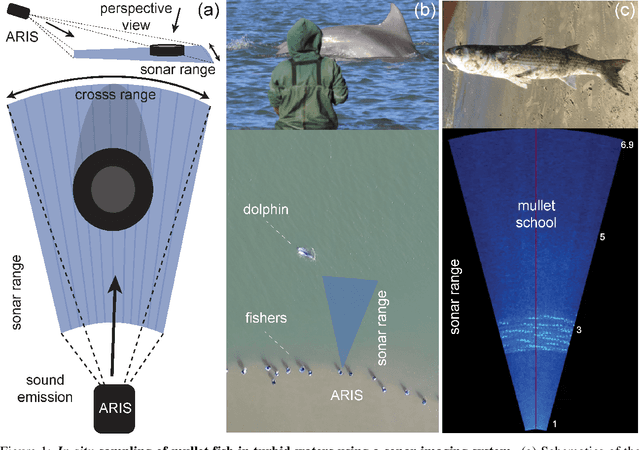
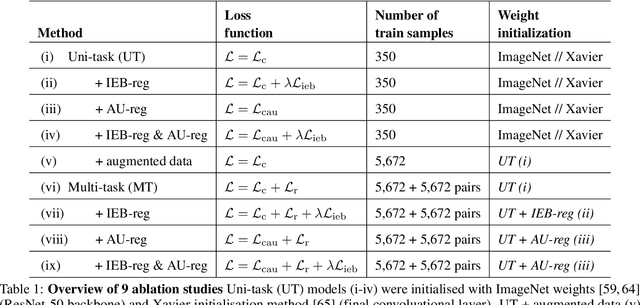
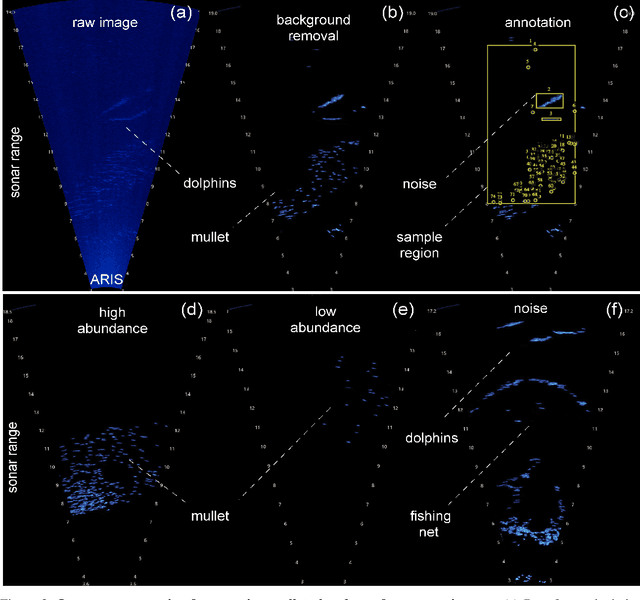
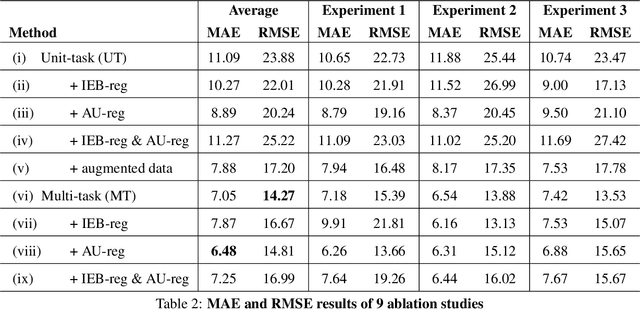
Effective conservation actions require effective population monitoring. However, accurately counting animals in the wild to inform conservation decision-making is difficult. Monitoring populations through image sampling has made data collection cheaper, wide-reaching and less intrusive but created a need to process and analyse this data efficiently. Counting animals from such data is challenging, particularly when densely packed in noisy images. Attempting this manually is slow and expensive, while traditional computer vision methods are limited in their generalisability. Deep learning is the state-of-the-art method for many computer vision tasks, but it has yet to be properly explored to count animals. To this end, we employ deep learning, with a density-based regression approach, to count fish in low-resolution sonar images. We introduce a large dataset of sonar videos, deployed to record wild mullet schools (Mugil liza), with a subset of 500 labelled images. We utilise abundant unlabelled data in a self-supervised task to improve the supervised counting task. For the first time in this context, by introducing uncertainty quantification, we improve model training and provide an accompanying measure of prediction uncertainty for more informed biological decision-making. Finally, we demonstrate the generalisability of our proposed counting framework through testing it on a recent benchmark dataset of high-resolution annotated underwater images from varying habitats (DeepFish). From experiments on both contrasting datasets, we demonstrate our network outperforms the few other deep learning models implemented for solving this task. By providing an open-source framework along with training data, our study puts forth an efficient deep learning template for crowd counting aquatic animals thereby contributing effective methods to assess natural populations from the ever-increasing visual data.
Kindling the Darkness: A Practical Low-light Image Enhancer
May 04, 2019
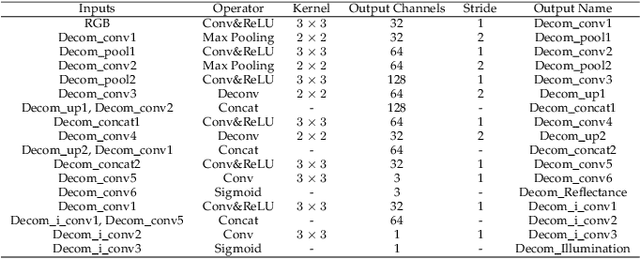
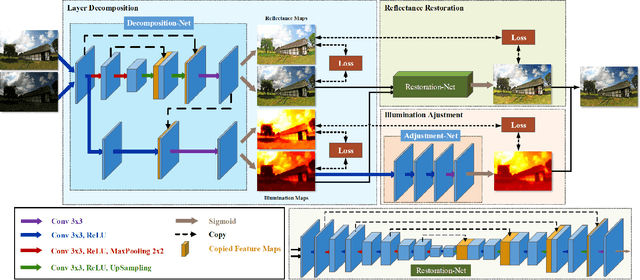
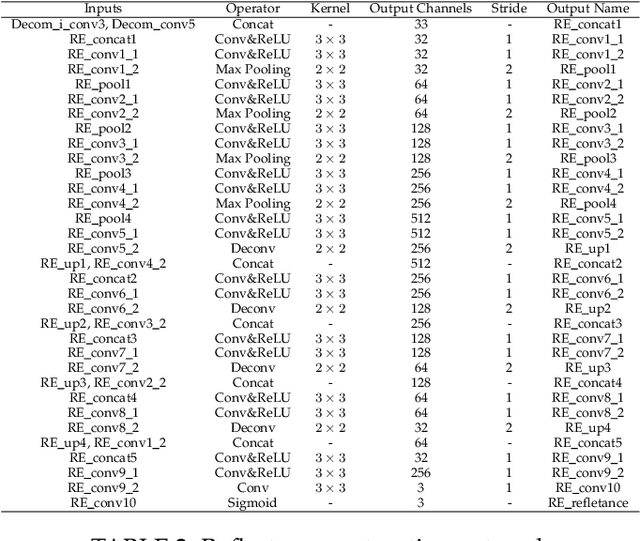
Images captured under low-light conditions often suffer from (partially) poor visibility. Besides unsatisfactory lightings, multiple types of degradations, such as noise and color distortion due to the limited quality of cameras, hide in the dark. In other words, solely turning up the brightness of dark regions will inevitably amplify hidden artifacts. This work builds a simple yet effective network for \textbf{Kin}dling the \textbf{D}arkness (denoted as KinD), which, inspired by Retinex theory, decomposes images into two components. One component (illumination) is responsible for light adjustment, while the other (reflectance) for degradation removal. In such a way, the original space is decoupled into two smaller subspaces, expecting to be better regularized/learned. It is worth to note that our network is trained with paired images shot under different exposure conditions, instead of using any ground-truth reflectance and illumination information. Extensive experiments are conducted to demonstrate the efficacy of our design and its superiority over state-of-the-art alternatives. Our KinD is robust against severe visual defects, and user-friendly to arbitrarily adjust light levels. In addition, our model spends less than 50ms to process an image in VGA resolution on a 2080Ti GPU. All the above merits make our KinD attractive for practical use.
EXplainable Neural-Symbolic Learning (X-NeSyL) methodology to fuse deep learning representations with expert knowledge graphs: the MonuMAI cultural heritage use case
Apr 24, 2021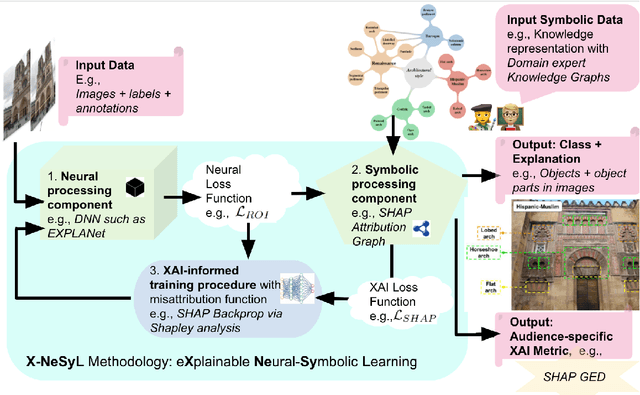


The latest Deep Learning (DL) models for detection and classification have achieved an unprecedented performance over classical machine learning algorithms. However, DL models are black-box methods hard to debug, interpret, and certify. DL alone cannot provide explanations that can be validated by a non technical audience. In contrast, symbolic AI systems that convert concepts into rules or symbols -- such as knowledge graphs -- are easier to explain. However, they present lower generalisation and scaling capabilities. A very important challenge is to fuse DL representations with expert knowledge. One way to address this challenge, as well as the performance-explainability trade-off is by leveraging the best of both streams without obviating domain expert knowledge. We tackle such problem by considering the symbolic knowledge is expressed in form of a domain expert knowledge graph. We present the eXplainable Neural-symbolic learning (X-NeSyL) methodology, designed to learn both symbolic and deep representations, together with an explainability metric to assess the level of alignment of machine and human expert explanations. The ultimate objective is to fuse DL representations with expert domain knowledge during the learning process to serve as a sound basis for explainability. X-NeSyL methodology involves the concrete use of two notions of explanation at inference and training time respectively: 1) EXPLANet: Expert-aligned eXplainable Part-based cLAssifier NETwork Architecture, a compositional CNN that makes use of symbolic representations, and 2) SHAP-Backprop, an explainable AI-informed training procedure that guides the DL process to align with such symbolic representations in form of knowledge graphs. We showcase X-NeSyL methodology using MonuMAI dataset for monument facade image classification, and demonstrate that our approach improves explainability and performance.
Deep Learning from Shallow Dives: Sonar Image Generation and Training for Underwater Object Detection
Oct 18, 2018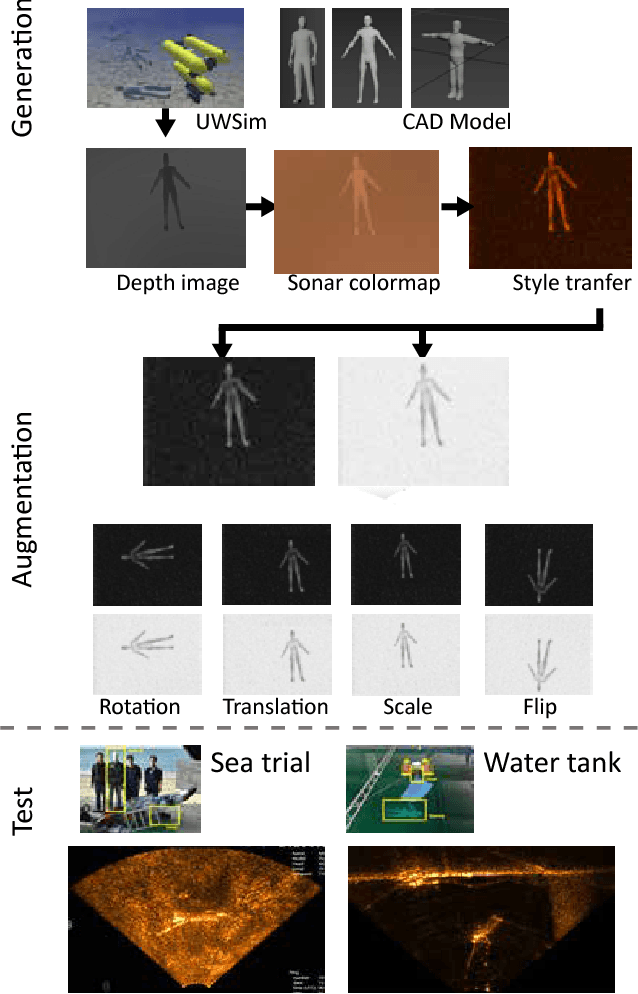
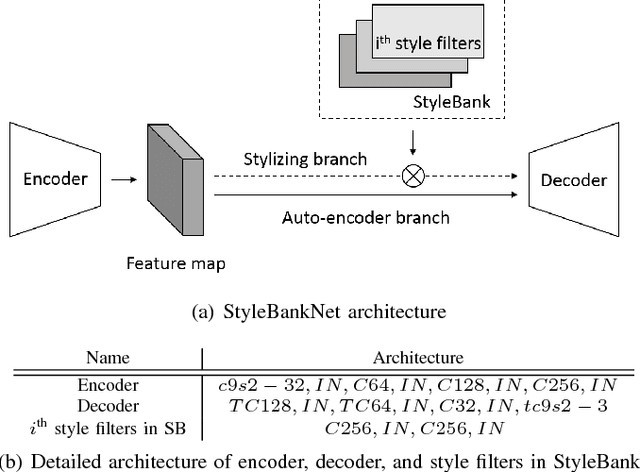

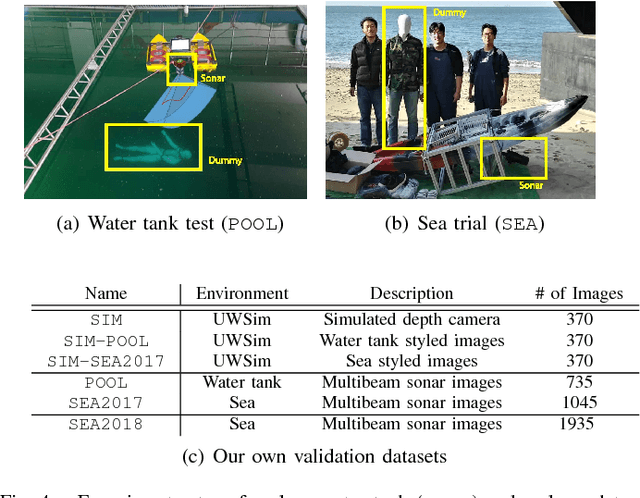
Among underwater perceptual sensors, imaging sonar has been highlighted for its perceptual robustness underwater. The major challenge of imaging sonar, however, arises from the difficulty in defining visual features despite limited resolution and high noise levels. Recent developments in deep learning provide a powerful solution for computer-vision researches using optical images. Unfortunately, deep learning-based approaches are not well established for imaging sonars, mainly due to the scant data in the training phase. Unlike the abundant publically available terrestrial images, obtaining underwater images is often costly, and securing enough underwater images for training is not straightforward. To tackle this issue, this paper presents a solution to this field's lack of data by introducing a novel end-to-end image-synthesizing method in the training image preparation phase. The proposed method present image synthesizing scheme to the images captured by an underwater simulator. Our synthetic images are based on the sonar imaging models and noisy characteristics to represent the real data obtained from the sea. We validate the proposed scheme by training using a simulator and by testing the simulated images with real underwater sonar images obtained from a water tank and the sea.
Robust joint registration of multiple stains and MRI for multimodal 3D histology reconstruction: Application to the Allen human brain atlas
Apr 30, 2021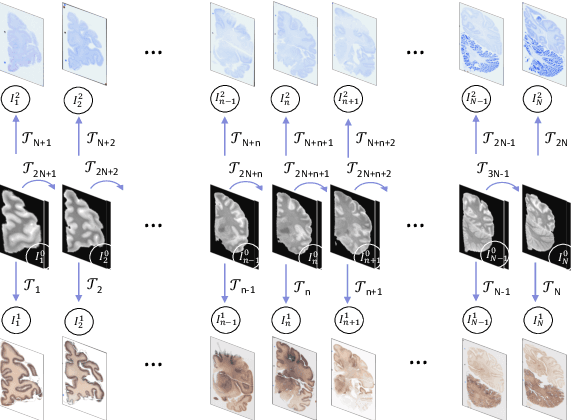
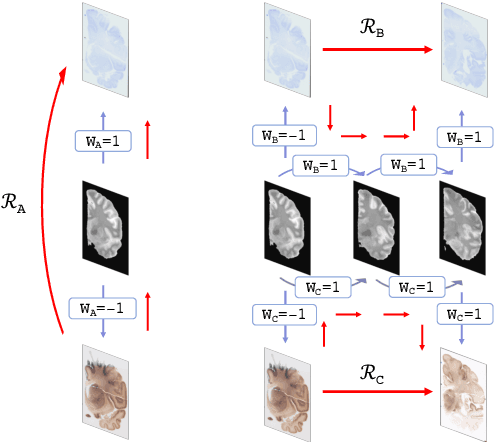
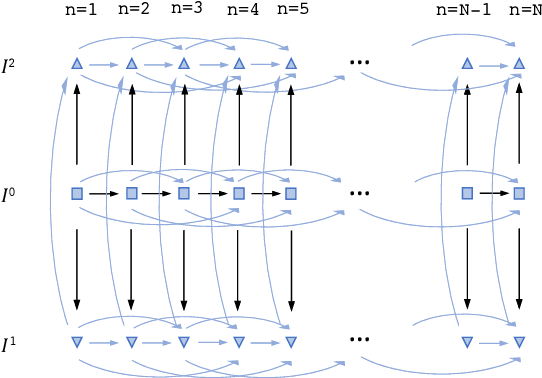
Joint registration of a stack of 2D histological sections to recover 3D structure (3D histology reconstruction) finds application in areas such as atlas building and validation of in vivo imaging. Straighforward pairwise registration of neighbouring sections yields smooth reconstructions but has well-known problems such as banana effect (straightening of curved structures) and z-shift (drift). While these problems can be alleviated with an external, linearly aligned reference (e.g., Magnetic Resonance images), registration is often inaccurate due to contrast differences and the strong nonlinear distortion of the tissue, including artefacts such as folds and tears. In this paper, we present a probabilistic model of spatial deformation that yields reconstructions for multiple histological stains that that are jointly smooth, robust to outliers, and follow the reference shape. The model relies on a spanning tree of latent transforms connecting all the sections and slices, and assumes that the registration between any pair of images can be see as a noisy version of the composition of (possibly inverted) latent transforms connecting the two images. Bayesian inference is used to compute the most likely latent transforms given a set of pairwise registrations between image pairs within and across modalities. Results on synthetic deformations on multiple MR modalities, show that our method can accurately and robustly register multiple contrasts even in the presence of outliers. The 3D histology reconstruction of two stains (Nissl and parvalbumin) from the Allen human brain atlas, show its benefits on real data with severe distortions. We also provide the correspondence to MNI space, bridging the gap between two of the most used atlases in histology and MRI. Data is available at https://openneuro.org/datasets/ds003590 and code https://github.com/acasamitjana/3dhirest.
Lightweight Feature Fusion Network for Single Image Super-Resolution
Apr 13, 2019
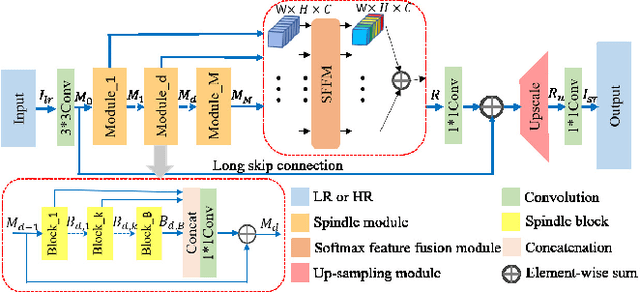
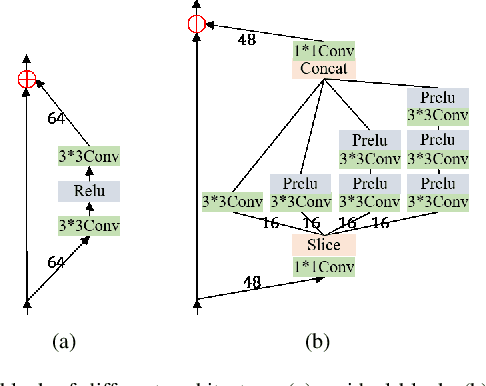
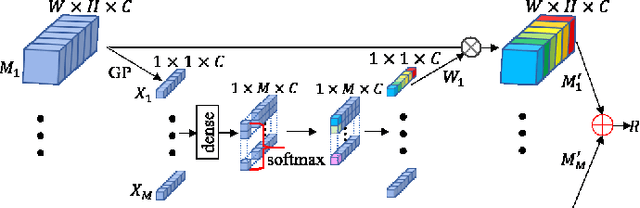
Single image super-resolution(SISR) has witnessed great progress as convolutional neural network(CNN) gets deeper and wider. However, enormous parameters hinder its application to real world problems. In this letter, We propose a lightweight feature fusion network (LFFN) that can fully explore multi-scale contextual information and greatly reduce network parameters while maximizing SISR results. LFFN is built on spindle blocks and a softmax feature fusion module (SFFM). Specifically, a spindle block is composed of a dimension extension unit, a feature exploration unit and a feature refinement unit. The dimension extension layer expands low dimension to high dimension and implicitly learns the feature maps which is suitable for the next unit. The feature exploration unit performs linear and nonlinear feature exploration aimed at different feature maps. The feature refinement layer is used to fuse and refine features. SFFM fuses the features from different modules in a self-adaptive learning manner with softmax function, making full use of hierarchical information with a small amount of parameter cost. Both qualitative and quantitative experiments on benchmark datasets show that LFFN achieves favorable performance against state-of-the-art methods with similar parameters.
Few-shot Weakly-Supervised Object Detection via Directional Statistics
Mar 25, 2021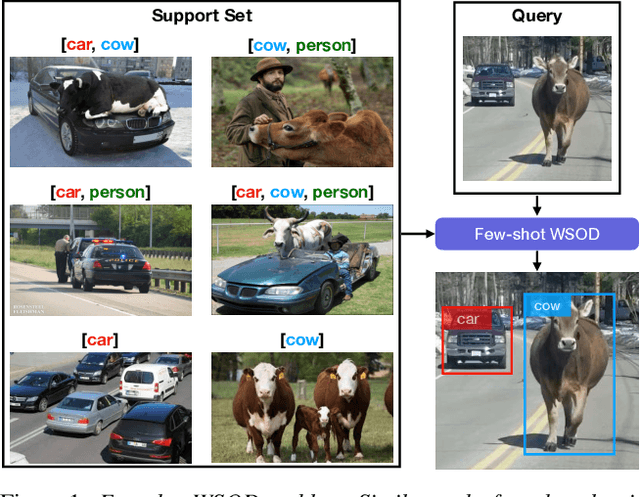
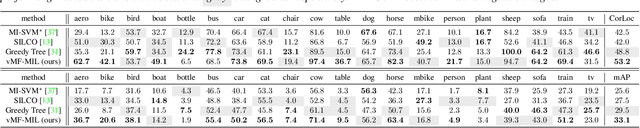
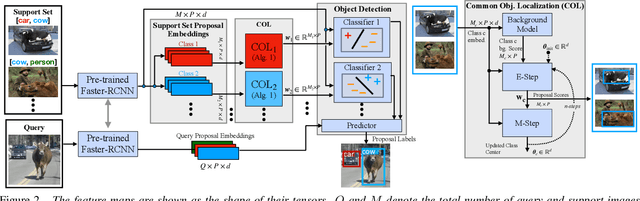

Detecting novel objects from few examples has become an emerging topic in computer vision recently. However, these methods need fully annotated training images to learn new object categories which limits their applicability in real world scenarios such as field robotics. In this work, we propose a probabilistic multiple instance learning approach for few-shot Common Object Localization (COL) and few-shot Weakly Supervised Object Detection (WSOD). In these tasks, only image-level labels, which are much cheaper to acquire, are available. We find that operating on features extracted from the last layer of a pre-trained Faster-RCNN is more effective compared to previous episodic learning based few-shot COL methods. Our model simultaneously learns the distribution of the novel objects and localizes them via expectation-maximization steps. As a probabilistic model, we employ von Mises-Fisher (vMF) distribution which captures the semantic information better than Gaussian distribution when applied to the pre-trained embedding space. When the novel objects are localized, we utilize them to learn a linear appearance model to detect novel classes in new images. Our extensive experiments show that the proposed method, despite being simple, outperforms strong baselines in few-shot COL and WSOD, as well as large-scale WSOD tasks.
Image Restoration from Patch-based Compressed Sensing Measurement
Jun 02, 2017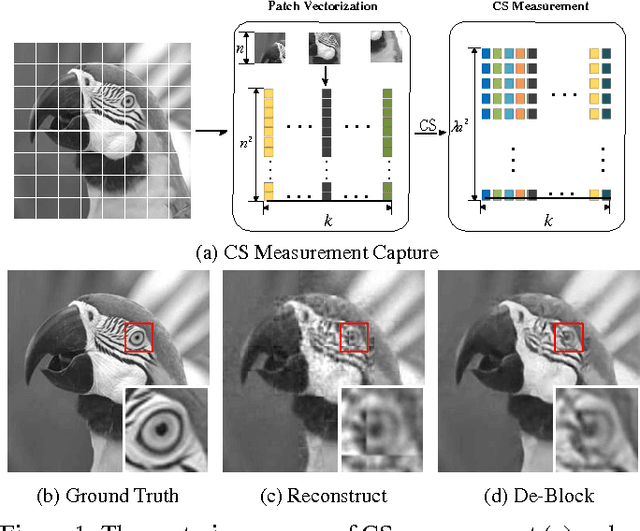

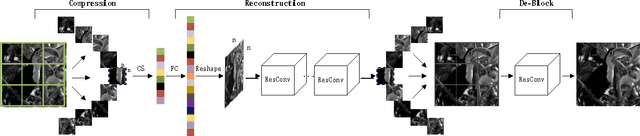

A series of methods have been proposed to reconstruct an image from compressively sensed random measurement, but most of them have high time complexity and are inappropriate for patch-based compressed sensing capture, because of their serious blocky artifacts in the restoration results. In this paper, we present a non-iterative image reconstruction method from patch-based compressively sensed random measurement. Our method features two cascaded networks based on residual convolution neural network to learn the end-to-end full image restoration, which is capable of reconstructing image patches and removing the blocky effect with low time cost. Experimental results on synthetic and real data show that our method outperforms state-of-the-art compressive sensing (CS) reconstruction methods with patch-based CS measurement. To demonstrate the effectiveness of our method in more general setting, we apply the de-block process in our method to JPEG compression artifacts removal and achieve outstanding performance as well.
An Overview on Artificial Intelligence Techniques for Diagnosis of Schizophrenia Based on Magnetic Resonance Imaging Modalities: Methods, Challenges, and Future Works
Feb 24, 2021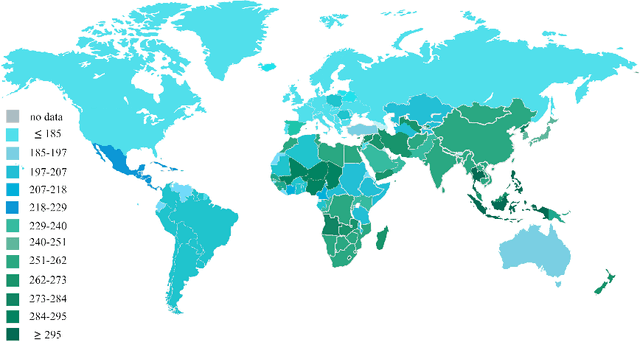
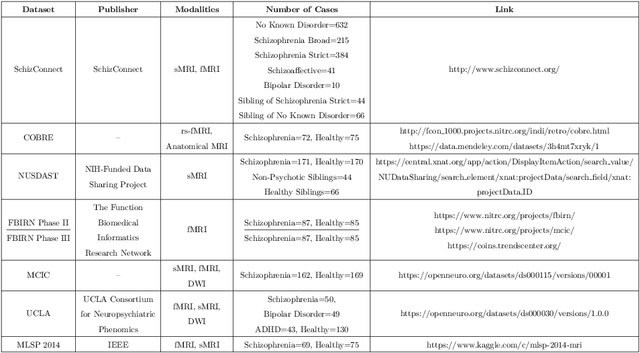
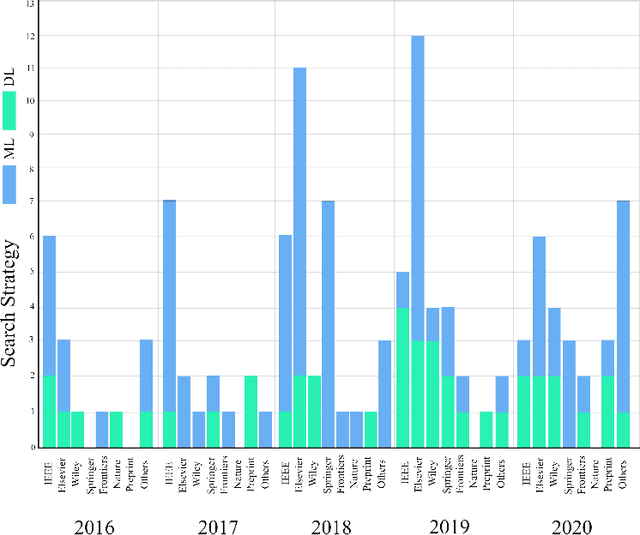
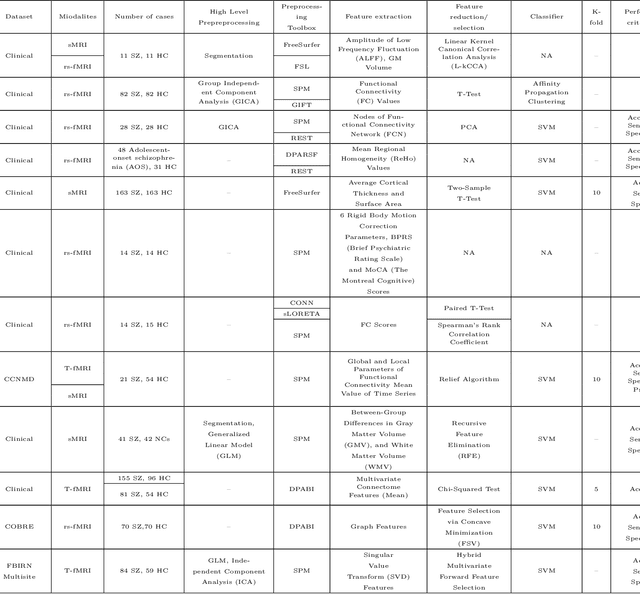
Schizophrenia (SZ) is a mental disorder that typically emerges in late adolescence or early adulthood. It reduces the life expectancy of patients by 15 years. Abnormal behavior, perception of emotions, social relationships, and reality perception are among its most significant symptoms. Past studies have revealed the temporal and anterior lobes of hippocampus regions of brain get affected by SZ. Also, increased volume of cerebrospinal fluid (CSF) and decreased volume of white and gray matter can be observed due to this disease. The magnetic resonance imaging (MRI) is the popular neuroimaging technique used to explore structural/functional brain abnormalities in SZ disorder owing to its high spatial resolution. Various artificial intelligence (AI) techniques have been employed with advanced image/signal processing methods to obtain accurate diagnosis of SZ. This paper presents a comprehensive overview of studies conducted on automated diagnosis of SZ using MRI modalities. Main findings, various challenges, and future works in developing the automated SZ detection are described in this paper.
A Dense-Depth Representation for VLAD descriptors in Content-Based Image Retrieval
Aug 15, 2018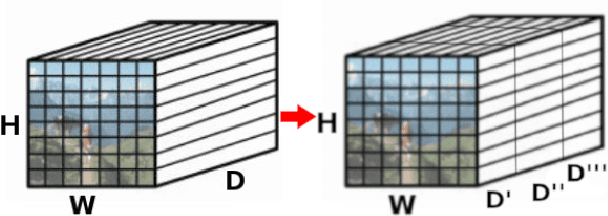
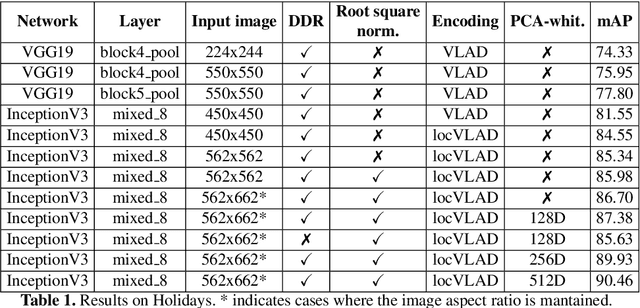
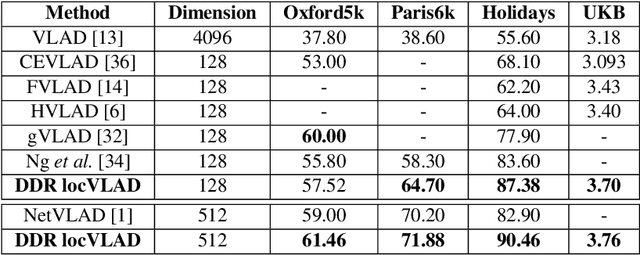
The recent advances brought by deep learning allowed to improve the performance in image retrieval tasks. Through the many convolutional layers, available in a Convolutional Neural Network (CNN), it is possible to obtain a hierarchy of features from the evaluated image. At every step, the patches extracted are smaller than the previous levels and more representative. Following this idea, this paper introduces a new detector applied on the feature maps extracted from pre-trained CNN. Specifically, this approach lets to increase the number of features in order to increase the performance of the aggregation algorithms like the most famous and used VLAD embedding. The proposed approach is tested on different public datasets: Holidays, Oxford5k, Paris6k and UKB.