 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Geometric Reasoner: Manifold-Informed Latent Foresight Search for Long-Context Reasoning
Jan 25, 2026Scaling test-time compute enhances long chain-of-thought (CoT) reasoning, yet existing approaches face a fundamental trade-off between computational cost and coverage quality: either incurring high training expense or yielding redundant trajectories. We introduce The Geometric Reasoner (TGR), a training-free framework that performs manifold-informed latent foresight search under strict memory bounds. At each chunk boundary, TGR scores candidate latent anchors via a lightweight look-ahead estimate combined with soft geometric regularizers that encourage smooth trajectories and diverse exploration. Chunk-wise KV cache resets keep memory linear in chunk length. On challenging math and code benchmarks, TGR improves robust trajectory coverage, measured by the area under the Pass@$k$ curve (AUC), by up to 13 points on Qwen3-8B, with negligible overhead of about 1.1--1.3 times.
Accelerating Chain-of-Thought Reasoning: When Goal-Gradient Importance Meets Dynamic Skipping
May 13, 2025Large Language Models leverage Chain-of-Thought (CoT) prompting for complex tasks, but their reasoning traces are often excessively verbose and inefficient, leading to significant computational costs and latency. Current CoT compression techniques typically rely on generic importance metrics and static compression rates, which may inadvertently remove functionally critical tokens or fail to adapt to varying reasoning complexity. To overcome these limitations, we propose Adaptive GoGI-Skip, a novel framework learning dynamic CoT compression via supervised fine-tuning. This approach introduces two synergistic innovations: (1) Goal-Gradient Importance (GoGI), a novel metric accurately identifying functionally relevant tokens by measuring the gradient influence of their intermediate representations on the final answer loss, and (2) Adaptive Dynamic Skipping (ADS), a mechanism dynamically regulating the compression rate based on runtime model uncertainty while ensuring local coherence through an adaptive N-token constraint. To our knowledge, this is the first work unifying a goal-oriented, gradient-based importance metric with dynamic, uncertainty-aware skipping for CoT compression. Trained on compressed MATH data, Adaptive GoGI-Skip demonstrates strong cross-domain generalization across diverse reasoning benchmarks including AIME, GPQA, and GSM8K. It achieves substantial efficiency gains - reducing CoT token counts by over 45% on average and delivering 1.6-2.0 times inference speedups - while maintaining high reasoning accuracy. Notably, it significantly outperforms existing baselines by preserving accuracy even at high effective compression rates, advancing the state of the art in the CoT reasoning efficiency-accuracy trade-off.
Lightweight Feature Fusion Network for Single Image Super-Resolution
Apr 13, 2019
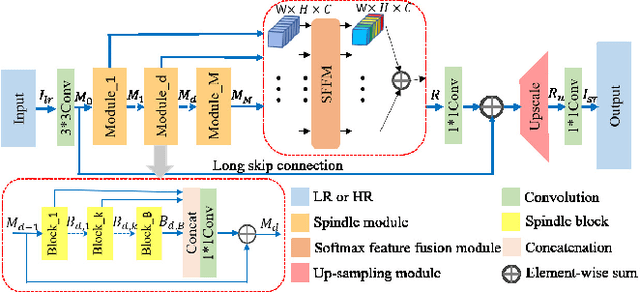
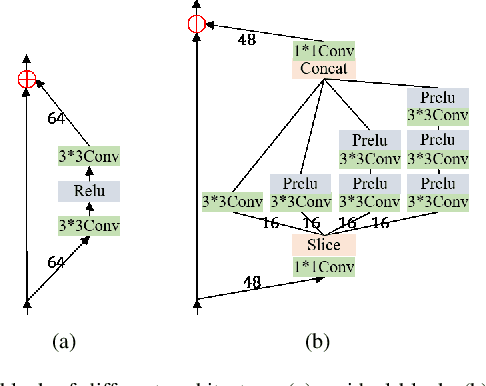
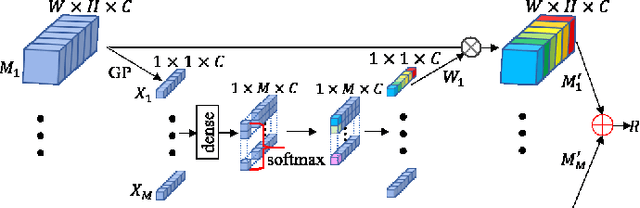
Single image super-resolution(SISR) has witnessed great progress as convolutional neural network(CNN) gets deeper and wider. However, enormous parameters hinder its application to real world problems. In this letter, We propose a lightweight feature fusion network (LFFN) that can fully explore multi-scale contextual information and greatly reduce network parameters while maximizing SISR results. LFFN is built on spindle blocks and a softmax feature fusion module (SFFM). Specifically, a spindle block is composed of a dimension extension unit, a feature exploration unit and a feature refinement unit. The dimension extension layer expands low dimension to high dimension and implicitly learns the feature maps which is suitable for the next unit. The feature exploration unit performs linear and nonlinear feature exploration aimed at different feature maps. The feature refinement layer is used to fuse and refine features. SFFM fuses the features from different modules in a self-adaptive learning manner with softmax function, making full use of hierarchical information with a small amount of parameter cost. Both qualitative and quantitative experiments on benchmark datasets show that LFFN achieves favorable performance against state-of-the-art methods with similar parameters.