 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Revisiting Adaptive Convolutions for Video Frame Interpolation
Nov 02, 2020
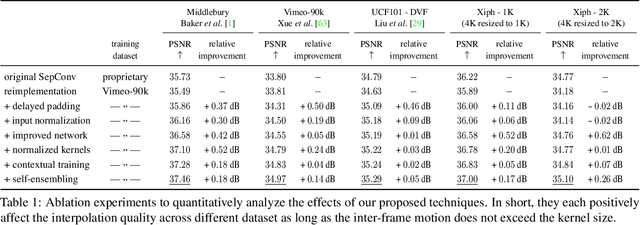
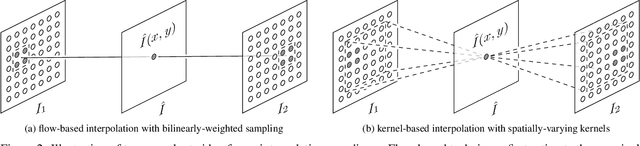
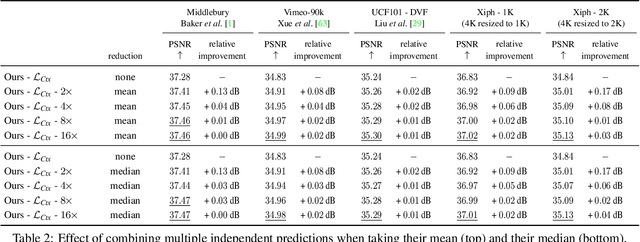
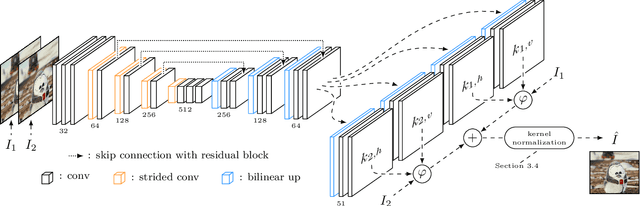
Video frame interpolation, the synthesis of novel views in time, is an increasingly popular research direction with many new papers further advancing the state of the art. But as each new method comes with a host of variables that affect the interpolation quality, it can be hard to tell what is actually important for this task. In this work, we show, somewhat surprisingly, that it is possible to achieve near state-of-the-art results with an older, simpler approach, namely adaptive separable convolutions, by a subtle set of low level improvements. In doing so, we propose a number of intuitive but effective techniques to improve the frame interpolation quality, which also have the potential to other related applications of adaptive convolutions such as burst image denoising, joint image filtering, or video prediction.
ISP4ML: Understanding the Role of Image Signal Processing in Efficient Deep Learning Vision Systems
Nov 25, 2019

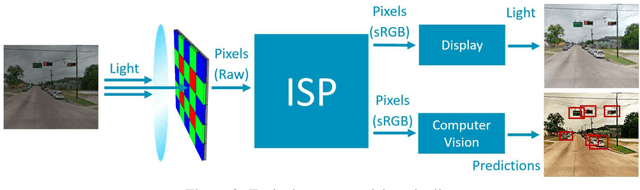
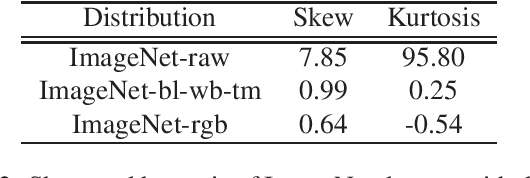
Convolutional neural networks (CNNs) are now predominant components in a variety of computer vision (CV) systems. These systems typically include an image signal processor (ISP), even though the ISP is traditionally designed to produce images that look appealing to humans. In CV systems, it is not clear what the role of the ISP is, or if it is even required at all for accurate prediction. In this work, we investigate the efficacy of the ISP in CNN classification tasks, and outline the system-level trade-offs between prediction accuracy and computational cost. To do so, we build software models of a configurable ISP and an imaging sensor in order to train CNNs on ImageNet with a range of different ISP settings and functionality. Results on ImageNet show that an ISP improves accuracy by 4.6%-12.2% on MobileNet architectures of different widths. Results using ResNets demonstrate that these trends also generalize to deeper networks. An ablation study of the various processing stages in a typical ISP reveals that the tone mapper is the most significant stage when operating on high dynamic range (HDR) images, by providing 5.8% average accuracy improvement alone. Overall, the ISP benefits system efficiency because the memory and computational costs of the ISP is minimal compared to the cost of using a larger CNN to achieve the same accuracy.
Gradient Projection Memory for Continual Learning
Mar 17, 2021
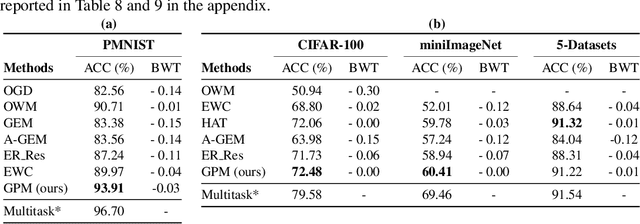
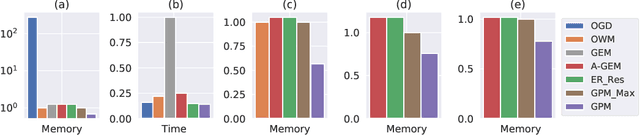
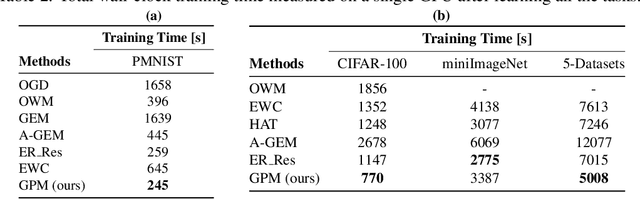
The ability to learn continually without forgetting the past tasks is a desired attribute for artificial learning systems. Existing approaches to enable such learning in artificial neural networks usually rely on network growth, importance based weight update or replay of old data from the memory. In contrast, we propose a novel approach where a neural network learns new tasks by taking gradient steps in the orthogonal direction to the gradient subspaces deemed important for the past tasks. We find the bases of these subspaces by analyzing network representations (activations) after learning each task with Singular Value Decomposition (SVD) in a single shot manner and store them in the memory as Gradient Projection Memory (GPM). With qualitative and quantitative analyses, we show that such orthogonal gradient descent induces minimum to no interference with the past tasks, thereby mitigates forgetting. We evaluate our algorithm on diverse image classification datasets with short and long sequences of tasks and report better or on-par performance compared to the state-of-the-art approaches.
* Accepted for Oral Presentation at ICLR 2021 https://openreview.net/forum?id=3AOj0RCNC2
Joint Modeling of Chest Radiographs and Radiology Reports for Pulmonary Edema Assessment
Aug 22, 2020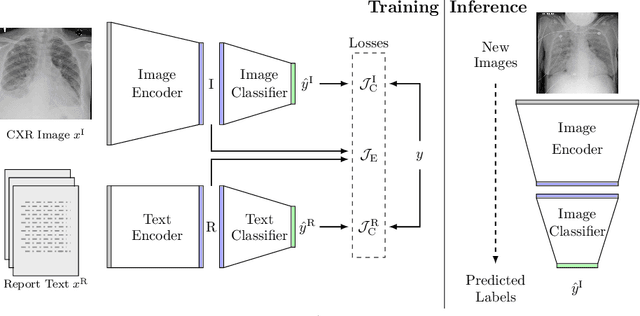

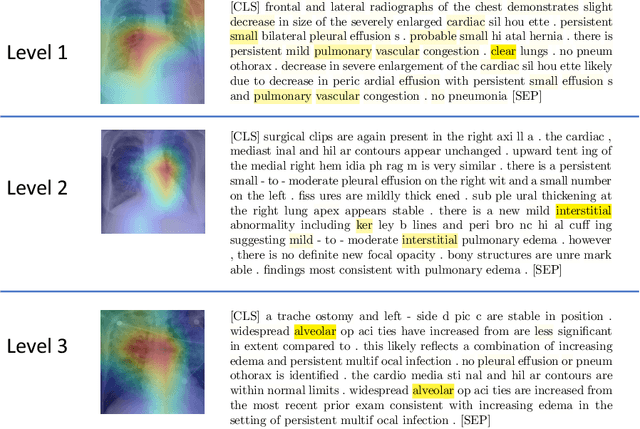
We propose and demonstrate a novel machine learning algorithm that assesses pulmonary edema severity from chest radiographs. While large publicly available datasets of chest radiographs and free-text radiology reports exist, only limited numerical edema severity labels can be extracted from radiology reports. This is a significant challenge in learning such models for image classification. To take advantage of the rich information present in the radiology reports, we develop a neural network model that is trained on both images and free-text to assess pulmonary edema severity from chest radiographs at inference time. Our experimental results suggest that the joint image-text representation learning improves the performance of pulmonary edema assessment compared to a supervised model trained on images only. We also show the use of the text for explaining the image classification by the joint model. To the best of our knowledge, our approach is the first to leverage free-text radiology reports for improving the image model performance in this application. Our code is available at https://github.com/RayRuizhiLiao/joint_chestxray.
Compact 3D Map-Based Monocular Localization Using Semantic Edge Alignment
Mar 27, 2021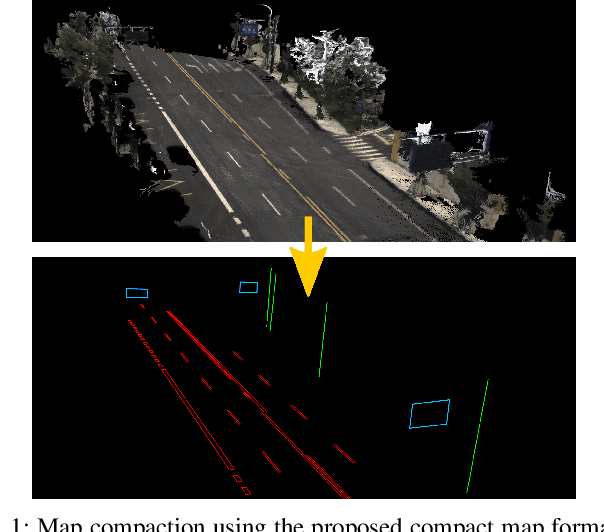
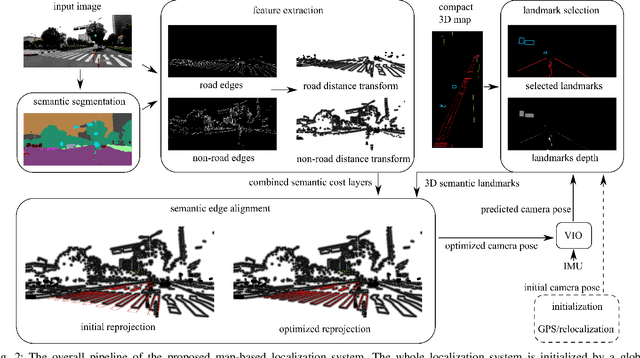

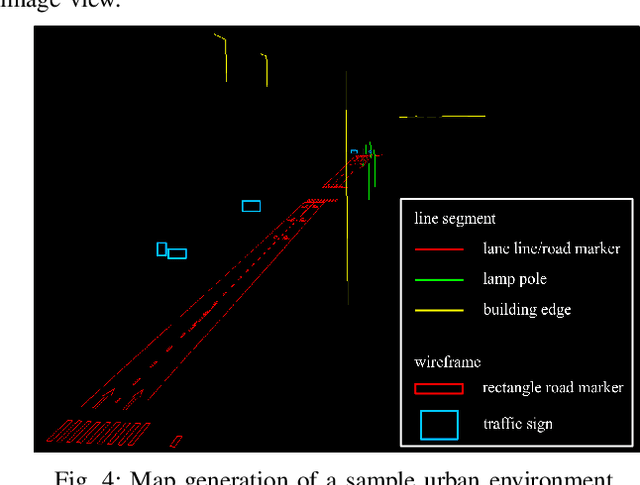
Accurate localization is fundamental to a variety of applications, such as navigation, robotics, autonomous driving, and Augmented Reality (AR). Different from incremental localization, global localization has no drift caused by error accumulation, which is desired in many application scenarios. In addition to GPS used in the open air, 3D maps are also widely used as alternative global localization references. In this paper, we propose a compact 3D map-based global localization system using a low-cost monocular camera and an IMU (Inertial Measurement Unit). The proposed compact map consists of two types of simplified elements with multiple semantic labels, which is well adaptive to various man-made environments like urban environments. Also, semantic edge features are used for the key image-map registration, which is robust against occlusion and long-term appearance changes in the environments. To further improve the localization performance, the key semantic edge alignment is formulated as an optimization problem based on initial poses predicted by an independent VIO (Visual-Inertial Odometry) module. The localization system is realized with modular design in real time. We evaluate the localization accuracy through real-world experimental results compared with ground truth, long-term localization performance is also demonstrated.
CapsField: Light Field-based Face and Expression Recognition in the Wild using Capsule Routing
Jan 10, 2021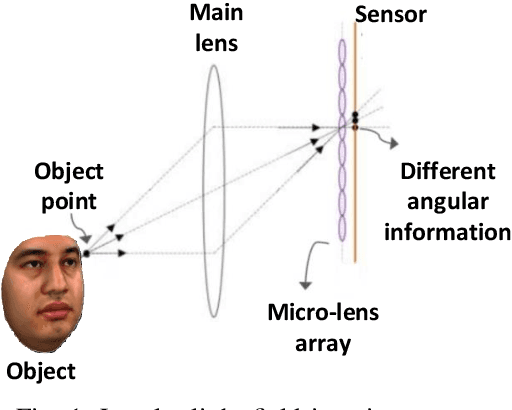
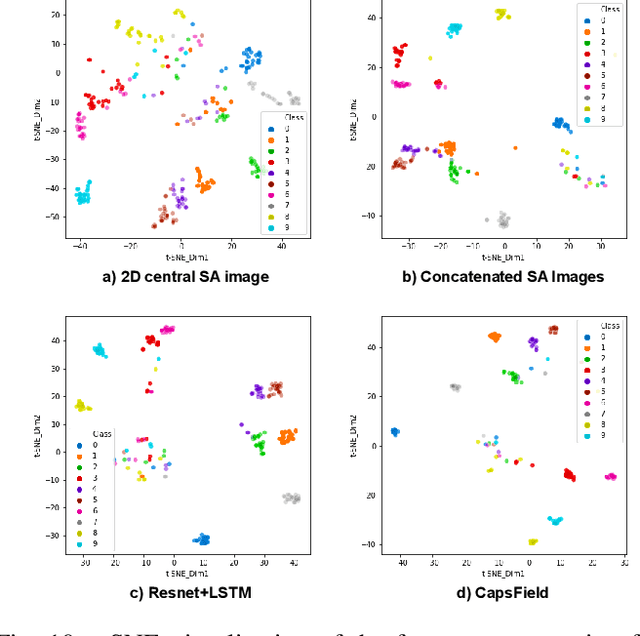
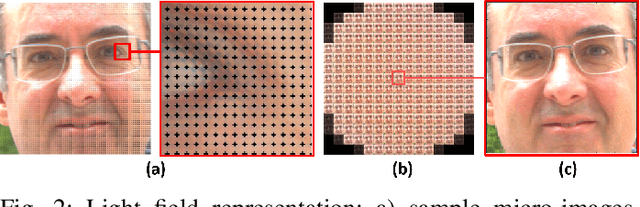
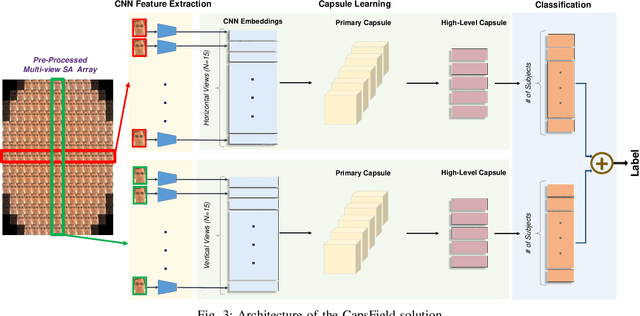
Light field (LF) cameras provide rich spatio-angular visual representations by sensing the visual scene from multiple perspectives and have recently emerged as a promising technology to boost the performance of human-machine systems such as biometrics and affective computing. Despite the significant success of LF representation for constrained facial image analysis, this technology has never been used for face and expression recognition in the wild. In this context, this paper proposes a new deep face and expression recognition solution, called CapsField, based on a convolutional neural network and an additional capsule network that utilizes dynamic routing to learn hierarchical relations between capsules. CapsField extracts the spatial features from facial images and learns the angular part-whole relations for a selected set of 2D sub-aperture images rendered from each LF image. To analyze the performance of the proposed solution in the wild, the first in the wild LF face dataset, along with a new complementary constrained face dataset captured from the same subjects recorded earlier have been captured and are made available. A subset of the in the wild dataset contains facial images with different expressions, annotated for usage in the context of face expression recognition tests. An extensive performance assessment study using the new datasets has been conducted for the proposed and relevant prior solutions, showing that the CapsField proposed solution achieves superior performance for both face and expression recognition tasks when compared to the state-of-the-art.
UDBNET: Unsupervised Document Binarization Network via Adversarial Game
Jul 14, 2020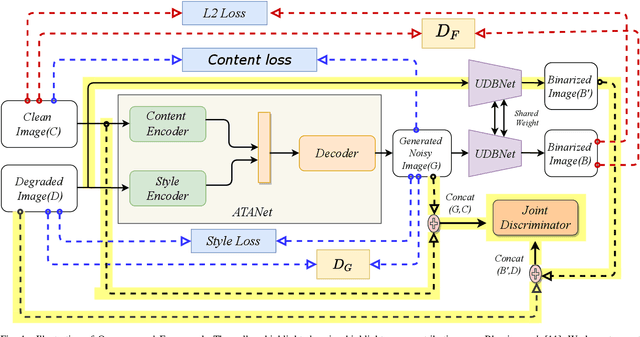


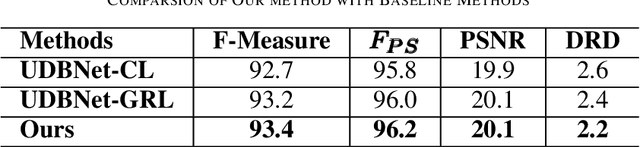
Degraded document image binarization is one of the most challenging tasks in the domain of document image analysis. In this paper, we present a novel approach towards document image binarization by introducing three-player min-max adversarial game. We train the network in an unsupervised setup by assuming that we do not have any paired-training data. In our approach, an Adversarial Texture Augmentation Network (ATANet) first superimposes the texture of a degraded reference image over a clean image. Later, the clean image along with its generated degraded version constitute the pseudo paired-data which is used to train the Unsupervised Document Binarization Network (UDBNet). Following this approach, we have enlarged the document binarization datasets as it generates multiple images having same content feature but different textual feature. These generated noisy images are then fed into the UDBNet to get back the clean version. The joint discriminator which is the third-player of our three-player min-max adversarial game tries to couple both the ATANet and UDBNet. The three-player min-max adversarial game stops, when the distributions modelled by the ATANet and the UDBNet align to the same joint distribution over time. Thus, the joint discriminator enforces the UDBNet to perform better on real degraded image. The experimental results indicate the superior performance of the proposed model over existing state-of-the-art algorithm on widely used DIBCO datasets. The source code of the proposed system is publicly available at https://github.com/VIROBO-15/UDBNET.
Two Novel Performance Improvements for Evolving CNN Topologies
Feb 10, 2021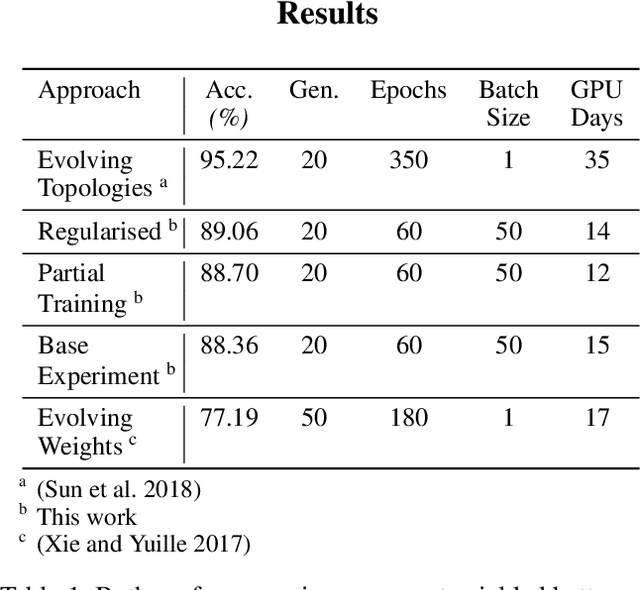
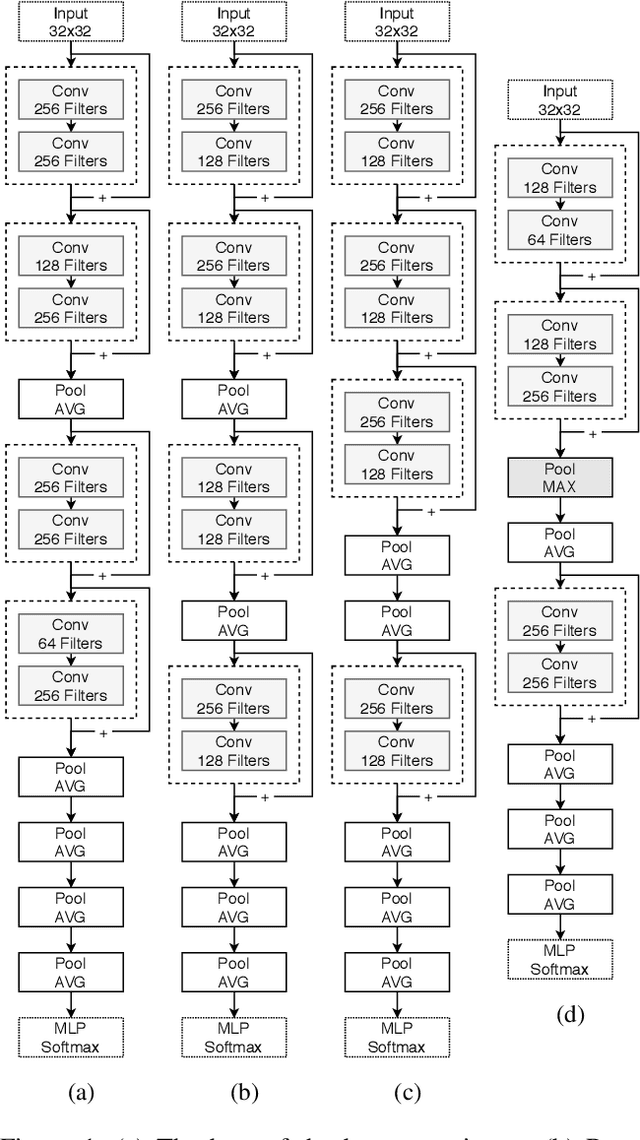
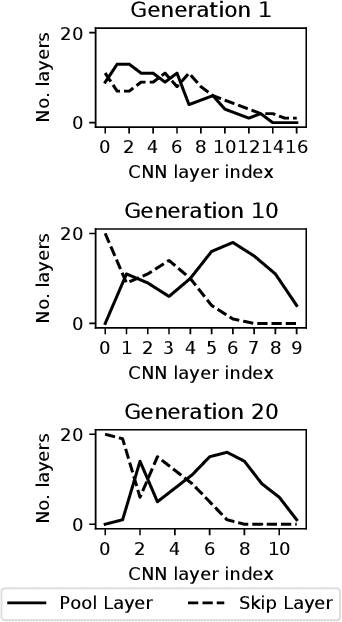
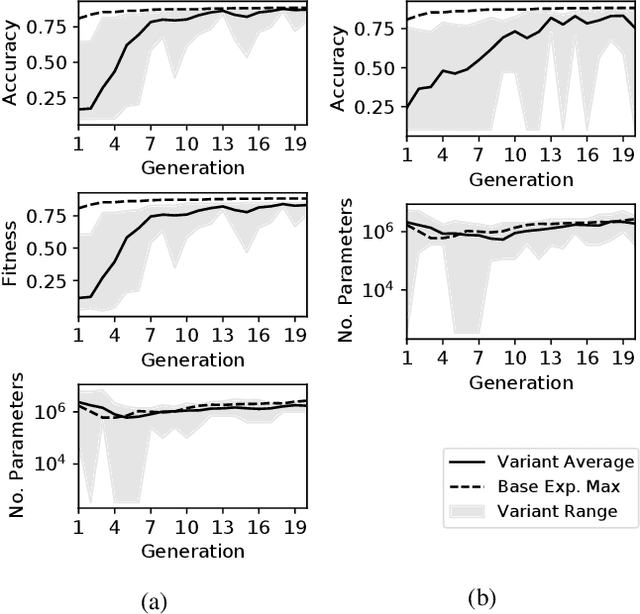
Convolutional Neural Networks (CNNs) are the state-of-the-art algorithms for the processing of images. However the configuration and training of these networks is a complex task requiring deep domain knowledge, experience and much trial and error. Using genetic algorithms, competitive CNN topologies for image recognition can be produced for any specific purpose, however in previous work this has come at high computational cost. In this work two novel approaches are presented to the utilisation of these algorithms, effective in reducing complexity and training time by nearly 20%. This is accomplished via regularisation directly on training time, and the use of partial training to enable early ranking of individual architectures. Both approaches are validated on the benchmark CIFAR10 data set, and maintain accuracy.
LUCES: A Dataset for Near-Field Point Light Source Photometric Stereo
Apr 27, 2021
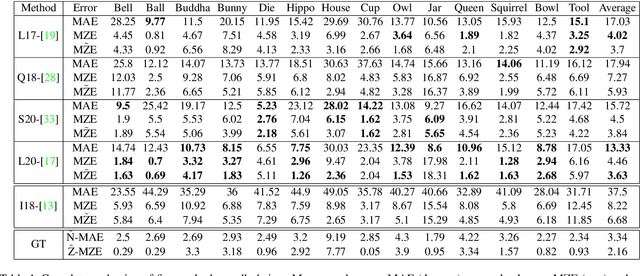


Three-dimensional reconstruction of objects from shading information is a challenging task in computer vision. As most of the approaches facing the Photometric Stereo problem use simplified far-field assumptions, real-world scenarios have essentially more complex physical effects that need to be handled for accurately reconstructing the 3D shape. An increasing number of methods have been proposed to address the problem when point light sources are assumed to be nearby the target object. The proximity of the light sources complicates the modeling of the image formation as the light behaviour requires non-linear parameterisation to describe its propagation and attenuation. To understand the capability of the approaches dealing with this near-field scenario, the literature till now has used synthetically rendered photometric images or minimal and very customised real-world data. In order to fill the gap in evaluating near-field photometric stereo methods, we introduce LUCES the first real-world 'dataset for near-fieLd point light soUrCe photomEtric Stereo' of 14 objects of a varying of materials. A device counting 52 LEDs has been designed to lit each object positioned 10 to 30 centimeters away from the camera. Together with the raw images, in order to evaluate the 3D reconstructions, the dataset includes both normal and depth maps for comparing different features of the retrieved 3D geometry. Furthermore, we evaluate the performance of the latest near-field Photometric Stereo algorithms on the proposed dataset to assess the SOTA method with respect to actual close range effects and object materials.
Thinking Deeply with Recurrence: Generalizing from Easy to Hard Sequential Reasoning Problems
Mar 17, 2021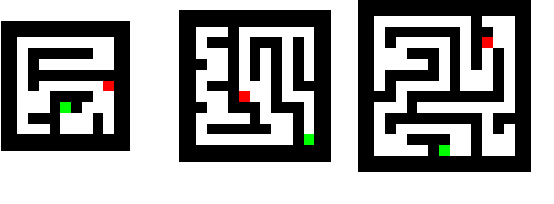
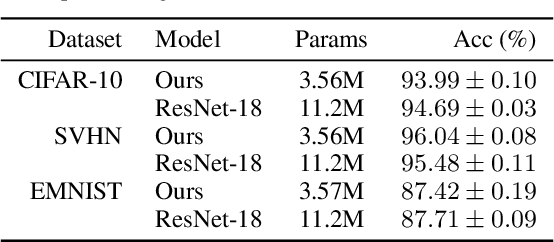
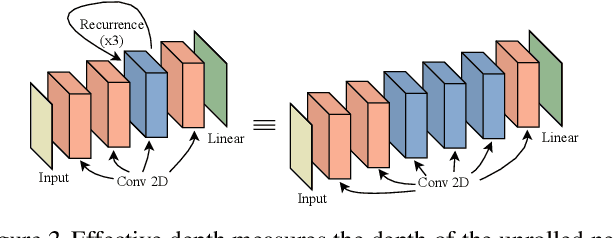

Deep neural networks are powerful machines for visual pattern recognition, but reasoning tasks that are easy for humans may still be difficult for neural models. Humans can extrapolate simple reasoning strategies to solve difficult problems using long sequences of abstract manipulations, i.e., harder problems are solved by thinking for longer. In contrast, the sequential computing budget of feed-forward networks is limited by their depth, and networks trained on simple problems have no way of extending their reasoning capabilities without retraining. In this work, we observe that recurrent networks have the uncanny ability to closely emulate the behavior of non-recurrent deep models, often doing so with far fewer parameters, on both image classification and maze solving tasks. We also explore whether recurrent networks can make the generalization leap from simple problems to hard problems simply by increasing the number of recurrent iterations used at test time. To this end, we show that recurrent networks that are trained to solve simple mazes with few recurrent steps can indeed solve much more complex problems simply by performing additional recurrences during inference.