 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Multiscale Image Denoising Algorithm Based On Dilated Residual Convolution Network
Dec 21, 2018
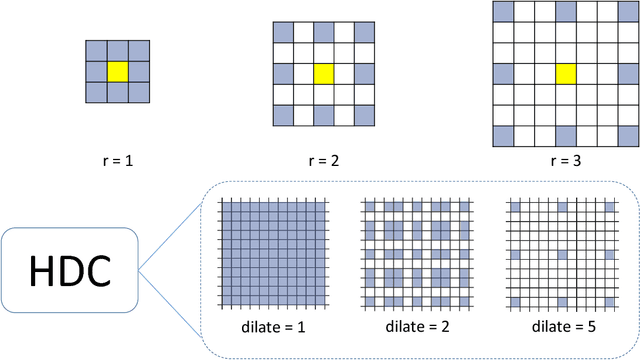

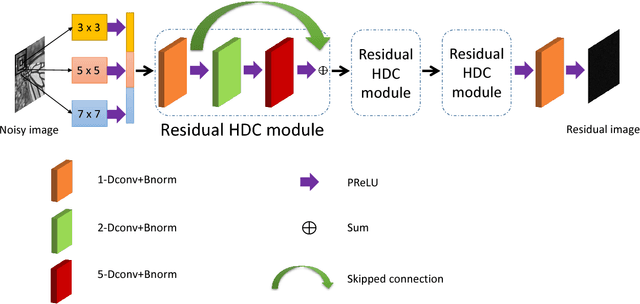
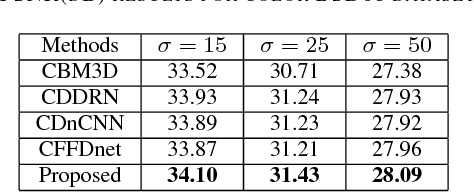
Image denoising is a classical problem in low level computer vision. Model-based optimization methods and deep learning approaches have been the two main strategies for solving the problem. Model-based optimization methods are flexible for handling different inverse problems but are usually time-consuming. In contrast, deep learning methods have fast testing speed but the performance of these CNNs is still inferior. To address this issue, here we propose a novel deep residual learning model that combines the dilated residual convolution and multi-scale convolution groups. Due to the complex patterns and structures of inside an image, the multiscale convolution group is utilized to learn those patterns and enlarge the receptive field. Specifically, the residual connection and batch normalization are utilized to speed up the training process and maintain the denoising performance. In order to decrease the gridding artifacts, we integrate the hybrid dilated convolution design into our model. To this end, this paper aims to train a lightweight and effective denoiser based on multiscale convolution group. Experimental results have demonstrated that the enhanced denoiser can not only achieve promising denoising results, but also become a strong competitor in practical application.
Weakly Supervised Instance Segmentation for Videos with Temporal Mask Consistency
Mar 23, 2021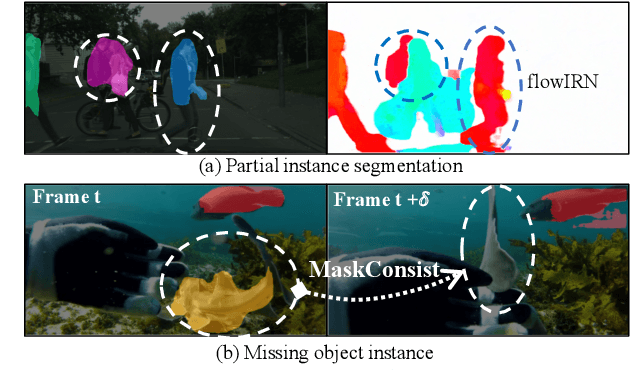
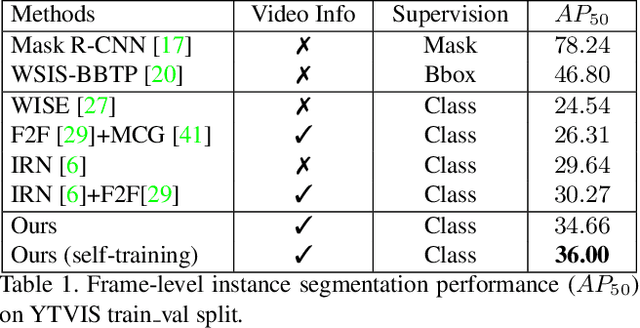
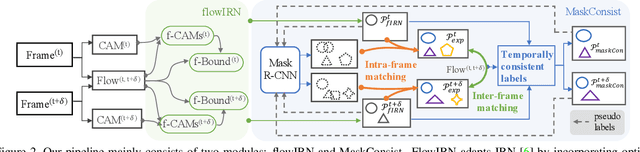
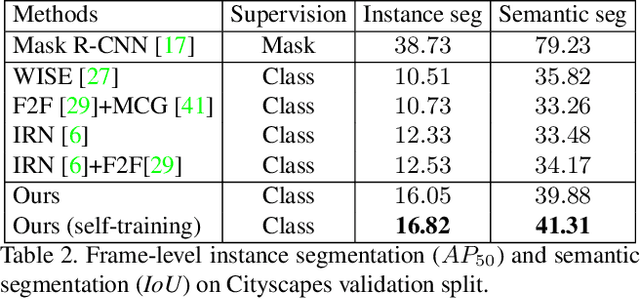
Weakly supervised instance segmentation reduces the cost of annotations required to train models. However, existing approaches which rely only on image-level class labels predominantly suffer from errors due to (a) partial segmentation of objects and (b) missing object predictions. We show that these issues can be better addressed by training with weakly labeled videos instead of images. In videos, motion and temporal consistency of predictions across frames provide complementary signals which can help segmentation. We are the first to explore the use of these video signals to tackle weakly supervised instance segmentation. We propose two ways to leverage this information in our model. First, we adapt inter-pixel relation network (IRN) to effectively incorporate motion information during training. Second, we introduce a new MaskConsist module, which addresses the problem of missing object instances by transferring stable predictions between neighboring frames during training. We demonstrate that both approaches together improve the instance segmentation metric $AP_{50}$ on video frames of two datasets: Youtube-VIS and Cityscapes by $5\%$ and $3\%$ respectively.
RTS3D: Real-time Stereo 3D Detection from 4D Feature-Consistency Embedding Space for Autonomous Driving
Dec 30, 2020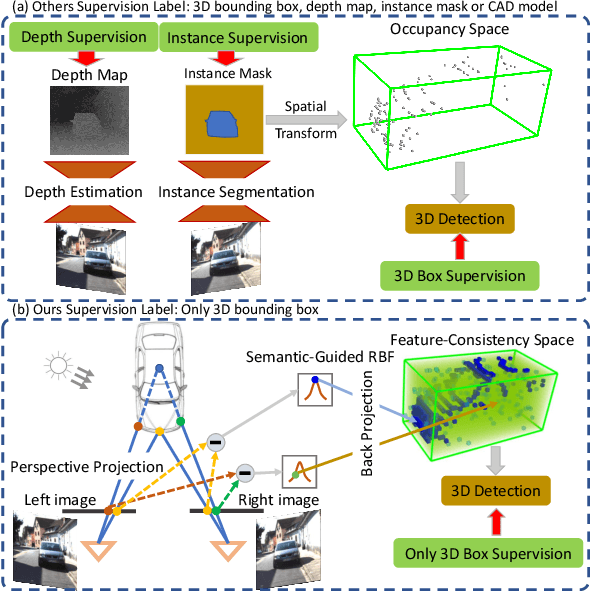

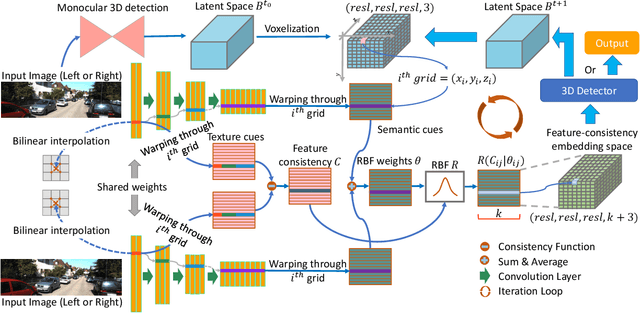
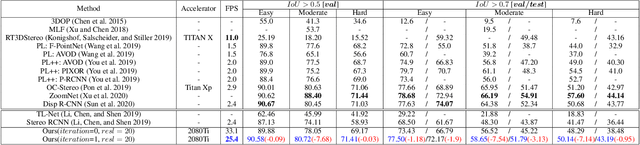
Although the recent image-based 3D object detection methods using Pseudo-LiDAR representation have shown great capabilities, a notable gap in efficiency and accuracy still exist compared with LiDAR-based methods. Besides, over-reliance on the stand-alone depth estimator, requiring a large number of pixel-wise annotations in the training stage and more computation in the inferencing stage, limits the scaling application in the real world. In this paper, we propose an efficient and accurate 3D object detection method from stereo images, named RTS3D. Different from the 3D occupancy space in the Pseudo-LiDAR similar methods, we design a novel 4D feature-consistent embedding (FCE) space as the intermediate representation of the 3D scene without depth supervision. The FCE space encodes the object's structural and semantic information by exploring the multi-scale feature consistency warped from stereo pair. Furthermore, a semantic-guided RBF (Radial Basis Function) and a structure-aware attention module are devised to reduce the influence of FCE space noise without instance mask supervision. Experiments on the KITTI benchmark show that RTS3D is the first true real-time system (FPS$>$24) for stereo image 3D detection meanwhile achieves $10\%$ improvement in average precision comparing with the previous state-of-the-art method. The code will be available at https://github.com/Banconxuan/RTS3D
Efficient Pedestrian Detection in Top-View Fisheye Images Using Compositions of Perspective View Patches
Sep 06, 2020
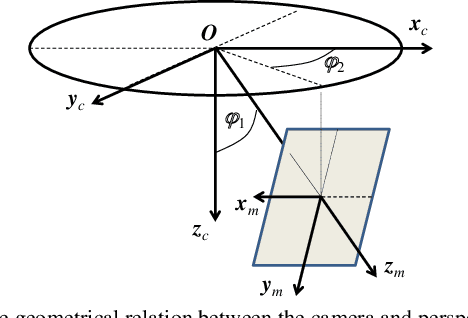

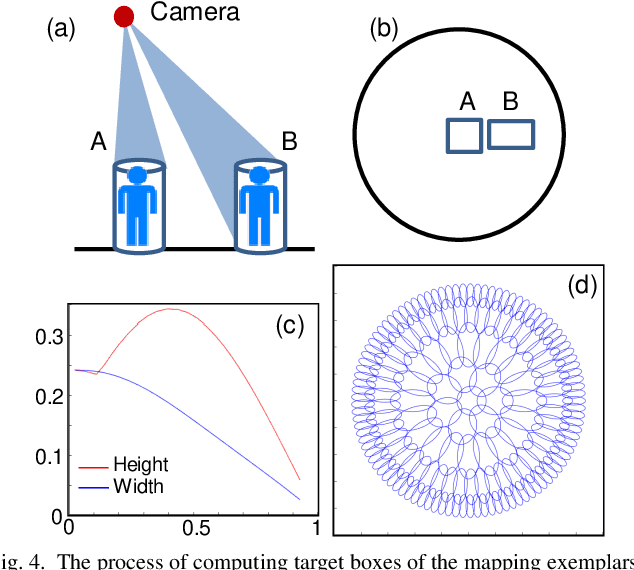
Pedestrian detection in images is a topic that has been studied extensively, but existing detectors designed for perspective images do not perform as successfully on images taken with top-view fisheye cameras, mainly due to the orientation variation of people in such images. In our proposed approach, several perspective views are generated from a fisheye image and then concatenated to form a composite image. As pedestrians in this composite image are more likely to be upright, existing detectors designed and trained for perspective images can be applied directly without additional training. We also describe a new method of mapping detection bounding boxes from the perspective views to the fisheye frame. The detection performance on several public datasets compare favorably with state-of-the-art results.
Deep Learning Segmentation of Complex Features in Atomic-Resolution Phase Contrast Transmission Electron Microscopy Images
Dec 09, 2020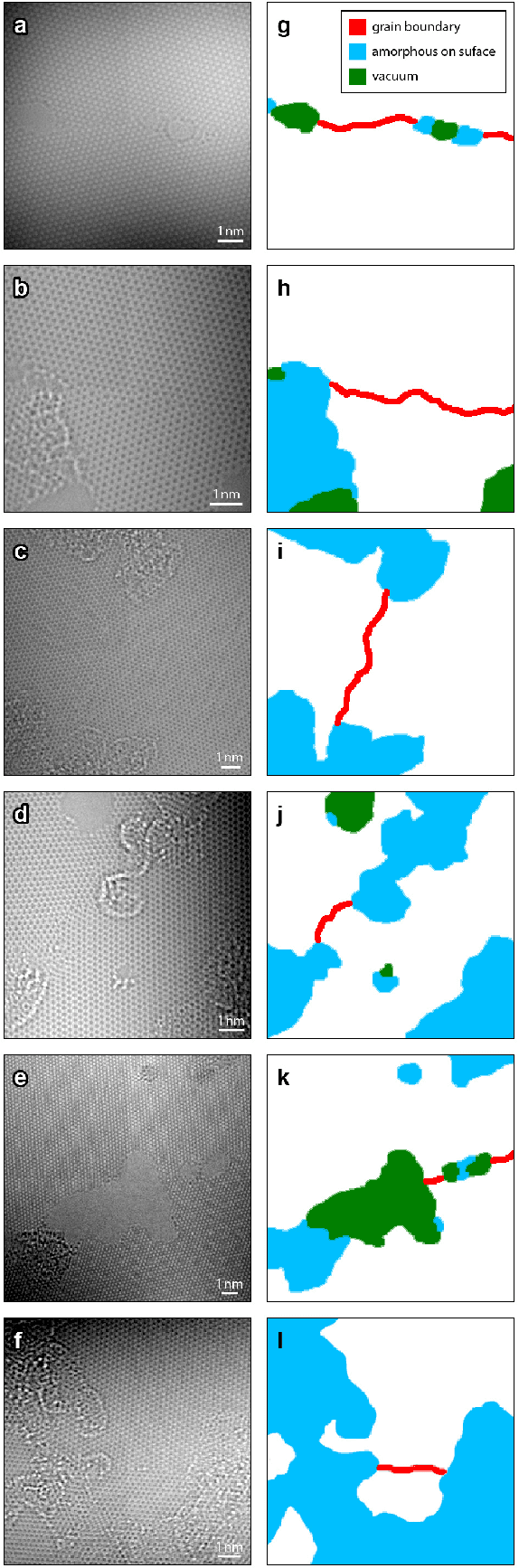

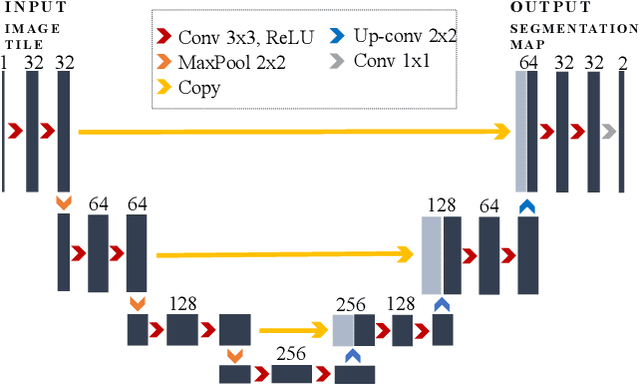

Phase contrast transmission electron microscopy (TEM) is a powerful tool for imaging the local atomic structure of materials. TEM has been used heavily in studies of defect structures of 2D materials such as monolayer graphene due to its high dose efficiency. However, phase contrast imaging can produce complex nonlinear contrast, even for weakly-scattering samples. It is therefore difficult to develop fully-automated analysis routines for phase contrast TEM studies using conventional image processing tools. For automated analysis of large sample regions of graphene, one of the key problems is segmentation between the structure of interest and unwanted structures such as surface contaminant layers. In this study, we compare the performance of a conventional Bragg filtering method to a deep learning routine based on the U-Net architecture. We show that the deep learning method is more general, simpler to apply in practice, and produces more accurate and robust results than the conventional algorithm. We provide easily-adaptable source code for all results in this paper, and discuss potential applications for deep learning in fully-automated TEM image analysis.
Efficient embedding network for 3D brain tumor segmentation
Nov 22, 2020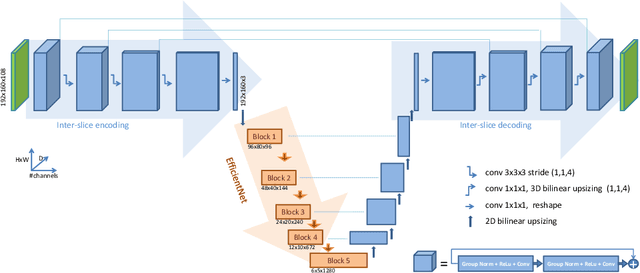
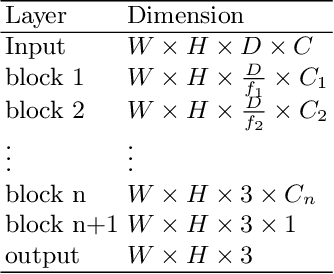
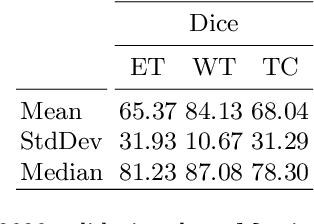
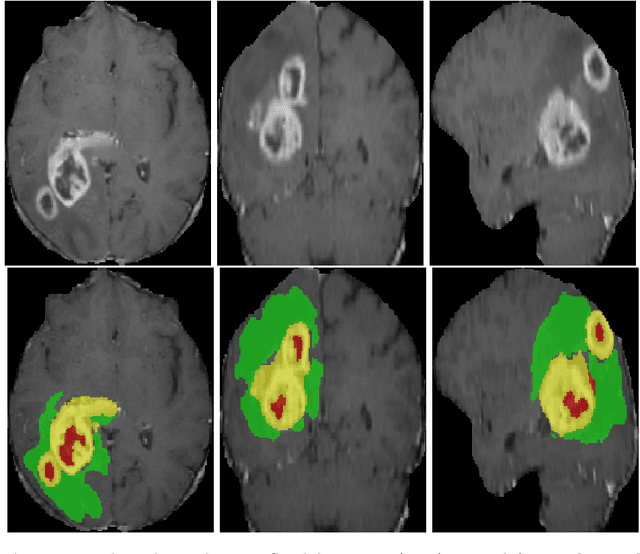
3D medical image processing with deep learning greatly suffers from a lack of data. Thus, studies carried out in this field are limited compared to works related to 2D natural image analysis, where very large datasets exist. As a result, powerful and efficient 2D convolutional neural networks have been developed and trained. In this paper, we investigate a way to transfer the performance of a two-dimensional classiffication network for the purpose of three-dimensional semantic segmentation of brain tumors. We propose an asymmetric U-Net network by incorporating the EfficientNet model as part of the encoding branch. As the input data is in 3D, the first layers of the encoder are devoted to the reduction of the third dimension in order to fit the input of the EfficientNet network. Experimental results on validation and test data from the BraTS 2020 challenge demonstrate that the proposed method achieve promising performance.
* Multimodal Brain Tumor Segmentation Challenge 2020
OCID-Ref: A 3D Robotic Dataset with Embodied Language for Clutter Scene Grounding
Mar 13, 2021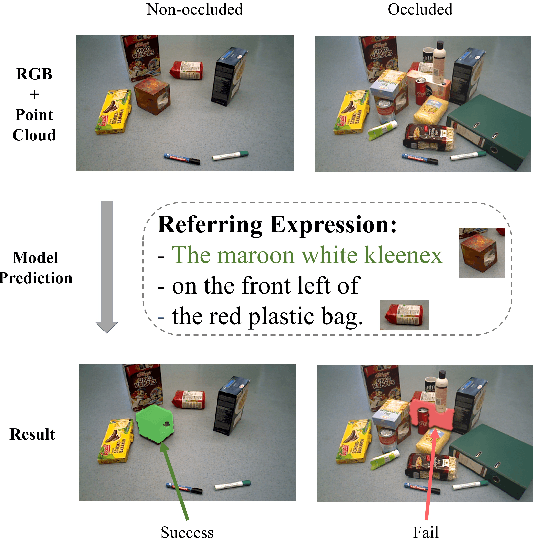

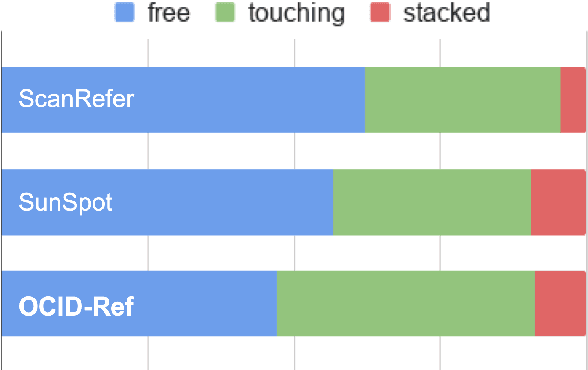

To effectively apply robots in working environments and assist humans, it is essential to develop and evaluate how visual grounding (VG) can affect machine performance on occluded objects. However, current VG works are limited in working environments, such as offices and warehouses, where objects are usually occluded due to space utilization issues. In our work, we propose a novel OCID-Ref dataset featuring a referring expression segmentation task with referring expressions of occluded objects. OCID-Ref consists of 305,694 referring expressions from 2,300 scenes with providing RGB image and point cloud inputs. To resolve challenging occlusion issues, we argue that it's crucial to take advantage of both 2D and 3D signals to resolve challenging occlusion issues. Our experimental results demonstrate the effectiveness of aggregating 2D and 3D signals but referring to occluded objects still remains challenging for the modern visual grounding systems. OCID-Ref is publicly available at https://github.com/lluma/OCID-Ref
Deep Multi-path Network Integrating Incomplete Biomarker and Chest CT Data for Evaluating Lung Cancer Risk
Oct 19, 2020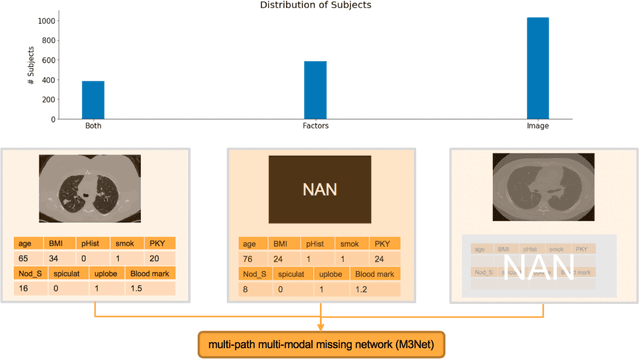
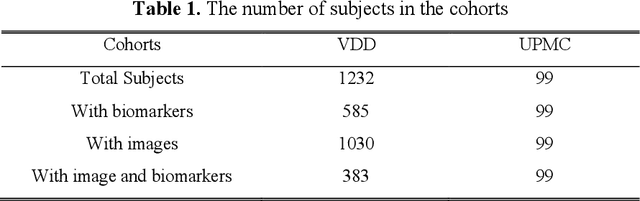
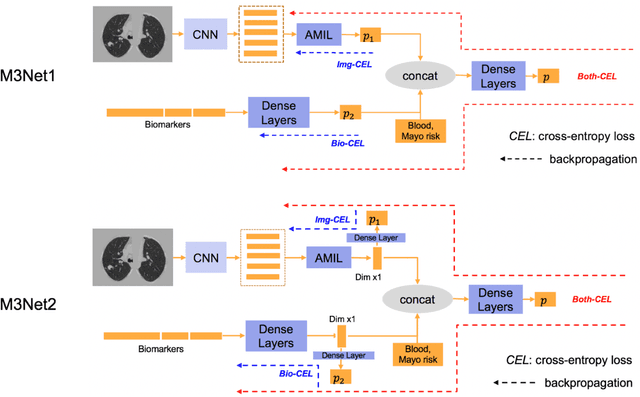
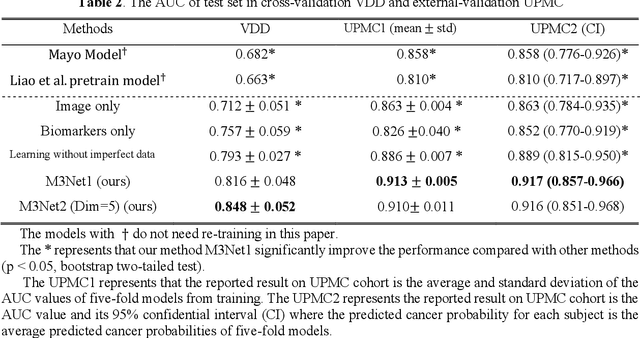
Clinical data elements (CDEs) (e.g., age, smoking history), blood markers and chest computed tomography (CT) structural features have been regarded as effective means for assessing lung cancer risk. These independent variables can provide complementary information and we hypothesize that combining them will improve the prediction accuracy. In practice, not all patients have all these variables available. In this paper, we propose a new network design, termed as multi-path multi-modal missing network (M3Net), to integrate the multi-modal data (i.e., CDEs, biomarker and CT image) considering missing modality with multiple paths neural network. Each path learns discriminative features of one modality, and different modalities are fused in a second stage for an integrated prediction. The network can be trained end-to-end with both medical image features and CDEs/biomarkers, or make a prediction with single modality. We evaluate M3Net with datasets including three sites from the Consortium for Molecular and Cellular Characterization of Screen-Detected Lesions (MCL) project. Our method is cross validated within a cohort of 1291 subjects (383 subjects with complete CDEs/biomarkers and CT images), and externally validated with a cohort of 99 subjects (99 with complete CDEs/biomarkers and CT images). Both cross-validation and external-validation results show that combining multiple modality significantly improves the predicting performance of single modality. The results suggest that integrating subjects with missing either CDEs/biomarker or CT imaging features can contribute to the discriminatory power of our model (p < 0.05, bootstrap two-tailed test). In summary, the proposed M3Net framework provides an effective way to integrate image and non-image data in the context of missing information.
IR2VI: Enhanced Night Environmental Perception by Unsupervised Thermal Image Translation
Jun 25, 2018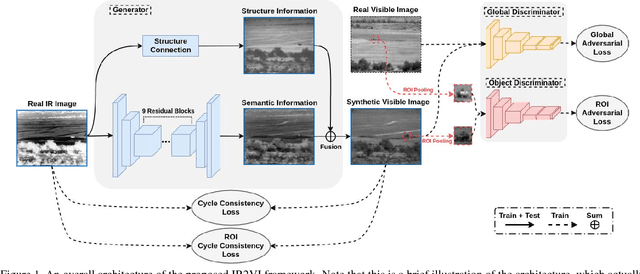



Context enhancement is critical for night vision (NV) applications, especially for the dark night situation without any artificial lights. In this paper, we present the infrared-to-visual (IR2VI) algorithm, a novel unsupervised thermal-to-visible image translation framework based on generative adversarial networks (GANs). IR2VI is able to learn the intrinsic characteristics from VI images and integrate them into IR images. Since the existing unsupervised GAN-based image translation approaches face several challenges, such as incorrect mapping and lack of fine details, we propose a structure connection module and a region-of-interest (ROI) focal loss method to address the current limitations. Experimental results show the superiority of the IR2VI algorithm over baseline methods.
Spectral Machine Learning for Pancreatic Mass Imaging Classification
May 03, 2021
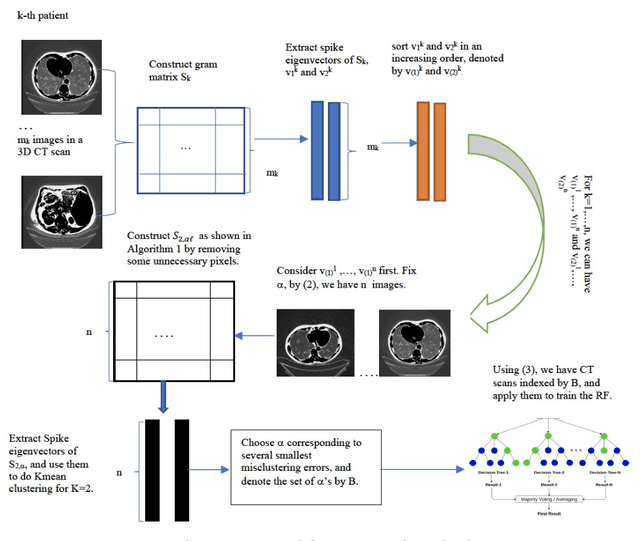
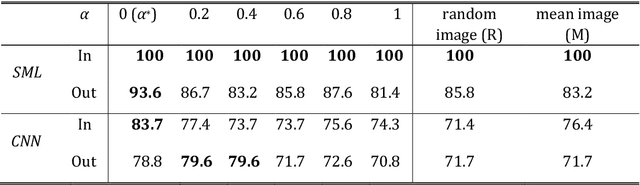
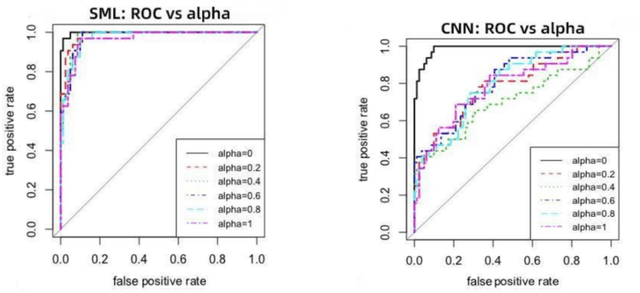
We present a novel spectral machine learning (SML) method in screening for pancreatic mass using CT imaging. Our algorithm is trained with approximately 30,000 images from 250 patients (50 patients with normal pancreas and 200 patients with abnormal pancreas findings) based on public data sources. A test accuracy of 94.6 percents was achieved in the out-of-sample diagnosis classification based on a total of approximately 15,000 images from 113 patients, whereby 26 out of 32 patients with normal pancreas and all 81 patients with abnormal pancreas findings were correctly diagnosed. SML is able to automatically choose fundamental images (on average 5 or 9 images for each patient) in the diagnosis classification and achieve the above mentioned accuracy. The computational time is 75 seconds for diagnosing 113 patients in a laptop with standard CPU running environment. Factors that influenced high performance of a well-designed integration of spectral learning and machine learning included: 1) use of eigenvectors corresponding to several of the largest eigenvalues of sample covariance matrix (spike eigenvectors) to choose input attributes in classification training, taking into account only the fundamental information of the raw images with less noise; 2) removal of irrelevant pixels based on mean-level spectral test to lower the challenges of memory capacity and enhance computational efficiency while maintaining superior classification accuracy; 3) adoption of state-of-the-art machine learning classification, gradient boosting and random forest. Our methodology showcases practical utility and improved accuracy of image diagnosis in pancreatic mass screening in the era of AI.