 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Task-driven Semantic Coding via Reinforcement Learning
Jun 07, 2021
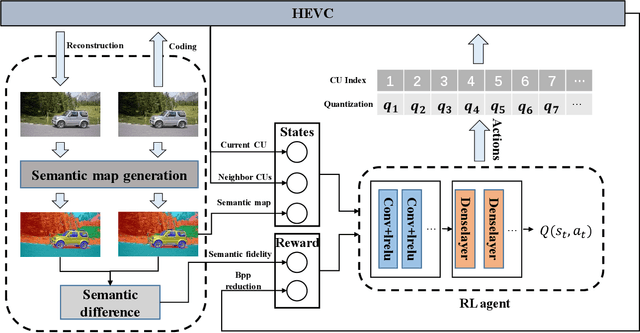
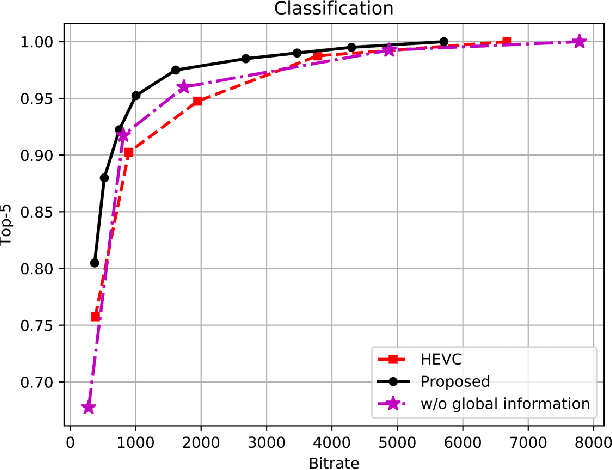
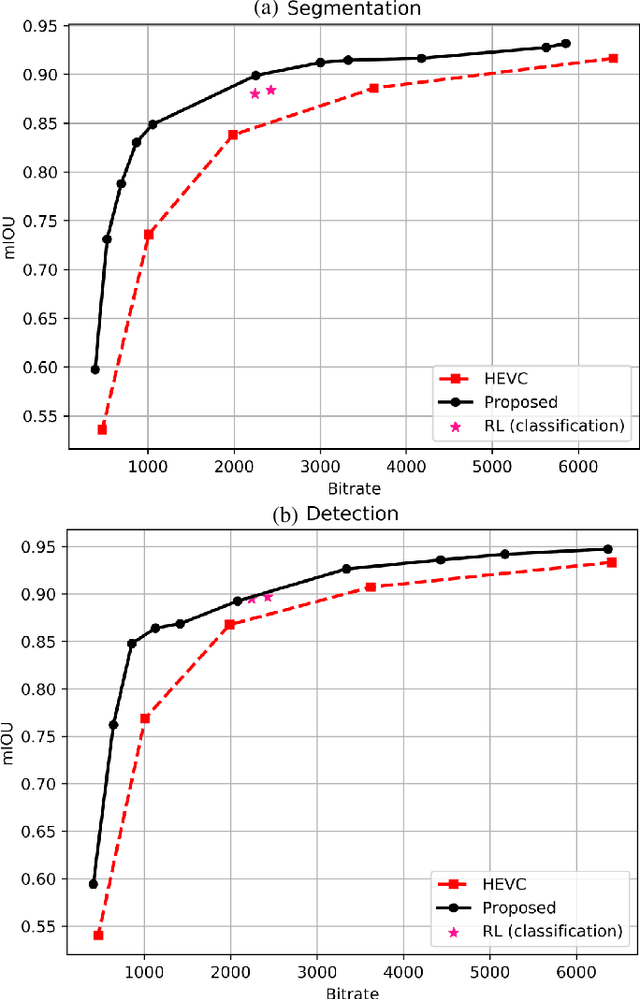
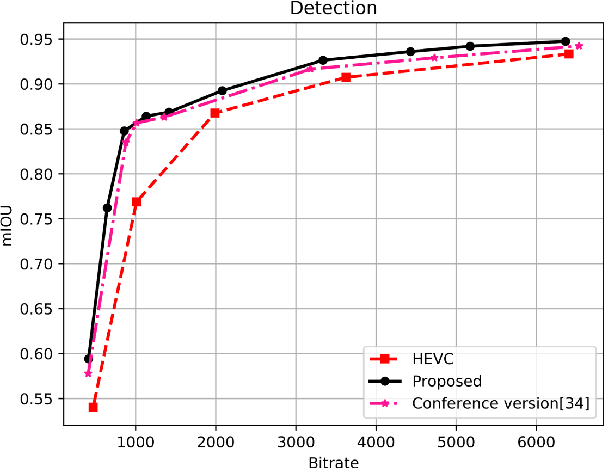
Task-driven semantic video/image coding has drawn considerable attention with the development of intelligent media applications, such as license plate detection, face detection, and medical diagnosis, which focuses on maintaining the semantic information of videos/images. Deep neural network (DNN)-based codecs have been studied for this purpose due to their inherent end-to-end optimization mechanism. However, the traditional hybrid coding framework cannot be optimized in an end-to-end manner, which makes task-driven semantic fidelity metric unable to be automatically integrated into the rate-distortion optimization process. Therefore, it is still attractive and challenging to implement task-driven semantic coding with the traditional hybrid coding framework, which should still be widely used in practical industry for a long time. To solve this challenge, we design semantic maps for different tasks to extract the pixelwise semantic fidelity for videos/images. Instead of directly integrating the semantic fidelity metric into traditional hybrid coding framework, we implement task-driven semantic coding by implementing semantic bit allocation based on reinforcement learning (RL). We formulate the semantic bit allocation problem as a Markov decision process (MDP) and utilize one RL agent to automatically determine the quantization parameters (QPs) for different coding units (CUs) according to the task-driven semantic fidelity metric. Extensive experiments on different tasks, such as classification, detection and segmentation, have demonstrated the superior performance of our approach by achieving an average bitrate saving of 34.39% to 52.62% over the High Efficiency Video Coding (H.265/HEVC) anchor under equivalent task-related semantic fidelity.
A Pipeline for Vision-Based On-Orbit Proximity Operations Using Deep Learning and Synthetic Imagery
Jan 14, 2021
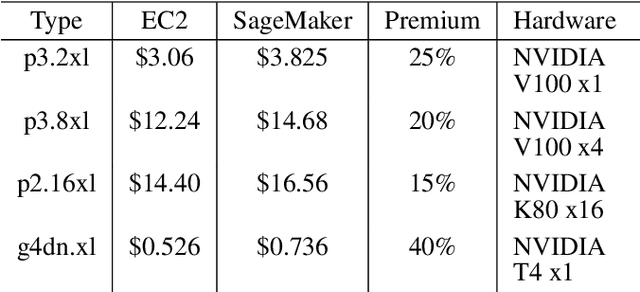


Deep learning has become the gold standard for image processing over the past decade. Simultaneously, we have seen growing interest in orbital activities such as satellite servicing and debris removal that depend on proximity operations between spacecraft. However, two key challenges currently pose a major barrier to the use of deep learning for vision-based on-orbit proximity operations. Firstly, efficient implementation of these techniques relies on an effective system for model development that streamlines data curation, training, and evaluation. Secondly, a scarcity of labeled training data (images of a target spacecraft) hinders creation of robust deep learning models. This paper presents an open-source deep learning pipeline, developed specifically for on-orbit visual navigation applications, that addresses these challenges. The core of our work consists of two custom software tools built on top of a cloud architecture that interconnects all stages of the model development process. The first tool leverages Blender, an open-source 3D graphics toolset, to generate labeled synthetic training data with configurable model poses (positions and orientations), lighting conditions, backgrounds, and commonly observed in-space image aberrations. The second tool is a plugin-based framework for effective dataset curation and model training; it provides common functionality like metadata generation and remote storage access to all projects while giving complete independence to project-specific code. Time-consuming, graphics-intensive processes such as synthetic image generation and model training run on cloud-based computational resources which scale to any scope and budget and allow development of even the largest datasets and models from any machine. The presented system has been used in the Texas Spacecraft Laboratory with marked benefits in development speed and quality.
MedAL: Deep Active Learning Sampling Method for Medical Image Analysis
Sep 28, 2018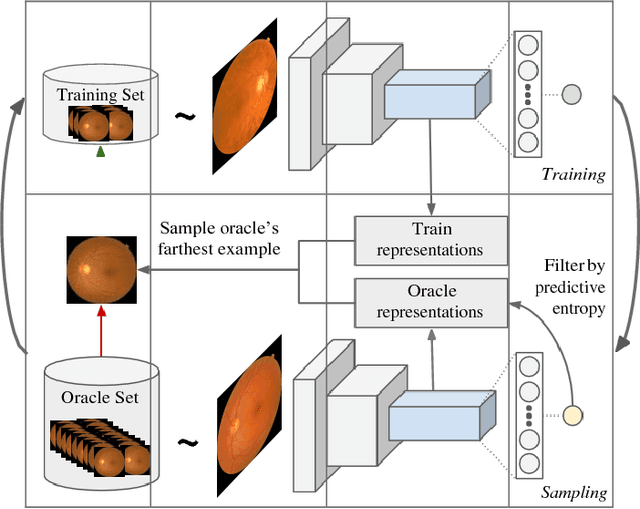
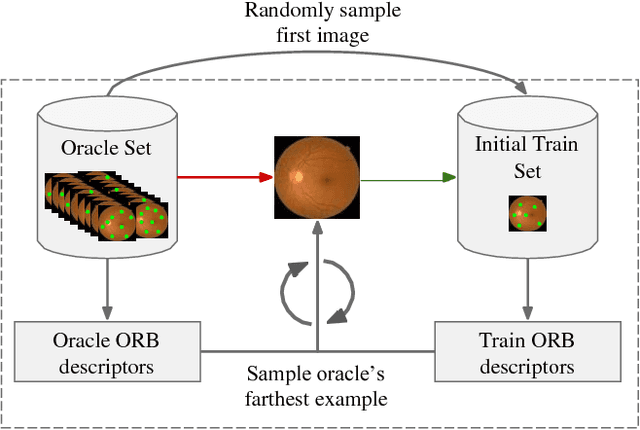
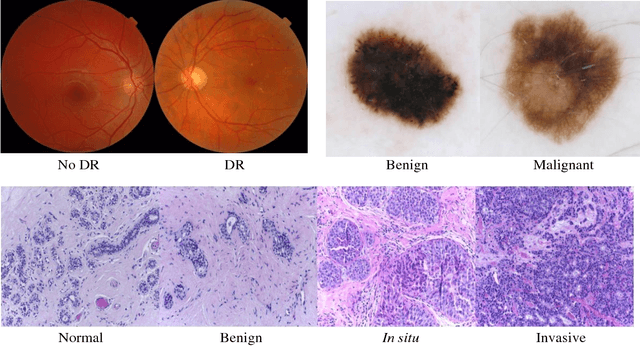
Deep learning models have been successfully used in medical image analysis problems but they require a large amount of labeled images to obtain good performance.Deep learning models have been successfully used in medical image analysis problems but they require a large amount of labeled images to obtain good performance. However, such large labeled datasets are costly to acquire. Active learning techniques can be used to minimize the number of required training labels while maximizing the model's performance.In this work, we propose a novel sampling method that queries the unlabeled examples that maximize the average distance to all training set examples in a learned feature space. We then extend our sampling method to define a better initial training set, without the need for a trained model, by using ORB feature descriptors. We validate MedAL on 3 medical image datasets and show that our method is robust to different dataset properties. MedAL is also efficient, achieving 80% accuracy on the task of Diabetic Retinopathy detection using only 425 labeled images, corresponding to a 32% reduction in the number of required labeled examples compared to the standard uncertainty sampling technique, and a 40% reduction compared to random sampling.
Learning Local Distortion Visibility From Image Quality Data-sets
Mar 11, 2018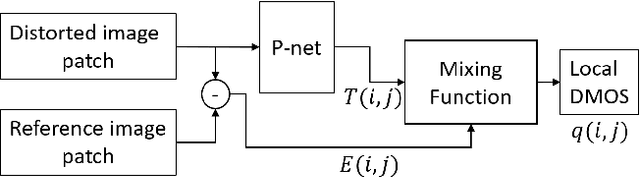
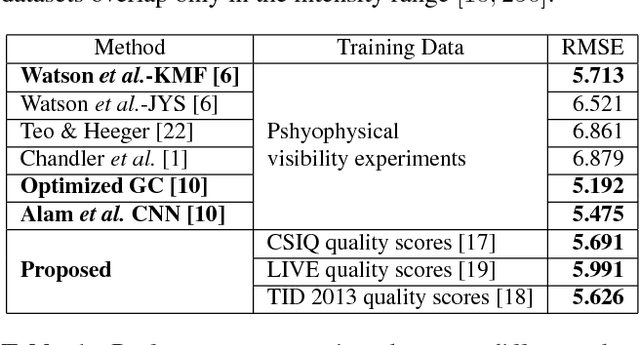
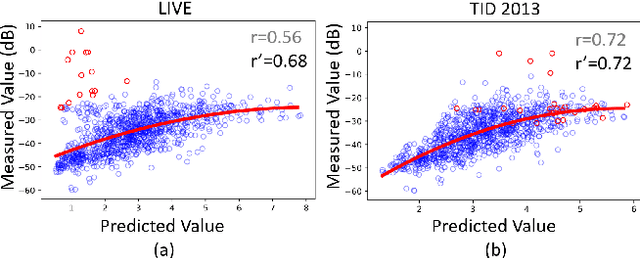
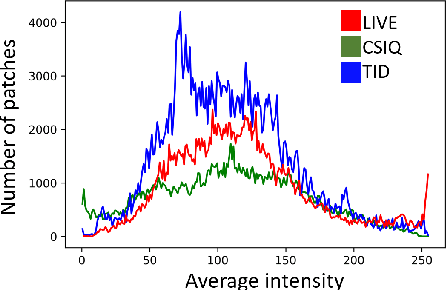
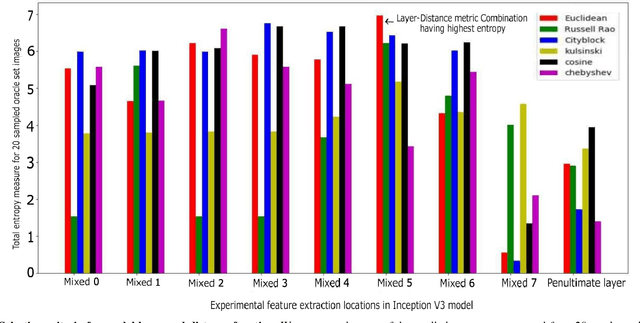
Accurate prediction of local distortion visibility thresholds is critical in many image and video processing applications. Existing methods require an accurate modeling of the human visual system, and are derived through pshycophysical experiments with simple, artificial stimuli. These approaches, however, are difficult to generalize to natural images with complex types of distortion. In this paper, we explore a different perspective, and we investigate whether it is possible to learn local distortion visibility from image quality scores. We propose a convolutional neural network based optimization framework to infer local detection thresholds in a distorted image. Our model is trained on multiple quality datasets, and the results are correlated with empirical visibility thresholds collected on complex stimuli in a recent study. Our results are comparable to state-of-the-art mathematical models that were trained on phsycovisual data directly. This suggests that it is possible to predict psychophysical phenomena from visibility information embedded in image quality scores.
Look here! A parametric learning based approach to redirect visual attention
Aug 12, 2020

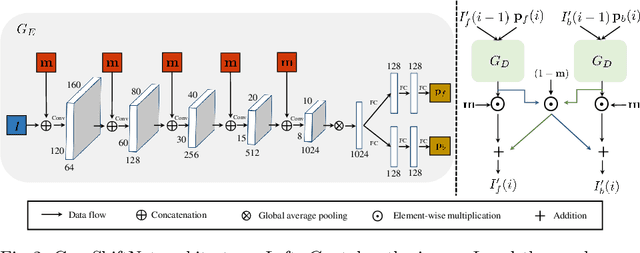
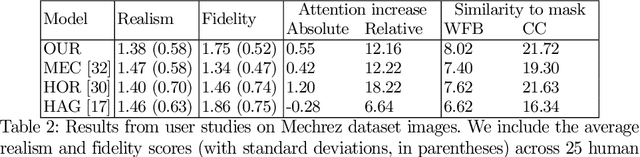
Across photography, marketing, and website design, being able to direct the viewer's attention is a powerful tool. Motivated by professional workflows, we introduce an automatic method to make an image region more attention-capturing via subtle image edits that maintain realism and fidelity to the original. From an input image and a user-provided mask, our GazeShiftNet model predicts a distinct set of global parametric transformations to be applied to the foreground and background image regions separately. We present the results of quantitative and qualitative experiments that demonstrate improvements over prior state-of-the-art. In contrast to existing attention shifting algorithms, our global parametric approach better preserves image semantics and avoids typical generative artifacts. Our edits enable inference at interactive rates on any image size, and easily generalize to videos. Extensions of our model allow for multi-style edits and the ability to both increase and attenuate attention in an image region. Furthermore, users can customize the edited images by dialing the edits up or down via interpolations in parameter space. This paper presents a practical tool that can simplify future image editing pipelines.
Learning Equivariant Representations
Dec 04, 2020
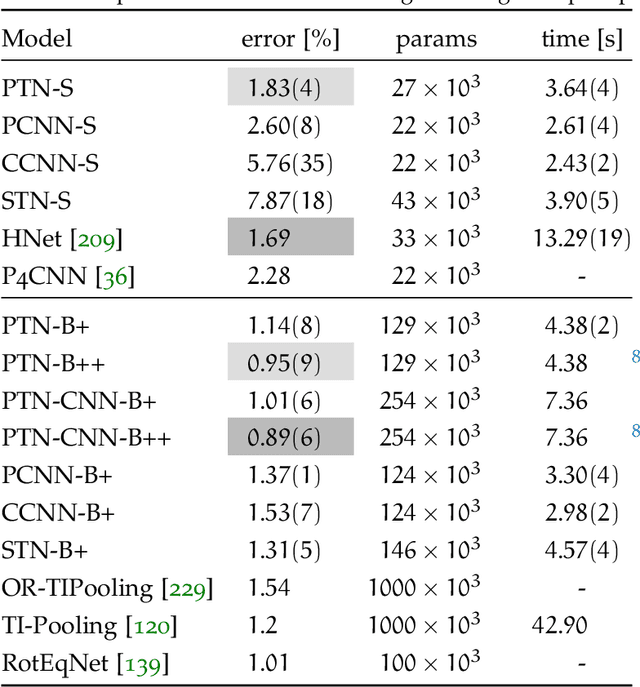
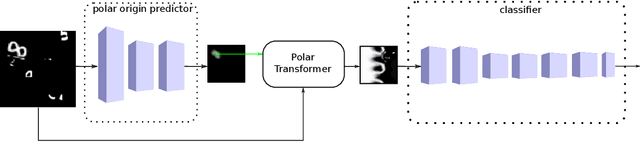
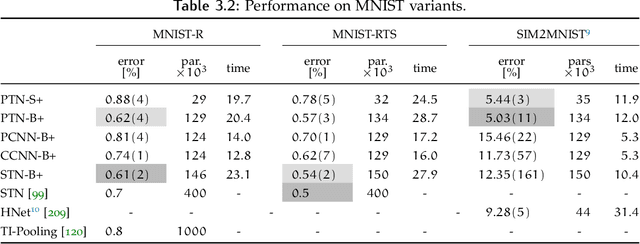
State-of-the-art deep learning systems often require large amounts of data and computation. For this reason, leveraging known or unknown structure of the data is paramount. Convolutional neural networks (CNNs) are successful examples of this principle, their defining characteristic being the shift-equivariance. By sliding a filter over the input, when the input shifts, the response shifts by the same amount, exploiting the structure of natural images where semantic content is independent of absolute pixel positions. This property is essential to the success of CNNs in audio, image and video recognition tasks. In this thesis, we extend equivariance to other kinds of transformations, such as rotation and scaling. We propose equivariant models for different transformations defined by groups of symmetries. The main contributions are (i) polar transformer networks, achieving equivariance to the group of similarities on the plane, (ii) equivariant multi-view networks, achieving equivariance to the group of symmetries of the icosahedron, (iii) spherical CNNs, achieving equivariance to the continuous 3D rotation group, (iv) cross-domain image embeddings, achieving equivariance to 3D rotations for 2D inputs, and (v) spin-weighted spherical CNNs, generalizing the spherical CNNs and achieving equivariance to 3D rotations for spherical vector fields. Applications include image classification, 3D shape classification and retrieval, panoramic image classification and segmentation, shape alignment and pose estimation. What these models have in common is that they leverage symmetries in the data to reduce sample and model complexity and improve generalization performance. The advantages are more significant on (but not limited to) challenging tasks where data is limited or input perturbations such as arbitrary rotations are present.
Reinforced Attention for Few-Shot Learning and Beyond
Apr 09, 2021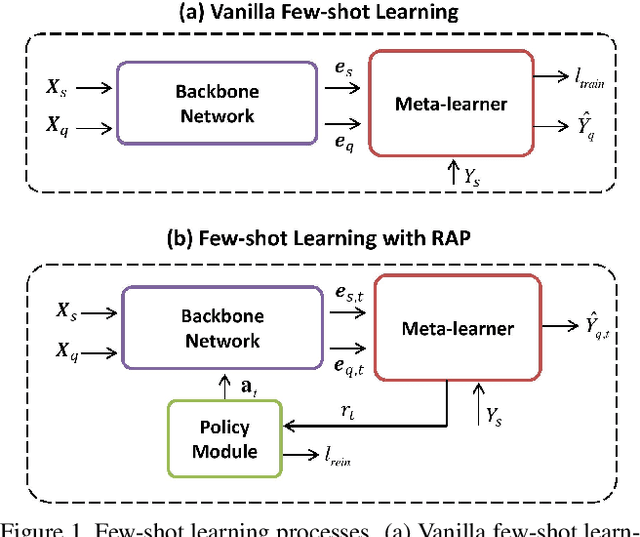
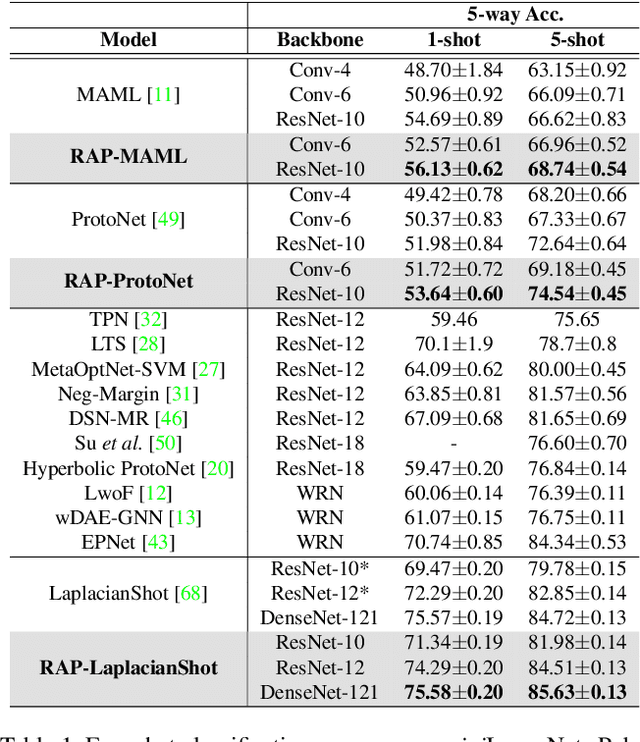
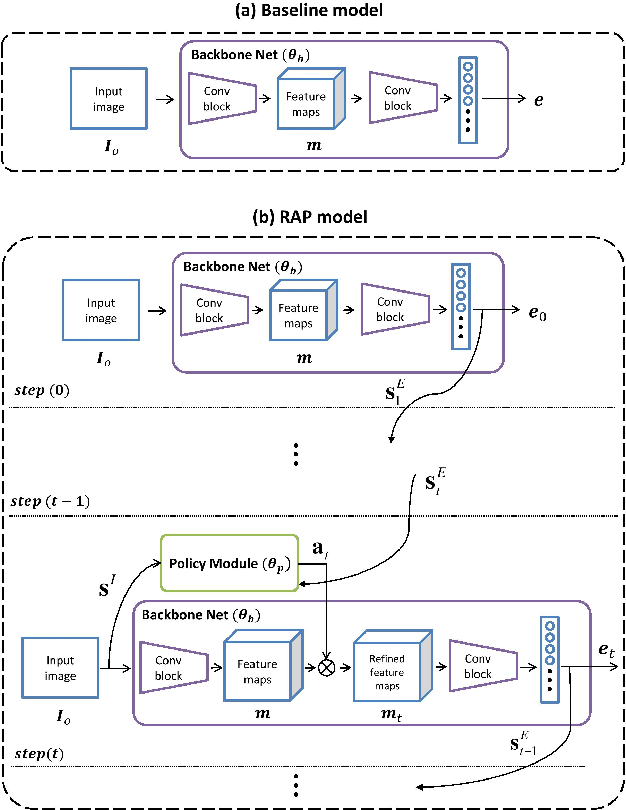
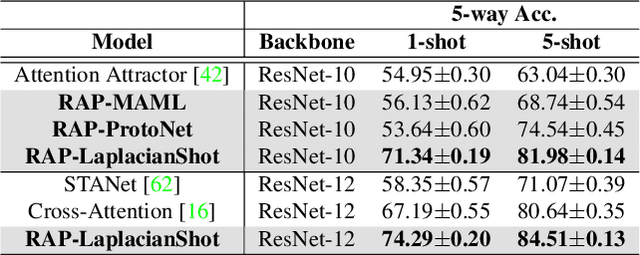
Few-shot learning aims to correctly recognize query samples from unseen classes given a limited number of support samples, often by relying on global embeddings of images. In this paper, we propose to equip the backbone network with an attention agent, which is trained by reinforcement learning. The policy gradient algorithm is employed to train the agent towards adaptively localizing the representative regions on feature maps over time. We further design a reward function based on the prediction of the held-out data, thus helping the attention mechanism to generalize better across the unseen classes. The extensive experiments show, with the help of the reinforced attention, that our embedding network has the capability to progressively generate a more discriminative representation in few-shot learning. Moreover, experiments on the task of image classification also show the effectiveness of the proposed design.
Image Super-Resolution Using Attention Based DenseNet with Residual Deconvolution
Jul 03, 2019
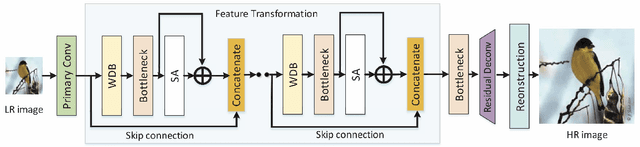
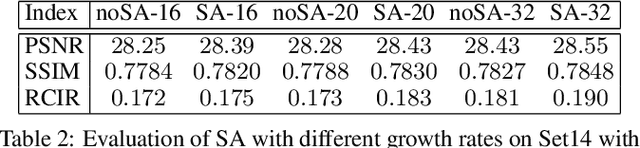
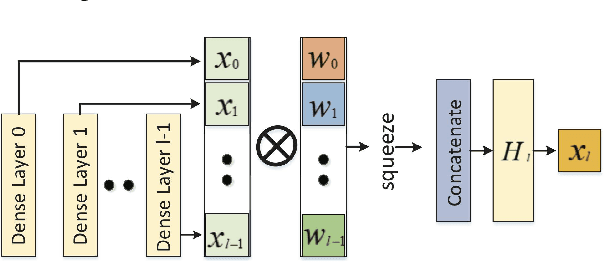
Image super-resolution is a challenging task and has attracted increasing attention in research and industrial communities. In this paper, we propose a novel end-to-end Attention-based DenseNet with Residual Deconvolution named as ADRD. In our ADRD, a weighted dense block, in which the current layer receives weighted features from all previous levels, is proposed to capture valuable features rely in dense layers adaptively. And a novel spatial attention module is presented to generate a group of attentive maps for emphasizing informative regions. In addition, we design an innovative strategy to upsample residual information via the deconvolution layer, so that the high-frequency details can be accurately upsampled. Extensive experiments conducted on publicly available datasets demonstrate the promising performance of the proposed ADRD against the state-of-the-arts, both quantitatively and qualitatively.
Dynamic Game Theoretic Neural Optimizer
May 08, 2021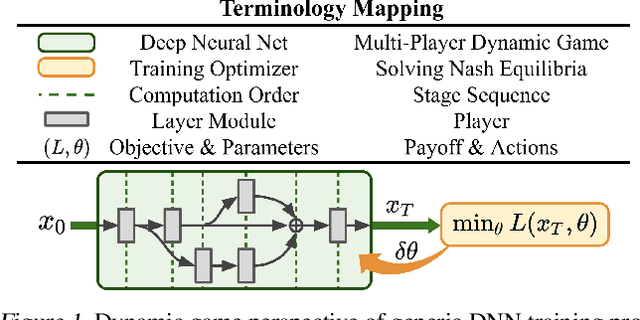

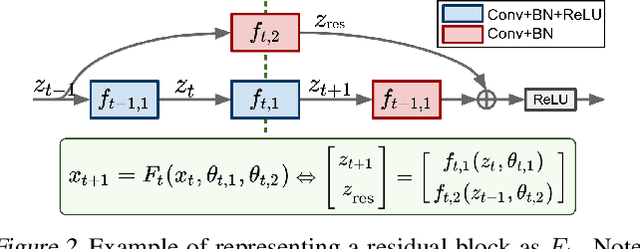
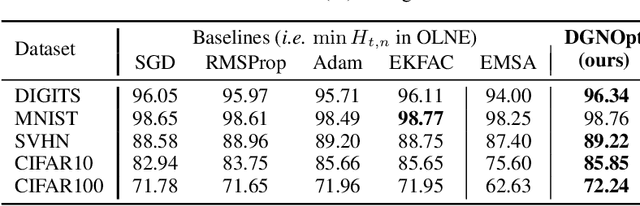
The connection between training deep neural networks (DNNs) and optimal control theory (OCT) has attracted considerable attention as a principled tool of algorithmic design. Despite few attempts being made, they have been limited to architectures where the layer propagation resembles a Markovian dynamical system. This casts doubts on their flexibility to modern networks that heavily rely on non-Markovian dependencies between layers (e.g. skip connections in residual networks). In this work, we propose a novel dynamic game perspective by viewing each layer as a player in a dynamic game characterized by the DNN itself. Through this lens, different classes of optimizers can be seen as matching different types of Nash equilibria, depending on the implicit information structure of each (p)layer. The resulting method, called Dynamic Game Theoretic Neural Optimizer (DGNOpt), not only generalizes OCT-inspired optimizers to richer network class; it also motivates a new training principle by solving a multi-player cooperative game. DGNOpt shows convergence improvements over existing methods on image classification datasets with residual networks. Our work marries strengths from both OCT and game theory, paving ways to new algorithmic opportunities from robust optimal control and bandit-based optimization.
Depth-wise layering of 3d images using dense depth maps: a threshold based approach
Oct 05, 2020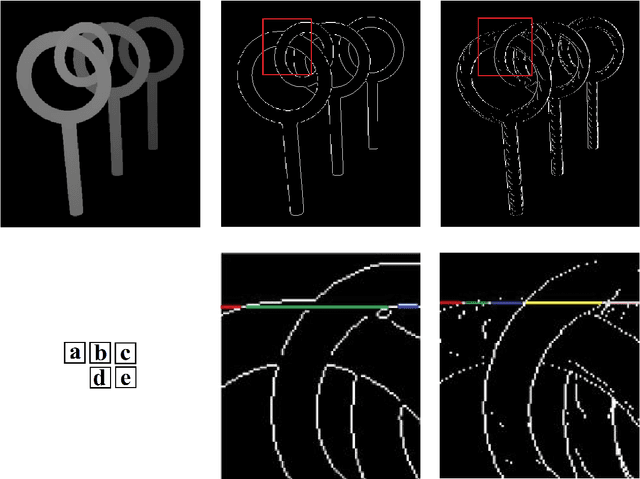
Image segmentation has long been a basic problem in computer vision. Depth-wise Layering is a kind of segmentation that slices an image in a depth-wise sequence unlike the conventional image segmentation problems dealing with surface-wise decomposition. The proposed Depth-wise Layering technique uses a single depth image of a static scene to slice it into multiple layers. The technique employs a thresholding approach to segment rows of the dense depth map into smaller partitions called Line-Segments in this paper. Then, it uses the line-segment labelling method to identify number of objects and layers of the scene independently. The final stage is to link objects of the scene to their respective object-layers. We evaluate the efficiency of the proposed technique by applying that on many images along with their dense depth maps. The experiments have shown promising results of layering.