 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
One-Pixel Attack Deceives Automatic Detection of Breast Cancer
Dec 01, 2020
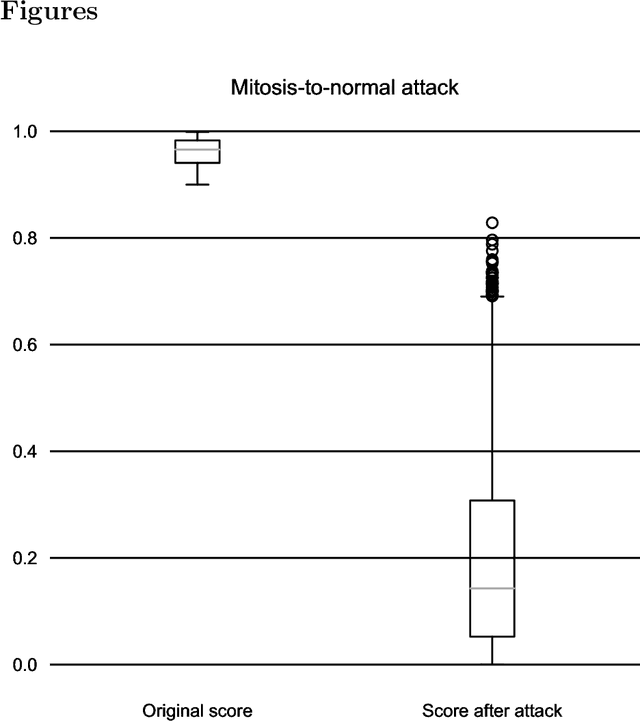
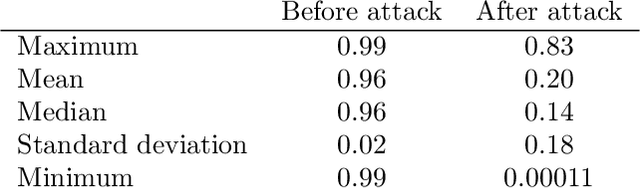
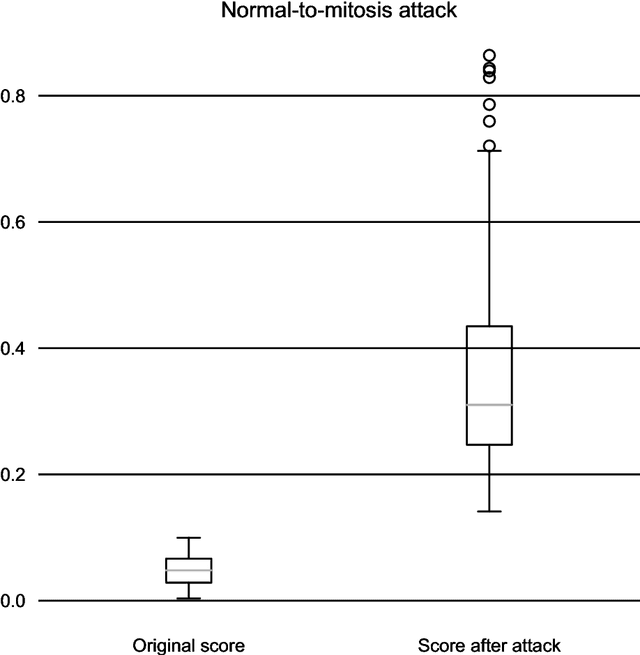
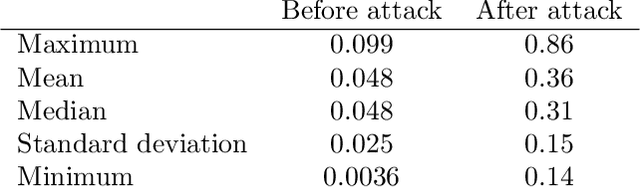
In this article we demonstrate that a state-of-the-art machine learning model predicting whether a whole slide image contains mitosis can be fooled by changing just a single pixel in the input image. Computer vision and machine learning can be used to automate various tasks in cancer diagnostic and detection. If an attacker can manipulate the automated processing, the results can be devastating and in the worst case lead to wrong diagnostic and treatments. In this research one-pixel attack is demonstrated in a real-life scenario with a real tumor dataset. The results indicate that a minor one-pixel modification of a whole slide image under analysis can affect the diagnosis. The attack poses a threat from the cyber security perspective: the one-pixel method can be used as an attack vector by a motivated attacker.
Fast Projective Image Rectification for Planar Objects with Manhattan Structure
Dec 04, 2019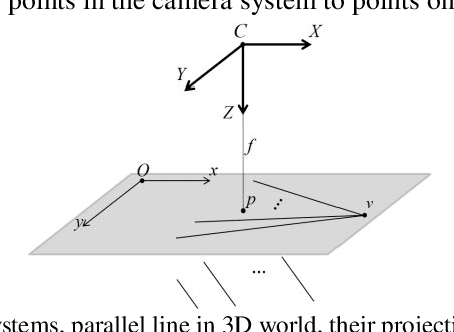
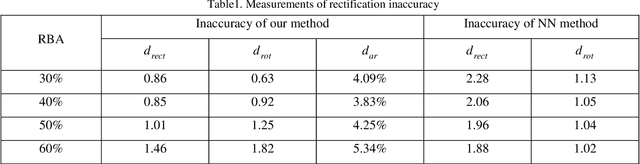
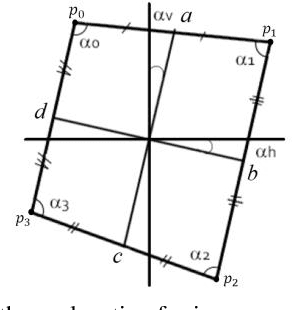

This paper presents a method for metric rectification of planar objects that preserves angles and length ratios. An inner structure of an object is assumed to follow the laws of Manhattan World i.e. the majority of line segments are aligned with two orthogonal directions of the object. For that purpose we introduce the method that estimates the position of two vanishing points corresponding to the main object directions. It is based on an original optimization function of segments that estimates a vanishing point position. For calculation of the rectification homography with two vanishing points we propose a new method based on estimation of the camera rotation so that the camera axis is perpendicular to the object plane. The proposed method can be applied for rectification of various objects such as documents or building facades. Also since the camera rotation is estimated the method can be employed for estimation of object orientation (for example, during a surgery with radiograph of osteosynthesis implants). The method was evaluated on the MIDV-500 dataset containing projectively distorted images of documents with complex background. According to the experimental results an accuracy of the proposed method is better or equal to the-state-of-the-art if the background occupies no more than half of the image. Runtime of the method is around 3ms on core i7 3610qm CPU.
A Two Stage GAN for High Resolution Retinal Image Generation and Segmentation
Jul 29, 2019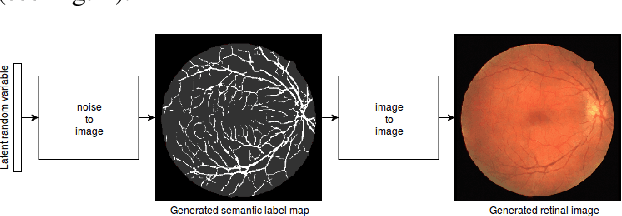
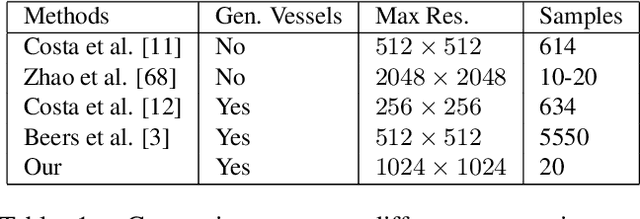
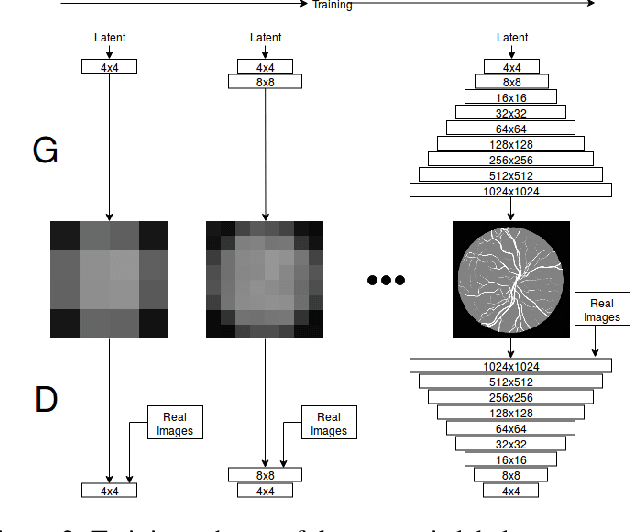
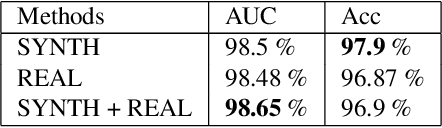
In recent years, the use of deep learning is becoming increasingly popular in computer vision. However, the effective training of deep architectures usually relies on huge sets of annotated data. This is critical in the medical field where it is difficult and expensive to obtain annotated images. In this paper, we use Generative Adversarial Networks (GANs) for synthesizing high quality retinal images, along with the corresponding semantic label-maps, to be used instead of real images during the training process. Differently from other previous proposals, we suggest a two step approach: first, a progressively growing GAN is trained to generate the semantic label-maps, which describe the blood vessel structure (i.e. vasculature); second, an image-to-image translation approach is used to obtain realistic retinal images from the generated vasculature. By using only a handful of training samples, our approach generates realistic high resolution images, that can be effectively used to enlarge small available datasets. Comparable results have been obtained employing the generated images in place of real data during training. The practical viability of the proposed approach has been demonstrated by applying it on two well established benchmark sets for retinal vessel segmentation, both containing a very small number of training samples. Our method obtained better performances with respect to state-of-the-art techniques.
Image-based model parameter optimisation using Model-Assisted Generative Adversarial Networks
Nov 30, 2018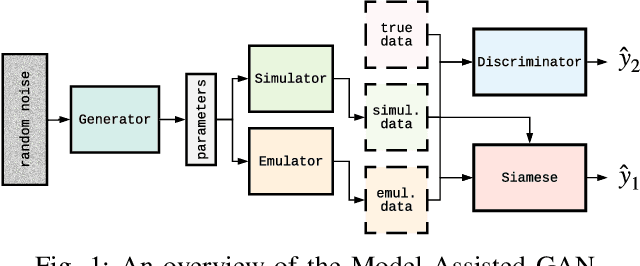
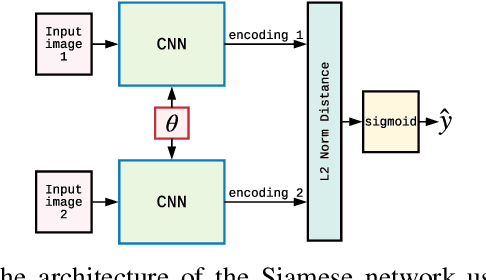
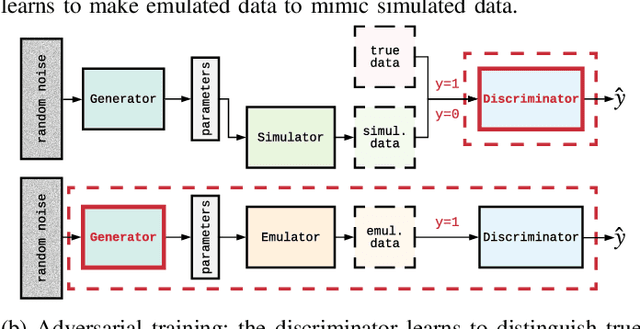
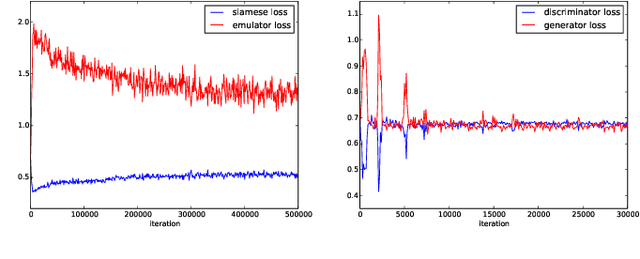
We propose and demonstrate the use of a Model-Assisted Generative Adversarial Network to produce simulated images that accurately match true images through the variation of underlying model parameters that describe the image generation process. The generator learns the parameter values that give images that best match the true images. Two case studies show the excellent agreement between the generated best match parameters and the true parameters. The best match parameter values that produce the most accurate simulated images can be extracted and used to re-tune the default simulation to minimise any bias when applying image recognition techniques to simulated and true images. In the case of a real-world experiment, the true data is replaced by experimental data with unknown true parameter values. The Model-Assisted Generative Adversarial Network uses a convolutional neural network to emulate the simulation for all parameter values that, when trained, can be used as a conditional generator for fast image production.
VolterraNet: A higher order convolutional network with group equivariance for homogeneous manifolds
Jun 05, 2021
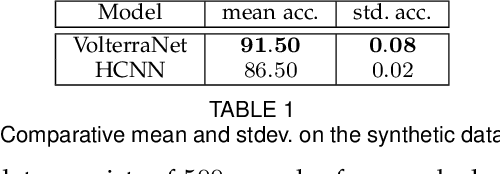

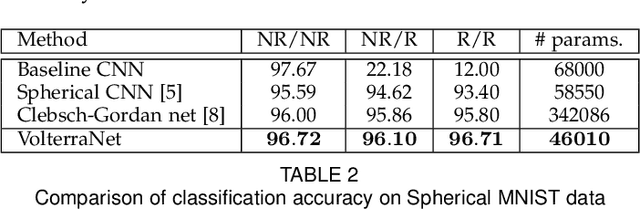
Convolutional neural networks have been highly successful in image-based learning tasks due to their translation equivariance property. Recent work has generalized the traditional convolutional layer of a convolutional neural network to non-Euclidean spaces and shown group equivariance of the generalized convolution operation. In this paper, we present a novel higher order Volterra convolutional neural network (VolterraNet) for data defined as samples of functions on Riemannian homogeneous spaces. Analagous to the result for traditional convolutions, we prove that the Volterra functional convolutions are equivariant to the action of the isometry group admitted by the Riemannian homogeneous spaces, and under some restrictions, any non-linear equivariant function can be expressed as our homogeneous space Volterra convolution, generalizing the non-linear shift equivariant characterization of Volterra expansions in Euclidean space. We also prove that second order functional convolution operations can be represented as cascaded convolutions which leads to an efficient implementation. Beyond this, we also propose a dilated VolterraNet model. These advances lead to large parameter reductions relative to baseline non-Euclidean CNNs. To demonstrate the efficacy of the VolterraNet performance, we present several real data experiments involving classification tasks on spherical-MNIST, atomic energy, Shrec17 data sets, and group testing on diffusion MRI data. Performance comparisons to the state-of-the-art are also presented.
Improving Word Recognition using Multiple Hypotheses and Deep Embeddings
Oct 27, 2020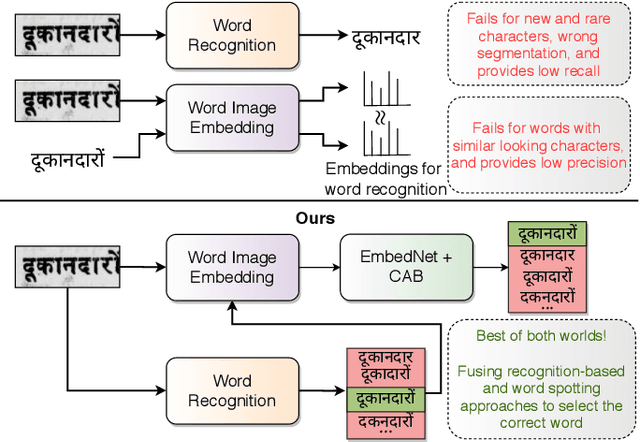
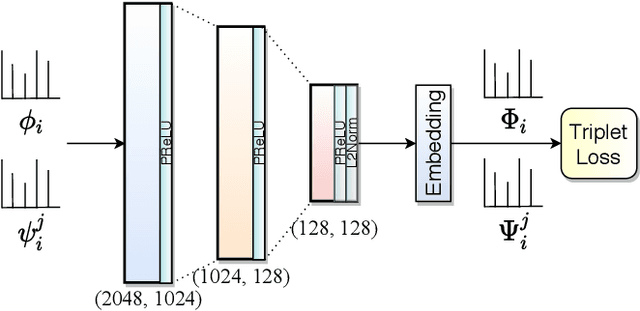
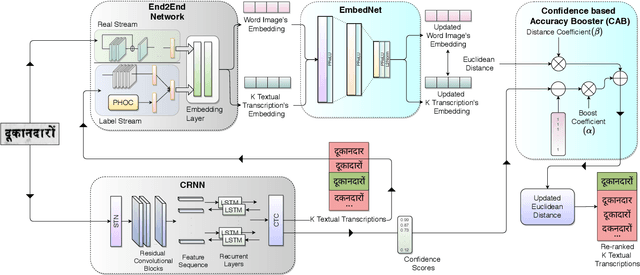
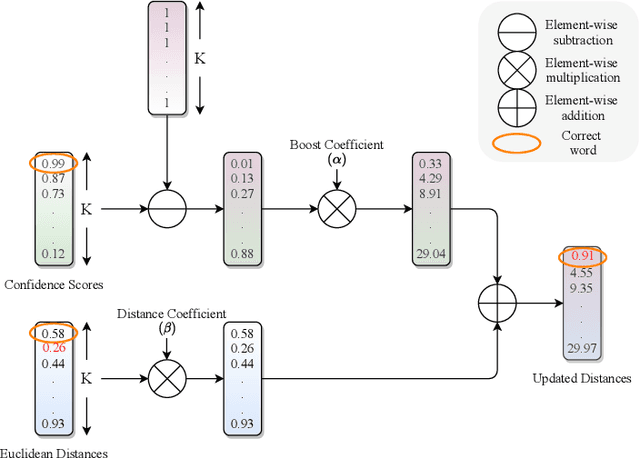
We propose a novel scheme for improving the word recognition accuracy using word image embeddings. We use a trained text recognizer, which can predict multiple text hypothesis for a given word image. Our fusion scheme improves the recognition process by utilizing the word image and text embeddings obtained from a trained word image embedding network. We propose EmbedNet, which is trained using a triplet loss for learning a suitable embedding space where the embedding of the word image lies closer to the embedding of the corresponding text transcription. The updated embedding space thus helps in choosing the correct prediction with higher confidence. To further improve the accuracy, we propose a plug-and-play module called Confidence based Accuracy Booster (CAB). The CAB module takes in the confidence scores obtained from the text recognizer and Euclidean distances between the embeddings to generate an updated distance vector. The updated distance vector has lower distance values for the correct words and higher distance values for the incorrect words. We rigorously evaluate our proposed method systematically on a collection of books in the Hindi language. Our method achieves an absolute improvement of around 10 percent in terms of word recognition accuracy.
What Can I Do Here? Learning New Skills by Imagining Visual Affordances
Jun 13, 2021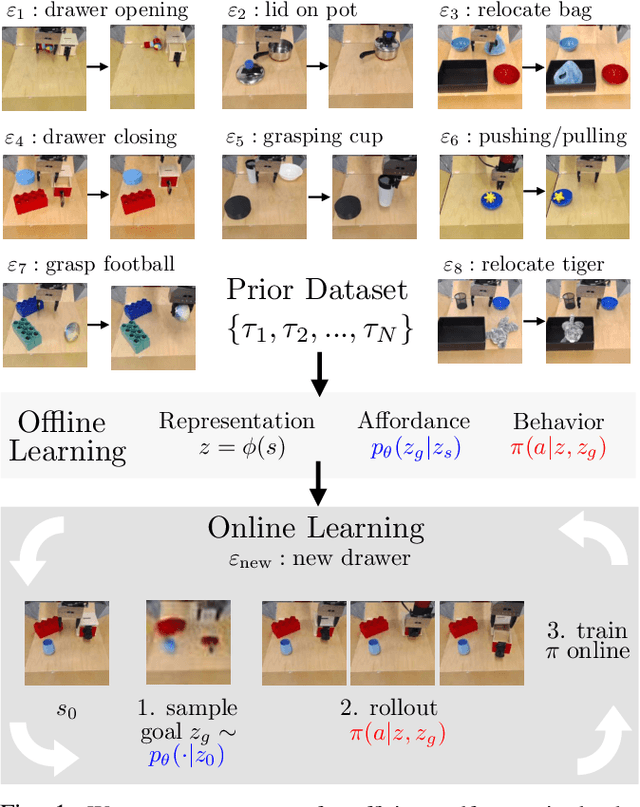


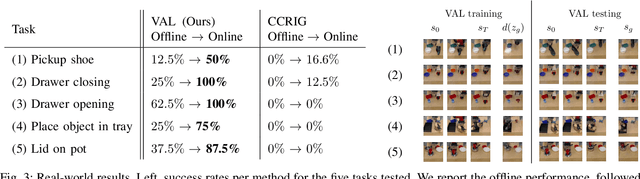
A generalist robot equipped with learned skills must be able to perform many tasks in many different environments. However, zero-shot generalization to new settings is not always possible. When the robot encounters a new environment or object, it may need to finetune some of its previously learned skills to accommodate this change. But crucially, previously learned behaviors and models should still be suitable to accelerate this relearning. In this paper, we aim to study how generative models of possible outcomes can allow a robot to learn visual representations of affordances, so that the robot can sample potentially possible outcomes in new situations, and then further train its policy to achieve those outcomes. In effect, prior data is used to learn what kinds of outcomes may be possible, such that when the robot encounters an unfamiliar setting, it can sample potential outcomes from its model, attempt to reach them, and thereby update both its skills and its outcome model. This approach, visuomotor affordance learning (VAL), can be used to train goal-conditioned policies that operate on raw image inputs, and can rapidly learn to manipulate new objects via our proposed affordance-directed exploration scheme. We show that VAL can utilize prior data to solve real-world tasks such drawer opening, grasping, and placing objects in new scenes with only five minutes of online experience in the new scene.
TransFG: A Transformer Architecture for Fine-grained Recognition
Mar 28, 2021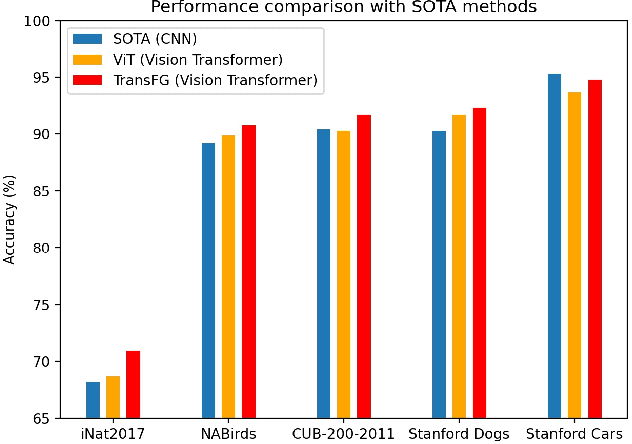
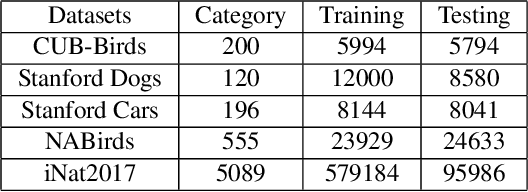
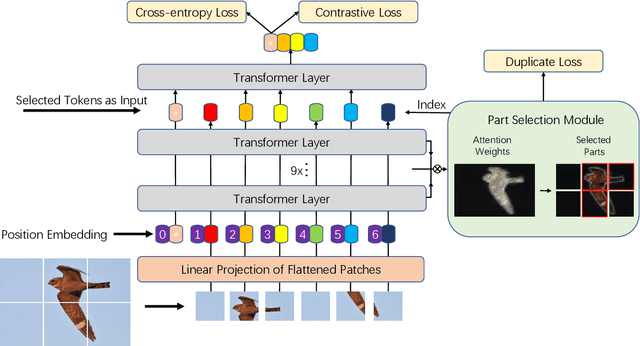
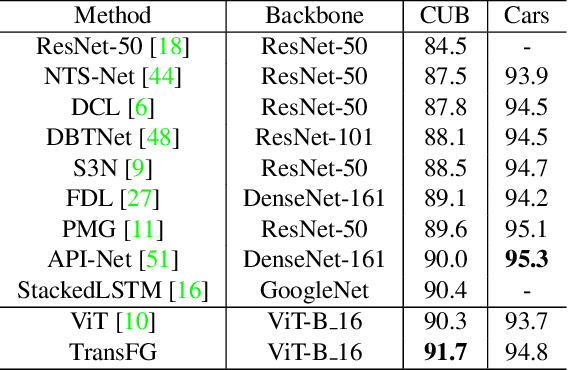
Fine-grained visual classification (FGVC) which aims at recognizing objects from subcategories is a very challenging task due to the inherently subtle inter-class differences. Recent works mainly tackle this problem by focusing on how to locate the most discriminative image regions and rely on them to improve the capability of networks to capture subtle variances. Most of these works achieve this by re-using the backbone network to extract features of selected regions. However, this strategy inevitably complicates the pipeline and pushes the proposed regions to contain most parts of the objects. Recently, vision transformer (ViT) shows its strong performance in the traditional classification task. The self-attention mechanism of the transformer links every patch token to the classification token. The strength of the attention link can be intuitively considered as an indicator of the importance of tokens. In this work, we propose a novel transformer-based framework TransFG where we integrate all raw attention weights of the transformer into an attention map for guiding the network to effectively and accurately select discriminative image patches and compute their relations. A contrastive loss is applied to further enlarge the distance between feature representations of similar sub-classes. We demonstrate the value of TransFG by conducting experiments on five popular fine-grained benchmarks: CUB-200-2011, Stanford Cars, Stanford Dogs, NABirds and iNat2017 where we achieve state-of-the-art performance. Qualitative results are presented for better understanding of our model. Code is available at https://github.com/TACJu/TransFG.
Generative Adversarial Networks (GANs) in Networking: A Comprehensive Survey & Evaluation
May 10, 2021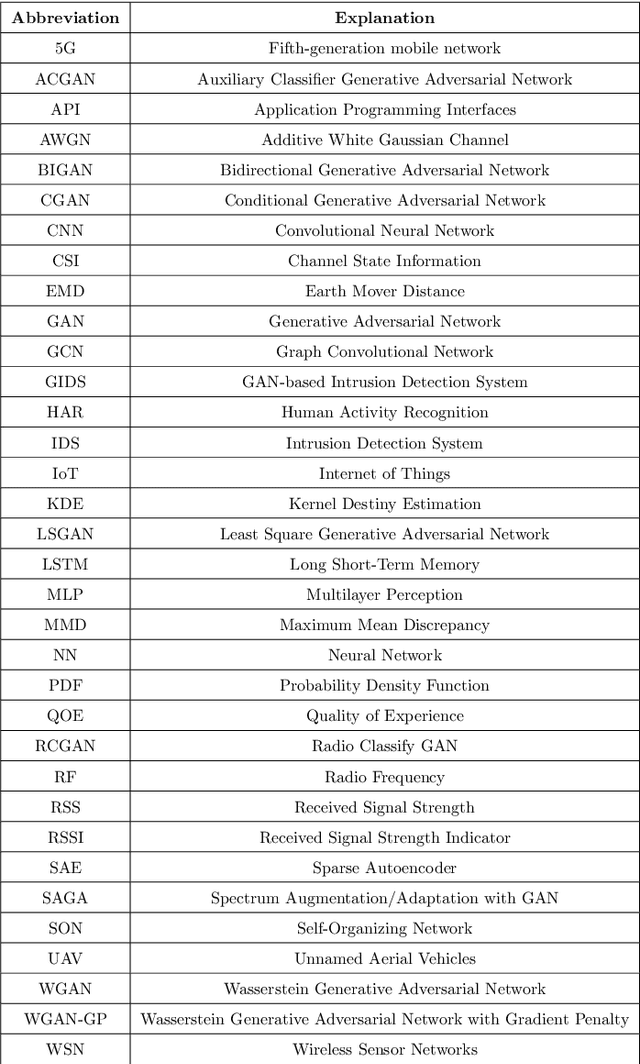
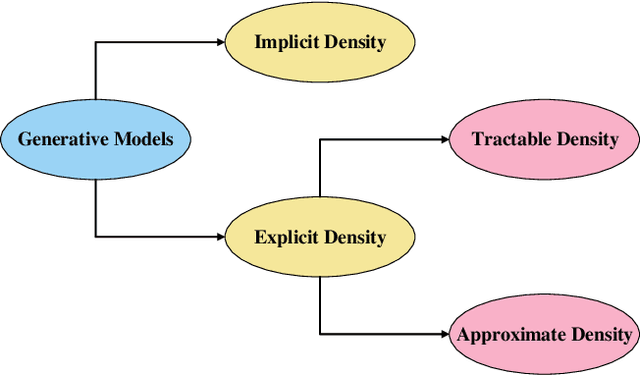
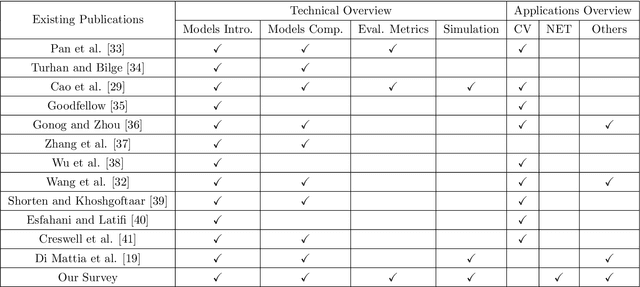
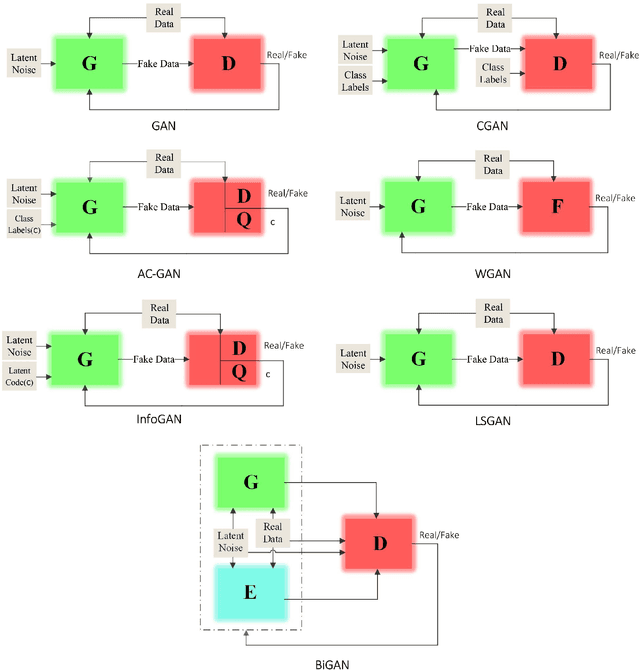
Despite the recency of their conception, Generative Adversarial Networks (GANs) constitute an extensively researched machine learning sub-field for the creation of synthetic data through deep generative modeling. GANs have consequently been applied in a number of domains, most notably computer vision, in which they are typically used to generate or transform synthetic images. Given their relative ease of use, it is therefore natural that researchers in the field of networking (which has seen extensive application of deep learning methods) should take an interest in GAN-based approaches. The need for a comprehensive survey of such activity is therefore urgent. In this paper, we demonstrate how this branch of machine learning can benefit multiple aspects of computer and communication networks, including mobile networks, network analysis, internet of things, physical layer, and cybersecurity. In doing so, we shall provide a novel evaluation framework for comparing the performance of different models in non-image applications, applying this to a number of reference network datasets.
Image-Based Size Analysis of Agglomerated and Partially Sintered Particles via Convolutional Neural Networks
Jul 12, 2019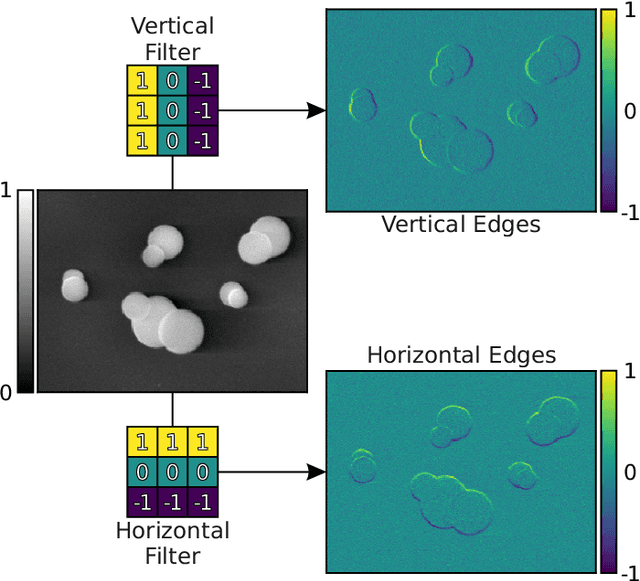
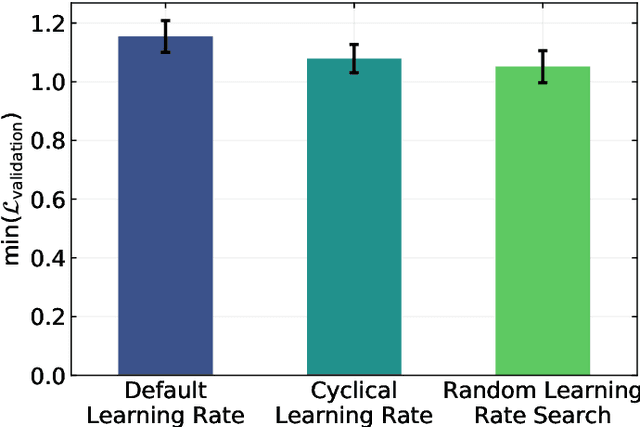
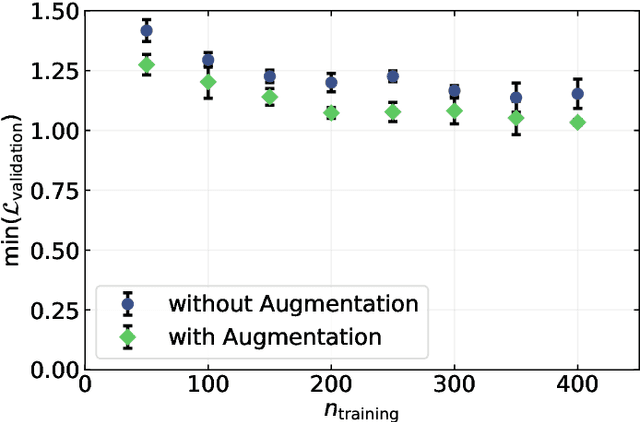
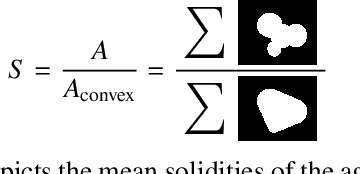
There is a high demand for fully automated methods for the analysis of particle size distributions of agglomerated, sintered or occluded primary particles. Therefore, a novel, deep learning-based, method for the pixel-perfect detection and sizing of agglomerated, aggregated or occluded primary particles was proposed and tested. As a specialty, the training of the utilized convolutional neural networks was carried out using only synthetic images, to avoid the laborious task of manual annotation and to increase the quality of the ground truth. Despite the training on synthetic images, the proposed method performs excellent on real world samples of sintered silica nanoparticles with various sintering degrees and varying image conditions. In a direct comparison, the proposed method clearly outperforms two state-of-the-art methods for automated image-based particle size analysis (Hough transformation and the ImageJ ParticleSizer plug-in), with respect to precision and speed, thereby advancing into regions of human-like performance and reliability.