 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Segmentation Based on Multiscale Fast Spectral Clustering
Dec 12, 2018
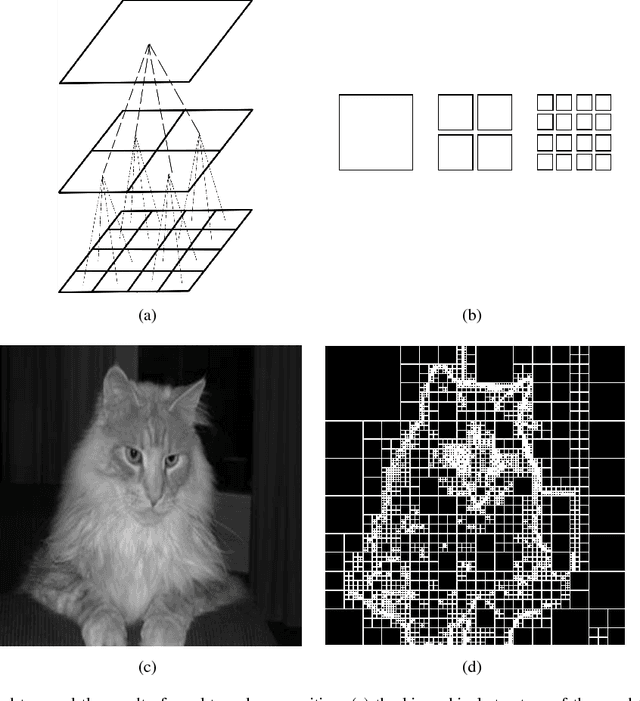
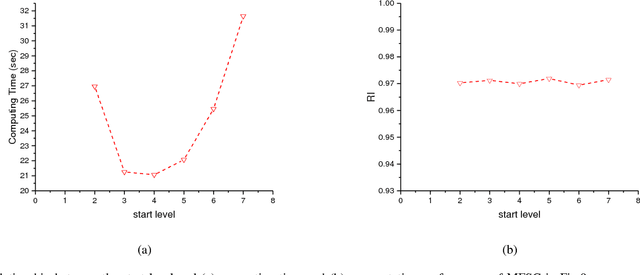
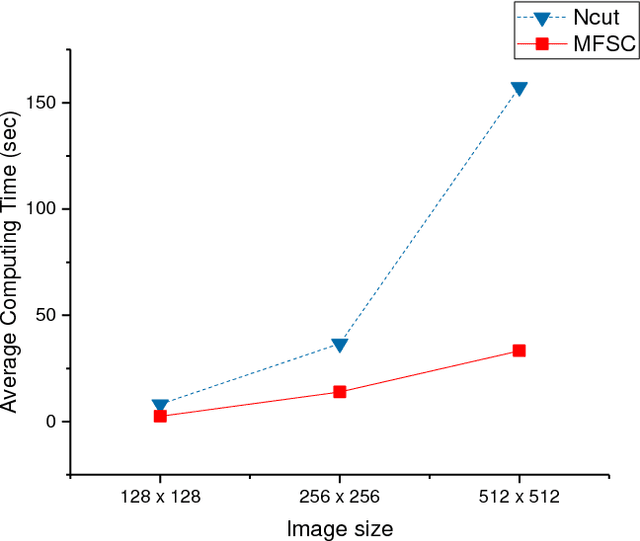
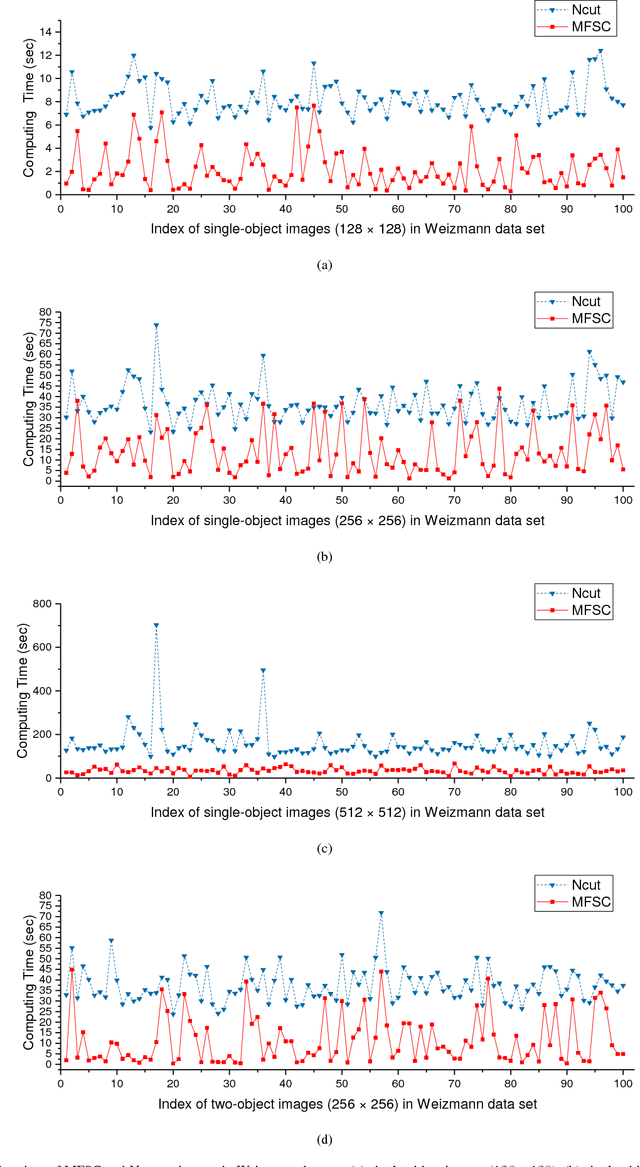
In recent years, spectral clustering has become one of the most popular clustering algorithms for image segmentation. However, it has restricted applicability to large-scale images due to its high computational complexity. In this paper, we first propose a novel algorithm called Fast Spectral Clustering based on quad-tree decomposition. The algorithm focuses on the spectral clustering at superpixel level and its computational complexity is O(nlogn) + O(m) + O(m^(3/2)); its memory cost is O(m), where n and m are the numbers of pixels and the superpixels of a image. Then we propose Multiscale Fast Spectral Clustering by improving Fast Spectral Clustering, which is based on the hierarchical structure of the quad-tree. The computational complexity of Multiscale Fast Spectral Clustering is O(nlogn) and its memory cost is O(m). Extensive experiments on real large-scale images demonstrate that Multiscale Fast Spectral Clustering outperforms Normalized cut in terms of lower computational complexity and memory cost, with comparable clustering accuracy.
A Lightweight ReLU-Based Feature Fusion for Aerial Scene Classification
Jun 15, 2021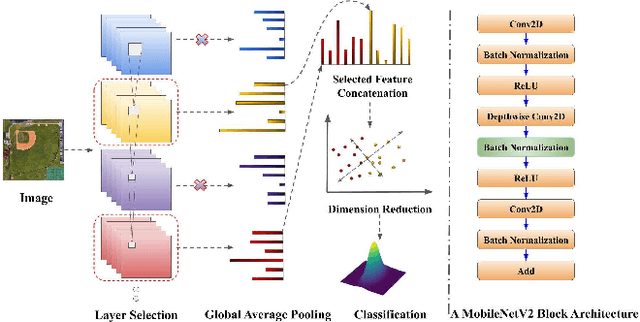

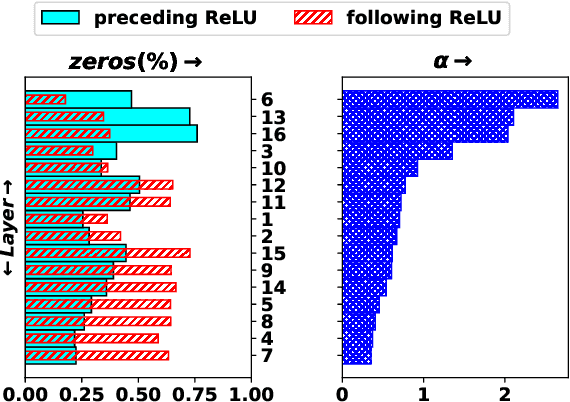
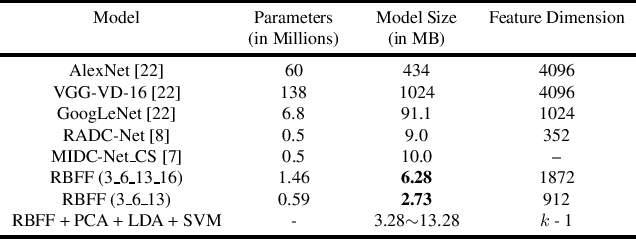
In this paper, we propose a transfer-learning based model construction technique for the aerial scene classification problem. The core of our technique is a layer selection strategy, named ReLU-Based Feature Fusion (RBFF), that extracts feature maps from a pretrained CNN-based single-object image classification model, namely MobileNetV2, and constructs a model for the aerial scene classification task. RBFF stacks features extracted from the batch normalization layer of a few selected blocks of MobileNetV2, where the candidate blocks are selected based on the characteristics of the ReLU activation layers present in those blocks. The feature vector is then compressed into a low-dimensional feature space using dimension reduction algorithms on which we train a low-cost SVM classifier for the classification of the aerial images. We validate our choice of selected features based on the significance of the extracted features with respect to our classification pipeline. RBFF remarkably does not involve any training of the base CNN model except for a few parameters for the classifier, which makes the technique very cost-effective for practical deployments. The constructed model despite being lightweight outperforms several recently proposed models in terms of accuracy for a number of aerial scene datasets.
Networks for Joint Affine and Non-parametric Image Registration
Mar 21, 2019
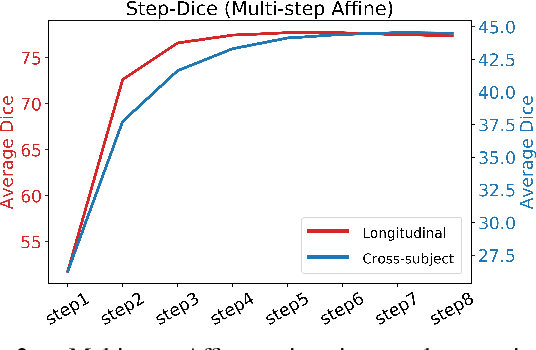
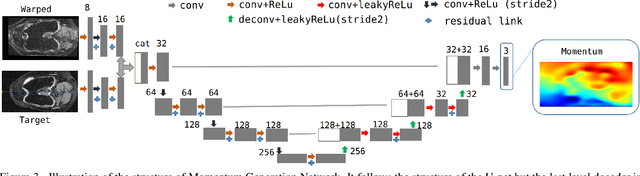

We introduce an end-to-end deep-learning framework for 3D medical image registration. In contrast to existing approaches, our framework combines two registration methods: an affine registration and a vector momentum-parameterized stationary velocity field (vSVF) model. Specifically, it consists of three stages. In the first stage, a multi-step affine network predicts affine transform parameters. In the second stage, we use a Unet-like network to generate a momentum, from which a velocity field can be computed via smoothing. Finally, in the third stage, we employ a self-iterable map-based vSVF component to provide a non-parametric refinement based on the current estimate of the transformation map. Once the model is trained, a registration is completed in one forward pass. To evaluate the performance, we conducted longitudinal and cross-subject experiments on 3D magnetic resonance images (MRI) of the knee of the Osteoarthritis Initiative (OAI) dataset. Results show that our framework achieves comparable performance to state-of-the-art medical image registration approaches, but it is much faster, with a better control of transformation regularity including the ability to produce approximately symmetric transformations, and combining affine and non-parametric registration.
Vid2Actor: Free-viewpoint Animatable Person Synthesis from Video in the Wild
Dec 23, 2020
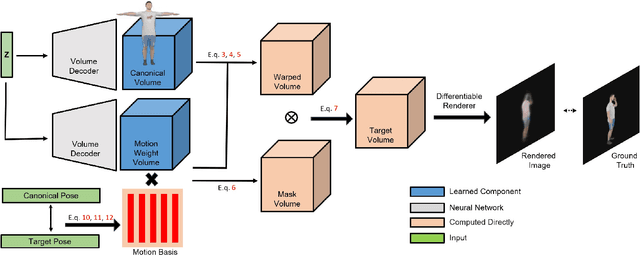
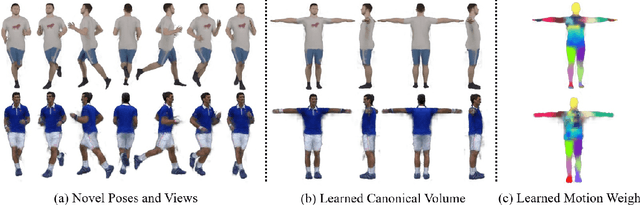

Given an "in-the-wild" video of a person, we reconstruct an animatable model of the person in the video. The output model can be rendered in any body pose to any camera view, via the learned controls, without explicit 3D mesh reconstruction. At the core of our method is a volumetric 3D human representation reconstructed with a deep network trained on input video, enabling novel pose/view synthesis. Our method is an advance over GAN-based image-to-image translation since it allows image synthesis for any pose and camera via the internal 3D representation, while at the same time it does not require a pre-rigged model or ground truth meshes for training, as in mesh-based learning. Experiments validate the design choices and yield results on synthetic data and on real videos of diverse people performing unconstrained activities (e.g. dancing or playing tennis). Finally, we demonstrate motion re-targeting and bullet-time rendering with the learned models.
Towards Photographic Image Manipulation with Balanced Growing of Generative Autoencoders
Apr 12, 2019
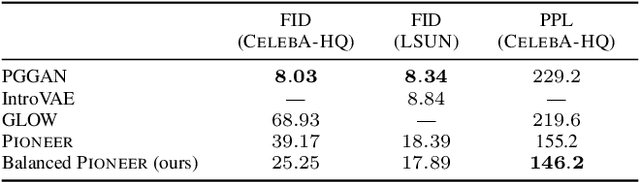

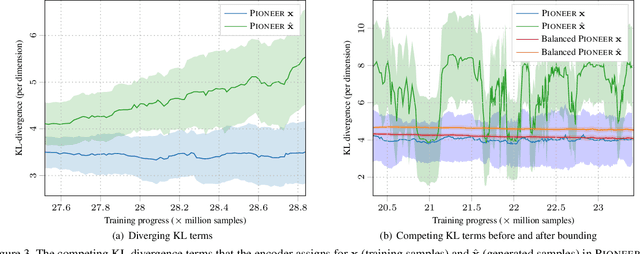
We build on recent advances in progressively growing generative autoencoder models. These models can encode and reconstruct existing images, and generate novel ones, at resolutions comparable to Generative Adversarial Networks (GANs), while consisting only of a single encoder and decoder network. The ability to reconstruct and arbitrarily modify existing samples such as images separates autoencoder models from GANs, but the output quality of image autoencoders has remained inferior. The recently proposed PIONEER autoencoder can reconstruct faces in the $256{\times}256$ CelebAHQ dataset, but like IntroVAE, another recent method, it often loses the identity of the person in the process. We propose an improved and simplified version of PIONEER and show significantly improved quality and preservation of the face identity in CelebAHQ, both visually and quantitatively. We also show evidence of state-of-the-art disentanglement of the latent space of the model, both quantitatively and via realistic image feature manipulations. On the LSUN Bedrooms dataset, our model also improves the results of the original PIONEER. Overall, our results indicate that the PIONEER networks provide a way to photorealistic face manipulation.
Two stages for visual object tracking
Apr 28, 2021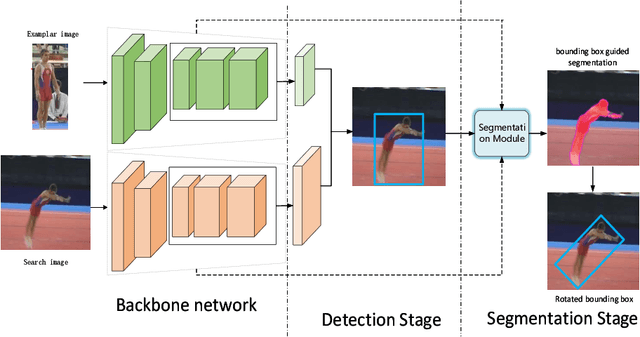
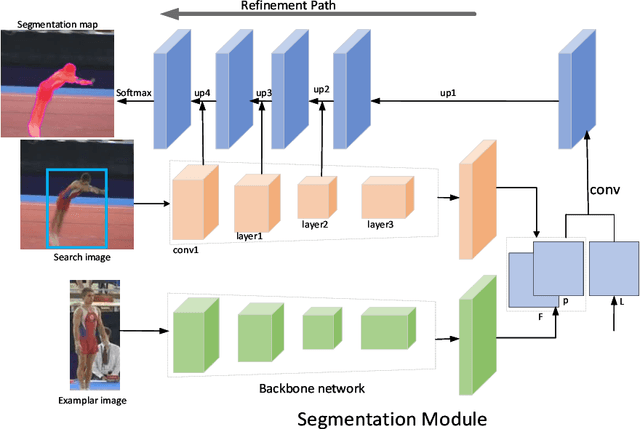


Siamese-based trackers have achived promising performance on visual object tracking tasks. Most existing Siamese-based trackers contain two separate branches for tracking, including classification branch and bounding box regression branch. In addition, image segmentation provides an alternative way to obetain the more accurate target region. In this paper, we propose a novel tracker with two-stages: detection and segmentation. The detection stage is capable of locating the target by Siamese networks. Then more accurate tracking results are obtained by segmentation module given the coarse state estimation in the first stage. We conduct experiments on four benchmarks. Our approach achieves state-of-the-art results, with the EAO of 52.6$\%$ on VOT2016, 51.3$\%$ on VOT2018, and 39.0$\%$ on VOT2019 datasets, respectively.
Fast Predictive Multimodal Image Registration
Mar 31, 2017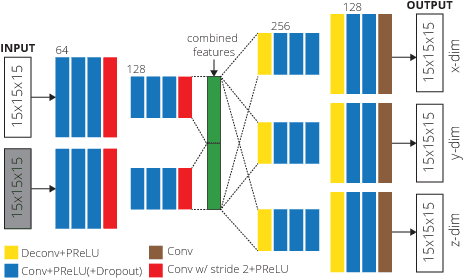
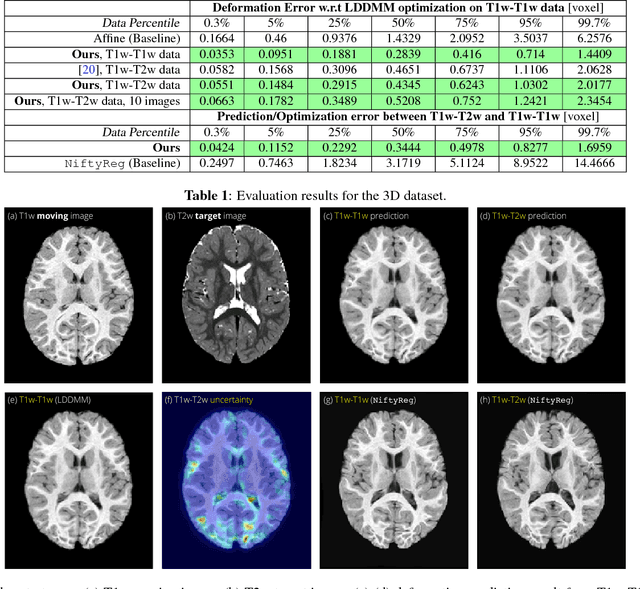
We introduce a deep encoder-decoder architecture for image deformation prediction from multimodal images. Specifically, we design an image-patch-based deep network that jointly (i) learns an image similarity measure and (ii) the relationship between image patches and deformation parameters. While our method can be applied to general image registration formulations, we focus on the Large Deformation Diffeomorphic Metric Mapping (LDDMM) registration model. By predicting the initial momentum of the shooting formulation of LDDMM, we preserve its mathematical properties and drastically reduce the computation time, compared to optimization-based approaches. Furthermore, we create a Bayesian probabilistic version of the network that allows evaluation of registration uncertainty via sampling of the network at test time. We evaluate our method on a 3D brain MRI dataset using both T1- and T2-weighted images. Our experiments show that our method generates accurate predictions and that learning the similarity measure leads to more consistent registrations than relying on generic multimodal image similarity measures, such as mutual information. Our approach is an order of magnitude faster than optimization-based LDDMM.
Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer
May 09, 2021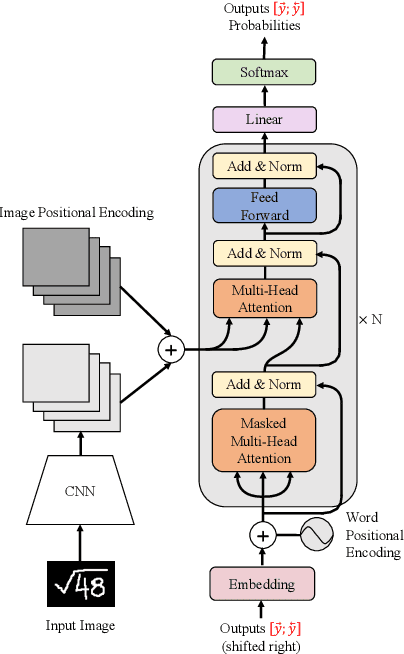
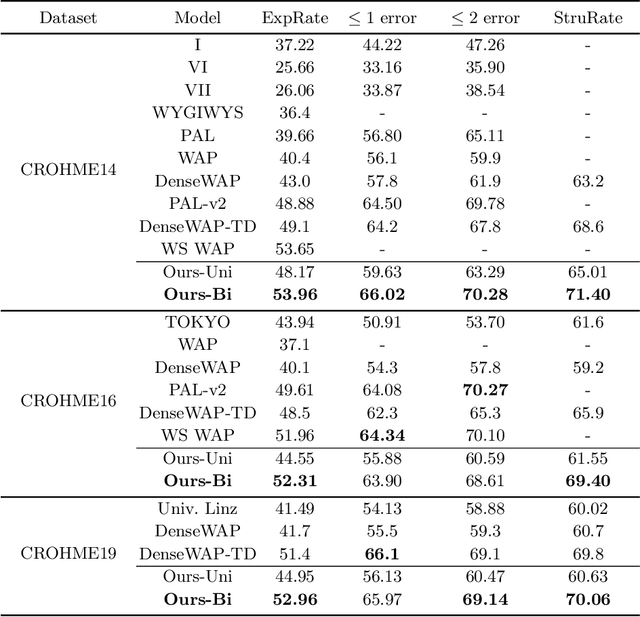
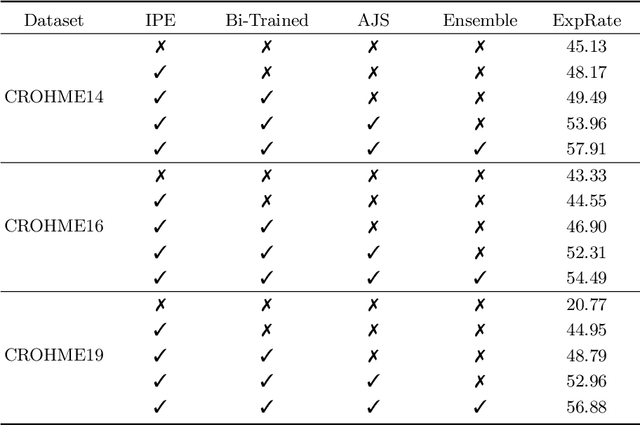
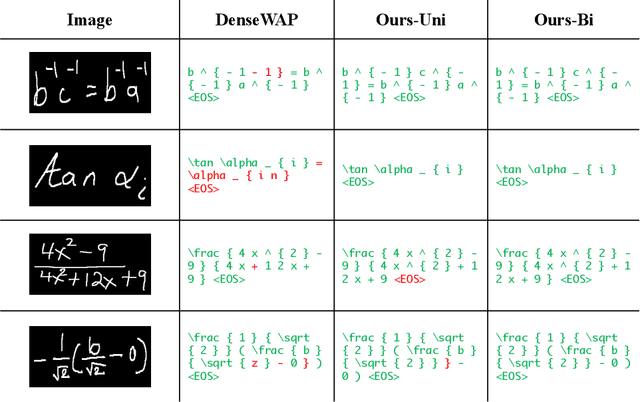
Encoder-decoder models have made great progress on handwritten mathematical expression recognition recently. However, it is still a challenge for existing methods to assign attention to image features accurately. Moreover, those encoder-decoder models usually adopt RNN-based models in their decoder part, which makes them inefficient in processing long $\LaTeX{}$ sequences. In this paper, a transformer-based decoder is employed to replace RNN-based ones, which makes the whole model architecture very concise. Furthermore, a novel training strategy is introduced to fully exploit the potential of the transformer in bidirectional language modeling. Compared to several methods that do not use data augmentation, experiments demonstrate that our model improves the ExpRate of current state-of-the-art methods on CROHME 2014 by 2.23%. Similarly, on CROHME 2016 and CROHME 2019, we improve the ExpRate by 1.92% and 2.28% respectively.
Diminishing Uncertainty within the Training Pool: Active Learning for Medical Image Segmentation
Jan 07, 2021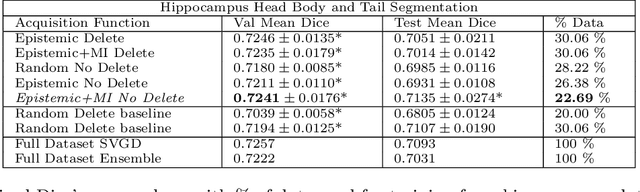
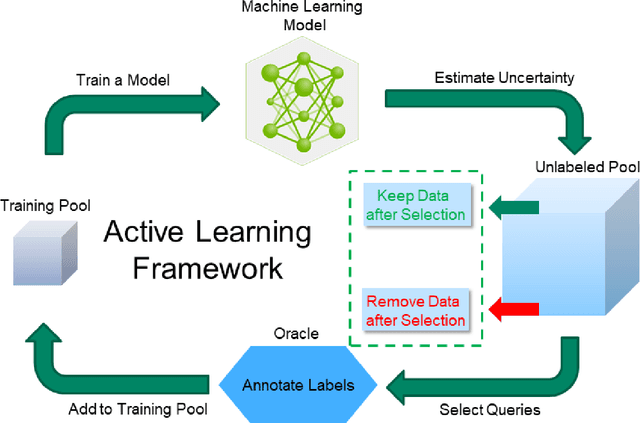
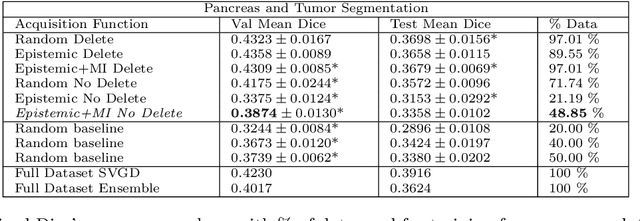
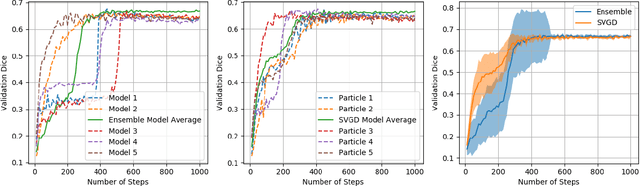
Active learning is a unique abstraction of machine learning techniques where the model/algorithm could guide users for annotation of a set of data points that would be beneficial to the model, unlike passive machine learning. The primary advantage being that active learning frameworks select data points that can accelerate the learning process of a model and can reduce the amount of data needed to achieve full accuracy as compared to a model trained on a randomly acquired data set. Multiple frameworks for active learning combined with deep learning have been proposed, and the majority of them are dedicated to classification tasks. Herein, we explore active learning for the task of segmentation of medical imaging data sets. We investigate our proposed framework using two datasets: 1.) MRI scans of the hippocampus, 2.) CT scans of pancreas and tumors. This work presents a query-by-committee approach for active learning where a joint optimizer is used for the committee. At the same time, we propose three new strategies for active learning: 1.) increasing frequency of uncertain data to bias the training data set; 2.) Using mutual information among the input images as a regularizer for acquisition to ensure diversity in the training dataset; 3.) adaptation of Dice log-likelihood for Stein variational gradient descent (SVGD). The results indicate an improvement in terms of data reduction by achieving full accuracy while only using 22.69 % and 48.85 % of the available data for each dataset, respectively.
* 19 pages, 13 figures, Transactions of Medical Imaging
Unsupervised Deep Feature Transfer for Low Resolution Image Classification
Aug 27, 2019

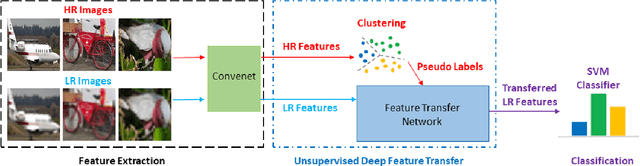
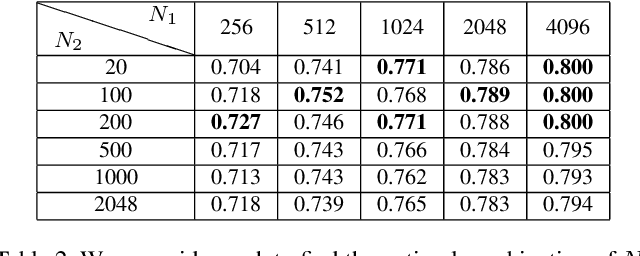
In this paper, we propose a simple while effective unsupervised deep feature transfer algorithm for low resolution image classification. No fine-tuning on convenet filters is required in our method. We use pre-trained convenet to extract features for both high- and low-resolution images, and then feed them into a two-layer feature transfer network for knowledge transfer. A SVM classifier is learned directly using these transferred low resolution features. Our network can be embedded into the state-of-the-art deep neural networks as a plug-in feature enhancement module. It preserves data structures in feature space for high resolution images, and transfers the distinguishing features from a well-structured source domain (high resolution features space) to a not well-organized target domain (low resolution features space). Extensive experiments on VOC2007 test set show that the proposed method achieves significant improvements over the baseline of using feature extraction.