 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Size Matters
Feb 09, 2021
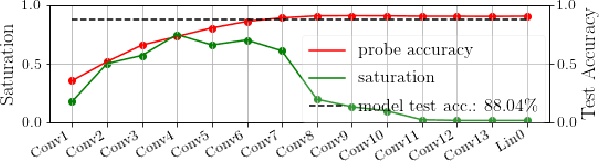
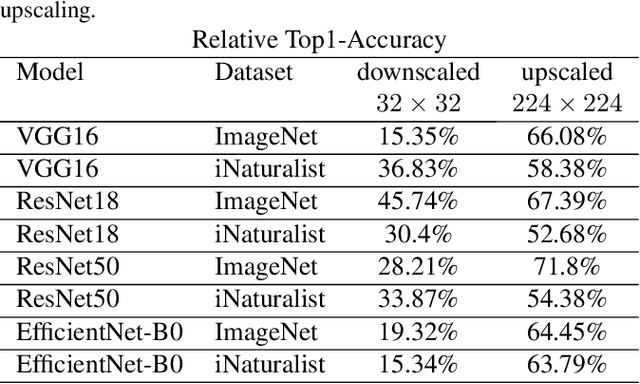
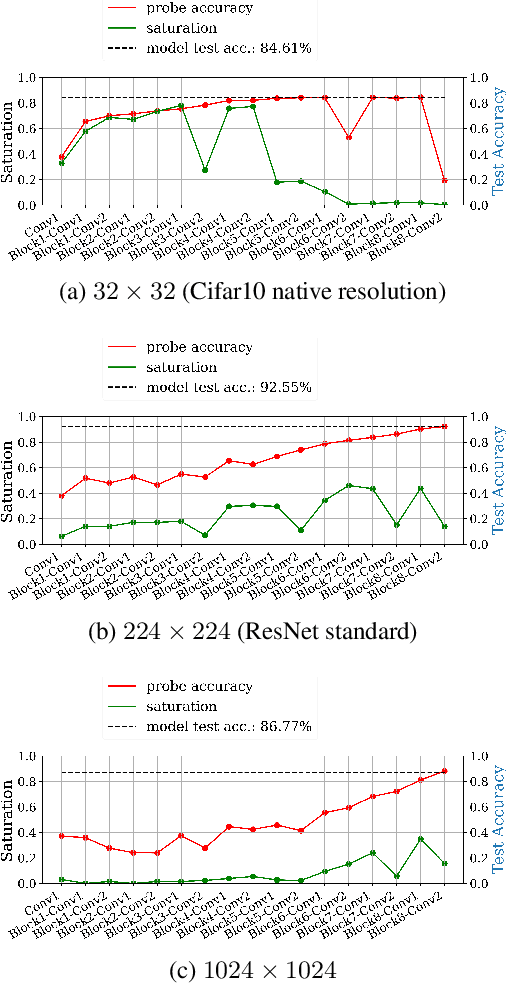
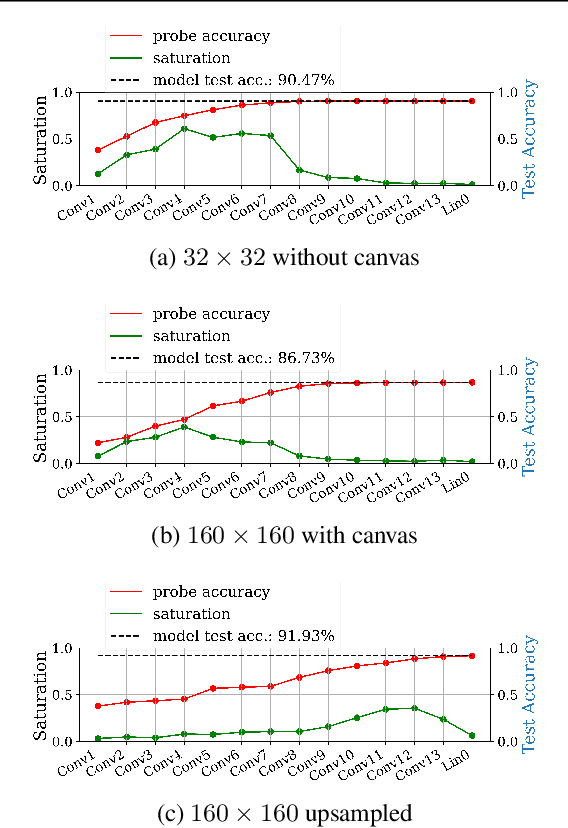
Fully convolutional neural networks can process input of arbitrary size by applying a combination of downsampling and pooling. However, we find that fully convolutional image classifiers are not agnostic to the input size but rather show significant differences in performance: presenting the same image at different scales can result in different outcomes. A closer look reveals that there is no simple relationship between input size and model performance (no `bigger is better'), but that each each network has a preferred input size, for which it shows best results. We investigate this phenomenon by applying different methods, including spectral analysis of layer activations and probe classifiers, showing that there are characteristic features depending on the network architecture. From this we find that the size of discriminatory features is critically influencing how the inference process is distributed among the layers.
Reducing Inference Latency with Concurrent Architectures for Image Recognition
Nov 13, 2020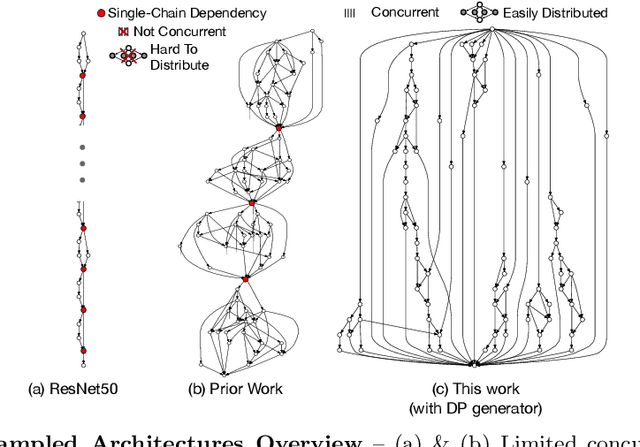

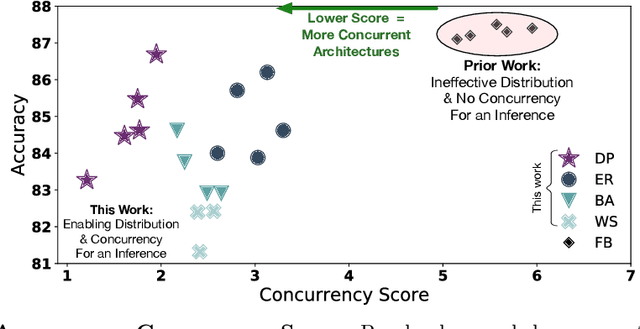
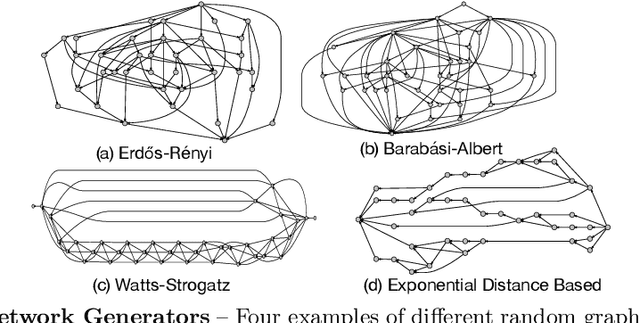
Satisfying the high computation demand of modern deep learning architectures is challenging for achieving low inference latency. The current approaches in decreasing latency only increase parallelism within a layer. This is because architectures typically capture a single-chain dependency pattern that prevents efficient distribution with a higher concurrency (i.e., simultaneous execution of one inference among devices). Such single-chain dependencies are so widespread that even implicitly biases recent neural architecture search (NAS) studies. In this visionary paper, we draw attention to an entirely new space of NAS that relaxes the single-chain dependency to provide higher concurrency and distribution opportunities. To quantitatively compare these architectures, we propose a score that encapsulates crucial metrics such as communication, concurrency, and load balancing. Additionally, we propose a new generator and transformation block that consistently deliver superior architectures compared to current state-of-the-art methods. Finally, our preliminary results show that these new architectures reduce the inference latency and deserve more attention.
Boundary Aware Multi-Focus Image Fusion Using Deep Neural Network
Mar 30, 2019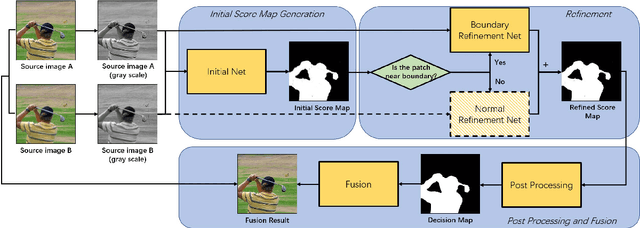



Since it is usually difficult to capture an all-in-focus image of a 3D scene directly, various multi-focus image fusion methods are employed to generate it from several images focusing at different depths. However, the performance of existing methods is barely satisfactory and often degrades for areas near the focused/defocused boundary (FDB). In this paper, a boundary aware method using deep neural network is proposed to overcome this problem. (1) Aiming to acquire improved fusion images, a 2-channel deep network is proposed to better extract the relative defocus information of the two source images. (2) After analyzing the different situations for patches far away from and near the FDB, we use two networks to handle them respectively. (3) To simulate the reality more precisely, a new approach of dataset generation is designed. Experiments demonstrate that the proposed method outperforms the state-of-the-art methods, both qualitatively and quantitatively.
Data augmentation and pre-trained networks for extremely low data regimes unsupervised visual inspection
Jun 02, 2021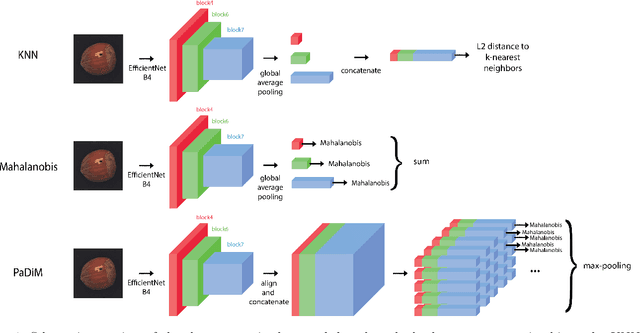
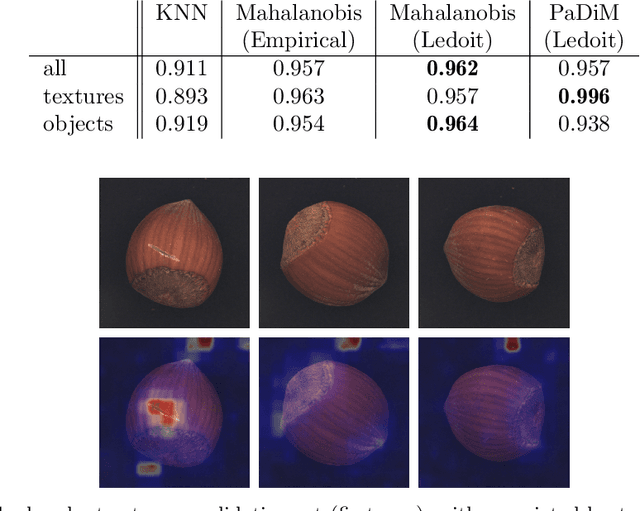
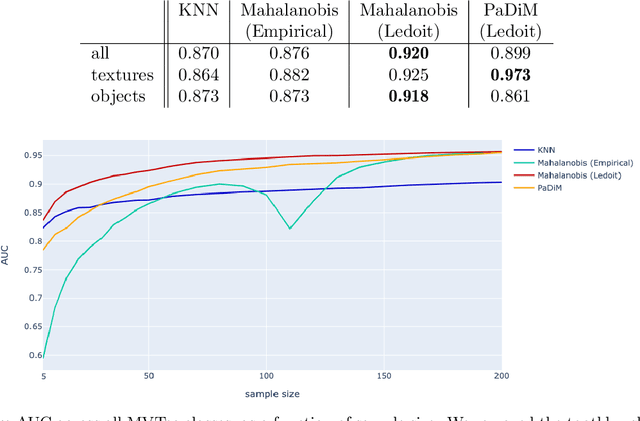
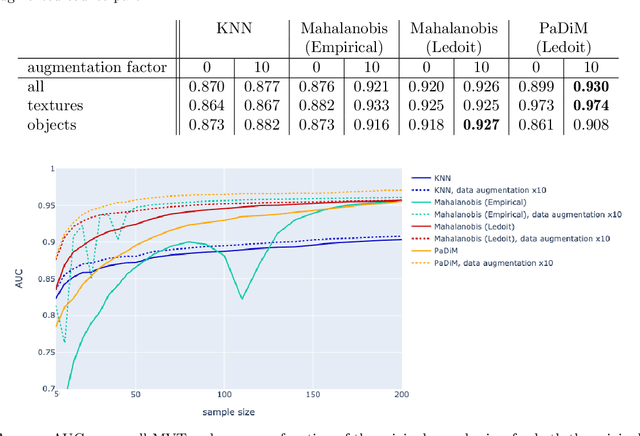
The use of deep features coming from pre-trained neural networks for unsupervised anomaly detection purposes has recently gathered momentum in the computer vision field. In particular, industrial inspection applications can take advantage of such features, as demonstrated by the multiple successes of related methods on the MVTec Anomaly Detection (MVTec AD) dataset. These methods make use of neural networks pre-trained on auxiliary classification tasks such as ImageNet. However, to our knowledge, no comparative study of robustness to the low data regimes between these approaches has been conducted yet. For quality inspection applications, the handling of limited sample sizes may be crucial as large quantities of images are not available for small series. In this work, we aim to compare three approaches based on deep pre-trained features when varying the quantity of available data in MVTec AD: KNN, Mahalanobis, and PaDiM. We show that although these methods are mostly robust to small sample sizes, they still can benefit greatly from using data augmentation in the original image space, which allows to deal with very small production runs.
Sound-to-Imagination: Unsupervised Crossmodal Translation Using Deep Dense Network Architecture
Jun 02, 2021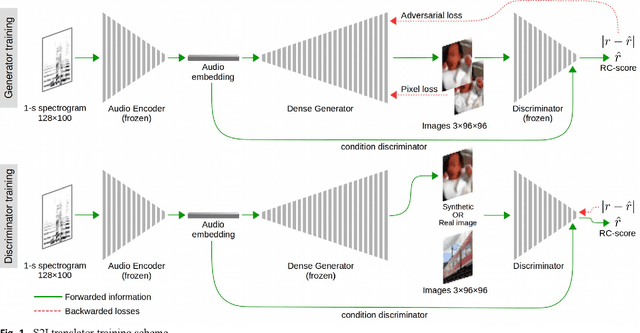

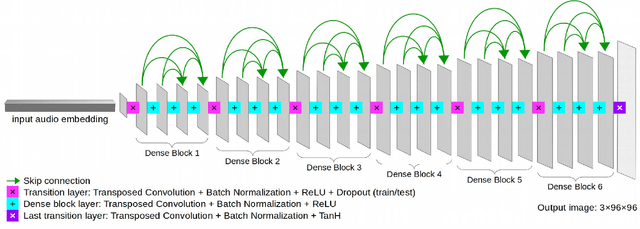
The motivation of our research is to develop a sound-to-image (S2I) translation system for enabling a human receiver to visually infer the occurrence of sound related events. We expect the computer to 'imagine' the scene from the captured sound, generating original images that picture the sound emitting source. Previous studies on similar topics opted for simplified approaches using data with low content diversity and/or strong supervision. Differently, we propose to perform unsupervised S2I translation using thousands of distinct and unknown scenes, with slightly pre-cleaned data, just enough to guarantee aural-visual semantic coherence. To that end, we employ conditional generative adversarial networks (GANs) with a deep densely connected generator. Besides, we implemented a moving-average adversarial loss to address GANs training instability. Though the specified S2I translation problem is quite challenging, we were able to generalize the translator model enough to obtain more than 14%, in average, of interpretable and semantically coherent images translated from unknown sounds. Additionally, we present a solution using informativity classifiers to perform quantitative evaluation of S2I translation.
Fast Perceptual Image Enhancement
Dec 31, 2018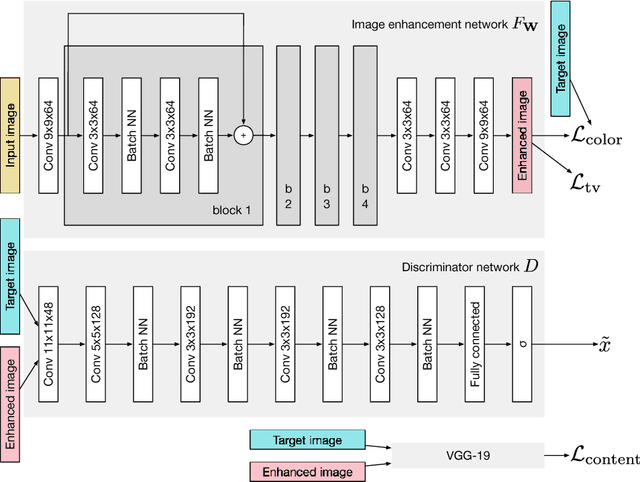
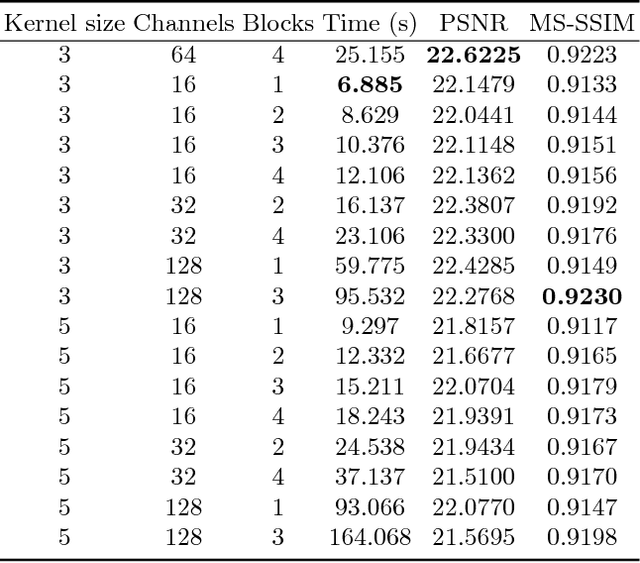
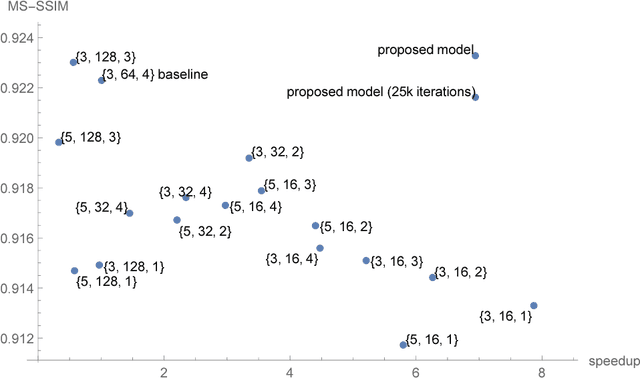
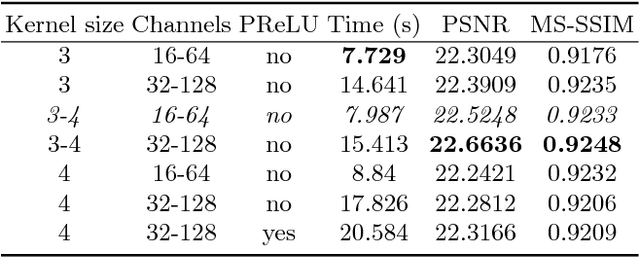
The vast majority of photos taken today are by mobile phones. While their quality is rapidly growing, due to physical limitations and cost constraints, mobile phone cameras struggle to compare in quality with DSLR cameras. This motivates us to computationally enhance these images. We extend upon the results of Ignatov et al., where they are able to translate images from compact mobile cameras into images with comparable quality to high-resolution photos taken by DSLR cameras. However, the neural models employed require large amounts of computational resources and are not lightweight enough to run on mobile devices. We build upon the prior work and explore different network architectures targeting an increase in image quality and speed. With an efficient network architecture which does most of its processing in a lower spatial resolution, we achieve a significantly higher mean opinion score (MOS) than the baseline while speeding up the computation by 6.3 times on a consumer-grade CPU. This suggests a promising direction for neural-network-based photo enhancement using the phone hardware of the future.
Latent Variable Models for Visual Question Answering
Jan 16, 2021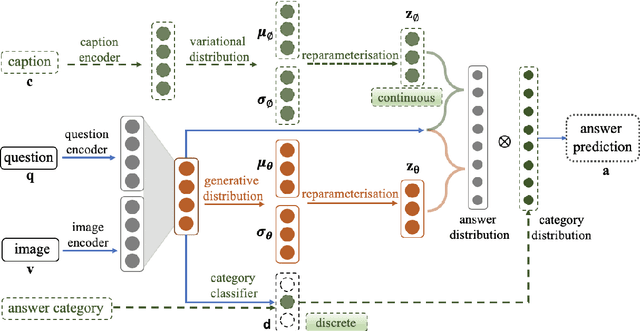
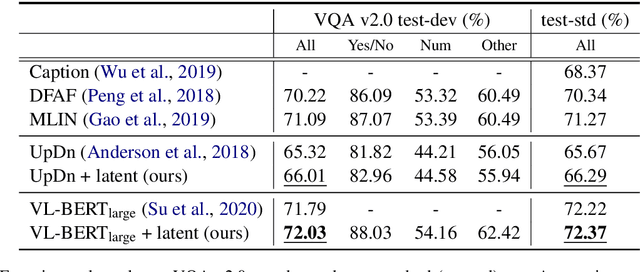

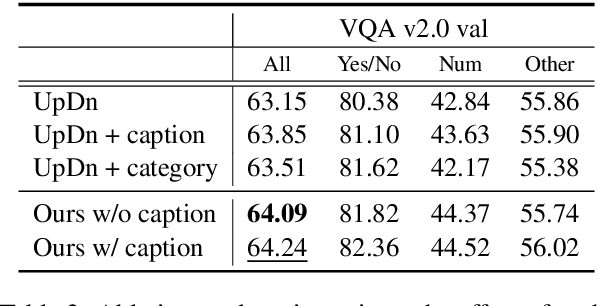
Conventional models for Visual Question Answering (VQA) explore deterministic approaches with various types of image features, question features, and attention mechanisms. However, there exist other modalities that can be explored in addition to image and question pairs to bring extra information to the models. In this work, we propose latent variable models for VQA where extra information (e.g. captions and answer categories) are incorporated as latent variables to improve inference, which in turn benefits question-answering performance. Experiments on the VQA v2.0 benchmarking dataset demonstrate the effectiveness of our proposed models in that they improve over strong baselines, especially those that do not rely on extensive language-vision pre-training.
3D-ANAS: 3D Asymmetric Neural Architecture Search for Fast Hyperspectral Image Classification
Jan 12, 2021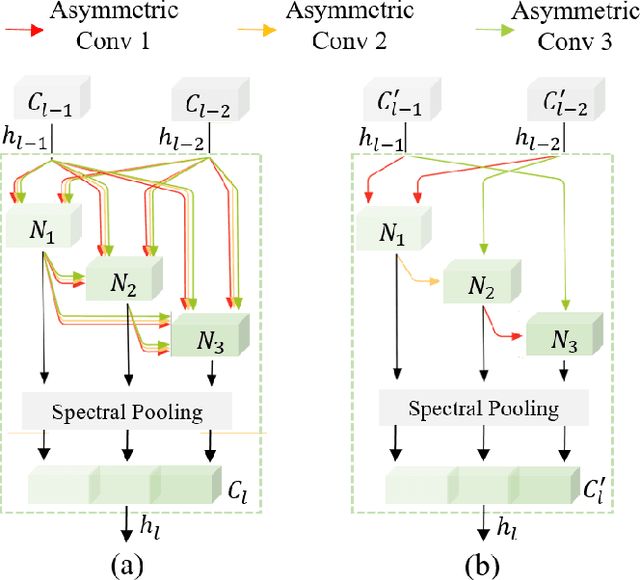
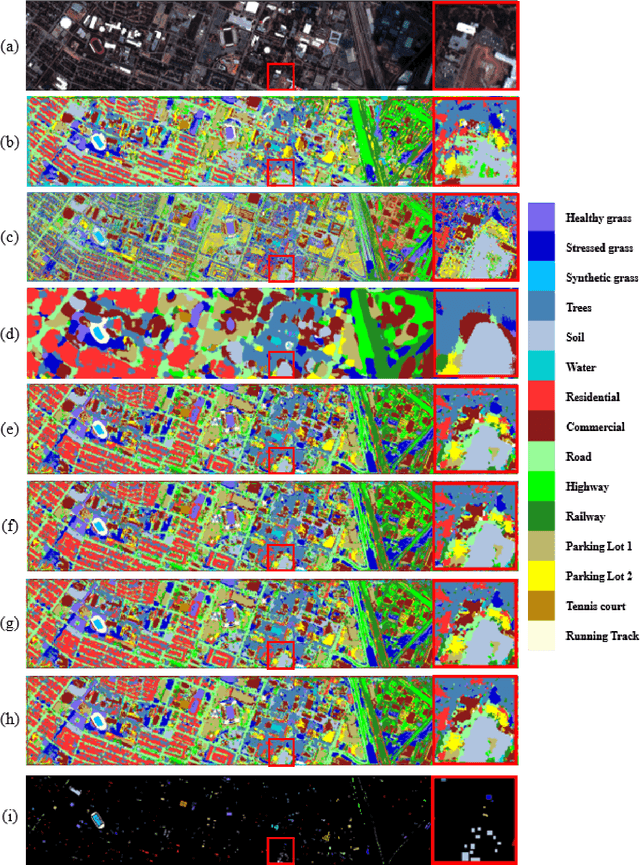
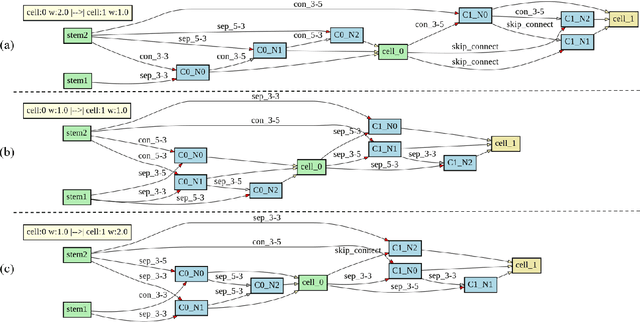
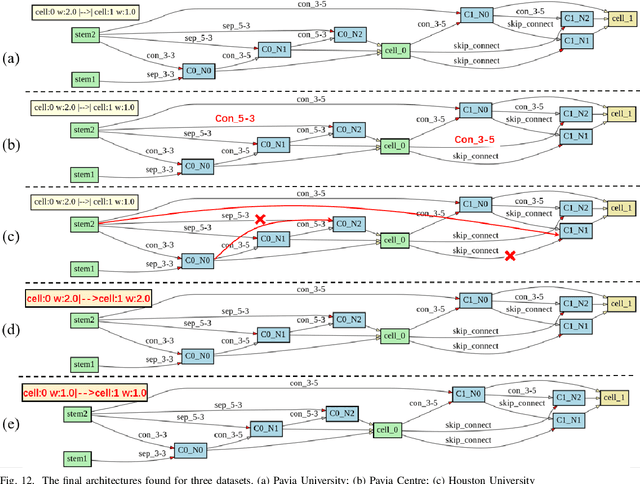
Hyperspectral images involve abundant spectral and spatial information, playing an irreplaceable role in land-cover classification. Recently, based on deep learning technologies, an increasing number of HSI classification approaches have been proposed, which demonstrate promising performance. However, previous studies suffer from two major drawbacks: 1) the architecture of most deep learning models is manually designed, relies on specialized knowledge, and is relatively tedious. Moreover, in HSI classifications, datasets captured by different sensors have different physical properties. Correspondingly, different models need to be designed for different datasets, which further increases the workload of designing architectures; 2) the mainstream framework is a patch-to-pixel framework. The overlap regions of patches of adjacent pixels are calculated repeatedly, which increases computational cost and time cost. Besides, the classification accuracy is sensitive to the patch size, which is artificially set based on extensive investigation experiments. To overcome the issues mentioned above, we firstly propose a 3D asymmetric neural network search algorithm and leverage it to automatically search for efficient architectures for HSI classifications. By analysing the characteristics of HSIs, we specifically build a 3D asymmetric decomposition search space, where spectral and spatial information are processed with different decomposition convolutions. Furthermore, we propose a new fast classification framework, i,e., pixel-to-pixel classification framework, which has no repetitive operations and reduces the overall cost. Experiments on three public HSI datasets captured by different sensors demonstrate the networks designed by our 3D-ANAS achieve competitive performance compared to several state-of-the-art methods, while having a much faster inference speed.
Recent Advances and Trends in Multimodal Deep Learning: A Review
May 24, 2021
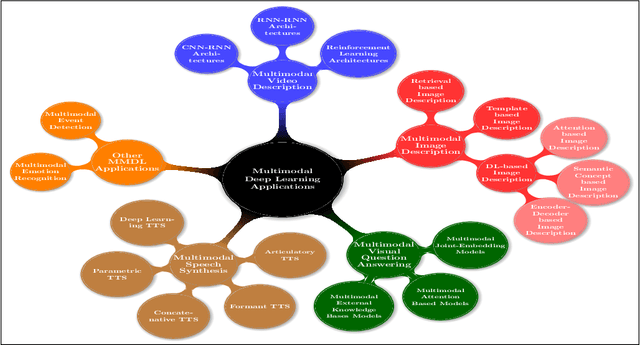

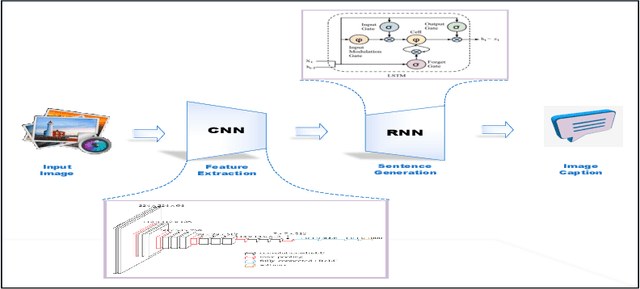
Deep Learning has implemented a wide range of applications and has become increasingly popular in recent years. The goal of multimodal deep learning is to create models that can process and link information using various modalities. Despite the extensive development made for unimodal learning, it still cannot cover all the aspects of human learning. Multimodal learning helps to understand and analyze better when various senses are engaged in the processing of information. This paper focuses on multiple types of modalities, i.e., image, video, text, audio, body gestures, facial expressions, and physiological signals. Detailed analysis of past and current baseline approaches and an in-depth study of recent advancements in multimodal deep learning applications has been provided. A fine-grained taxonomy of various multimodal deep learning applications is proposed, elaborating on different applications in more depth. Architectures and datasets used in these applications are also discussed, along with their evaluation metrics. Last, main issues are highlighted separately for each domain along with their possible future research directions.
Braille to Text Translation for Bengali Language: A Geometric Approach
Dec 02, 2020
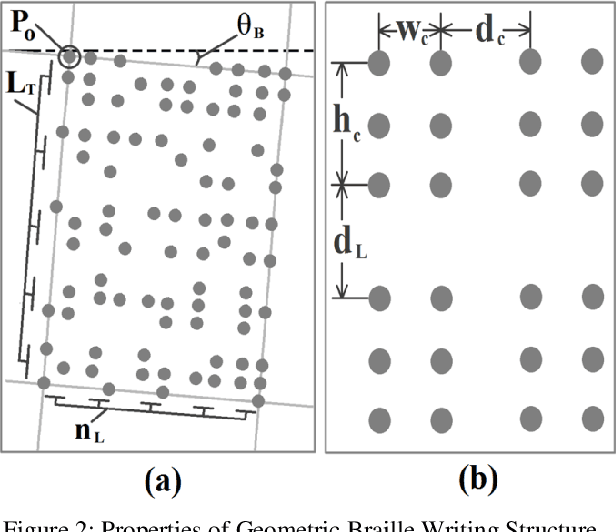
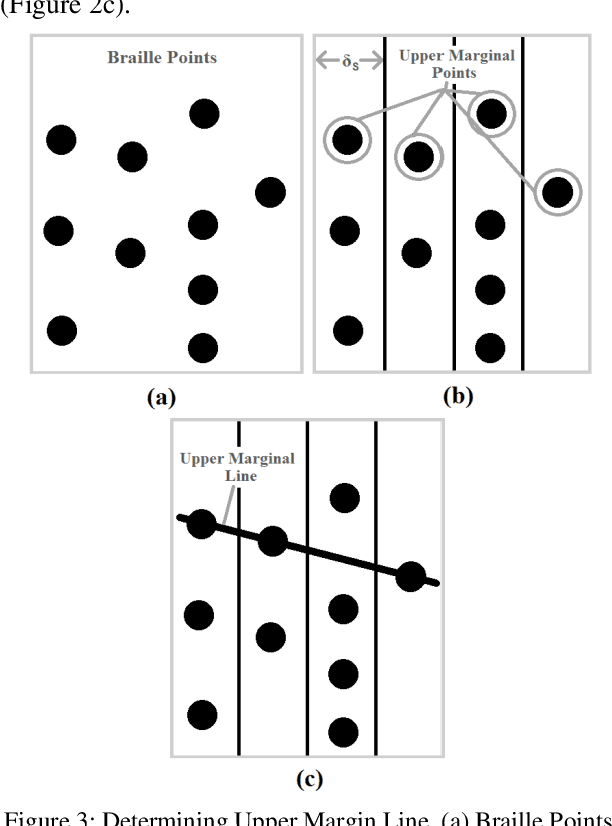
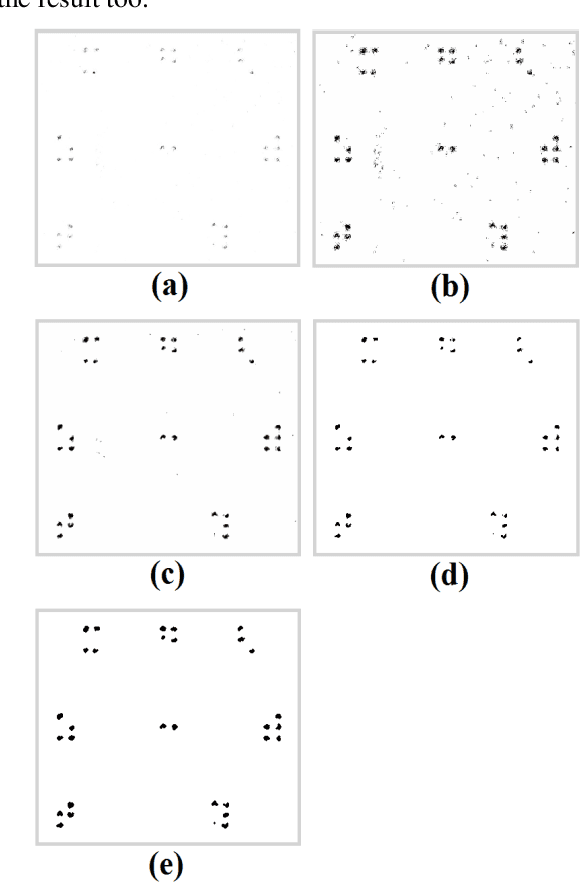
Braille is the only system to visually impaired people for reading and writing. However, general people cannot read Braille. So, teachers and relatives find it hard to assist them with learning. Almost every major language has software solutions for this translation purpose. However, in Bengali there is an absence of this useful tool. Here, we propose Braille to Text Translator, which takes image of these tactile alphabets, and translates them to plain text. Image deterioration, scan-time page rotation, and braille dot deformation are the principal issues in this scheme. All of these challenges are directly checked using special image processing and geometric structure analysis. The technique yields 97.25% accuracy in recognizing Braille characters.