 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Barcode Method for Generative Model Evaluation driven by Topological Data Analysis
Jun 04, 2021
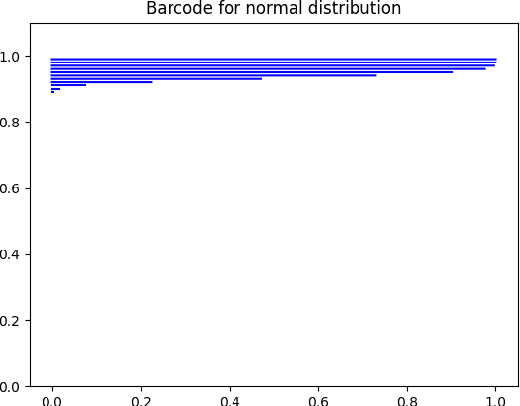

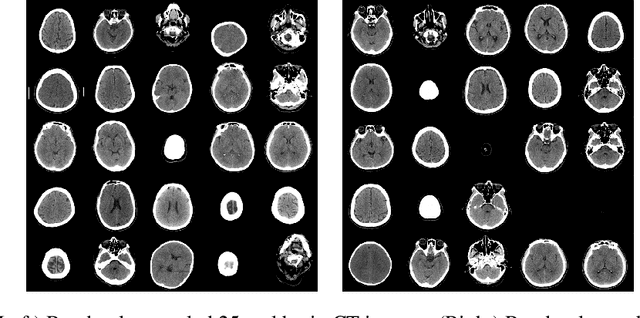
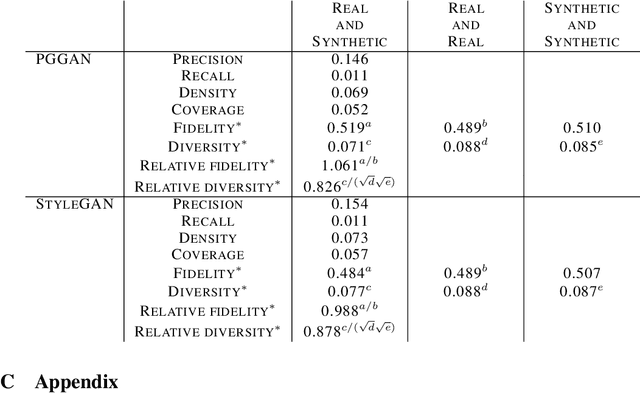
Evaluating the performance of generative models in image synthesis is a challenging task. Although the Fr\'echet Inception Distance is a widely accepted evaluation metric, it integrates different aspects (e.g., fidelity and diversity) of synthesized images into a single score and assumes the normality of embedded vectors. Recent methods such as precision-and-recall and its variants such as density-and-coverage have been developed to separate fidelity and diversity based on k-nearest neighborhood methods. In this study, we propose an algorithm named barcode, which is inspired by the topological data analysis and is almost free of assumption and hyperparameter selections. In extensive experiments on real-world datasets as well as theoretical approach on high-dimensional normal samples, it was found that the 'usual' normality assumption of embedded vectors has several drawbacks. The experimental results demonstrate that barcode outperforms other methods in evaluating fidelity and diversity of GAN outputs. Official codes can be found in https://github.com/minjeekim00/Barcode.
Semi-supervised Keypoint Localization
Jan 20, 2021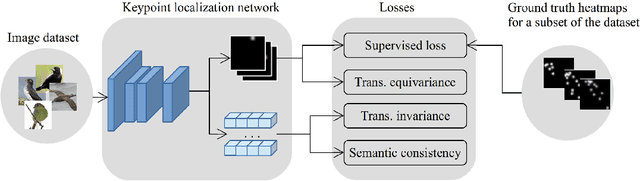

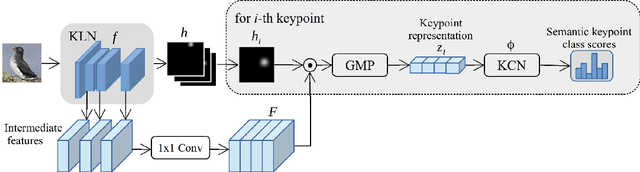
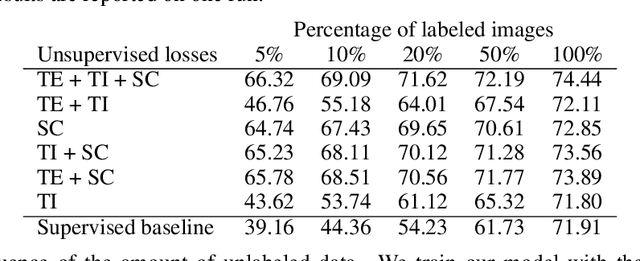
Knowledge about the locations of keypoints of an object in an image can assist in fine-grained classification and identification tasks, particularly for the case of objects that exhibit large variations in poses that greatly influence their visual appearance, such as wild animals. However, supervised training of a keypoint detection network requires annotating a large image dataset for each animal species, which is a labor-intensive task. To reduce the need for labeled data, we propose to learn simultaneously keypoint heatmaps and pose invariant keypoint representations in a semi-supervised manner using a small set of labeled images along with a larger set of unlabeled images. Keypoint representations are learnt with a semantic keypoint consistency constraint that forces the keypoint detection network to learn similar features for the same keypoint across the dataset. Pose invariance is achieved by making keypoint representations for the image and its augmented copies closer together in feature space. Our semi-supervised approach significantly outperforms previous methods on several benchmarks for human and animal body landmark localization.
Sanity Simulations for Saliency Methods
May 13, 2021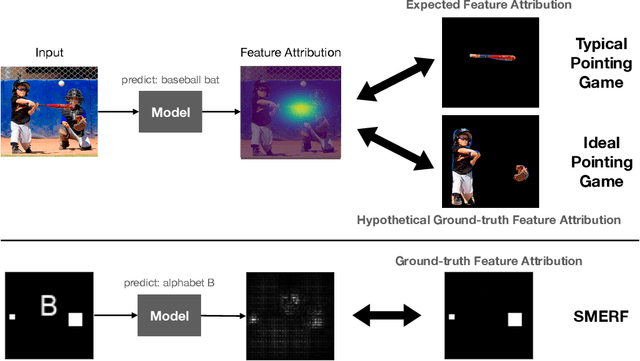
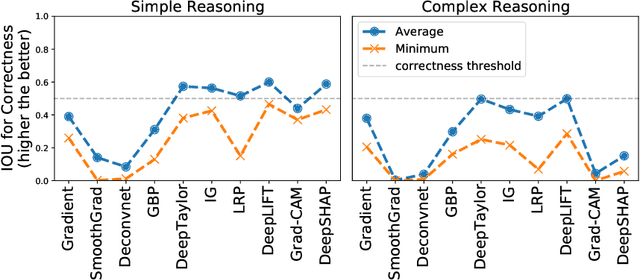
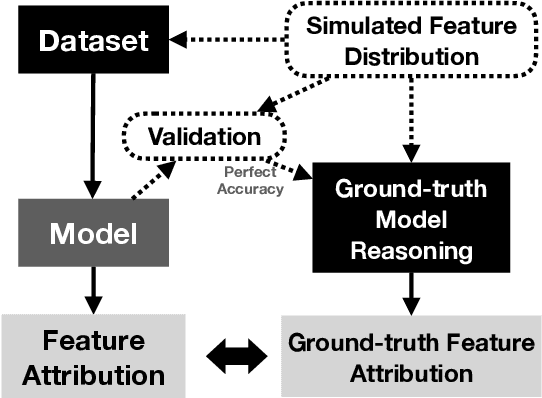
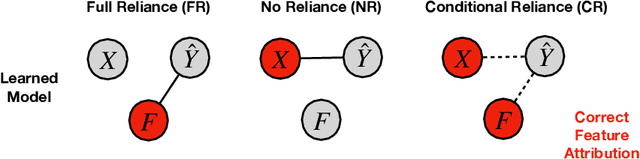
Saliency methods are a popular class of feature attribution tools that aim to capture a model's predictive reasoning by identifying "important" pixels in an input image. However, the development and adoption of saliency methods are currently hindered by the lack of access to underlying model reasoning, which prevents accurate method evaluation. In this work, we design a synthetic evaluation framework, SMERF, that allows us to perform ground-truth-based evaluation of saliency methods while controlling the underlying complexity of model reasoning. Experimental evaluations via SMERF reveal significant limitations in existing saliency methods, especially given the relative simplicity of SMERF's synthetic evaluation tasks. Moreover, the SMERF benchmarking suite represents a useful tool in the development of new saliency methods to potentially overcome these limitations.
Combiner: Full Attention Transformer with Sparse Computation Cost
Jul 12, 2021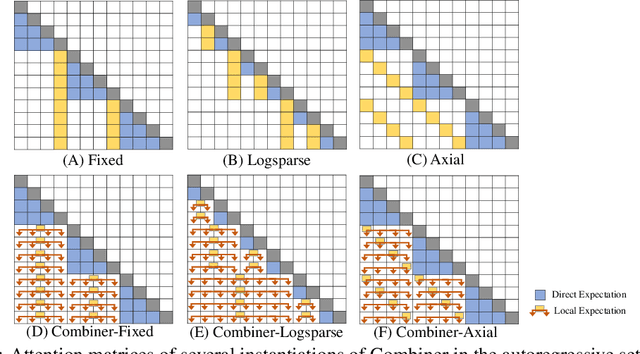
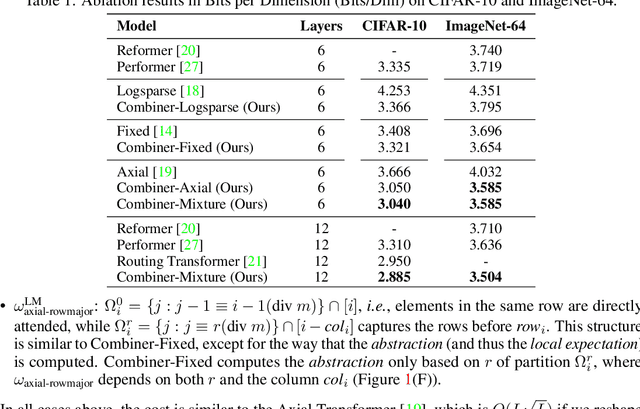
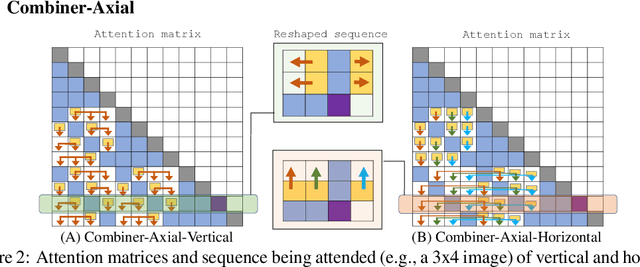

Transformers provide a class of expressive architectures that are extremely effective for sequence modeling. However, the key limitation of transformers is their quadratic memory and time complexity $\mathcal{O}(L^2)$ with respect to the sequence length in attention layers, which restricts application in extremely long sequences. Most existing approaches leverage sparsity or low-rank assumptions in the attention matrix to reduce cost, but sacrifice expressiveness. Instead, we propose Combiner, which provides full attention capability in each attention head while maintaining low computation and memory complexity. The key idea is to treat the self-attention mechanism as a conditional expectation over embeddings at each location, and approximate the conditional distribution with a structured factorization. Each location can attend to all other locations, either via direct attention, or through indirect attention to abstractions, which are again conditional expectations of embeddings from corresponding local regions. We show that most sparse attention patterns used in existing sparse transformers are able to inspire the design of such factorization for full attention, resulting in the same sub-quadratic cost ($\mathcal{O}(L\log(L))$ or $\mathcal{O}(L\sqrt{L})$). Combiner is a drop-in replacement for attention layers in existing transformers and can be easily implemented in common frameworks. An experimental evaluation on both autoregressive and bidirectional sequence tasks demonstrates the effectiveness of this approach, yielding state-of-the-art results on several image and text modeling tasks.
LocalTrans: A Multiscale Local Transformer Network for Cross-Resolution Homography Estimation
Jun 13, 2021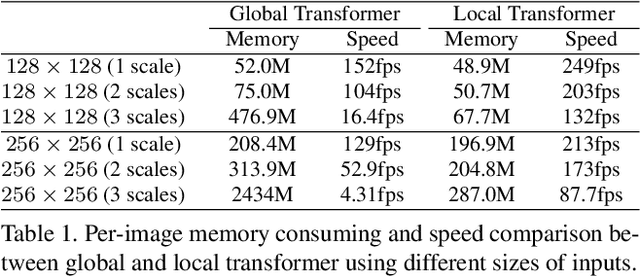
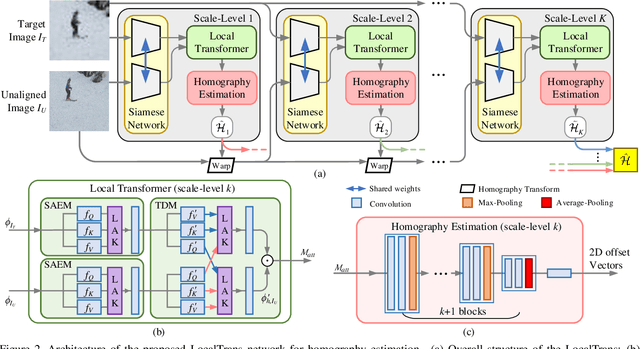
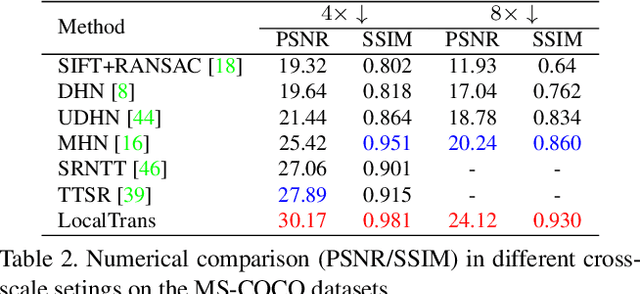
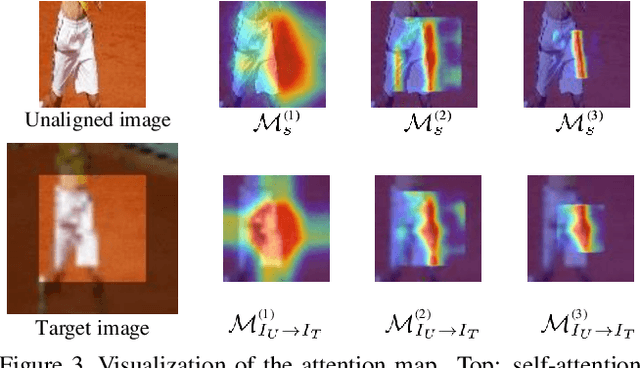
Cross-resolution image alignment is a key problem in multiscale gigapixel photography, which requires to estimate homography matrix using images with large resolution gap. Existing deep homography methods concatenate the input images or features, neglecting the explicit formulation of correspondences between them, which leads to degraded accuracy in cross-resolution challenges. In this paper, we consider the cross-resolution homography estimation as a multimodal problem, and propose a local transformer network embedded within a multiscale structure to explicitly learn correspondences between the multimodal inputs, namely, input images with different resolutions. The proposed local transformer adopts a local attention map specifically for each position in the feature. By combining the local transformer with the multiscale structure, the network is able to capture long-short range correspondences efficiently and accurately. Experiments on both the MS-COCO dataset and the real-captured cross-resolution dataset show that the proposed network outperforms existing state-of-the-art feature-based and deep-learning-based homography estimation methods, and is able to accurately align images under $10\times$ resolution gap.
Rolling-Shutter-Aware Differential SfM and Image Rectification
Mar 10, 2019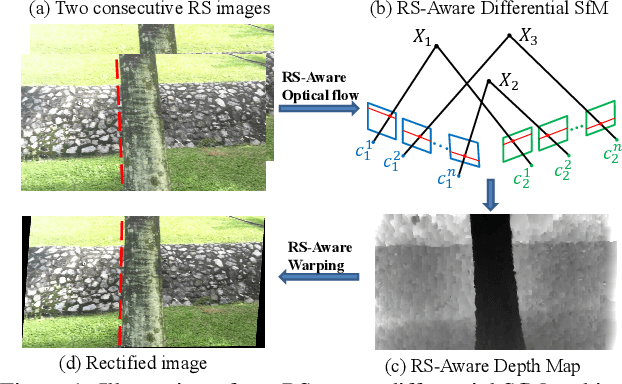
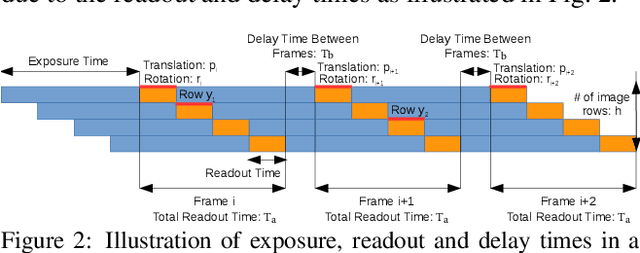

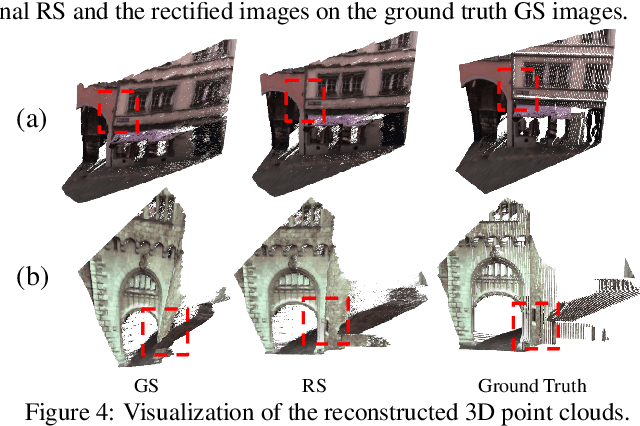
In this paper, we develop a modified differential Structure from Motion (SfM) algorithm that can estimate relative pose from two consecutive frames despite of Rolling Shutter (RS) artifacts. In particular, we show that under constant velocity assumption, the errors induced by the rolling shutter effect can be easily rectified by a linear scaling operation on each optical flow. We further propose a 9-point algorithm to recover the relative pose of a rolling shutter camera that undergoes constant acceleration motion. We demonstrate that the dense depth maps recovered from the relative pose of the RS camera can be used in a RS-aware warping for image rectification to recover high-quality Global Shutter (GS) images. Experiments on both synthetic and real RS images show that our RS-aware differential SfM algorithm produces more accurate results on relative pose estimation and 3D reconstruction from images distorted by RS effect compared to standard SfM algorithms that assume a GS camera model. We also demonstrate that our RS-aware warping for image rectification method outperforms state-of-the-art commercial software products, i.e. Adobe After Effects and Apple Imovie, at removing RS artifacts.
An Interaction-based Convolutional Neural Network (ICNN) Towards Better Understanding of COVID-19 X-ray Images
Jun 13, 2021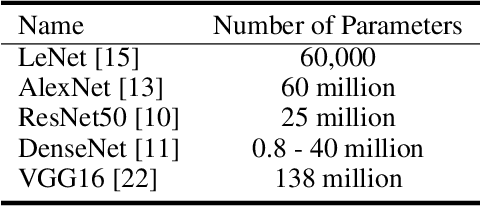
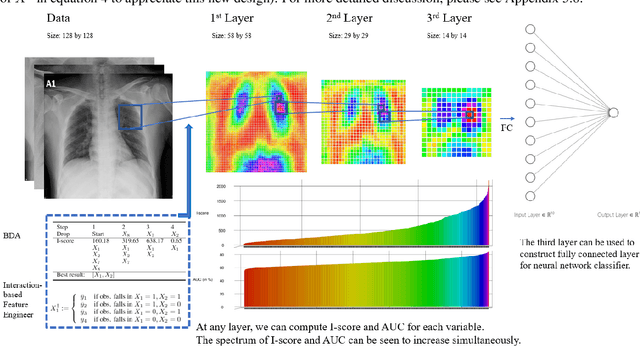

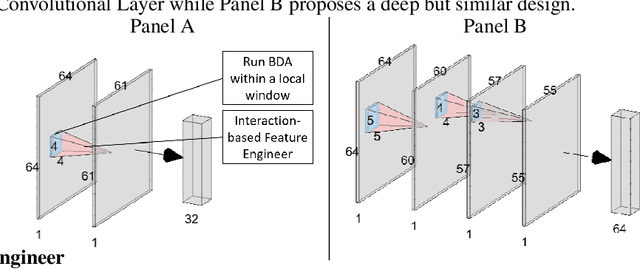
The field of Explainable Artificial Intelligence (XAI) aims to build explainable and interpretable machine learning (or deep learning) methods without sacrificing prediction performance. Convolutional Neural Networks (CNNs) have been successful in making predictions, especially in image classification. However, these famous deep learning models use tens of millions of parameters based on a large number of pre-trained filters which have been repurposed from previous data sets. We propose a novel Interaction-based Convolutional Neural Network (ICNN) that does not make assumptions about the relevance of local information. Instead, we use a model-free Influence Score (I-score) to directly extract the influential information from images to form important variable modules. We demonstrate that the proposed method produces state-of-the-art prediction performance of 99.8% on a real-world data set classifying COVID-19 Chest X-ray images without sacrificing the explanatory power of the model. This proposed design can efficiently screen COVID-19 patients before human diagnosis, and will be the benchmark for addressing future XAI problems in large-scale data sets.
Trends in deep learning for medical hyperspectral image analysis
Nov 27, 2020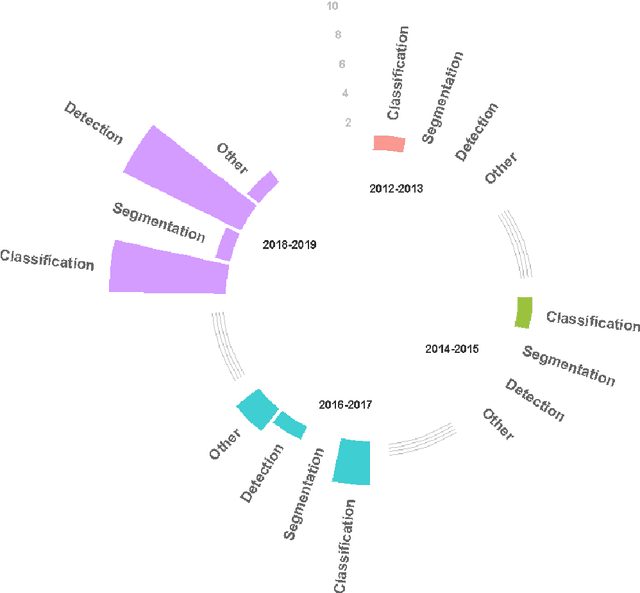
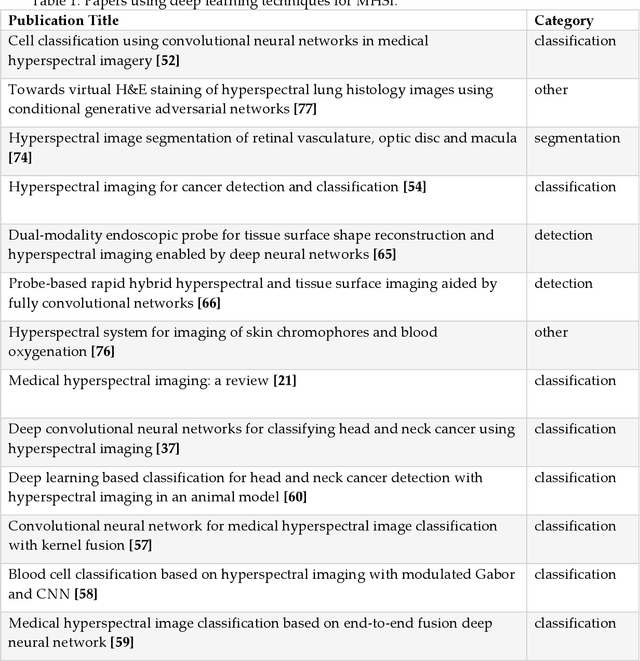
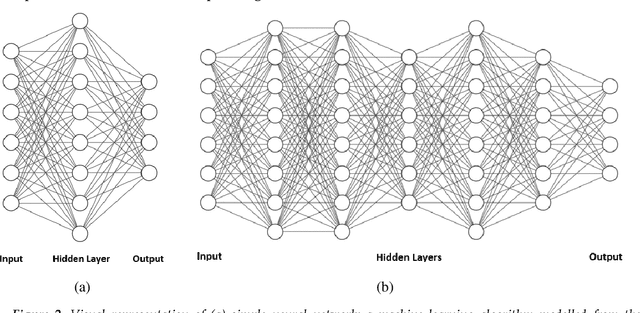
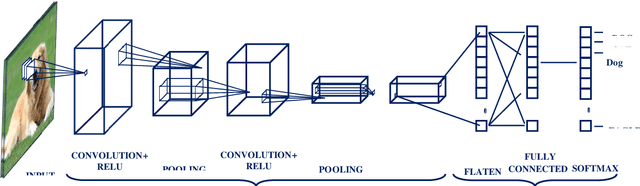
Deep learning algorithms have seen acute growth of interest in their applications throughout several fields of interest in the last decade, with medical hyperspectral imaging being a particularly promising domain. So far, to the best of our knowledge, there is no review paper that discusses the implementation of deep learning for medical hyperspectral imaging, which is what this review paper aims to accomplish by examining publications that currently utilize deep learning to perform effective analysis of medical hyperspectral imagery. This paper discusses deep learning concepts that are relevant and applicable to medical hyperspectral imaging analysis, several of which have been implemented since the boom in deep learning. This will comprise of reviewing the use of deep learning for classification, segmentation, and detection in order to investigate the analysis of medical hyperspectral imaging. Lastly, we discuss the current and future challenges pertaining to this discipline and the possible efforts to overcome such trials.
FloorLevel-Net: Recognizing Floor-Level Lines with Height-Attention-Guided Multi-task Learning
Jul 06, 2021
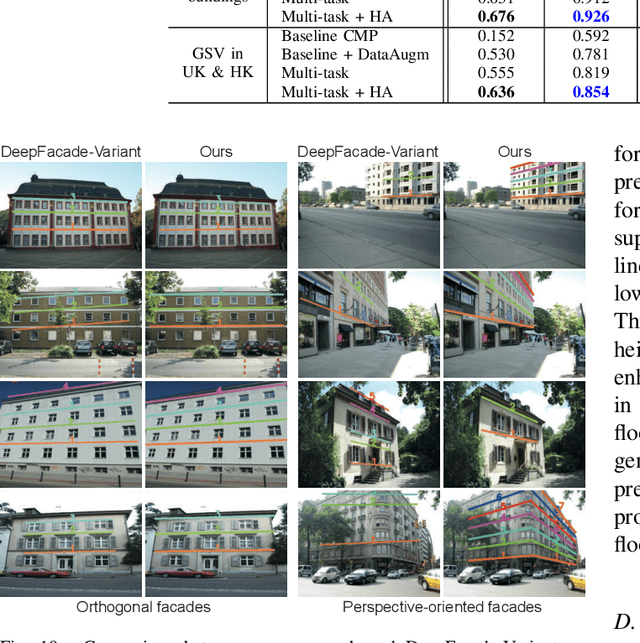


The ability to recognize the position and order of the floor-level lines that divide adjacent building floors can benefit many applications, for example, urban augmented reality (AR). This work tackles the problem of locating floor-level lines in street-view images, using a supervised deep learning approach. Unfortunately, very little data is available for training such a network $-$ current street-view datasets contain either semantic annotations that lack geometric attributes, or rectified facades without perspective priors. To address this issue, we first compile a new dataset and develop a new data augmentation scheme to synthesize training samples by harassing (i) the rich semantics of existing rectified facades and (ii) perspective priors of buildings in diverse street views. Next, we design FloorLevel-Net, a multi-task learning network that associates explicit features of building facades and implicit floor-level lines, along with a height-attention mechanism to help enforce a vertical ordering of floor-level lines. The generated segmentations are then passed to a second-stage geometry post-processing to exploit self-constrained geometric priors for plausible and consistent reconstruction of floor-level lines. Quantitative and qualitative evaluations conducted on assorted facades in existing datasets and street views from Google demonstrate the effectiveness of our approach. Also, we present context-aware image overlay results and show the potentials of our approach in enriching AR-related applications.
Tortured phrases: A dubious writing style emerging in science. Evidence of critical issues affecting established journals
Jul 12, 2021

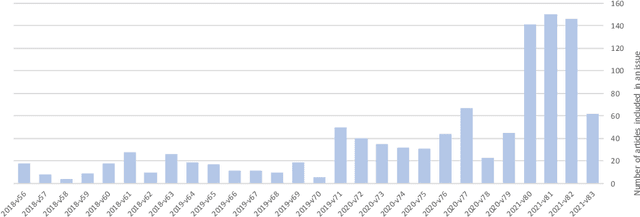
Probabilistic text generators have been used to produce fake scientific papers for more than a decade. Such nonsensical papers are easily detected by both human and machine. Now more complex AI-powered generation techniques produce texts indistinguishable from that of humans and the generation of scientific texts from a few keywords has been documented. Our study introduces the concept of tortured phrases: unexpected weird phrases in lieu of established ones, such as 'counterfeit consciousness' instead of 'artificial intelligence.' We combed the literature for tortured phrases and study one reputable journal where these concentrated en masse. Hypothesising the use of advanced language models we ran a detector on the abstracts of recent articles of this journal and on several control sets. The pairwise comparisons reveal a concentration of abstracts flagged as 'synthetic' in the journal. We also highlight irregularities in its operation, such as abrupt changes in editorial timelines. We substantiate our call for investigation by analysing several individual dubious articles, stressing questionable features: tortured writing style, citation of non-existent literature, and unacknowledged image reuse. Surprisingly, some websites offer to rewrite texts for free, generating gobbledegook full of tortured phrases. We believe some authors used rewritten texts to pad their manuscripts. We wish to raise the awareness on publications containing such questionable AI-generated or rewritten texts that passed (poor) peer review. Deception with synthetic texts threatens the integrity of the scientific literature.