 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DepthwiseGANs: Fast Training Generative Adversarial Networks for Realistic Image Synthesis
Mar 06, 2019

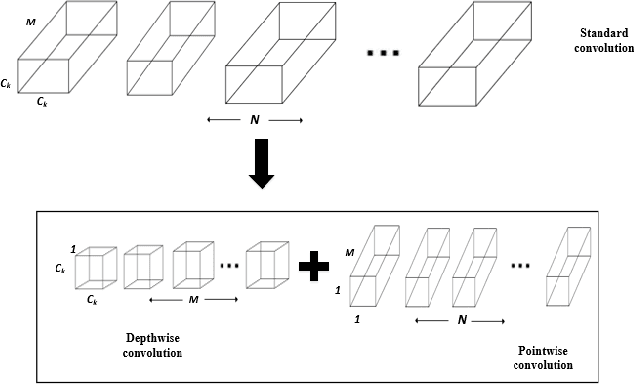
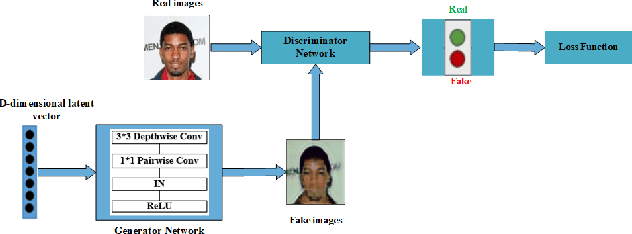
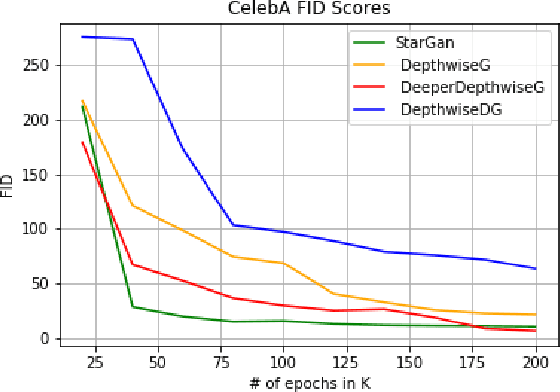
Recent work has shown significant progress in the direction of synthetic data generation using Generative Adversarial Networks (GANs). GANs have been applied in many fields of computer vision including text-to-image conversion, domain transfer, super-resolution, and image-to-video applications. In computer vision, traditional GANs are based on deep convolutional neural networks. However, deep convolutional neural networks can require extensive computational resources because they are based on multiple operations performed by convolutional layers, which can consist of millions of trainable parameters. Training a GAN model can be difficult and it takes a significant amount of time to reach an equilibrium point. In this paper, we investigate the use of depthwise separable convolutions to reduce training time while maintaining data generation performance. Our results show that a DepthwiseGAN architecture can generate realistic images in shorter training periods when compared to a StarGan architecture, but that model capacity still plays a significant role in generative modelling. In addition, we show that depthwise separable convolutions perform best when only applied to the generator. For quality evaluation of generated images, we use the Fr\'echet Inception Distance (FID), which compares the similarity between the generated image distribution and that of the training dataset.
Adversarial Image Translation: Unrestricted Adversarial Examples in Face Recognition Systems
May 27, 2019

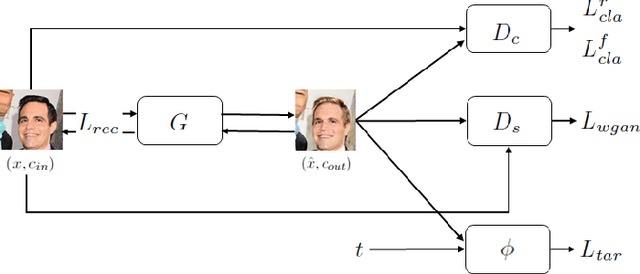

Thanks to recent advances in Deep Neural Networks (DNNs), face recognition systems have achieved high accuracy in classification of a large number of face images. However, recent works demonstrate that DNNs could be vulnerable to adversarial examples and raise concerns about robustness of face recognition systems. In particular adversarial examples that are not restricted to small perturbations could be more serious risks since conventional certified defenses might be ineffective against them. To shed light on the vulnerability to this type of adversarial examples, we propose a flexible and efficient method to generate unrestricted adversarial examples using image translation techniques. Our method enables us to translate a source image into any desired facial appearance with large perturbations so that target face recognition systems could be deceived. Through our experiments, we demonstrate that our method achieves about 90% and 30% attack success rates under a white- and black-box setting, respectively. We also illustrate that our translated images are perceptually realistic and maintain personal identity while the perturbations are large enough to bypass certified defenses.
Shifts: A Dataset of Real Distributional Shift Across Multiple Large-Scale Tasks
Jul 15, 2021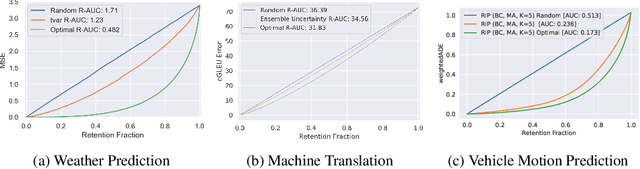
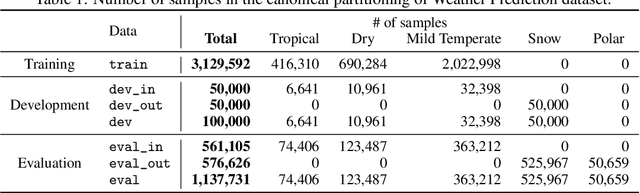
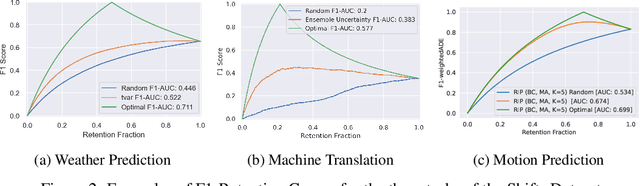
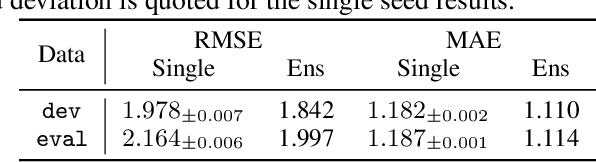
There has been significant research done on developing methods for improving robustness to distributional shift and uncertainty estimation. In contrast, only limited work has examined developing standard datasets and benchmarks for assessing these approaches. Additionally, most work on uncertainty estimation and robustness has developed new techniques based on small-scale regression or image classification tasks. However, many tasks of practical interest have different modalities, such as tabular data, audio, text, or sensor data, which offer significant challenges involving regression and discrete or continuous structured prediction. Thus, given the current state of the field, a standardized large-scale dataset of tasks across a range of modalities affected by distributional shifts is necessary. This will enable researchers to meaningfully evaluate the plethora of recently developed uncertainty quantification methods, as well as assessment criteria and state-of-the-art baselines. In this work, we propose the \emph{Shifts Dataset} for evaluation of uncertainty estimates and robustness to distributional shift. The dataset, which has been collected from industrial sources and services, is composed of three tasks, with each corresponding to a particular data modality: tabular weather prediction, machine translation, and self-driving car (SDC) vehicle motion prediction. All of these data modalities and tasks are affected by real, `in-the-wild' distributional shifts and pose interesting challenges with respect to uncertainty estimation. In this work we provide a description of the dataset and baseline results for all tasks.
Brain Tumor Image Retrieval via Multitask Learning
Oct 22, 2018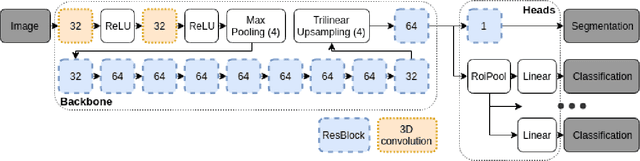
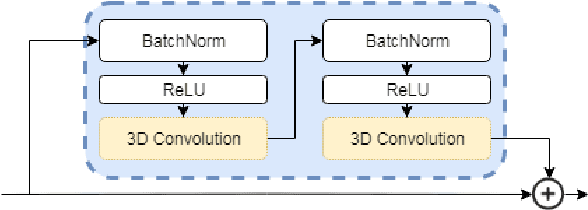

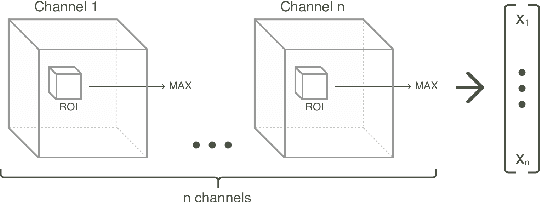
Classification-based image retrieval systems are built by training convolutional neural networks (CNNs) on a relevant classification problem and using the distance in the resulting feature space as a similarity metric. However, in practical applications, it is often desirable to have representations which take into account several aspects of the data (e.g., brain tumor type and its localization). In our work, we extend the classification-based approach with multitask learning: we train a CNN on brain MRI scans with heterogeneous labels and implement a corresponding tumor image retrieval system. We validate our approach on brain tumor data which contains information about tumor types, shapes and localization. We show that our method allows us to build representations that contain more relevant information about tumors than single-task classification-based approaches.
Deep learning with photosensor timing information as a background rejection method for the Cherenkov Telescope Array
Mar 10, 2021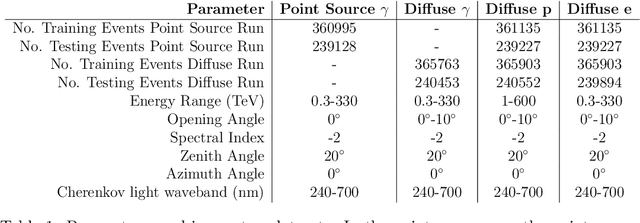
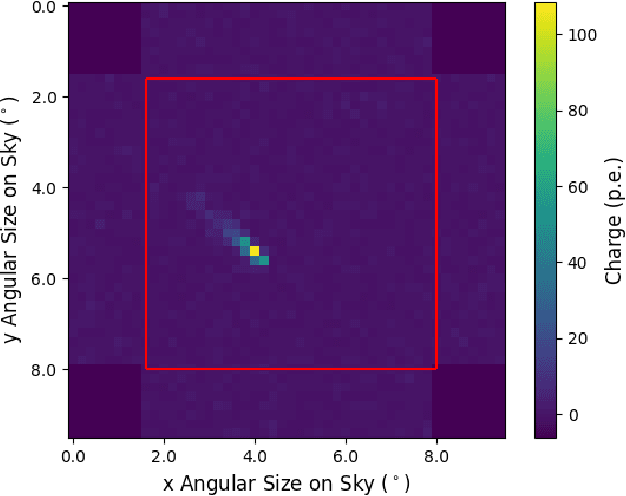
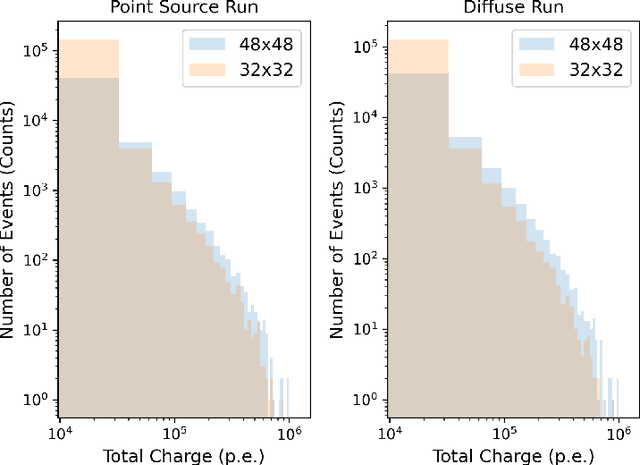

New deep learning techniques present promising new analysis methods for Imaging Atmospheric Cherenkov Telescopes (IACTs) such as the upcoming Cherenkov Telescope Array (CTA). In particular, the use of Convolutional Neural Networks (CNNs) could provide a direct event classification method that uses the entire information contained within the Cherenkov shower image, bypassing the need to Hillas parameterise the image and allowing fast processing of the data. Existing work in this field has utilised images of the integrated charge from IACT camera photomultipliers, however the majority of current and upcoming generation IACT cameras have the capacity to read out the entire photosensor waveform following a trigger. As the arrival times of Cherenkov photons from Extensive Air Showers (EAS) at the camera plane are dependent upon the altitude of their emission and the impact distance from the telescope, these waveforms contain information potentially useful for IACT event classification. In this test-of-concept simulation study, we investigate the potential for using these camera pixel waveforms with new deep learning techniques as a background rejection method, against both proton and electron induced EAS. We find that a means of utilising their information is to create a set of seven additional 2-dimensional pixel maps of waveform parameters, to be fed into the machine learning algorithm along with the integrated charge image. Whilst we ultimately find that the only classification power against electrons is based upon event direction, methods based upon timing information appear to out-perform similar charge based methods for gamma/hadron separation. We also review existing methods of event classifications using a combination of deep learning and timing information in other astroparticle physics experiments.
Data Efficient Unsupervised Domain Adaptation for Cross-Modality Image Segmentation
Jul 05, 2019
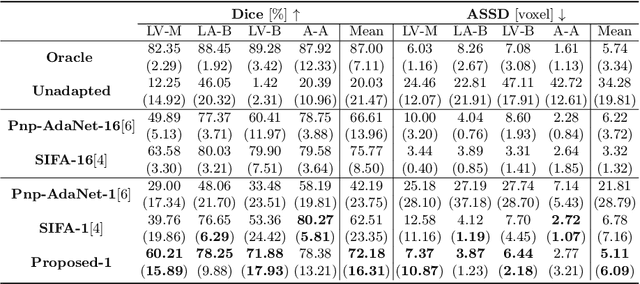
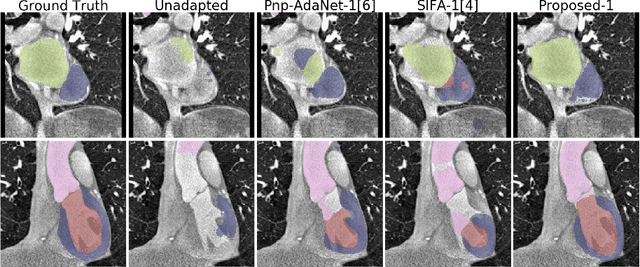
Deep learning models trained on medical images from a source domain (e.g. imaging modality) often fail when deployed on images from a different target domain, despite imaging common anatomical structures. Deep unsupervised domain adaptation (UDA) aims to improve the performance of a deep neural network model on a target domain, using solely unlabelled target domain data and labelled source domain data. However, current state-of-the-art methods exhibit reduced performance when target data is scarce. In this work, we introduce a new data efficient UDA method for multi-domain medical image segmentation. The proposed method combines a novel VAE-based feature prior matching, which is data-efficient, and domain adversarial training to learn a shared domain-invariant latent space which is exploited during segmentation. Our method is evaluated on a public multi-modality cardiac image segmentation dataset by adapting from the labelled source domain (3D MRI) to the unlabelled target domain (3D CT). We show that by using only one single unlabelled 3D CT scan, the proposed architecture outperforms the state-of-the-art in the same setting. Finally, we perform ablation studies on prior matching and domain adversarial training to shed light on the theoretical grounding of the proposed method.
Auto-Encoding Scene Graphs for Image Captioning
Dec 11, 2018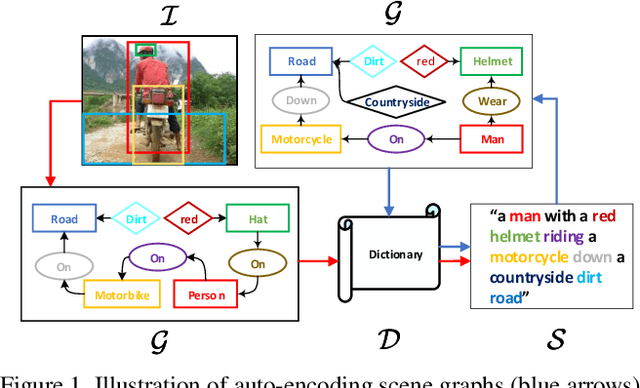
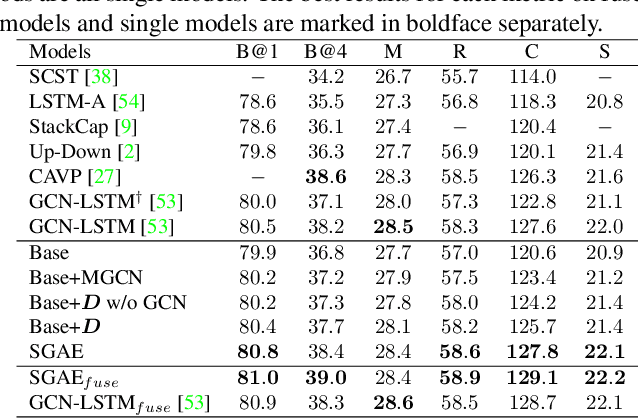
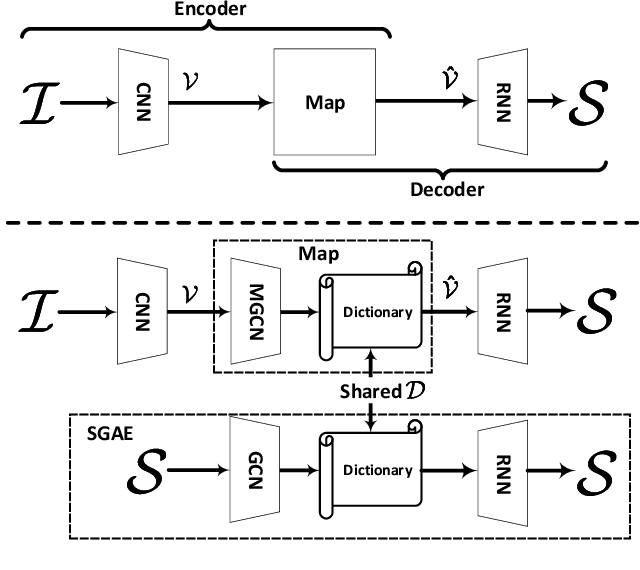
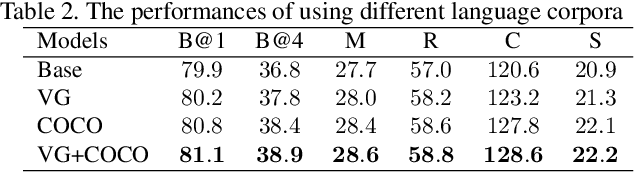
We propose Scene Graph Auto-Encoder (SGAE) that incorporates the language inductive bias into the encoder-decoder image captioning framework for more human-like captions. Intuitively, we humans use the inductive bias to compose collocations and contextual inference in discourse. For example, when we see the relation `person on bike', it is natural to replace `on' with `ride' and infer `person riding bike on a road' even the `road' is not evident. Therefore, exploiting such bias as a language prior is expected to help the conventional encoder-decoder models less likely overfit to the dataset bias and focus on reasoning. Specifically, we use the scene graph --- a directed graph ($\mathcal{G}$) where an object node is connected by adjective nodes and relationship nodes --- to represent the complex structural layout of both image ($\mathcal{I}$) and sentence ($\mathcal{S}$). In the textual domain, we use SGAE to learn a dictionary ($\mathcal{D}$) that helps to reconstruct sentences in the $\mathcal{S}\rightarrow \mathcal{G} \rightarrow \mathcal{D} \rightarrow \mathcal{S}$ pipeline, where $\mathcal{D}$ encodes the desired language prior; in the vision-language domain, we use the shared $\mathcal{D}$ to guide the encoder-decoder in the $\mathcal{I}\rightarrow \mathcal{G}\rightarrow \mathcal{D} \rightarrow \mathcal{S}$ pipeline. Thanks to the scene graph representation and shared dictionary, the inductive bias is transferred across domains in principle. We validate the effectiveness of SGAE on the challenging MS-COCO image captioning benchmark, e.g., our SGAE-based single-model achieves a new state-of-the-art $127.8$ CIDEr-D on the Karpathy split, and a competitive $125.5$ CIDEr-D (c40) on the official server even compared to other ensemble models.
Synthesizing Novel Pairs of Image and Text
Dec 18, 2017
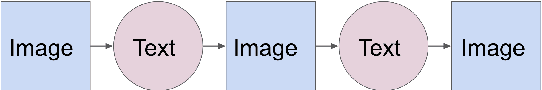

Generating novel pairs of image and text is a problem that combines computer vision and natural language processing. In this paper, we present strategies for generating novel image and caption pairs based on existing captioning datasets. The model takes advantage of recent advances in generative adversarial networks and sequence-to-sequence modeling. We make generalizations to generate paired samples from multiple domains. Furthermore, we study cycles -- generating from image to text then back to image and vise versa, as well as its connection with autoencoders.
Assessment of Subjective and Objective Quality of Live Streaming Sports Videos
Jun 15, 2021
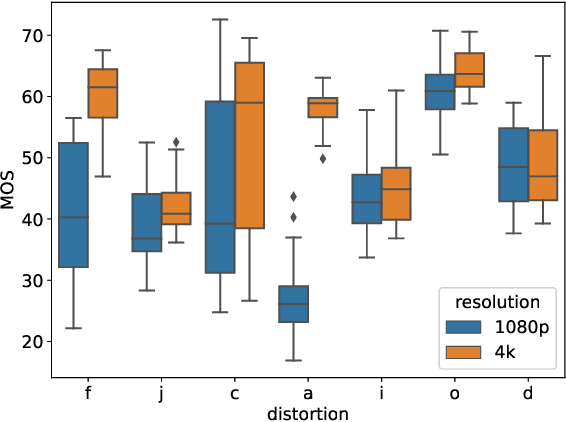
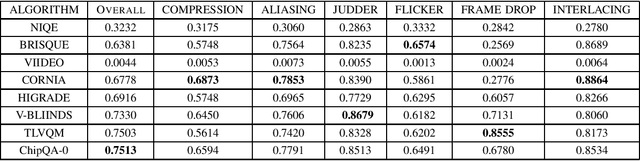
Video live streaming is gaining prevalence among video streaming services, especially for the delivery of popular sporting events. Many objective Video Quality Assessment (VQA) models have been developed to predict the perceptual quality of videos. Appropriate databases that exemplify the distortions encountered in live streaming videos are important to designing and learning objective VQA models. Towards making progress in this direction, we built a video quality database specifically designed for live streaming VQA research. The new video database is called the Laboratory for Image and Video Engineering (LIVE) Live stream Database. The LIVE Livestream Database includes 315 videos of 45 contents impaired by 6 types of distortions. We also performed a subjective quality study using the new database, whereby more than 12,000 human opinions were gathered from 40 subjects. We demonstrate the usefulness of the new resource by performing a holistic evaluation of the performance of current state-of-the-art (SOTA) VQA models. The LIVE Livestream database is being made publicly available for these purposes at https://live.ece.utexas.edu/research/LIVE_APV_Study/apv_index.html.
EGGS: Eigen-Gap Guided Search Making Subspace Clustering Easy
Jul 27, 2021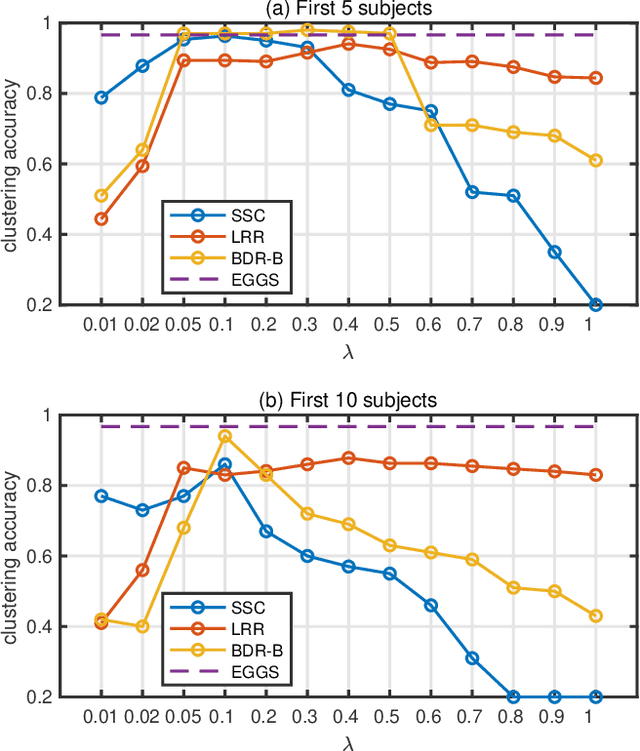
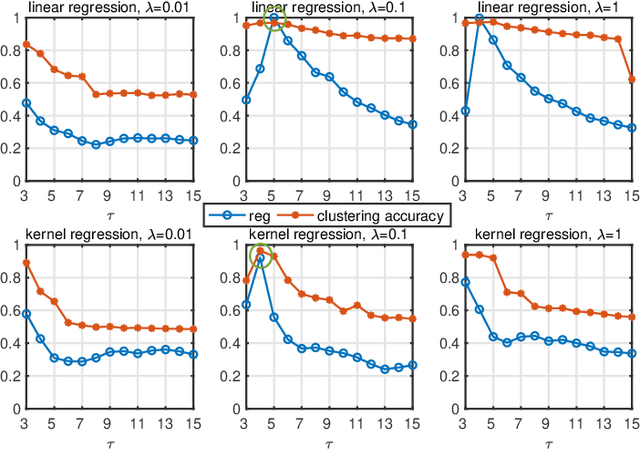
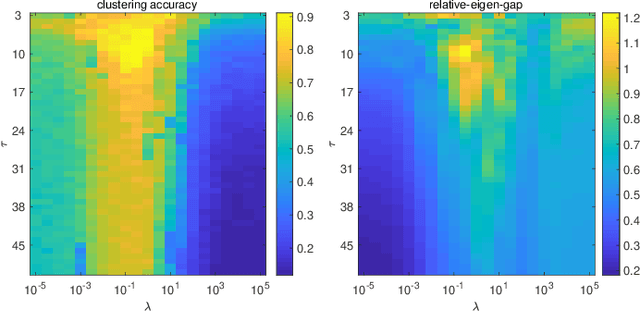
The performance of spectral clustering heavily relies on the quality of affinity matrix. A variety of affinity-matrix-construction methods have been proposed but they have hyper-parameters to determine beforehand, which requires strong experience and lead to difficulty in real applications especially when the inter-cluster similarity is high or/and the dataset is large. On the other hand, we often have to determine to use a linear model or a nonlinear model, which still depends on experience. To solve these two problems, in this paper, we present an eigen-gap guided search method for subspace clustering. The main idea is to find the most reliable affinity matrix among a set of candidates constructed by linear and kernel regressions, where the reliability is quantified by the \textit{relative-eigen-gap} of graph Laplacian defined in this paper. We show, theoretically and numerically, that the Laplacian matrix with a larger relative-eigen-gap often yields a higher clustering accuracy and stability. Our method is able to automatically search the best model and hyper-parameters in a pre-defined space. The search space is very easy to determine and can be arbitrarily large, though a relatively compact search space can reduce the highly unnecessary computation. Our method has high flexibility and convenience in real applications, and also has low computational cost because the affinity matrix is not computed by iterative optimization. We extend the method to large-scale datasets such as MNIST, on which the time cost is less than 90s and the clustering accuracy is state-of-the-art. Extensive experiments of natural image clustering show that our method is more stable, accurate, and efficient than baseline methods.