 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias Remediation in Driver Drowsiness Detection systems using Generative Adversarial Networks
Dec 10, 2019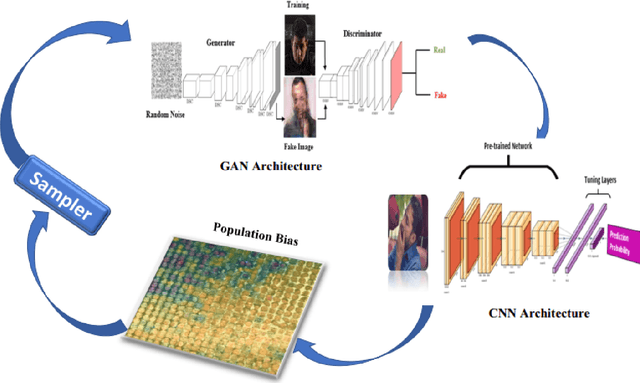
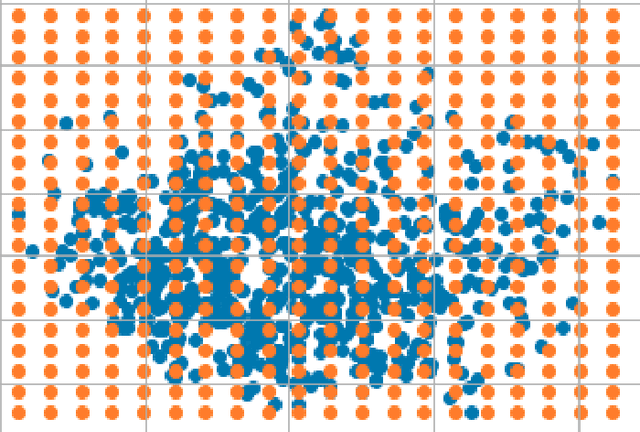


Datasets are crucial when training a deep neural network. When datasets are unrepresentative, trained models are prone to bias because they are unable to generalise to real world settings. This is particularly problematic for models trained in specific cultural contexts, which may not represent a wide range of races, and thus fail to generalise. This is a particular challenge for Driver drowsiness detection, where many publicly available datasets are unrepresentative as they cover only certain ethnicity groups. Traditional augmentation methods are unable to improve a model's performance when tested on other groups with different facial attributes, and it is often challenging to build new, more representative datasets. In this paper, we introduce a novel framework that boosts the performance of detection of drowsiness for different ethnicity groups. Our framework improves Convolutional Neural Network (CNN) trained for prediction by using Generative Adversarial networks (GAN) for targeted data augmentation based on a population bias visualisation strategy that groups faces with similar facial attributes and highlights where the model is failing. A sampling method selects faces where the model is not performing well, which are used to fine-tune the CNN. Experiments show the efficacy of our approach in improving driver drowsiness detection for under represented ethnicity groups. Here, models trained on publicly available datasets are compared with a model trained using the proposed data augmentation strategy. Although developed in the context of driver drowsiness detection, the proposed framework is not limited to the driver drowsiness detection task, but can be applied to other applications.
DepthwiseGANs: Fast Training Generative Adversarial Networks for Realistic Image Synthesis
Mar 06, 2019
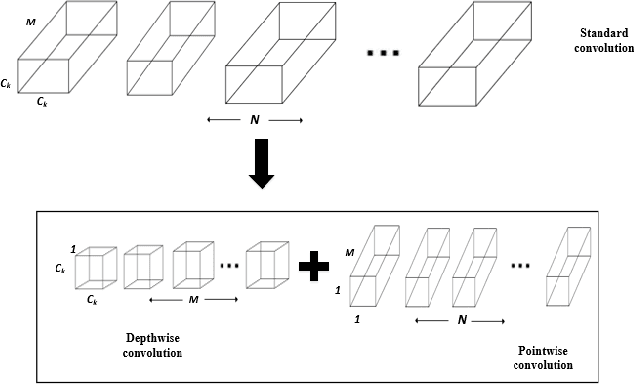
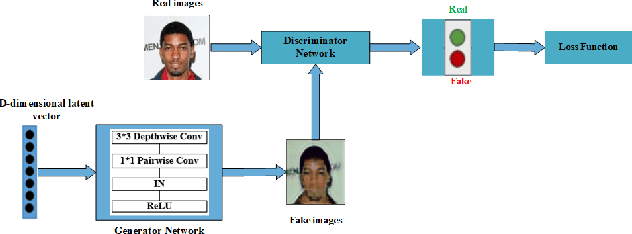
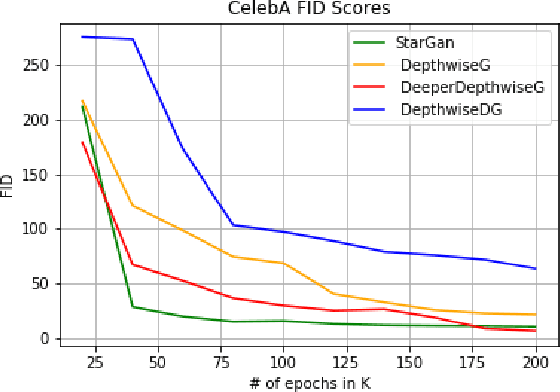
Recent work has shown significant progress in the direction of synthetic data generation using Generative Adversarial Networks (GANs). GANs have been applied in many fields of computer vision including text-to-image conversion, domain transfer, super-resolution, and image-to-video applications. In computer vision, traditional GANs are based on deep convolutional neural networks. However, deep convolutional neural networks can require extensive computational resources because they are based on multiple operations performed by convolutional layers, which can consist of millions of trainable parameters. Training a GAN model can be difficult and it takes a significant amount of time to reach an equilibrium point. In this paper, we investigate the use of depthwise separable convolutions to reduce training time while maintaining data generation performance. Our results show that a DepthwiseGAN architecture can generate realistic images in shorter training periods when compared to a StarGan architecture, but that model capacity still plays a significant role in generative modelling. In addition, we show that depthwise separable convolutions perform best when only applied to the generator. For quality evaluation of generated images, we use the Fr\'echet Inception Distance (FID), which compares the similarity between the generated image distribution and that of the training dataset.