 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Going Beyond Saliency Maps: Training Deep Models to Interpret Deep Models
Feb 16, 2021
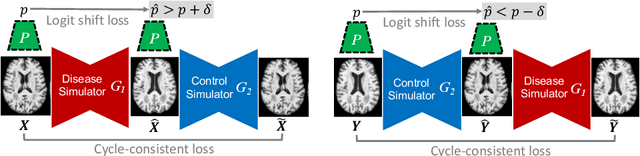
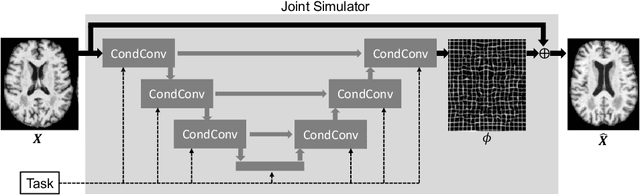
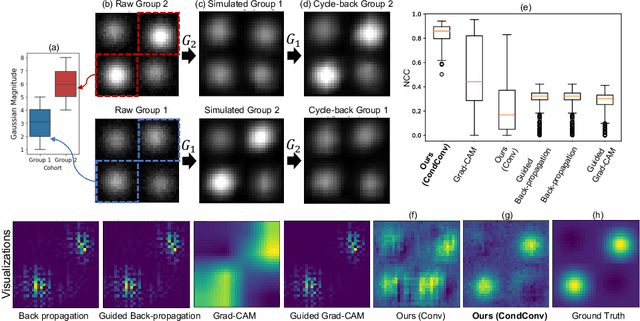
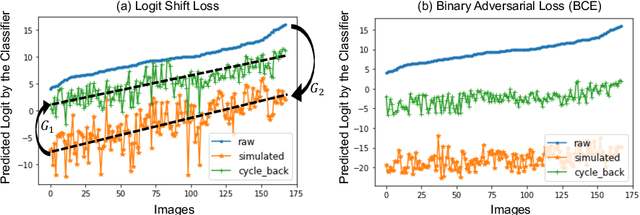
Interpretability is a critical factor in applying complex deep learning models to advance the understanding of brain disorders in neuroimaging studies. To interpret the decision process of a trained classifier, existing techniques typically rely on saliency maps to quantify the voxel-wise or feature-level importance for classification through partial derivatives. Despite providing some level of localization, these maps are not human-understandable from the neuroscience perspective as they do not inform the specific meaning of the alteration linked to the brain disorder. Inspired by the image-to-image translation scheme, we propose to train simulator networks that can warp a given image to inject or remove patterns of the disease. These networks are trained such that the classifier produces consistently increased or decreased prediction logits for the simulated images. Moreover, we propose to couple all the simulators into a unified model based on conditional convolution. We applied our approach to interpreting classifiers trained on a synthetic dataset and two neuroimaging datasets to visualize the effect of the Alzheimer's disease and alcohol use disorder. Compared to the saliency maps generated by baseline approaches, our simulations and visualizations based on the Jacobian determinants of the warping field reveal meaningful and understandable patterns related to the diseases.
Efficient Medical Image Segmentation with Intermediate Supervision Mechanism
Nov 15, 2020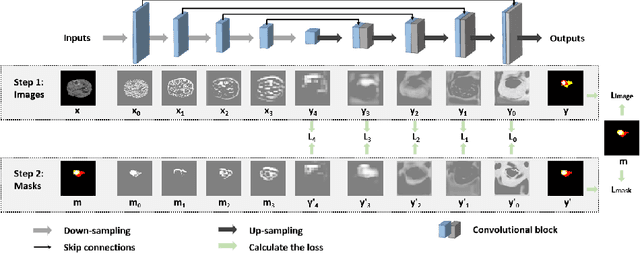
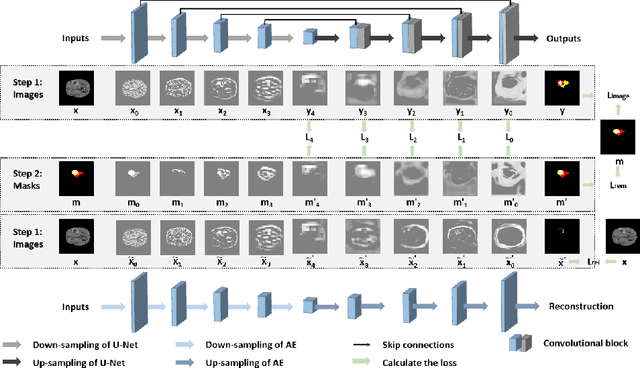
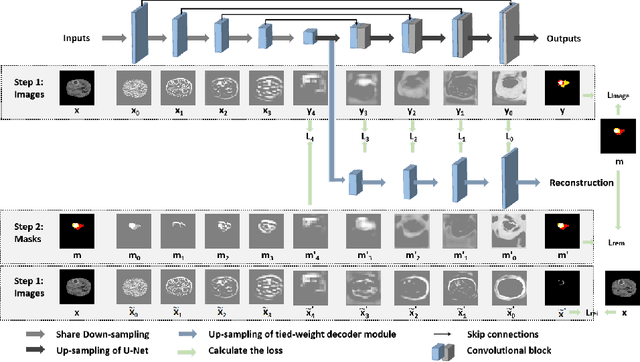
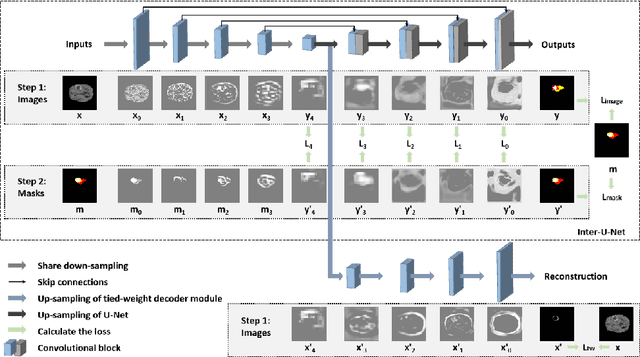
Because the expansion path of U-Net may ignore the characteristics of small targets, intermediate supervision mechanism is proposed. The original mask is also entered into the network as a label for intermediate output. However, U-Net is mainly engaged in segmentation, and the extracted features are also targeted at segmentation location information, and the input and output are different. The label we need is that the input and output are both original masks, which is more similar to the refactoring process, so we propose another intermediate supervision mechanism. However, the features extracted by the contraction path of this intermediate monitoring mechanism are not necessarily consistent. For example, U-Net's contraction path extracts transverse features, while auto-encoder extracts longitudinal features, which may cause the output of the expansion path to be inconsistent with the label. Therefore, we put forward the intermediate supervision mechanism of shared-weight decoder module. Although the intermediate supervision mechanism improves the segmentation accuracy, the training time is too long due to the extra input and multiple loss functions. For one of these problems, we have introduced tied-weight decoder. To reduce the redundancy of the model, we combine shared-weight decoder module with tied-weight decoder module.
A comparative study of various Deep Learning techniques for spatio-temporal Super-Resolution reconstruction of Forced Isotropic Turbulent flows
Jul 07, 2021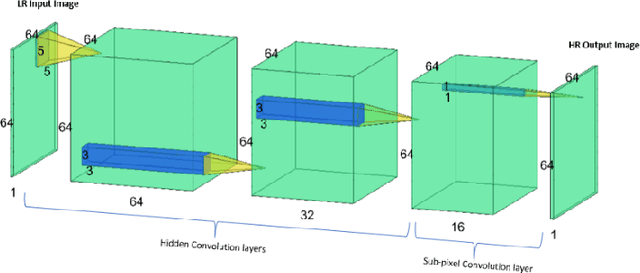
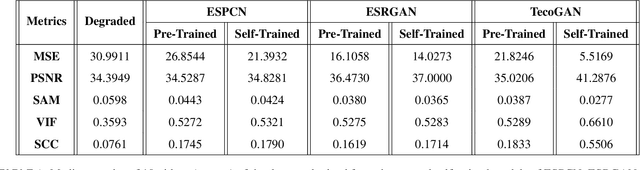
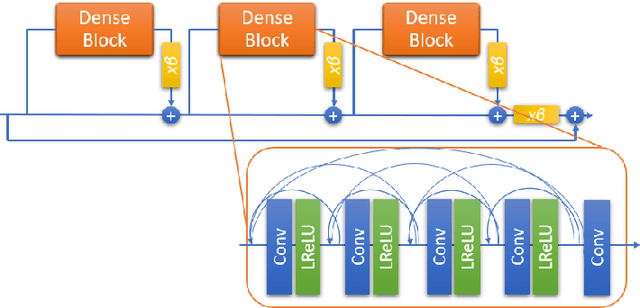
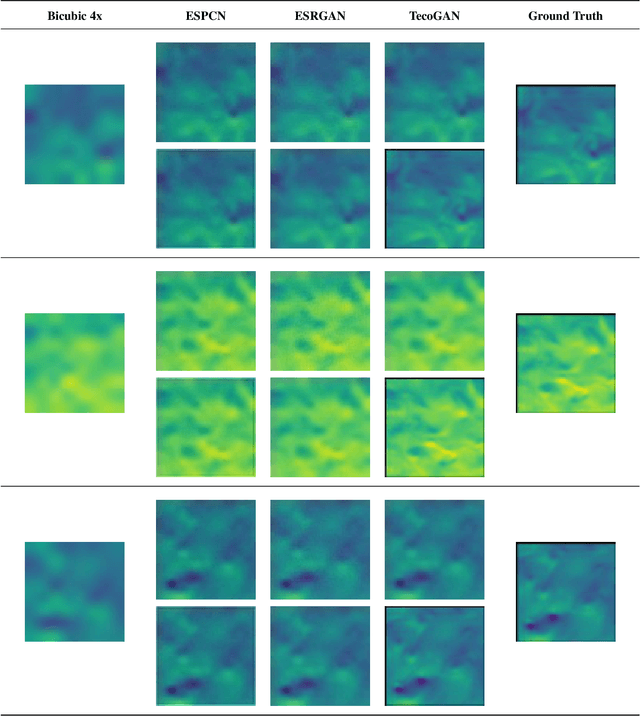
Super-resolution is an innovative technique that upscales the resolution of an image or a video and thus enables us to reconstruct high-fidelity images from low-resolution data. This study performs super-resolution analysis on turbulent flow fields spatially and temporally using various state-of-the-art machine learning techniques like ESPCN, ESRGAN and TecoGAN to reconstruct high-resolution flow fields from low-resolution flow field data, especially keeping in mind the need for low resource consumption and rapid results production/verification. The dataset used for this study is extracted from the 'isotropic 1024 coarse' dataset which is a part of Johns Hopkins Turbulence Databases (JHTDB). We have utilized pre-trained models and fine tuned them to our needs, so as to minimize the computational resources and the time required for the implementation of the super-resolution models. The advantages presented by this method far exceed the expectations and the outcomes of regular single structure models. The results obtained through these models are then compared using MSE, PSNR, SAM, VIF and SCC metrics in order to evaluate the upscaled results, find the balance between computational power and output quality, and then identify the most accurate and efficient model for spatial and temporal super-resolution of turbulent flow fields.
Ensemble Augmentation for Deep Neural Networks Using 1-D Time Series Vibration Data
Aug 06, 2021
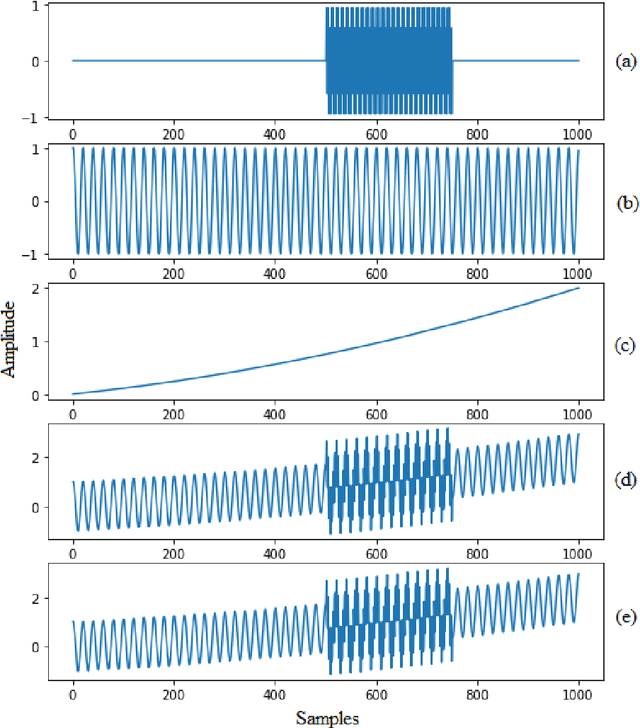
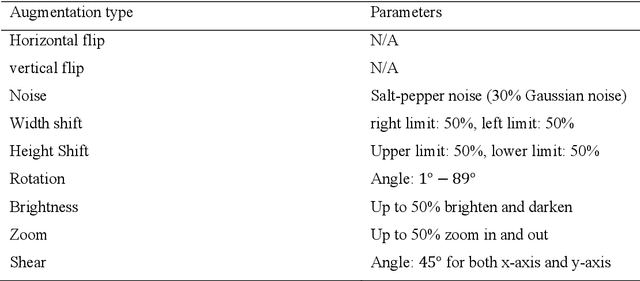
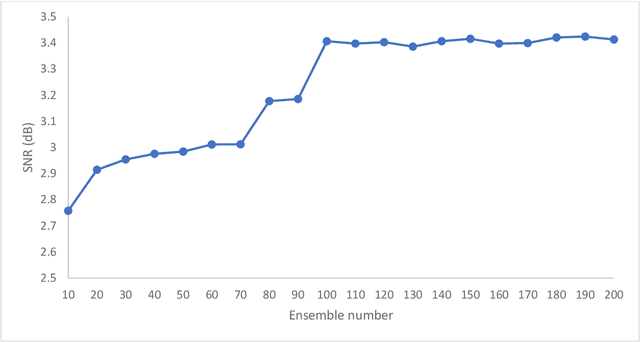
Time-series data are one of the fundamental types of raw data representation used in data-driven techniques. In machine condition monitoring, time-series vibration data are overly used in data mining for deep neural networks. Typically, vibration data is converted into images for classification using Deep Neural Networks (DNNs), and scalograms are the most effective form of image representation. However, the DNN classifiers require huge labeled training samples to reach their optimum performance. So, many forms of data augmentation techniques are applied to the classifiers to compensate for the lack of training samples. However, the scalograms are graphical representations where the existing augmentation techniques suffer because they either change the graphical meaning or have too much noise in the samples that change the physical meaning. In this study, a data augmentation technique named ensemble augmentation is proposed to overcome this limitation. This augmentation method uses the power of white noise added in ensembles to the original samples to generate real-like samples. After averaging the signal with ensembles, a new signal is obtained that contains the characteristics of the original signal. The parameters for the ensemble augmentation are validated using a simulated signal. The proposed method is evaluated using 10 class bearing vibration data using three state-of-the-art Transfer Learning (TL) models, namely, Inception-V3, MobileNet-V2, and ResNet50. Augmented samples are generated in two increments: the first increment generates the same number of fake samples as the training samples, and in the second increment, the number of samples is increased gradually. The outputs from the proposed method are compared with no augmentation, augmentations using deep convolution generative adversarial network (DCGAN), and several geometric transformation-based augmentations...
Enhancing sensor resolution improves CNN accuracy given the same number of parameters or FLOPS
Mar 09, 2021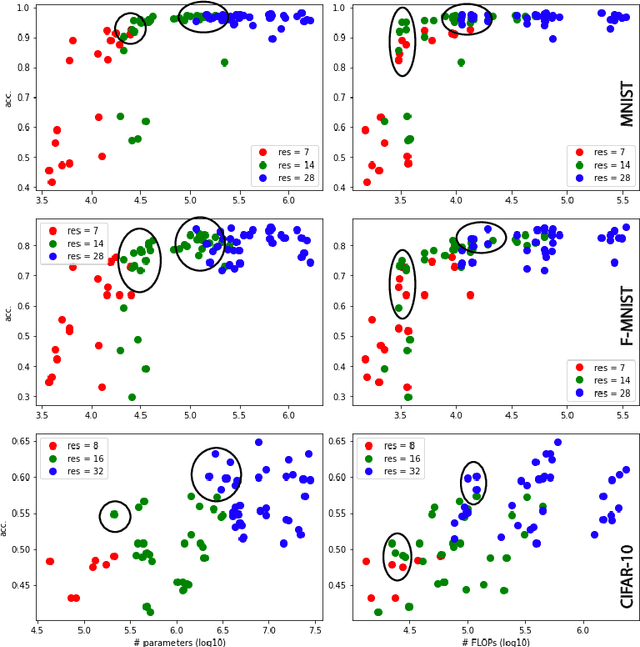
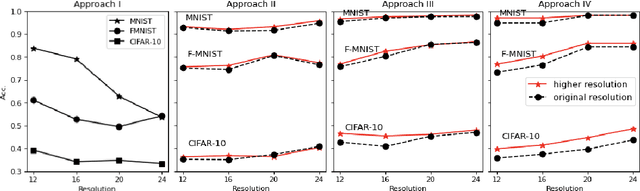
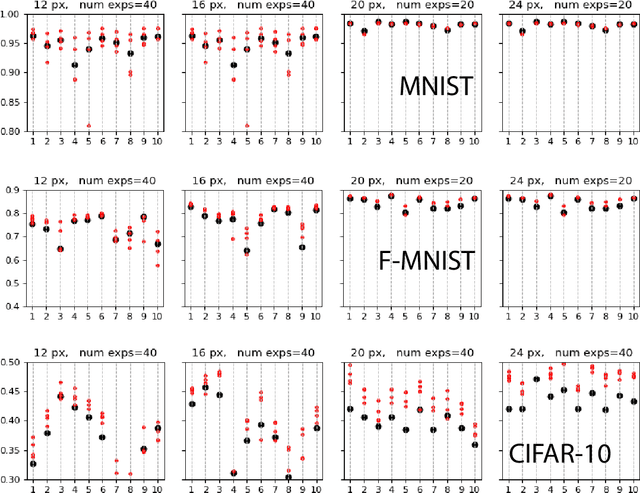
High image resolution is critical to obtain a good performance in many computer vision applications. Computational complexity of CNNs, however, grows significantly with the increase in input image size. Here, we show that it is almost always possible to modify a network such that it achieves higher accuracy at a higher input resolution while having the same number of parameters or/and FLOPS. The idea is similar to the EfficientNet paper but instead of optimizing network width, depth and resolution simultaneously, here we focus only on input resolution. This makes the search space much smaller which is more suitable for low computational budget regimes. More importantly, by controlling for the number of model parameters (and hence model capacity), we show that the additional benefit in accuracy is indeed due to the higher input resolution. Preliminary empirical investigation over MNIST, Fashion MNIST, and CIFAR10 datasets demonstrates the efficiency of the proposed approach.
Supervised Training of Dense Object Nets using Optimal Descriptors for Industrial Robotic Applications
Feb 16, 2021


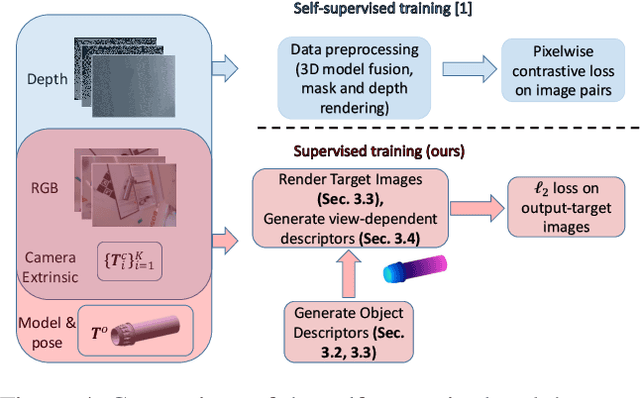
Dense Object Nets (DONs) by Florence, Manuelli and Tedrake (2018) introduced dense object descriptors as a novel visual object representation for the robotics community. It is suitable for many applications including object grasping, policy learning, etc. DONs map an RGB image depicting an object into a descriptor space image, which implicitly encodes key features of an object invariant to the relative camera pose. Impressively, the self-supervised training of DONs can be applied to arbitrary objects and can be evaluated and deployed within hours. However, the training approach relies on accurate depth images and faces challenges with small, reflective objects, typical for industrial settings, when using consumer grade depth cameras. In this paper we show that given a 3D model of an object, we can generate its descriptor space image, which allows for supervised training of DONs. We rely on Laplacian Eigenmaps (LE) to embed the 3D model of an object into an optimally generated space. While our approach uses more domain knowledge, it can be efficiently applied even for smaller and reflective objects, as it does not rely on depth information. We compare the training methods on generating 6D grasps for industrial objects and show that our novel supervised training approach improves the pick-and-place performance in industry-relevant tasks.
FDeblur-GAN: Fingerprint Deblurring using Generative Adversarial Network
Jun 21, 2021
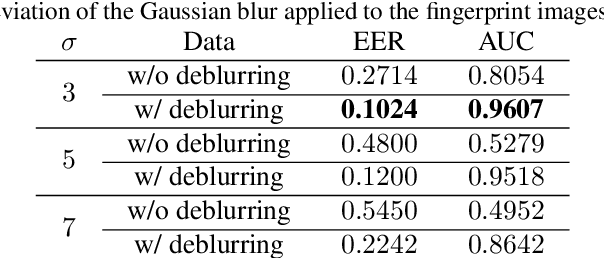
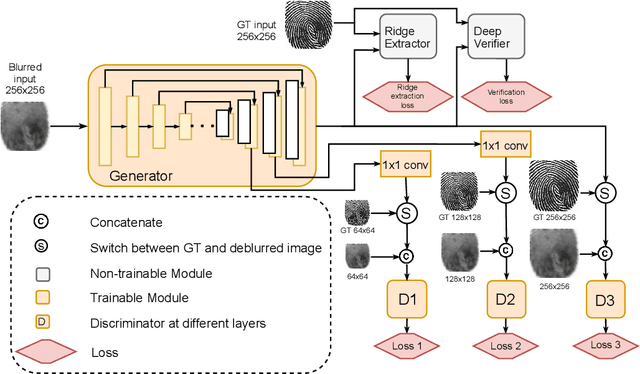
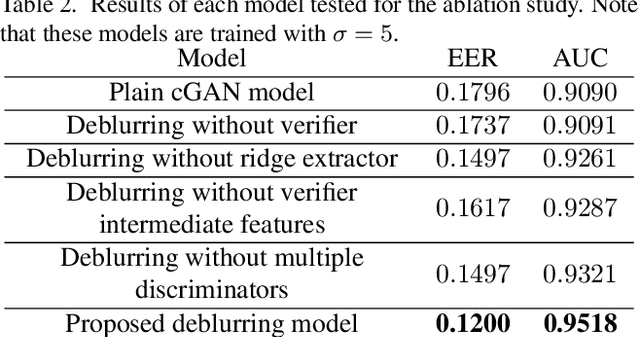
While working with fingerprint images acquired from crime scenes, mobile cameras, or low-quality sensors, it becomes difficult for automated identification systems to verify the identity due to image blur and distortion. We propose a fingerprint deblurring model FDeblur-GAN, based on the conditional Generative Adversarial Networks (cGANs) and multi-stage framework of the stack GAN. Additionally, we integrate two auxiliary sub-networks into the model for the deblurring task. The first sub-network is a ridge extractor model. It is added to generate ridge maps to ensure that fingerprint information and minutiae are preserved in the deblurring process and prevent the model from generating erroneous minutiae. The second sub-network is a verifier that helps the generator to preserve the ID information during the generation process. Using a database of blurred fingerprints and corresponding ridge maps, the deep network learns to deblur from the input blurry samples. We evaluate the proposed method in combination with two different fingerprint matching algorithms. We achieved an accuracy of 95.18% on our fingerprint database for the task of matching deblurred and ground truth fingerprints.
Explainable Deep Few-shot Anomaly Detection with Deviation Networks
Aug 01, 2021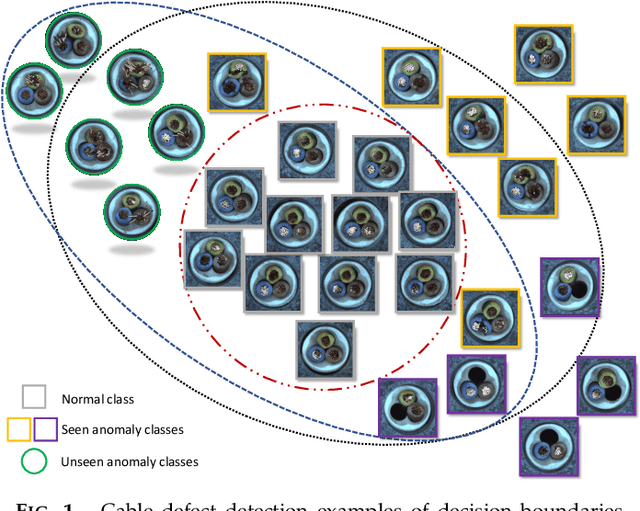
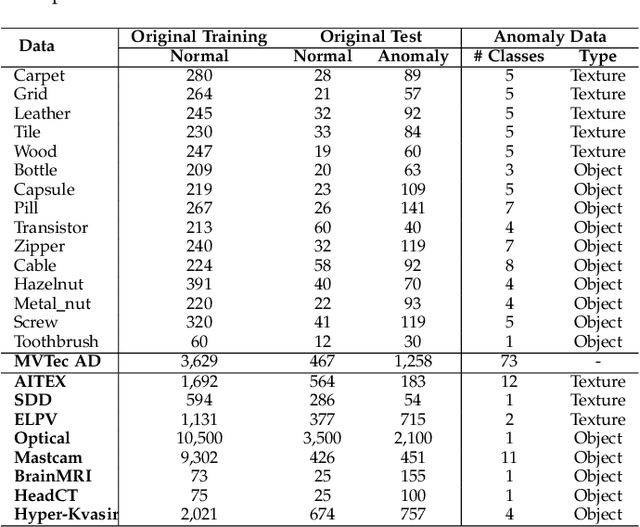
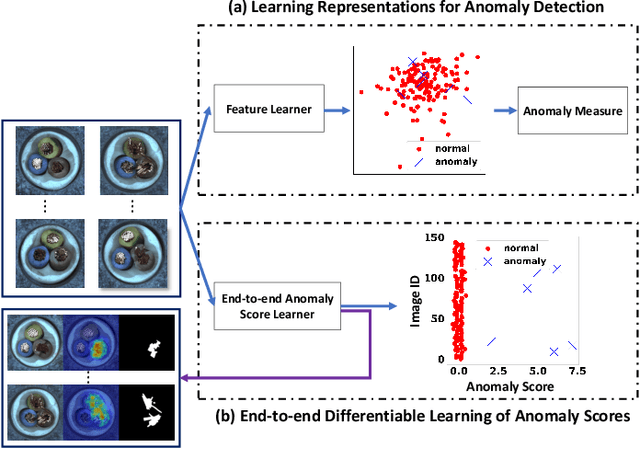
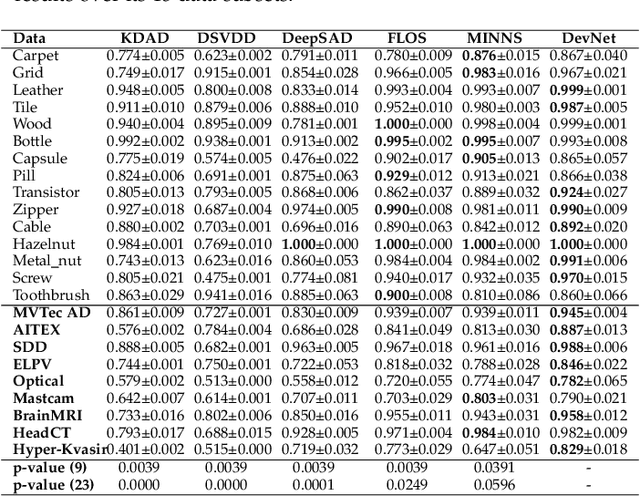
Existing anomaly detection paradigms overwhelmingly focus on training detection models using exclusively normal data or unlabeled data (mostly normal samples). One notorious issue with these approaches is that they are weak in discriminating anomalies from normal samples due to the lack of the knowledge about the anomalies. Here, we study the problem of few-shot anomaly detection, in which we aim at using a few labeled anomaly examples to train sample-efficient discriminative detection models. To address this problem, we introduce a novel weakly-supervised anomaly detection framework to train detection models without assuming the examples illustrating all possible classes of anomaly. Specifically, the proposed approach learns discriminative normality (regularity) by leveraging the labeled anomalies and a prior probability to enforce expressive representations of normality and unbounded deviated representations of abnormality. This is achieved by an end-to-end optimization of anomaly scores with a neural deviation learning, in which the anomaly scores of normal samples are imposed to approximate scalar scores drawn from the prior while that of anomaly examples is enforced to have statistically significant deviations from these sampled scores in the upper tail. Furthermore, our model is optimized to learn fine-grained normality and abnormality by top-K multiple-instance-learning-based feature subspace deviation learning, allowing more generalized representations. Comprehensive experiments on nine real-world image anomaly detection benchmarks show that our model is substantially more sample-efficient and robust, and performs significantly better than state-of-the-art competing methods in both closed-set and open-set settings. Our model can also offer explanation capability as a result of its prior-driven anomaly score learning. Code and datasets are available at: https://git.io/DevNet.
TNT: Text-Conditioned Network with Transductive Inference for Few-Shot Video Classification
Jun 21, 2021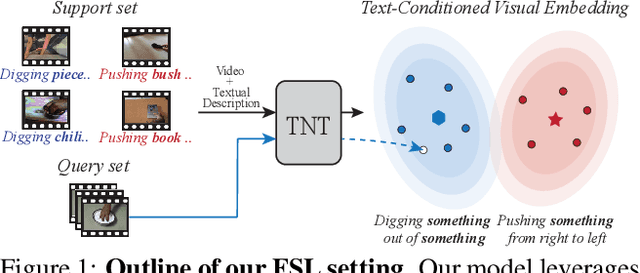
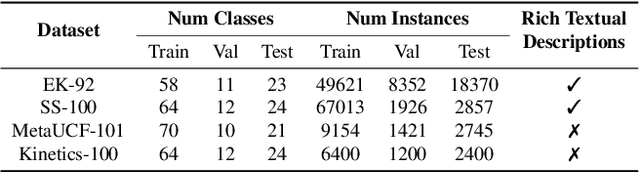
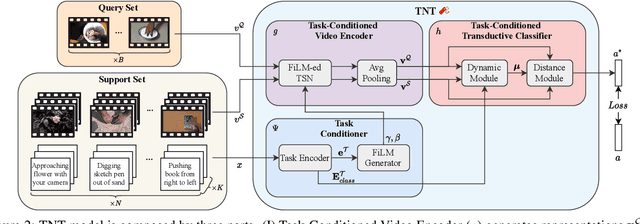
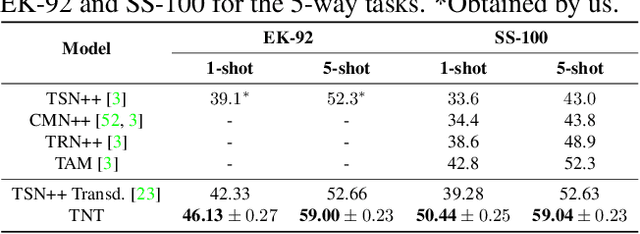
Recently, few-shot learning has received increasing interest. Existing efforts have been focused on image classification, with very few attempts dedicated to the more challenging few-shot video classification problem. These few attempts aim to effectively exploit the temporal dimension in videos for better learning in low data regimes. However, they have largely ignored a key characteristic of video which could be vital for few-shot recognition, that is, videos are often accompanied by rich text descriptions. In this paper, for the first time, we propose to leverage these human-provided textual descriptions as privileged information when training a few-shot video classification model. Specifically, we formulate a text-based task conditioner to adapt video features to the few-shot learning task. Our model follows a transductive setting where query samples and support textual descriptions can be used to update the support set class prototype to further improve the task-adaptation ability of the model. Our model obtains state-of-the-art performance on four challenging benchmarks in few-shot video action classification.
Exoplanet Detection in Starshade Images
Mar 17, 2021
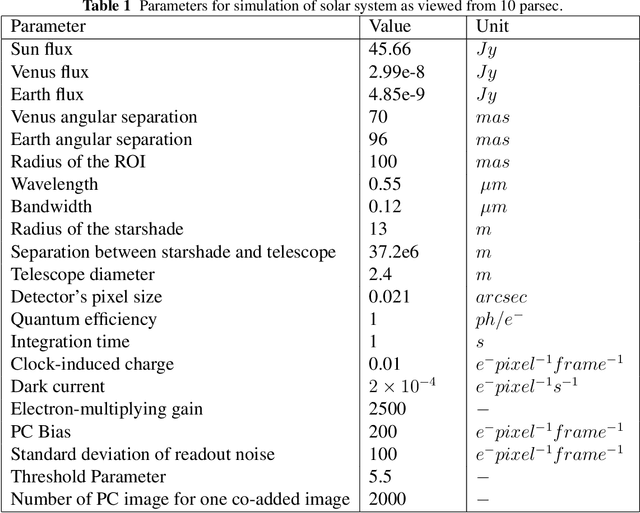
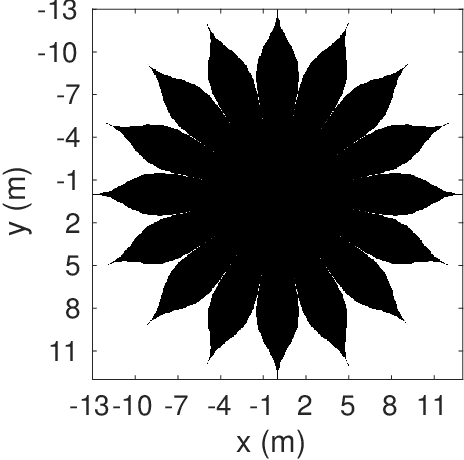

A starshade suppresses starlight by a factor of 1E11 in the image plane of a telescope, which is crucial for directly imaging Earth-like exoplanets. The state of the art in high contrast post-processing and signal detection methods were developed specifically for images taken with an internal coronagraph system and focus on the removal of quasi-static speckles. These methods are less useful for starshade images where such speckles are not present. This paper is dedicated to investigating signal processing methods tailored to work efficiently on starshade images. We describe a signal detection method, the generalized likelihood ratio test (GLRT), for starshade missions and look into three important problems. First, even with the light suppression provided by the starshade, rocky exoplanets are still difficult to detect in reflected light due to their absolute faintness. GLRT can successfully flag these dim planets. Moreover, GLRT provides estimates of the planets' positions and intensities and the theoretical false alarm rate of the detection. Second, small starshade shape errors, such as a truncated petal tip, can cause artifacts that are hard to distinguish from real planet signals; the detection method can help distinguish planet signals from such artifacts. The third direct imaging problem is that exozodiacal dust degrades detection performance. We develop an iterative generalized likelihood ratio test to mitigate the effect of dust on the image. In addition, we provide guidance on how to choose the number of photon counting images to combine into one co-added image before doing detection, which will help utilize the observation time efficiently. All the methods are demonstrated on realistic simulated images.