 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTNT: Text-Conditioned Network with Transductive Inference for Few-Shot Video Classification
Paper and Code
Jun 21, 2021
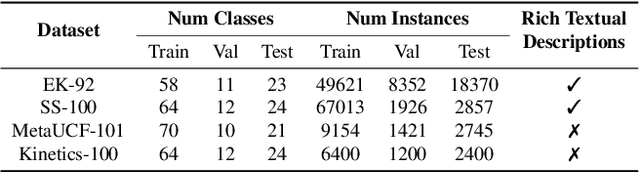
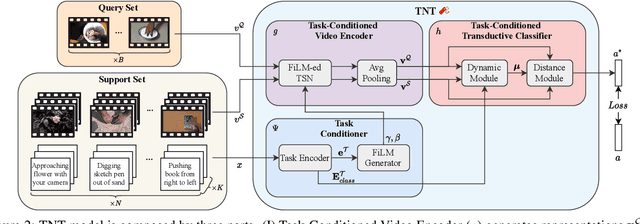
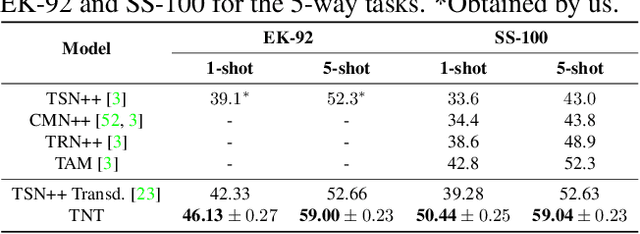
Recently, few-shot learning has received increasing interest. Existing efforts have been focused on image classification, with very few attempts dedicated to the more challenging few-shot video classification problem. These few attempts aim to effectively exploit the temporal dimension in videos for better learning in low data regimes. However, they have largely ignored a key characteristic of video which could be vital for few-shot recognition, that is, videos are often accompanied by rich text descriptions. In this paper, for the first time, we propose to leverage these human-provided textual descriptions as privileged information when training a few-shot video classification model. Specifically, we formulate a text-based task conditioner to adapt video features to the few-shot learning task. Our model follows a transductive setting where query samples and support textual descriptions can be used to update the support set class prototype to further improve the task-adaptation ability of the model. Our model obtains state-of-the-art performance on four challenging benchmarks in few-shot video action classification.