 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
UniDual: A Unified Model for Image and Video Understanding
Jun 12, 2019
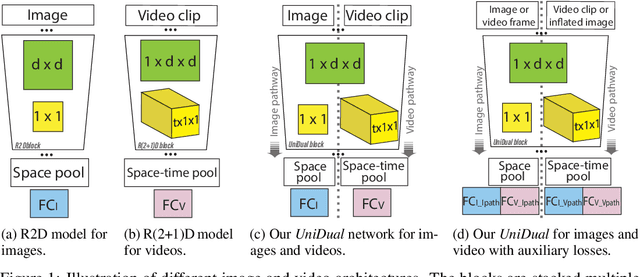
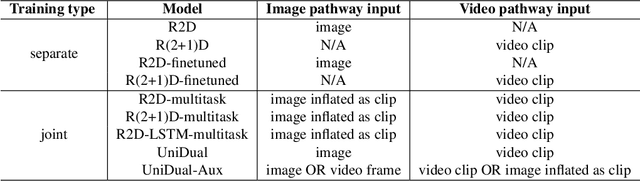
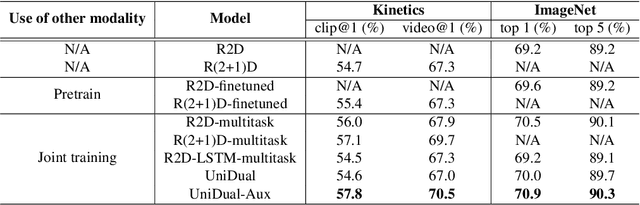
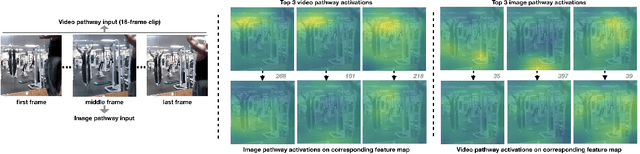
Although a video is effectively a sequence of images, visual perception systems typically model images and videos separately, thus failing to exploit the correlation and the synergy provided by these two media. While a few prior research efforts have explored the benefits of leveraging still-image datasets for video analysis, or vice-versa, most of these attempts have been limited to pretraining a model on one type of visual modality and then adapting it via finetuning on the other modality. In contrast, in this paper we introduce a framework that enables joint training of a unified model on mixed collections of image and video examples spanning different tasks. The key ingredient in our architecture design is a new network block, which we name UniDual. It consists of a shared 2D spatial convolution followed by two parallel point-wise convolutional layers, one devoted to images and the other one used for videos. For video input, the point-wise filtering implements a temporal convolution. For image input, it performs a pixel-wise nonlinear transformation. Repeated stacking of such blocks gives rise to a network where images and videos undergo partially distinct execution pathways, unified by spatial convolutions (capturing commonalities in visual appearance) but separated by point-wise operations (modeling patterns specific to each modality). Extensive experiments on Kinetics and ImageNet demonstrate that our UniDual model jointly trained on these datasets yields substantial accuracy gains for both tasks, compared to 1) training separate models, 2) traditional multi-task learning and 3) the conventional framework of pretraining-followed-by-finetuning. On Kinetics, the UniDual architecture applied to a state-of-the-art video backbone model (R(2+1)D-152) yields an additional video@1 accuracy gain of 1.5%.
Synthesizing 3D Shapes from Silhouette Image Collections using Multi-projection Generative Adversarial Networks
Jun 10, 2019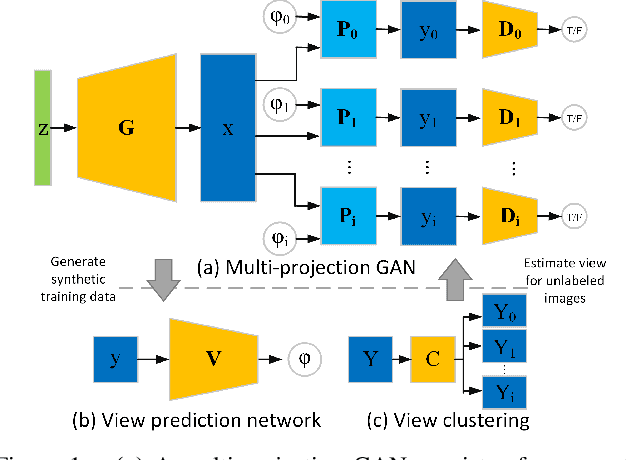

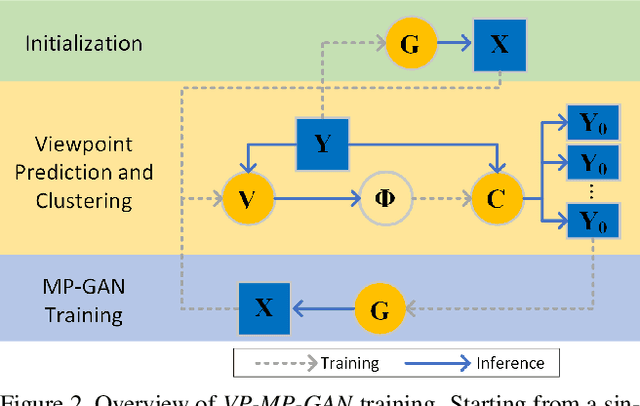

We present a new weakly supervised learning-based method for generating novel category-specific 3D shapes from unoccluded image collections. Our method is weakly supervised and only requires silhouette annotations from unoccluded, category-specific objects. Our method does not require access to the object's 3D shape, multiple observations per object from different views, intra-image pixel-correspondences, or any view annotations. Key to our method is a novel multi-projection generative adversarial network (MP-GAN) that trains a 3D shape generator to be consistent with multiple 2D projections of the 3D shapes, and without direct access to these 3D shapes. This is achieved through multiple discriminators that encode the distribution of 2D projections of the 3D shapes seen from a different views. Additionally, to determine the view information for each silhouette image, we also train a view prediction network on visualizations of 3D shapes synthesized by the generator. We iteratively alternate between training the generator and training the view prediction network. We validate our multi-projection GAN on both synthetic and real image datasets. Furthermore, we also show that multi-projection GANs can aid in learning other high-dimensional distributions from lower dimensional training datasets, such as material-class specific spatially varying reflectance properties from images.
Transfer learning approach to Classify the X-ray image that corresponds to corona disease Using ResNet50 pretrained by ChexNet
May 18, 2021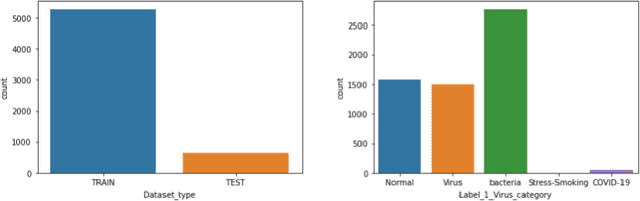

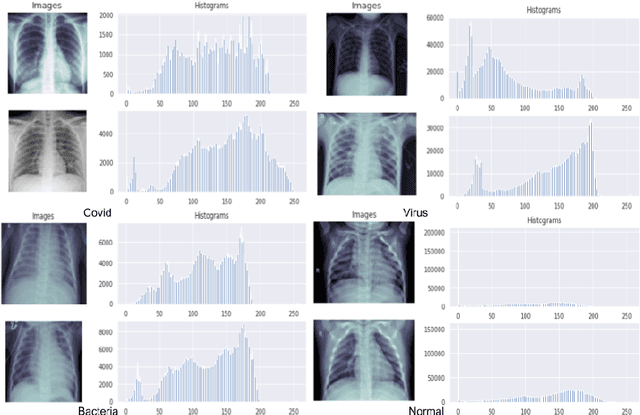
Coronavirus adversely has affected people worldwide. There are common symptoms between the Covid19 virus disease and other respiratory diseases like pneumonia or Influenza. Therefore, diagnosing it fast is crucial not only to save patients but also to prevent it from spreading. One of the most reliant methods of diagnosis is through X-ray images of a lung. With the help of deep learning approaches, we can teach the deep model to learn the condition of an affected lung. Therefore, it can classify the new sample as if it is a Covid19 infected patient or not. In this project, we train a deep model based on ResNet50 pretrained by ImageNet dataset and CheXNet dataset. Based on the imbalanced CoronaHack Chest X-Ray dataset introducing by Kaggle we applied both binary and multi-class classification. Also, we compare the results when using Focal loss and Cross entropy loss.
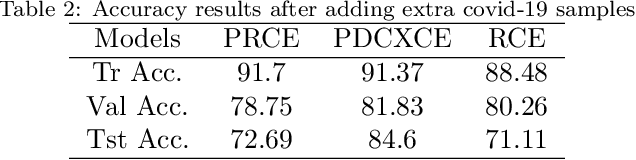
Spline Positional Encoding for Learning 3D Implicit Signed Distance Fields
Jun 03, 2021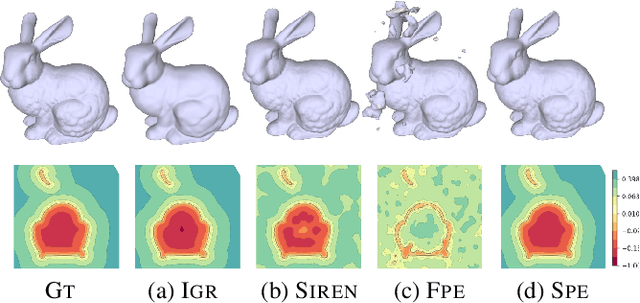

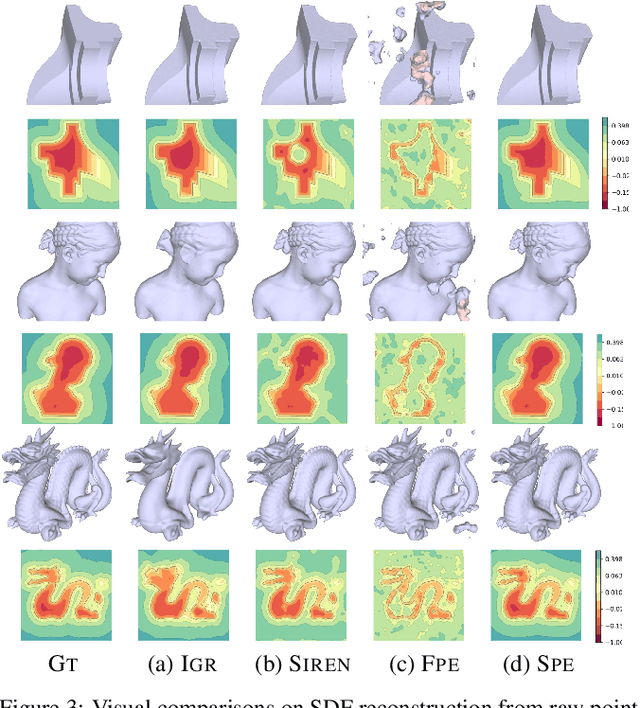
Multilayer perceptrons (MLPs) have been successfully used to represent 3D shapes implicitly and compactly, by mapping 3D coordinates to the corresponding signed distance values or occupancy values. In this paper, we propose a novel positional encoding scheme, called Spline Positional Encoding, to map the input coordinates to a high dimensional space before passing them to MLPs, for helping to recover 3D signed distance fields with fine-scale geometric details from unorganized 3D point clouds. We verified the superiority of our approach over other positional encoding schemes on tasks of 3D shape reconstruction from input point clouds and shape space learning. The efficacy of our approach extended to image reconstruction is also demonstrated and evaluated.
GENESIS-V2: Inferring Unordered Object Representations without Iterative Refinement
Apr 20, 2021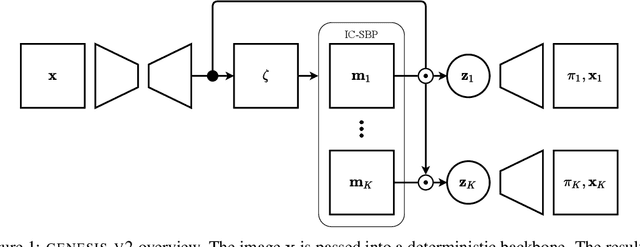

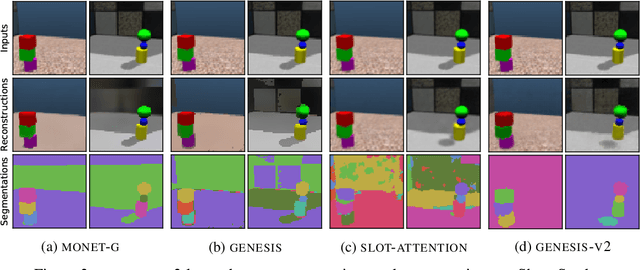
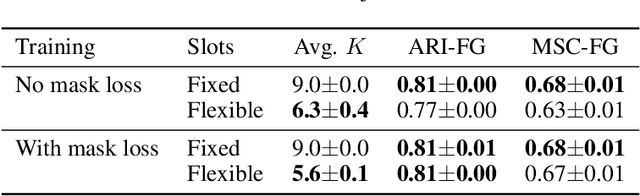
Advances in object-centric generative models (OCGMs) have culminated in the development of a broad range of methods for unsupervised object segmentation and interpretable object-centric scene generation. These methods, however, are limited to simulated and real-world datasets with limited visual complexity. Moreover, object representations are often inferred using RNNs which do not scale well to large images or iterative refinement which avoids imposing an unnatural ordering on objects in an image but requires the a priori initialisation of a fixed number of object representations. In contrast to established paradigms, this work proposes an embedding-based approach in which embeddings of pixels are clustered in a differentiable fashion using a stochastic, non-parametric stick-breaking process. Similar to iterative refinement, this clustering procedure also leads to randomly ordered object representations, but without the need of initialising a fixed number of clusters a priori. This is used to develop a new model, GENESIS-V2, which can infer a variable number of object representations without using RNNs or iterative refinement. We show that GENESIS-V2 outperforms previous methods for unsupervised image segmentation and object-centric scene generation on established synthetic datasets as well as more complex real-world datasets.
Helsinki Deblur Challenge 2021: description of photographic data
May 21, 2021

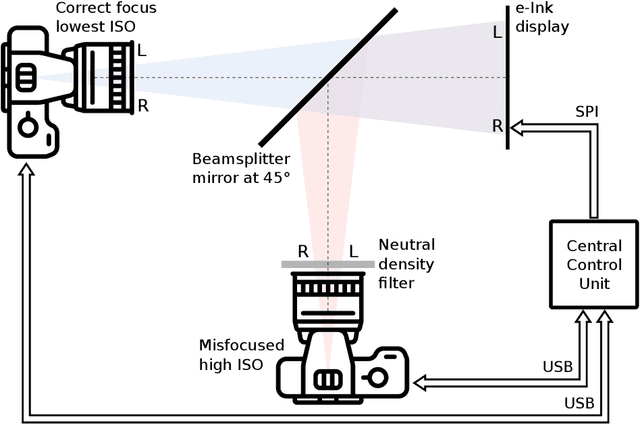
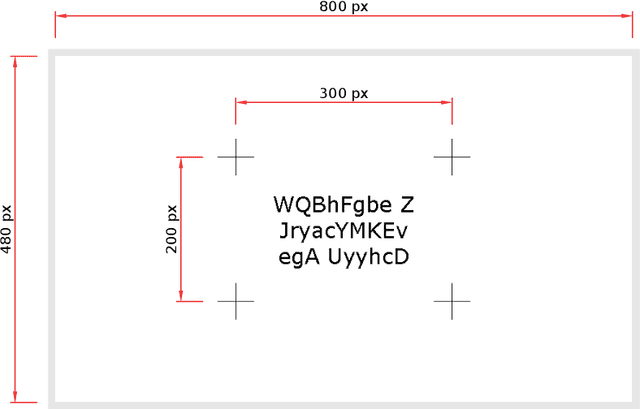
The photographic dataset collected for the Helsinki Deblur Challenge 2021 (HDC2021) contains pairs of images taken by two identical cameras of the same target but with different conditions. One camera is always in focus and produces sharp and low-noise images the other camera produces blurred and noisy images as it is gradually more and more out of focus and has a higher ISO setting. Even though the dataset was designed and captured with the HDC2021 in mind it can be used for any testing and benchmarking of image deblurring algorithms. The data is available here: https://doi.org/10.5281/zenodo.477228
Image Captioning using Deep Neural Architectures
Jan 17, 2018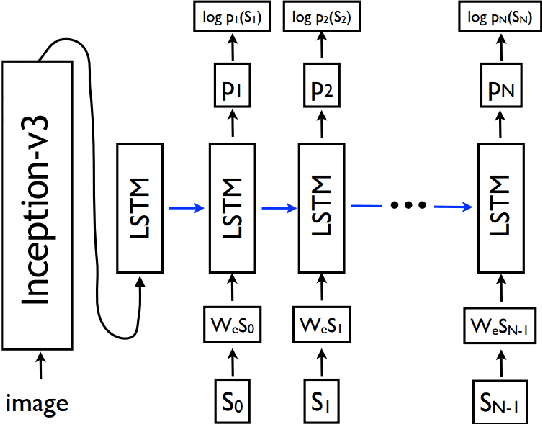
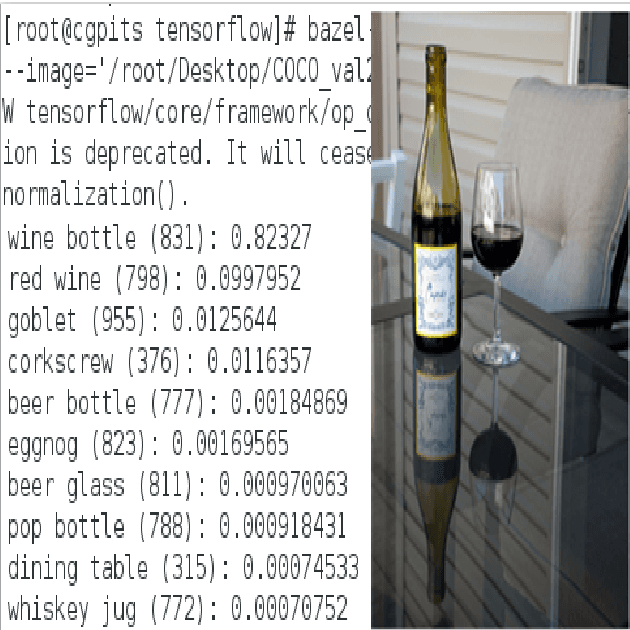


Automatically creating the description of an image using any natural languages sentence like English is a very challenging task. It requires expertise of both image processing as well as natural language processing. This paper discuss about different available models for image captioning task. We have also discussed about how the advancement in the task of object recognition and machine translation has greatly improved the performance of image captioning model in recent years. In addition to that we have discussed how this model can be implemented. In the end, we have also evaluated the performance of model using standard evaluation matrices.
Sexing Caucasian 2D footprints using convolutional neural networks
Jul 23, 2021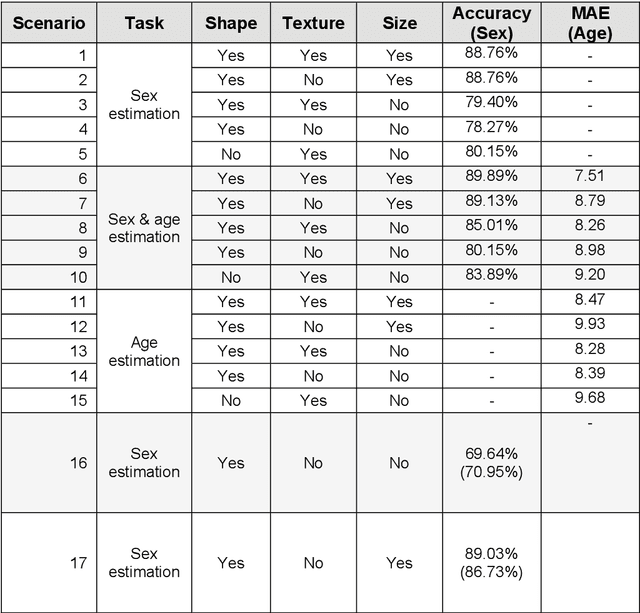
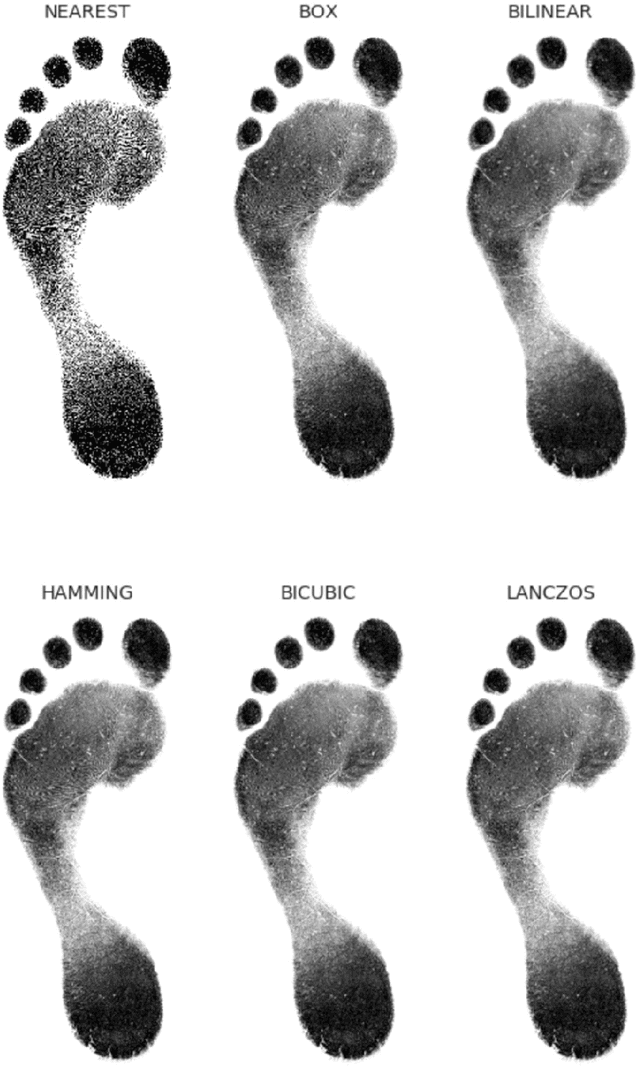
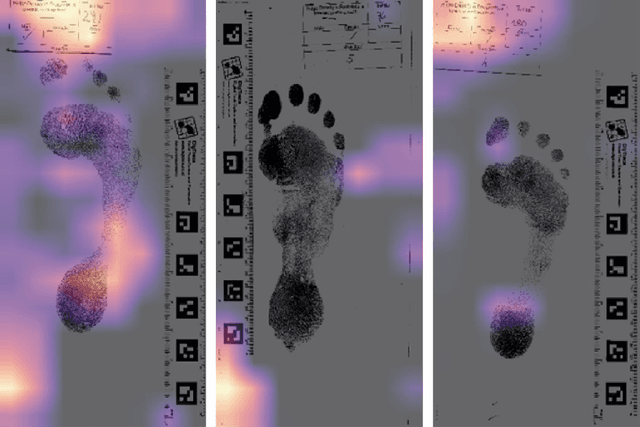
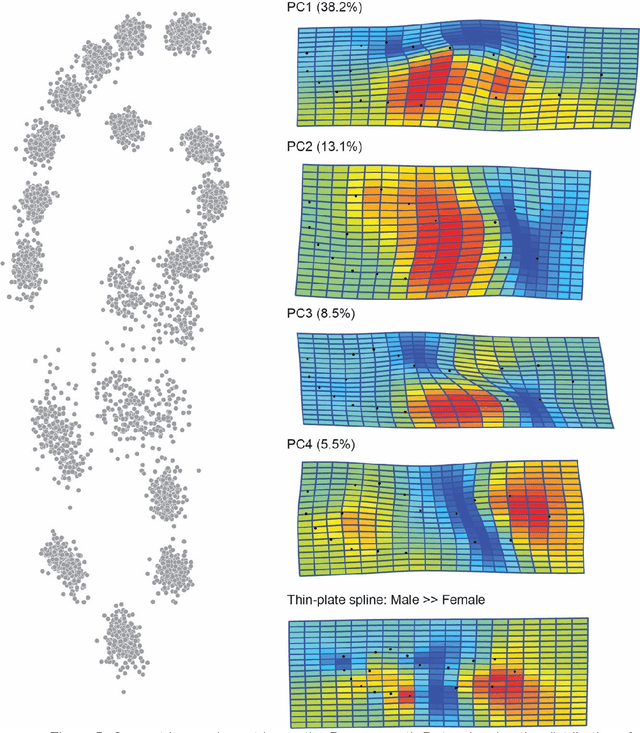
Footprints are left, or obtained, in a variety of scenarios from crime scenes to anthropological investigations. Determining the sex of a footprint can be useful in screening such impressions and attempts have been made to do so using single or multi landmark distances, shape analyses and via the density of friction ridges. Here we explore the relative importance of different components in sexing two-dimensional foot impressions namely, size, shape and texture. We use a machine learning approach and compare this to more traditional methods of discrimination. Two datasets are used, a pilot data set collected from students at Bournemouth University (N=196) and a larger data set collected by podiatrists at Sheffield NHS Teaching Hospital (N=2677). Our convolutional neural network can sex a footprint with accuracy of around 90% on a test set of N=267 footprint images using all image components, which is better than an expert can achieve. However, the quality of the impressions impacts on this success rate, but the results are promising and in time it may be possible to create an automated screening algorithm in which practitioners of whatever sort (medical or forensic) can obtain a first order sexing of a two-dimensional footprint.
SynthRef: Generation of Synthetic Referring Expressions for Object Segmentation
Jun 08, 2021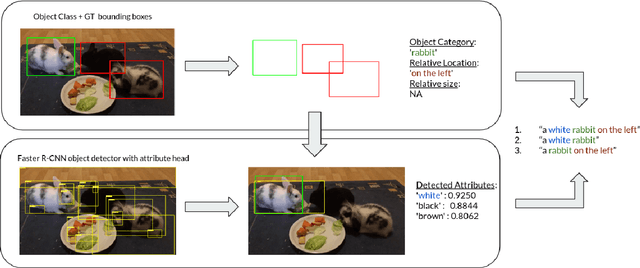



Recent advances in deep learning have brought significant progress in visual grounding tasks such as language-guided video object segmentation. However, collecting large datasets for these tasks is expensive in terms of annotation time, which represents a bottleneck. To this end, we propose a novel method, namely SynthRef, for generating synthetic referring expressions for target objects in an image (or video frame), and we also present and disseminate the first large-scale dataset with synthetic referring expressions for video object segmentation. Our experiments demonstrate that by training with our synthetic referring expressions one can improve the ability of a model to generalize across different datasets, without any additional annotation cost. Moreover, our formulation allows its application to any object detection or segmentation dataset.
Black-Box Diagnosis and Calibration on GAN Intra-Mode Collapse: A Pilot Study
Jul 23, 2021

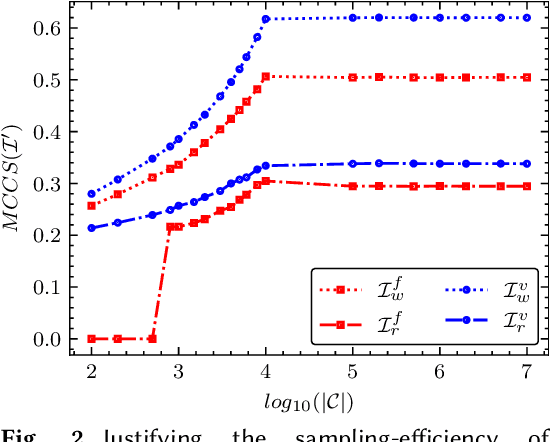

Generative adversarial networks (GANs) nowadays are capable of producing images of incredible realism. One concern raised is whether the state-of-the-art GAN's learned distribution still suffers from mode collapse, and what to do if so. Existing diversity tests of samples from GANs are usually conducted qualitatively on a small scale, and/or depends on the access to original training data as well as the trained model parameters. This paper explores to diagnose GAN intra-mode collapse and calibrate that, in a novel black-box setting: no access to training data, nor the trained model parameters, is assumed. The new setting is practically demanded, yet rarely explored and significantly more challenging. As a first stab, we devise a set of statistical tools based on sampling, that can visualize, quantify, and rectify intra-mode collapse. We demonstrate the effectiveness of our proposed diagnosis and calibration techniques, via extensive simulations and experiments, on unconditional GAN image generation (e.g., face and vehicle). Our study reveals that the intra-mode collapse is still a prevailing problem in state-of-the-art GANs and the mode collapse is diagnosable and calibratable in black-box settings. Our codes are available at: https://github.com/VITA-Group/BlackBoxGANCollapse.