 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep learning-based virtual refocusing of images using an engineered point-spread function
Dec 22, 2020
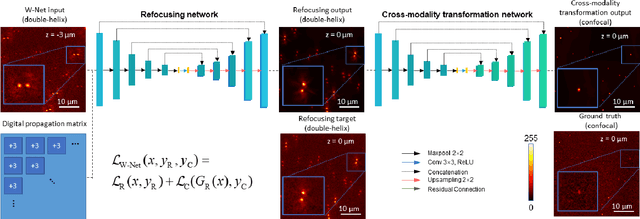

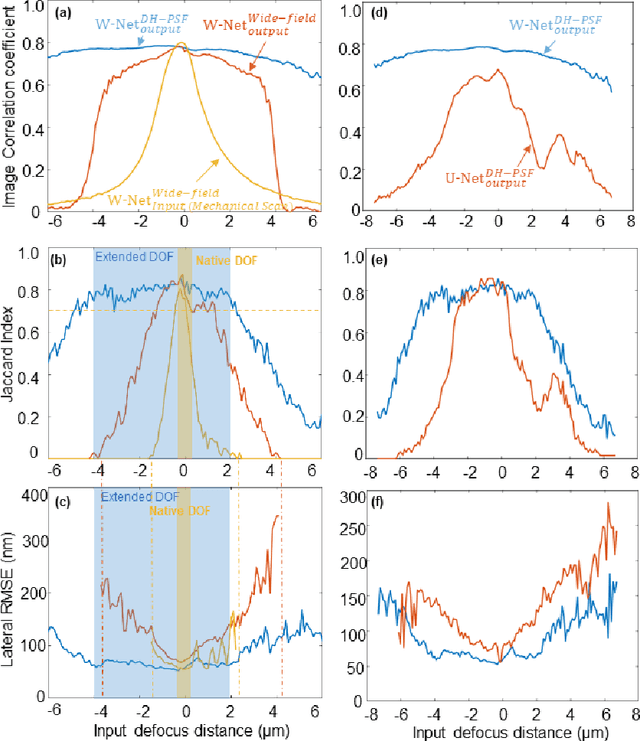
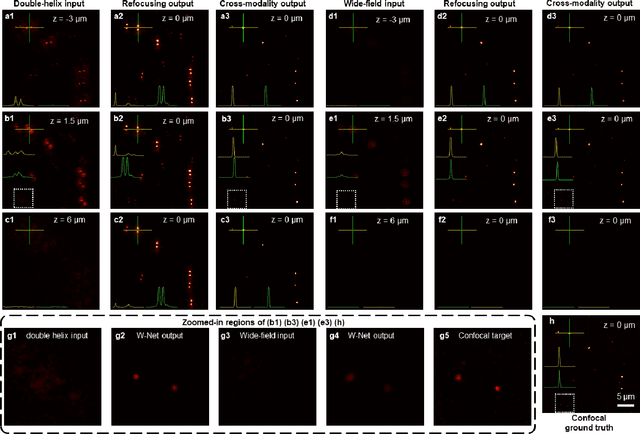
We present a virtual image refocusing method over an extended depth of field (DOF) enabled by cascaded neural networks and a double-helix point-spread function (DH-PSF). This network model, referred to as W-Net, is composed of two cascaded generator and discriminator network pairs. The first generator network learns to virtually refocus an input image onto a user-defined plane, while the second generator learns to perform a cross-modality image transformation, improving the lateral resolution of the output image. Using this W-Net model with DH-PSF engineering, we extend the DOF of a fluorescence microscope by ~20-fold. This approach can be applied to develop deep learning-enabled image reconstruction methods for localization microscopy techniques that utilize engineered PSFs to improve their imaging performance, including spatial resolution and volumetric imaging throughput.
Lesion Conditional Image Generation for Improved Segmentation of Intracranial Hemorrhage from CT Images
Mar 30, 2020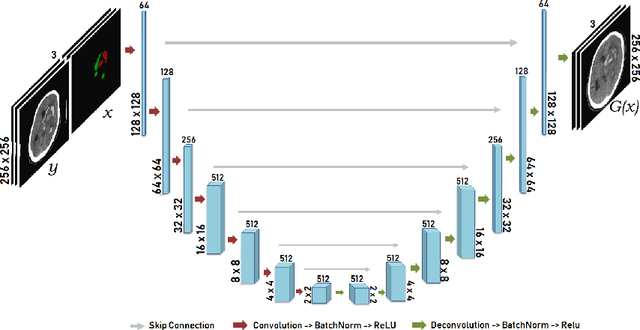

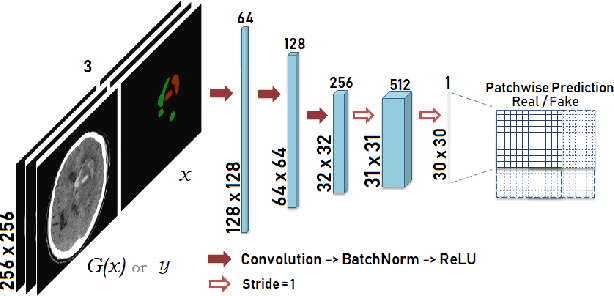
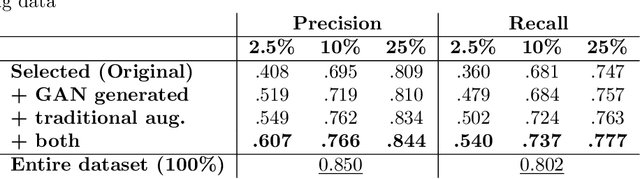
Data augmentation can effectively resolve a scarcity of images when training machine-learning algorithms. It can make them more robust to unseen images. We present a lesion conditional Generative Adversarial Network LcGAN to generate synthetic Computed Tomography (CT) images for data augmentation. A lesion conditional image (segmented mask) is an input to both the generator and the discriminator of the LcGAN during training. The trained model generates contextual CT images based on input masks. We quantify the quality of the images by using a fully convolutional network (FCN) score and blurriness. We also train another classification network to select better synthetic images. These synthetic CT images are then augmented to our hemorrhagic lesion segmentation network. By applying this augmentation method on 2.5%, 10% and 25% of original data, segmentation improved by 12.8%, 6% and 1.6% respectively.
Show, Recall, and Tell: Image Captioning with Recall Mechanism
Jan 15, 2020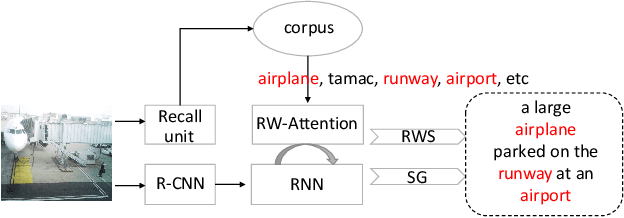
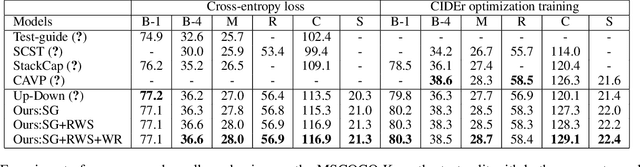
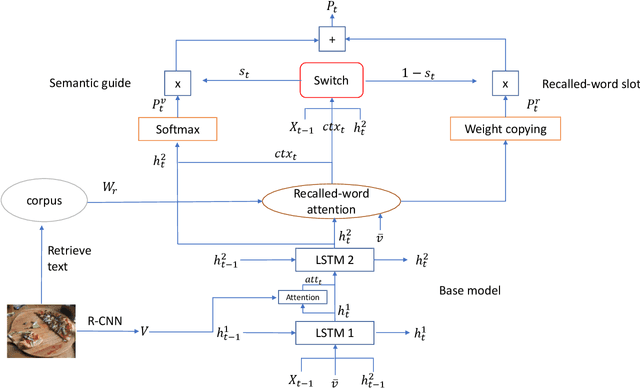
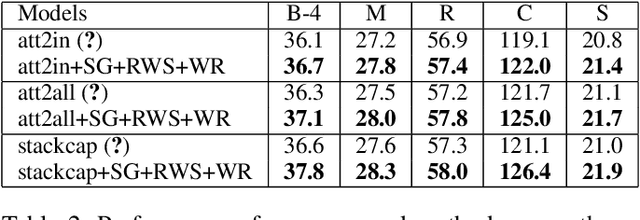
Generating natural and accurate descriptions in image cap-tioning has always been a challenge. In this paper, we pro-pose a novel recall mechanism to imitate the way human con-duct captioning. There are three parts in our recall mecha-nism : recall unit, semantic guide (SG) and recalled-wordslot (RWS). Recall unit is a text-retrieval module designedto retrieve recalled words for images. SG and RWS are de-signed for the best use of recalled words. SG branch cangenerate a recalled context, which can guide the process ofgenerating caption. RWS branch is responsible for copyingrecalled words to the caption. Inspired by pointing mecha-nism in text summarization, we adopt a soft switch to balancethe generated-word probabilities between SG and RWS. Inthe CIDEr optimization step, we also introduce an individualrecalled-word reward (WR) to boost training. Our proposedmethods (SG+RWS+WR) achieve BLEU-4 / CIDEr / SPICEscores of 36.6 / 116.9 / 21.3 with cross-entropy loss and 38.7 /129.1 / 22.4 with CIDEr optimization on MSCOCO Karpathytest split, which surpass the results of other state-of-the-artmethods.
A Novel Solution of an Elastic Net Regularization for Dementia Knowledge Discovery using Deep Learning
Aug 21, 2021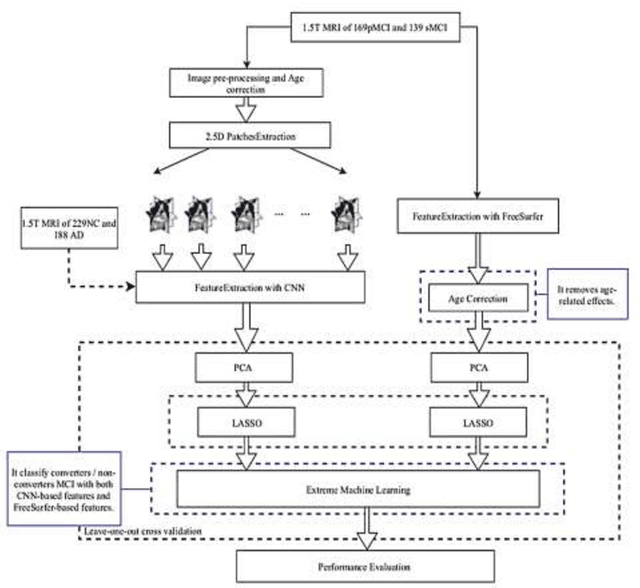

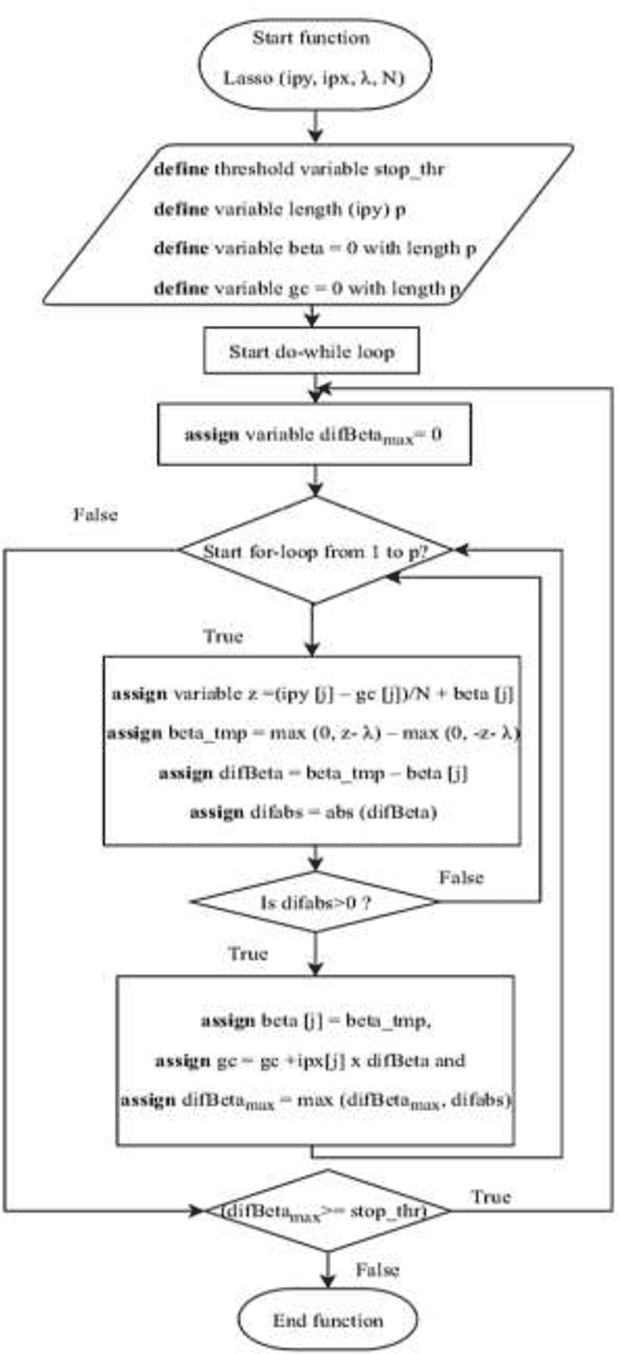
Background and Aim: Accurate classification of Magnetic Resonance Images (MRI) is essential to accurately predict Mild Cognitive Impairment (MCI) to Alzheimer's Disease (AD) conversion. Meanwhile, deep learning has been successfully implemented to classify and predict dementia disease. However, the accuracy of MRI image classification is low. This paper aims to increase the accuracy and reduce the processing time of classification through Deep Learning Architecture by using Elastic Net Regularization in Feature Selection. Methodology: The proposed system consists of Convolutional Neural Network (CNN) to enhance the accuracy of classification and prediction by using Elastic Net Regularization. Initially, the MRI images are fed into CNN for features extraction through convolutional layers alternate with pooling layers, and then through a fully connected layer. After that, the features extracted are subjected to Principle Component Analysis (PCA) and Elastic Net Regularization for feature selection. Finally, the selected features are used as an input to Extreme Machine Learning (EML) for the classification of MRI images. Results: The result shows that the accuracy of the proposed solution is better than the current system. In addition to that, the proposed method has improved the classification accuracy by 5% on average and reduced the processing time by 30 ~ 40 seconds on average. Conclusion: The proposed system is focused on improving the accuracy and processing time of MCI converters/non-converters classification. It consists of features extraction, feature selection, and classification using CNN, FreeSurfer, PCA, Elastic Net, Extreme Machine Learning. Finally, this study enhances the accuracy and the processing time by using Elastic Net Regularization, which provides important selected features for classification.
* 20 pages
Predictive Image Regression for Longitudinal Studies with Missing Data
Aug 19, 2018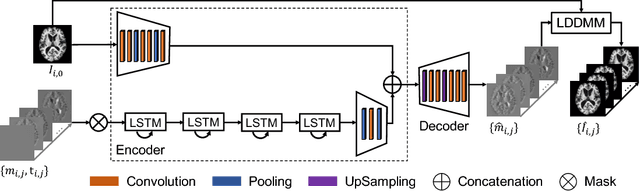
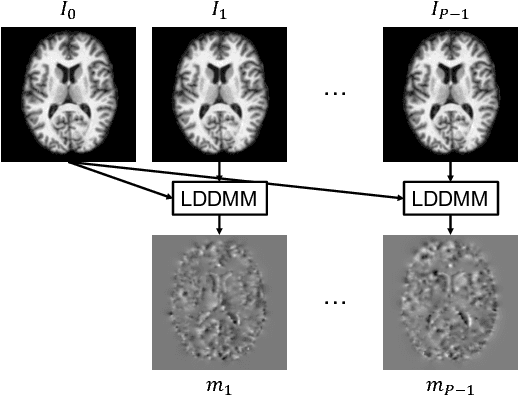
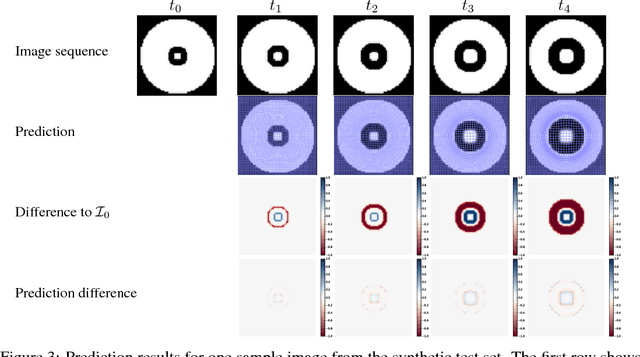
In this paper, we propose a predictive regression model for longitudinal images with missing data based on large deformation diffeomorphic metric mapping (LDDMM) and deep neural networks. Instead of directly predicting image scans, our model predicts a vector momentum sequence associated with a baseline image. This momentum sequence parameterizes the original image sequence in the LDDMM framework and lies in the tangent space of the baseline image, which is Euclidean. A recurrent network with long term-short memory (LSTM) units encodes the time-varying changes in the vector-momentum sequence, and a convolutional neural network (CNN) encodes the baseline image of the vector momenta. Features extracted by the LSTM and CNN are fed into a decoder network to reconstruct the vector momentum sequence, which is used for the image sequence prediction by deforming the baseline image with LDDMM shooting. To handle the missing images at some time points, we adopt a binary mask to ignore their reconstructions in the loss calculation. We evaluate our model on synthetically generated images and the brain MRIs from the OASIS dataset. Experimental results demonstrate the promising predictions of the spatiotemporal changes in both datasets, irrespective of large or subtle changes in longitudinal image sequences.
One-shot Face Reenactment Using Appearance Adaptive Normalization
Feb 20, 2021
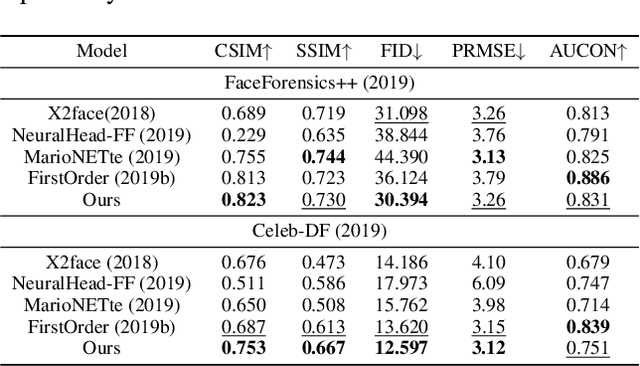
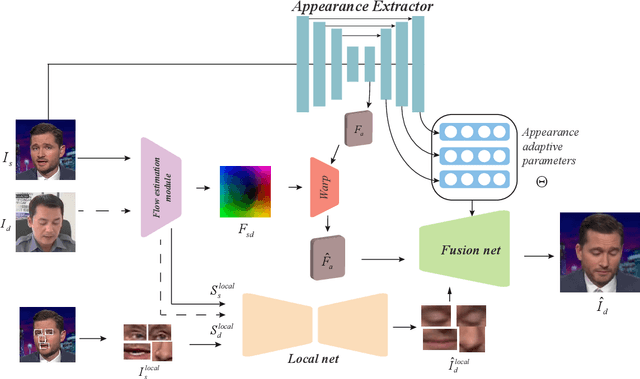
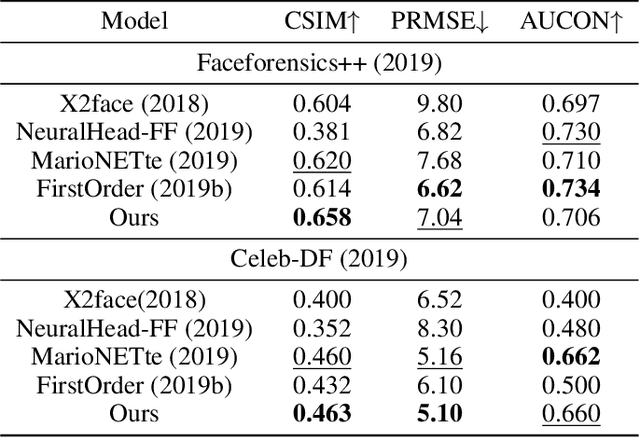
The paper proposes a novel generative adversarial network for one-shot face reenactment, which can animate a single face image to a different pose-and-expression (provided by a driving image) while keeping its original appearance. The core of our network is a novel mechanism called appearance adaptive normalization, which can effectively integrate the appearance information from the input image into our face generator by modulating the feature maps of the generator using the learned adaptive parameters. Furthermore, we specially design a local net to reenact the local facial components (i.e., eyes, nose and mouth) first, which is a much easier task for the network to learn and can in turn provide explicit anchors to guide our face generator to learn the global appearance and pose-and-expression. Extensive quantitative and qualitative experiments demonstrate the significant efficacy of our model compared with prior one-shot methods.
Distilling the Knowledge from Normalizing Flows
Jun 25, 2021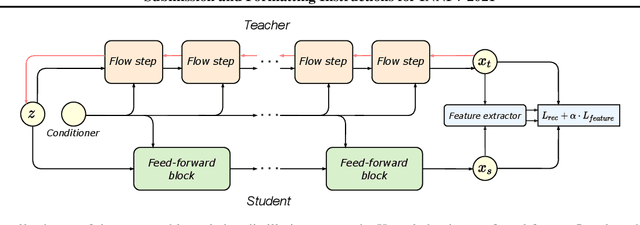
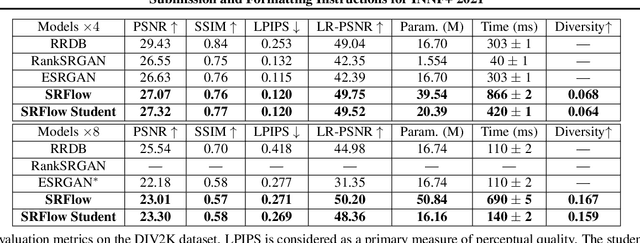
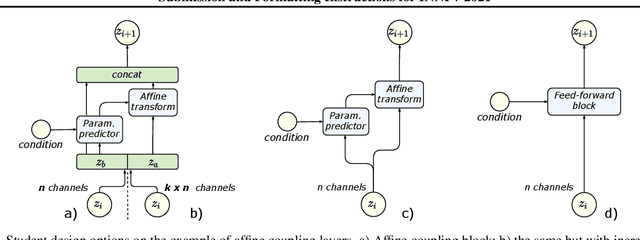
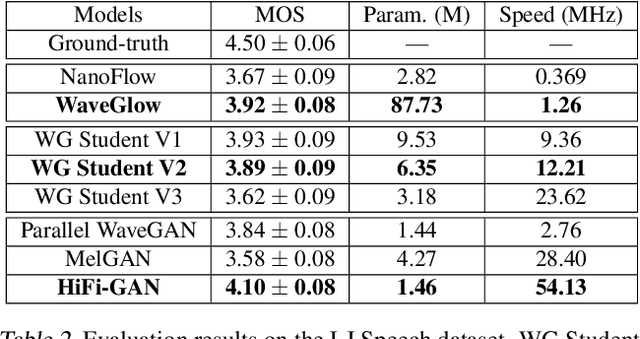
Normalizing flows are a powerful class of generative models demonstrating strong performance in several speech and vision problems. In contrast to other generative models, normalizing flows are latent variable models with tractable likelihoods and allow for stable training. However, they have to be carefully designed to represent invertible functions with efficient Jacobian determinant calculation. In practice, these requirements lead to overparameterized and sophisticated architectures that are inferior to alternative feed-forward models in terms of inference time and memory consumption. In this work, we investigate whether one can distill flow-based models into more efficient alternatives. We provide a positive answer to this question by proposing a simple distillation approach and demonstrating its effectiveness on state-of-the-art conditional flow-based models for image super-resolution and speech synthesis.
Self-Supervised Learning of Remote Sensing Scene Representations Using Contrastive Multiview Coding
Apr 14, 2021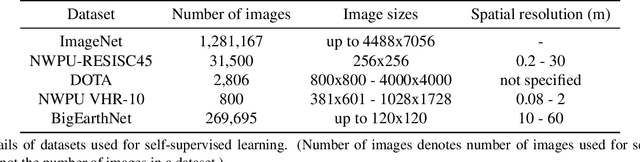
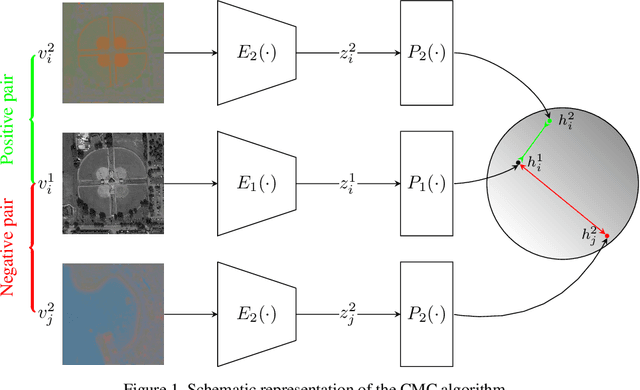

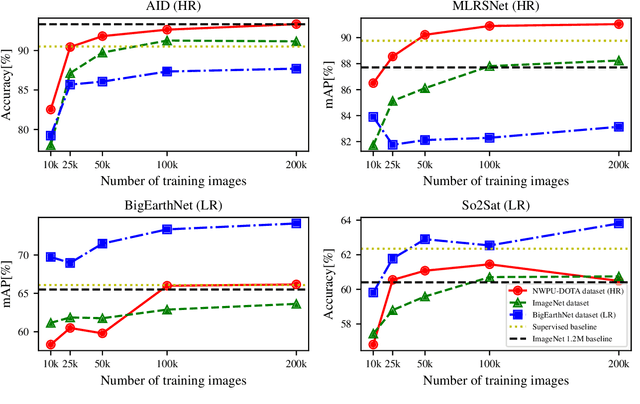
In recent years self-supervised learning has emerged as a promising candidate for unsupervised representation learning. In the visual domain its applications are mostly studied in the context of images of natural scenes. However, its applicability is especially interesting in specific areas, like remote sensing and medicine, where it is hard to obtain huge amounts of labeled data. In this work, we conduct an extensive analysis of the applicability of self-supervised learning in remote sensing image classification. We analyze the influence of the number and domain of images used for self-supervised pre-training on the performance on downstream tasks. We show that, for the downstream task of remote sensing image classification, using self-supervised pre-training on remote sensing images can give better results than using supervised pre-training on images of natural scenes. Besides, we also show that self-supervised pre-training can be easily extended to multispectral images producing even better results on our downstream tasks.
Laguerre-Gauss Preprocessing: Line Profiles as Image Features for Aerial Images Classification
Dec 13, 2019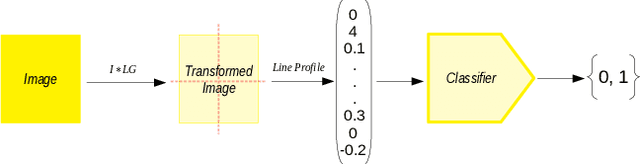


An image preprocessing methodology based on Fourier analysis together with the Laguerre-Gauss Spatial Filter is proposed. This is an alternative to obtain features from aerial images that reduces the feature space significantly, preserving enough information for classification tasks. Experiments on a challenging data set of aerial images show that it is possible to learn a robust classifier from this transformed and smaller feature space using simple models, with similar performance to the complete feature space and more complex models.
Do Time Constraints Re-Prioritize Attention to Shapes During Visual Photo Inspection?
Apr 14, 2021


People's visual experiences of the world are easy to carve up and examine along natural language boundaries, e.g., by category labels, attribute labels, etc. However, it is more difficult to elicit detailed visuospatial information about what a person attends to, e.g., the specific shape of a tree. Paying attention to the shapes of things not only feeds into well defined tasks like visual category learning, but it is also what enables us to differentiate similarly named objects and to take on creative visual pursuits, like poetically describing the shape of a thing, or finding shapes in the clouds or stars. We use a new data collection method that elicits people's prioritized attention to shapes during visual photo inspection by asking them to trace important parts of the image under varying time constraints. Using data collected via crowdsourcing over a set of 187 photographs, we examine changes in patterns of visual attention across individuals, across image types, and across time constraints.