 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShow, Recall, and Tell: Image Captioning with Recall Mechanism
Paper and Code
Jan 15, 2020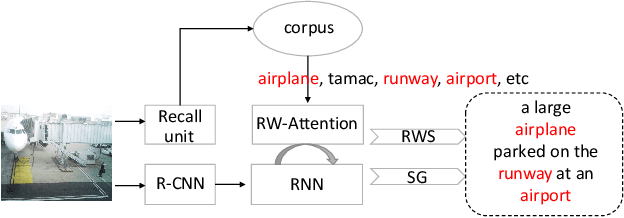
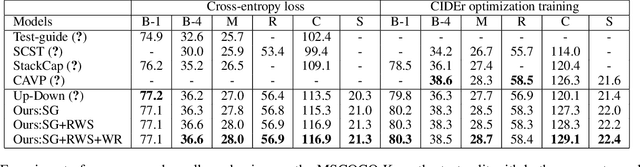
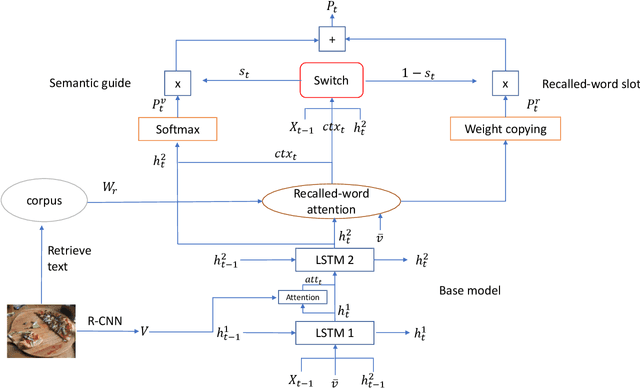
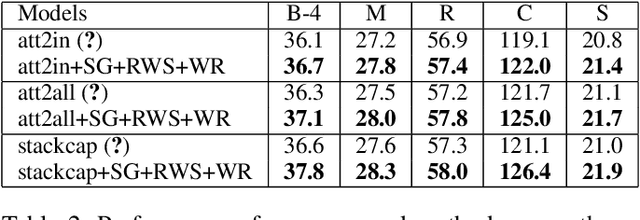
Generating natural and accurate descriptions in image cap-tioning has always been a challenge. In this paper, we pro-pose a novel recall mechanism to imitate the way human con-duct captioning. There are three parts in our recall mecha-nism : recall unit, semantic guide (SG) and recalled-wordslot (RWS). Recall unit is a text-retrieval module designedto retrieve recalled words for images. SG and RWS are de-signed for the best use of recalled words. SG branch cangenerate a recalled context, which can guide the process ofgenerating caption. RWS branch is responsible for copyingrecalled words to the caption. Inspired by pointing mecha-nism in text summarization, we adopt a soft switch to balancethe generated-word probabilities between SG and RWS. Inthe CIDEr optimization step, we also introduce an individualrecalled-word reward (WR) to boost training. Our proposedmethods (SG+RWS+WR) achieve BLEU-4 / CIDEr / SPICEscores of 36.6 / 116.9 / 21.3 with cross-entropy loss and 38.7 /129.1 / 22.4 with CIDEr optimization on MSCOCO Karpathytest split, which surpass the results of other state-of-the-artmethods.