 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TyXe: Pyro-based Bayesian neural nets for Pytorch
Oct 01, 2021
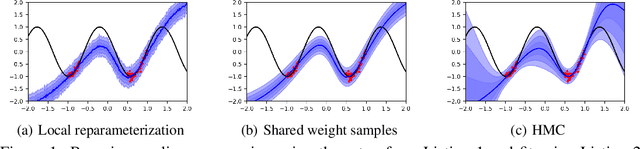
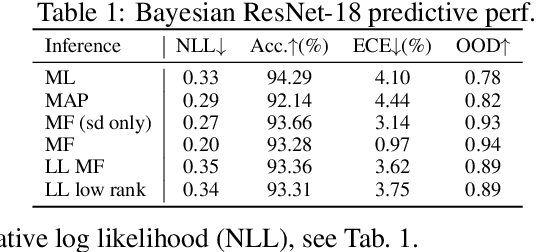
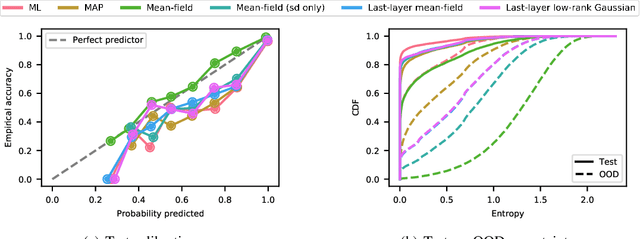

We introduce TyXe, a Bayesian neural network library built on top of Pytorch and Pyro. Our leading design principle is to cleanly separate architecture, prior, inference and likelihood specification, allowing for a flexible workflow where users can quickly iterate over combinations of these components. In contrast to existing packages TyXe does not implement any layer classes, and instead relies on architectures defined in generic Pytorch code. TyXe then provides modular choices for canonical priors, variational guides, inference techniques, and layer selections for a Bayesian treatment of the specified architecture. Sampling tricks for variance reduction, such as local reparameterization or flipout, are implemented as effect handlers, which can be applied independently of other specifications. We showcase the ease of use of TyXe to explore Bayesian versions of popular models from various libraries: toy regression with a pure Pytorch neural network; large-scale image classification with torchvision ResNets; graph neural networks based on DGL; and Neural Radiance Fields built on top of Pytorch3D. Finally, we provide convenient abstractions for variational continual learning. In all cases the change from a deterministic to a Bayesian neural network comes with minimal modifications to existing code, offering a broad range of researchers and practitioners alike practical access to uncertainty estimation techniques. The library is available at https://github.com/TyXe-BDL/TyXe.
Reliable and Efficient Image Cropping: A Grid Anchor based Approach
Apr 09, 2019
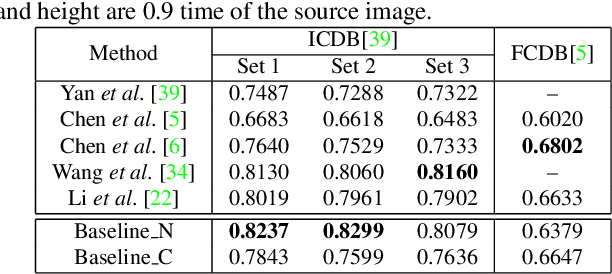

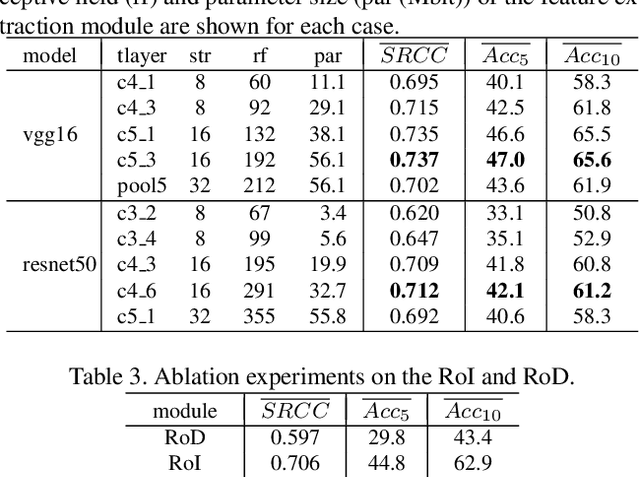
Image cropping aims to improve the composition as well as aesthetic quality of an image by removing extraneous content from it. Existing image cropping databases provide only one or several human-annotated bounding boxes as the groundtruth, which cannot reflect the non-uniqueness and flexibility of image cropping in practice. The employed evaluation metrics such as intersection-over-union cannot reliably reflect the real performance of cropping models, either. This work revisits the problem of image cropping, and presents a grid anchor based formulation by considering the special properties and requirements (e.g., local redundancy, content preservation, aspect ratio) of image cropping. Our formulation reduces the searching space of candidate crops from millions to less than one hundred. Consequently, a grid anchor based cropping benchmark is constructed, where all crops of each image are annotated and more reliable evaluation metrics are defined. We also design an effective and lightweight network module, which simultaneously considers the region of interest and region of discard for more accurate image cropping. Our model can stably output visually pleasing crops for images of different scenes and run at a speed of 125 FPS. Code and dataset are available at: https://github.com/HuiZeng/Grid-Anchor-based-Image-Cropping.
PeelNet: Textured 3D reconstruction of human body using single view RGB image
Feb 16, 2020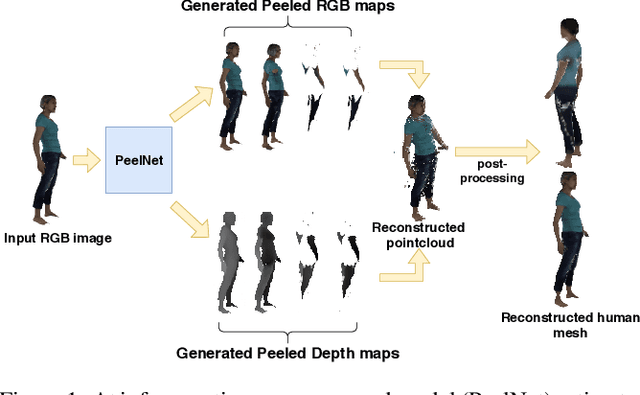

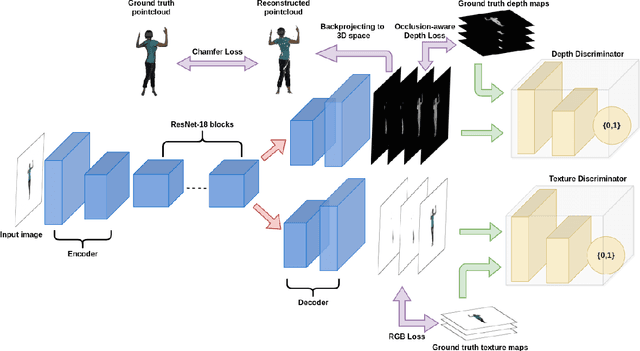
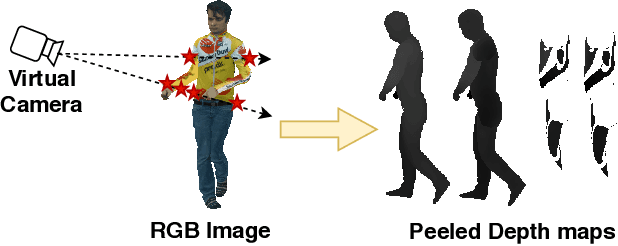
Reconstructing human shape and pose from a single image is a challenging problem due to issues like severe self-occlusions, clothing variations, and changes in lighting to name a few. Many applications in the entertainment industry, e-commerce, health-care (physiotherapy), and mobile-based AR/VR platforms can benefit from recovering the 3D human shape, pose, and texture. In this paper, we present PeelNet, an end-to-end generative adversarial framework to tackle the problem of textured 3D reconstruction of the human body from a single RGB image. Motivated by ray tracing for generating realistic images of a 3D scene, we tackle this problem by representing the human body as a set of peeled depth and RGB maps which are obtained by extending rays beyond the first intersection with the 3D object. This formulation allows us to handle self-occlusions efficiently. Current parametric model-based approaches fail to model loose clothing and surface-level details and are proposed for the underlying naked human body. Majority of non-parametric approaches are either computationally expensive or provide unsatisfactory results. We present a simple non-parametric solution where the peeled maps are generated from a single RGB image as input. Our proposed peeled depth maps are back-projected to 3D volume to obtain a complete 3D shape. The corresponding RGB maps provide vertex-level texture details. We compare our method against current state-of-the-art methods in 3D reconstruction and demonstrate the effectiveness of our method on BUFF and MonoPerfCap datasets.
Integrating Knowledge and Reasoning in Image Understanding
Jun 24, 2019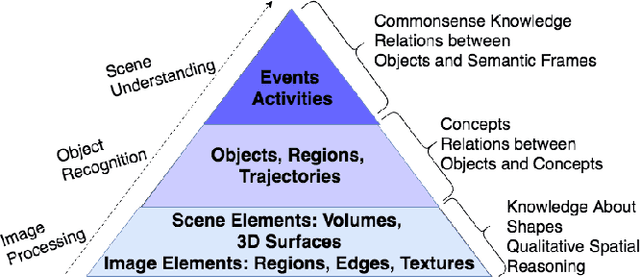

Deep learning based data-driven approaches have been successfully applied in various image understanding applications ranging from object recognition, semantic segmentation to visual question answering. However, the lack of knowledge integration as well as higher-level reasoning capabilities with the methods still pose a hindrance. In this work, we present a brief survey of a few representative reasoning mechanisms, knowledge integration methods and their corresponding image understanding applications developed by various groups of researchers, approaching the problem from a variety of angles. Furthermore, we discuss upon key efforts on integrating external knowledge with neural networks. Taking cues from these efforts, we conclude by discussing potential pathways to improve reasoning capabilities.
* 8 pages, 2 figures
Accurate Indoor Radio Frequency Imaging using a New Extended Rytov Approximation for Lossy Media
Oct 07, 2021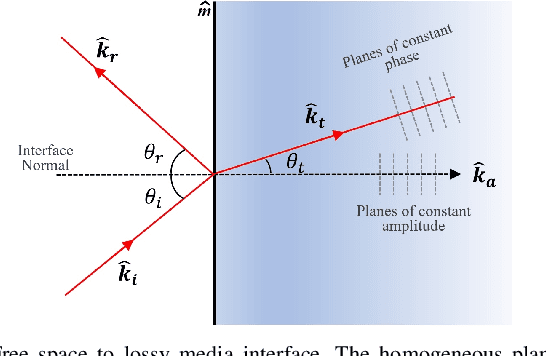
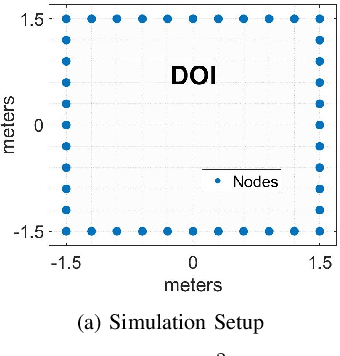
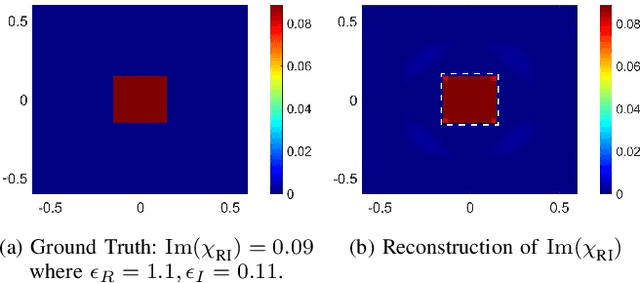
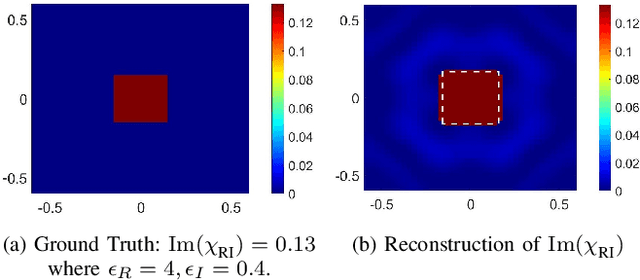
Imaging objects with high relative permittivity and large electrical size remains a challenging problem in the field of inverse scattering. In this work we present a phaseless inverse scattering method that can accurately image and reconstruct objects even with these attributes. The reconstruction accuracy obtained under these conditions has not been achieved previously and can therefore open up the area to technologically important applications such as indoor Radio Frequency (RF) and microwave imaging. The novelty of the approach is that it utilizes a high frequency approximation for waves passing through lossy media to provide corrections to the conventional Rytov approximation (RA). We refer to this technique as the Extended Phaseless Rytov Approximation for Low Loss Media (xPRA-LM). Simulation as well as experimental results are provided for indoor RF imaging using phaseless measurements from 2.4 GHz based WiFi nodes. We demonstrate that the approach provides accurate reconstruction of an object up to relative permittivities of $15+j1.5$ for object sizes greater than $20 \lambda$ ($\lambda$ is wavelength inside object). Even at higher relative permittivities of up to $\epsilon_r=77+j 7$, object shape reconstruction remains accurate, however the reconstruction amplitude is less accurate. These results have not been obtained before and can be utilized to achieve the potential of RF and microwave imaging in applications such as indoor RF imaging.
ZSD-YOLO: Zero-Shot YOLO Detection using Vision-Language KnowledgeDistillation
Sep 24, 2021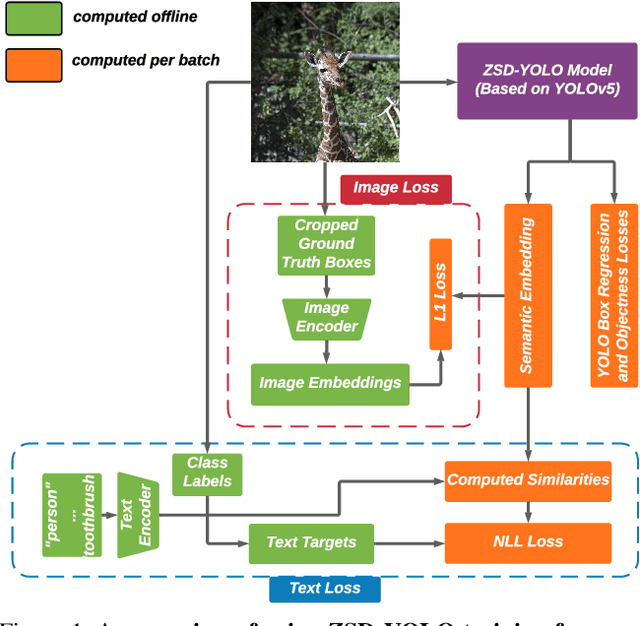
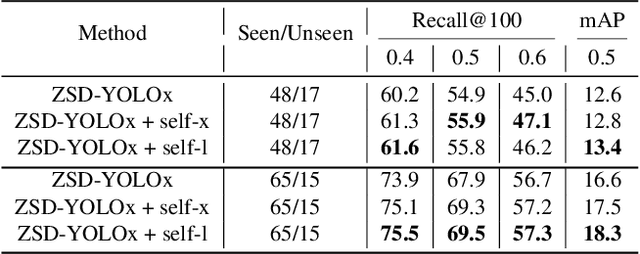
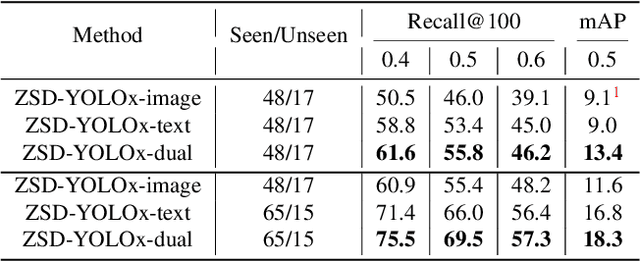

Real-world object sampling produces long-tailed distributions requiring exponentially more images for rare types. Zero-shot detection, which aims to detect unseen objects, is one direction to address this problem. A dataset such as COCO is extensively annotated across many images but with a sparse number of categories and annotating all object classes across a diverse domain is expensive and challenging. To advance zero-shot detection, we develop a Vision-Language distillation method that aligns both image and text embeddings from a zero-shot pre-trained model such as CLIP to a modified semantic prediction head from a one-stage detector like YOLOv5. With this method, we are able to train an object detector that achieves state-of-the-art accuracy on the COCO zero-shot detection splits with fewer model parameters. During inference, our model can be adapted to detect any number of object classes without additional training. We also find that the improvements provided by the scaling of our method are consistent across various YOLOv5 scales. Furthermore, we develop a self-training method that provides a significant score improvement without needing extra images nor labels.
Image Processing and Quality Control for Abdominal Magnetic Resonance Imaging in the UK Biobank
Jul 16, 2020
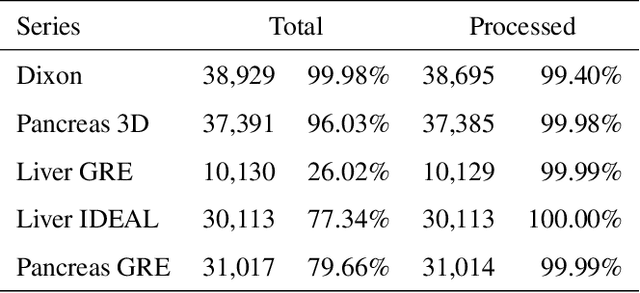

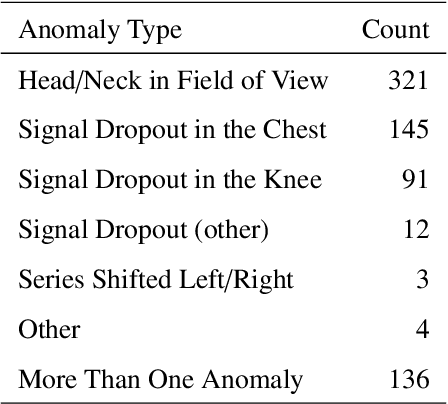
An end-to-end image analysis pipeline is presented for the abdominal MRI protocol used in the UK Biobank on the first 38,971 participants. Emphasis is on the processing steps necessary to ensure a high-level of data quality and consistency is produced in order to prepare the datasets for downstream quantitative analysis, such as segmentation and parameter estimation. Quality control procedures have been incorporated to detect and, where possible, correct issues in the raw data. Detection of fat-water swaps in the Dixon series is performed by a deep learning model and corrected automatically. Bone joints are predicted using a hybrid atlas-based registration and deep learning model for the shoulders, hips and knees. Simultaneous estimation of proton density fat fraction and transverse relaxivity (R2*) is performed using both the magnitude and phase information for the single-slice multiecho series. Approximately 98.1% of the two-point Dixon acquisitions were successfully processed and passed quality control, with 99.98% of the high-resolution T1-weighted 3D volumes succeeding. Approximately 99.98% of the single-slice multiecho acquisitions covering the liver were successfully processed and passed quality control, with 97.6% of the single-slice multiecho acquisitions covering the pancreas succeeding. At least one fat-water swap was detected in 1.8% of participants. With respect to the bone joints, approximately 3.3% of participants were missing at least one knee joint and 0.8% were missing at least one shoulder joint. For the participants who received both single-slice multiecho acquisition protocols for the liver a systematic difference between the two protocols was identified and modeled using multiple linear regression. The findings presented here will be invaluable for scientists who seek to use image-derived phenotypes from the abdominal MRI protocol.
A Method to Generate Synthetically Warped Document Image
Oct 15, 2019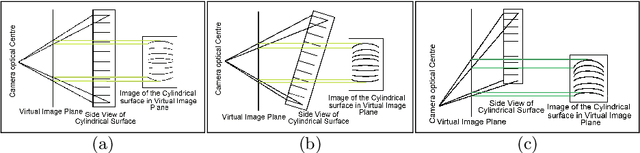

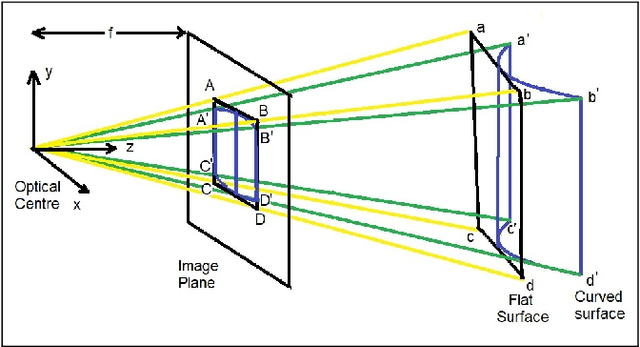

The digital camera captured document images may often be warped and distorted due to different camera angles or document surfaces. A robust technique is needed to solve this kind of distortion. The research on dewarping of the document suffers due to the limited availability of benchmark public dataset. In recent times, deep learning based approaches are used to solve the problems accurately. To train most of the deep neural networks a large number of document images is required and generating such a large volume of document images manually is difficult. In this paper, we propose a technique to generate a synthetic warped image from a flat-bedded scanned document image. It is done by calculating warping factors for each pixel position using two warping position parameters (WPP) and eight warping control parameters (WCP). These parameters can be specified as needed depending upon the desired warping. The results are compared with similar real captured images both qualitative and quantitative way.
Bilinear discriminant feature line analysis for image feature extraction
May 03, 2019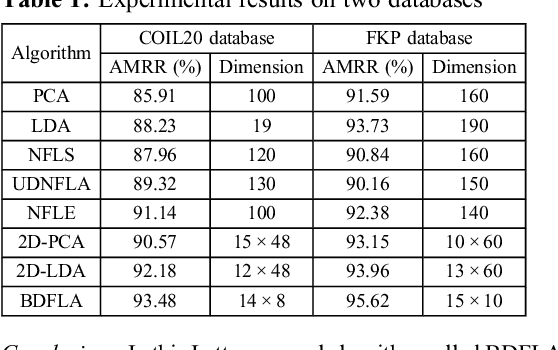
A novel bilinear discriminant feature line analysis (BDFLA) is proposed for image feature extraction. The nearest feature line (NFL) is a powerful classifier. Some NFL-based subspace algorithms were introduced recently. In most of the classical NFL-based subspace learning approaches, the input samples are vectors. For image classification tasks, the image samples should be transformed to vectors first. This process induces a high computational complexity and may also lead to loss of the geometric feature of samples. The proposed BDFLA is a matrix-based algorithm. It aims to minimise the within-class scatter and maximise the between-class scatter based on a two-dimensional (2D) NFL. Experimental results on two-image databases confirm the effectiveness.
NICO: A Dataset Towards Non-I.I.D. Image Classification
Jun 07, 2019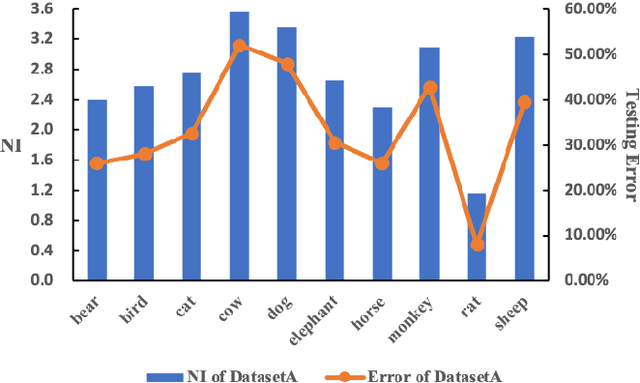
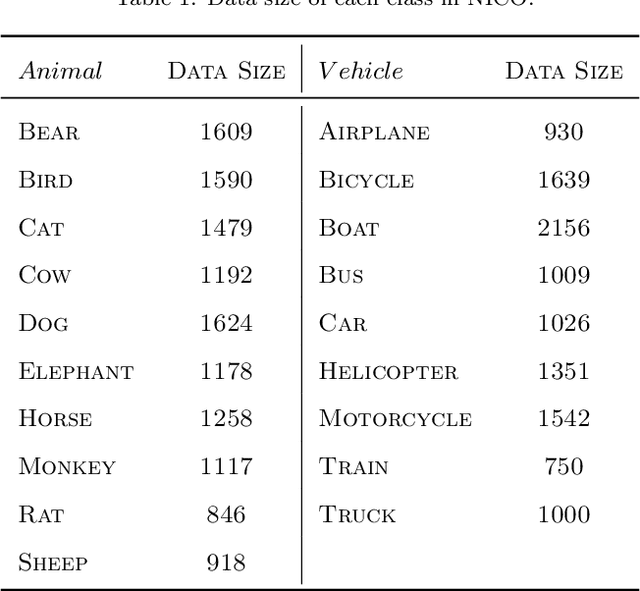
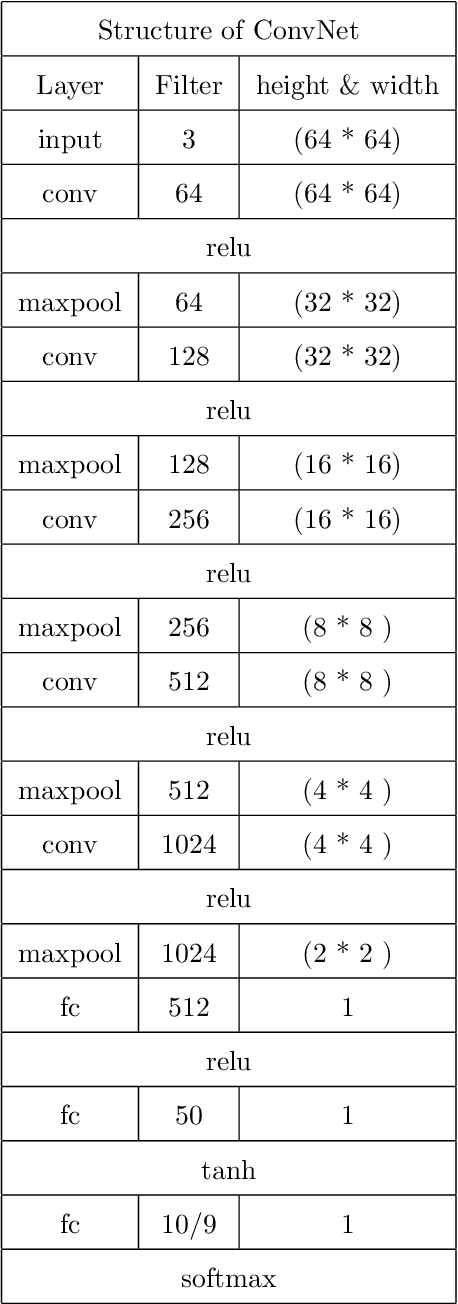
The I.I.D. hypothesis between training data and testing data is the basis of a large number of image classification methods. Such a property can hardly be guaranteed in practical cases where the Non-IIDness is common, leading to instable performances of these models. In literature, however, the Non-I.I.D. image classification problem is largely understudied. A key reason is the lacking of a well-designed dataset to support related research. In this paper, we construct and release a Non-I.I.D. image dataset called NICO, which makes use of contexts to create Non-IIDness consciously. Extended experimental results and anslyses demonstrate that the NICO dataset can well support the training of a ConvNet model from scratch, and NICO can support various Non-I.I.D. situations with sufficient flexibility compared to other datasets.