 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Convolutional neural networks model improvements using demographics and image processing filters on chest x-rays
Nov 30, 2019
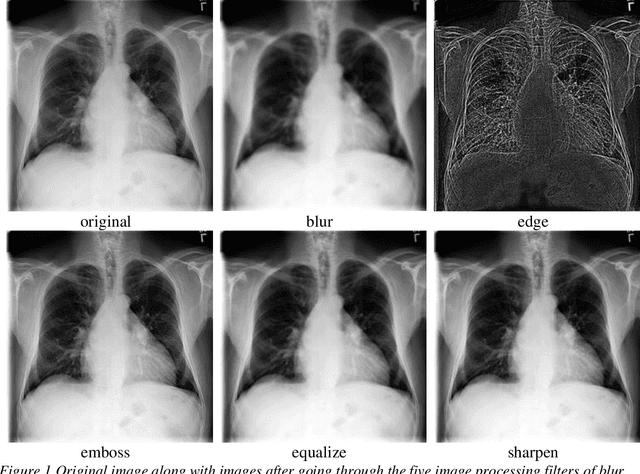
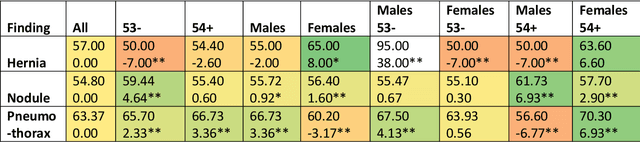
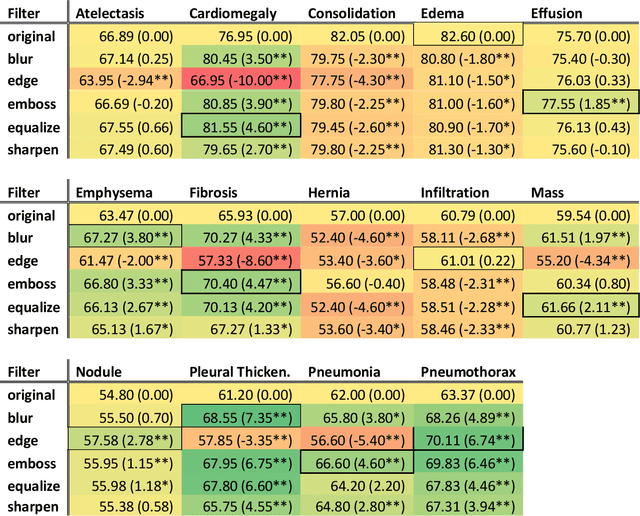

Purpose: The purpose of this study was to observe change in accuracies of convolutional neural networks (CNN) models (ratio of correct classifications to total predictions) on thoracic radiological images by creating different binary classification models based on age, gender, and image pre-processing filters on 14 pathologies. Methodology: This is a quantitative research exploring variation in CNN model accuracies. Radiological thoracic images were divided by age and gender and pre-processed by various image processing filters. Findings: We found partial support for enhancement to model accuracies by segregating modeling images by age and gender and applying image processing filters even though image processing filters are sometimes thought of as information filters. Research limitations: This study may be biased because it is based on radiological images by another research that tagged the images using an automated process that was not checked by a human. Practical implications: Researchers may want to focus on creating models segregated by demographics and pre-process the modeling images using image processing filters. Practitioners developing assistive technologies for thoracic diagnoses may benefit from incorporating demographics and employing multiple models simultaneously with varying statistical likelihood. Originality/value: This study uses demographics in model creation and utilizes image processing filters to improve model performance. Keywords: Convolutional Neural Network (CNN), Chest X-Ray, ChestX-ray14, Lung, Atelectasis, Cardiomegaly, Consolidation, Edema, Effusion, Emphysema, Infiltration, Mass, Nodule, Pleural Thickening, Pneumonia, Pneumathorax
SUR-FeatNet: Predicting the Satisfied User Ratio Curvefor Image Compression with Deep Feature Learning
Jan 07, 2020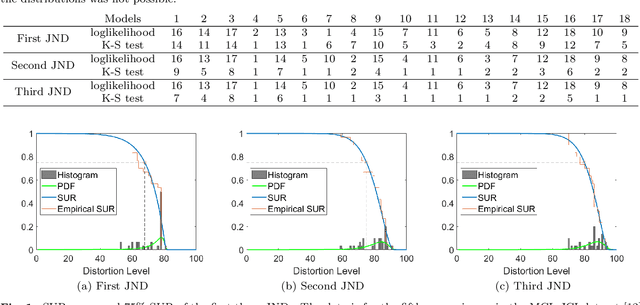
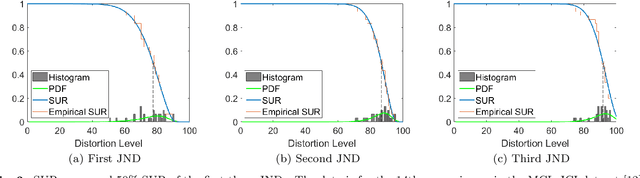
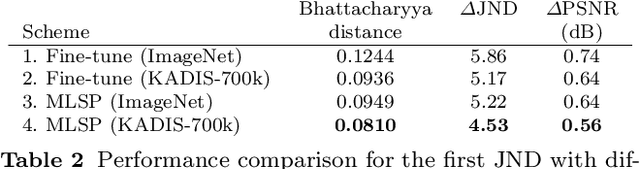
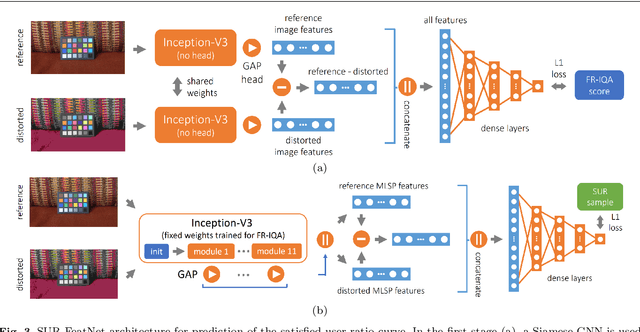
The Satisfied User Ratio (SUR) curve for a lossy image compression scheme, e.g., JPEG, gives the distribution function of the Just Noticeable Difference (JND), the smallest distortion level that can be perceived by a subject when a reference image is compared to a distorted one. A sequence of JNDs can be defined with a suitable successive choice of reference images. We propose the first deep learning approach to predict SUR curves. We show how to exploit maximum likelihood estimation and the Kolmogorov-Smirnov test to select a suitable parametric model for the distribution function. We then use deep feature learning to predict samples of the SUR curve and apply the method of least squares to fit the parametric model to the predicted samples. Our deep learning approach relies on a Siamese Convolutional Neural Networks (CNN), transfer learning, and deep feature learning, using pairs consisting of a reference image and compressed image for training. Experiments on the MCL-JCI dataset showed state-of-the-art performance. For example, the mean Bhattacharyya distances between the predicted and ground truth first, second, and third JND distributions were 0.0810, 0.0702, and 0.0522, respectively, and the corresponding average absolute differences of the peak signal-to-noise ratio at the median of the distributions were 0.56, 0.65, and 0.53 dB.
A Universal Representation Transformer Layer for Few-Shot Image Classification
Jun 21, 2020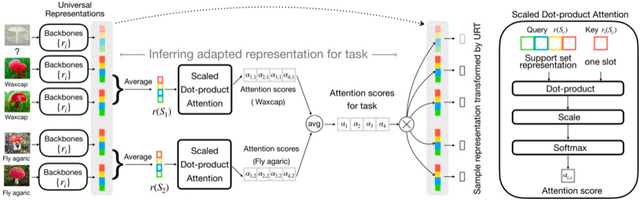
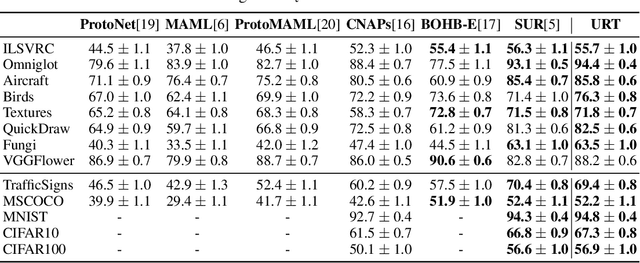
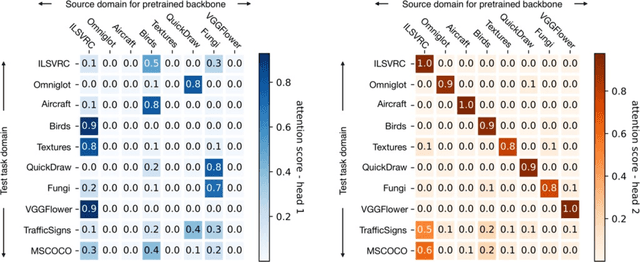
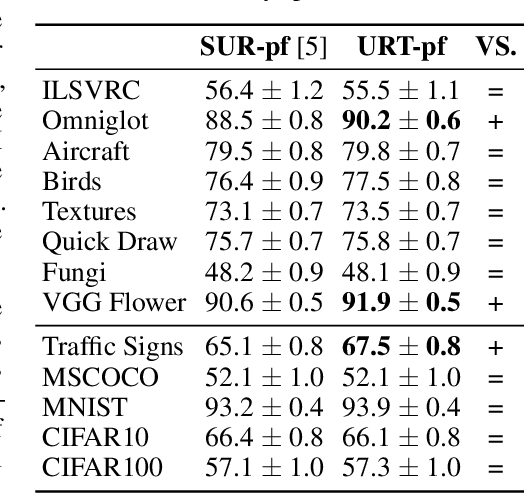
Few-shot classification aims to recognize unseen classes when presented with only a small number of samples. We consider the problem of multi-domain few-shot image classification, where unseen classes and examples come from diverse data sources. This problem has seen growing interest and has inspired the development of benchmarks such as Meta-Dataset. A key challenge in this multi-domain setting is to effectively integrate the feature representations from the diverse set of training domains. Here, we propose a Universal Representation Transformer (URT) layer, that meta-learns to leverage universal features for few-shot classification by dynamically re-weighting and composing the most appropriate domain-specific representations. In experiments, we show that URT sets a new state-of-the-art result on Meta-Dataset. Specifically, it outperforms the best previous model on three data sources or performs the same in others. We analyze variants of URT and present a visualization of the attention score heatmaps that sheds light on how the model performs cross-domain generalization. Our code is available at https://github.com/liulu112601/URT.
Multi-task Federated Learning for Heterogeneous Pancreas Segmentation
Aug 19, 2021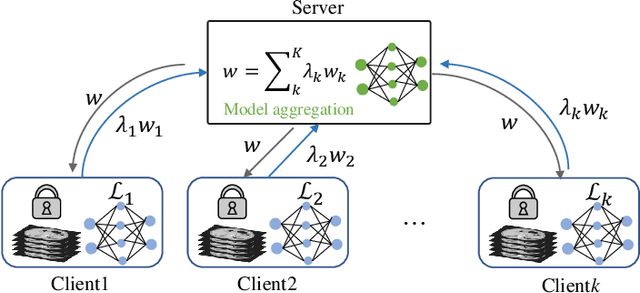
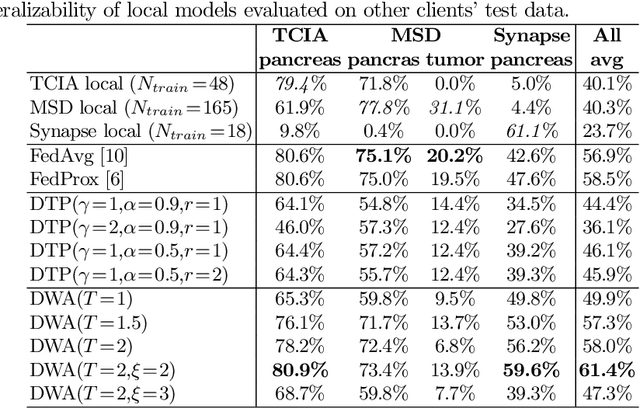
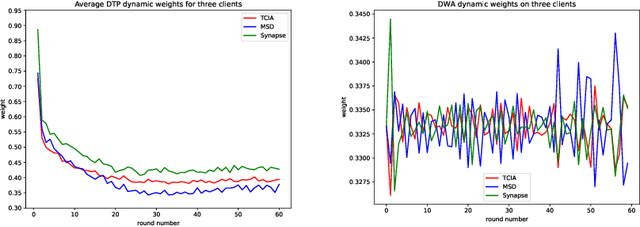

Federated learning (FL) for medical image segmentation becomes more challenging in multi-task settings where clients might have different categories of labels represented in their data. For example, one client might have patient data with "healthy'' pancreases only while datasets from other clients may contain cases with pancreatic tumors. The vanilla federated averaging algorithm makes it possible to obtain more generalizable deep learning-based segmentation models representing the training data from multiple institutions without centralizing datasets. However, it might be sub-optimal for the aforementioned multi-task scenarios. In this paper, we investigate heterogeneous optimization methods that show improvements for the automated segmentation of pancreas and pancreatic tumors in abdominal CT images with FL settings.
Distinguishing rule- and exemplar-based generalization in learning systems
Oct 08, 2021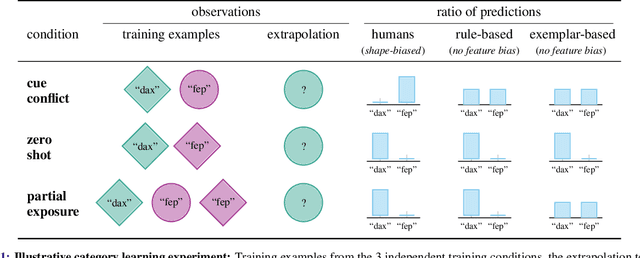
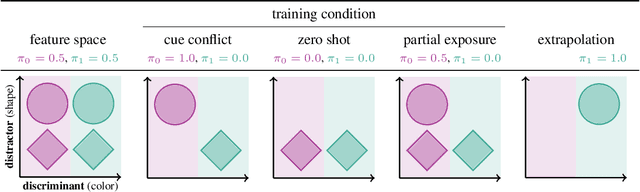
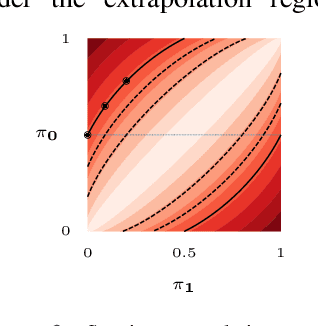
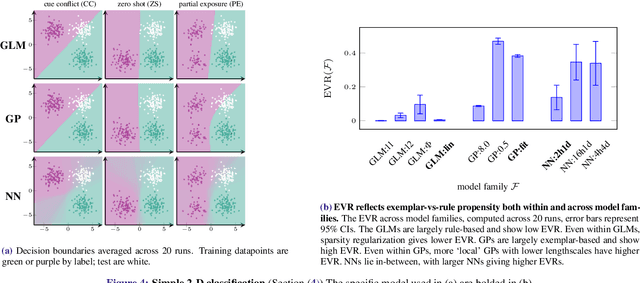
Despite the increasing scale of datasets in machine learning, generalization to unseen regions of the data distribution remains crucial. Such extrapolation is by definition underdetermined and is dictated by a learner's inductive biases. Machine learning systems often do not share the same inductive biases as humans and, as a result, extrapolate in ways that are inconsistent with our expectations. We investigate two distinct such inductive biases: feature-level bias (differences in which features are more readily learned) and exemplar-vs-rule bias (differences in how these learned features are used for generalization). Exemplar- vs. rule-based generalization has been studied extensively in cognitive psychology, and, in this work, we present a protocol inspired by these experimental approaches for directly probing this trade-off in learning systems. The measures we propose characterize changes in extrapolation behavior when feature coverage is manipulated in a combinatorial setting. We present empirical results across a range of models and across both expository and real-world image and language domains. We demonstrate that measuring the exemplar-rule trade-off while controlling for feature-level bias provides a more complete picture of extrapolation behavior than existing formalisms. We find that most standard neural network models have a propensity towards exemplar-based extrapolation and discuss the implications of these findings for research on data augmentation, fairness, and systematic generalization.
Milking CowMask for Semi-Supervised Image Classification
Apr 03, 2020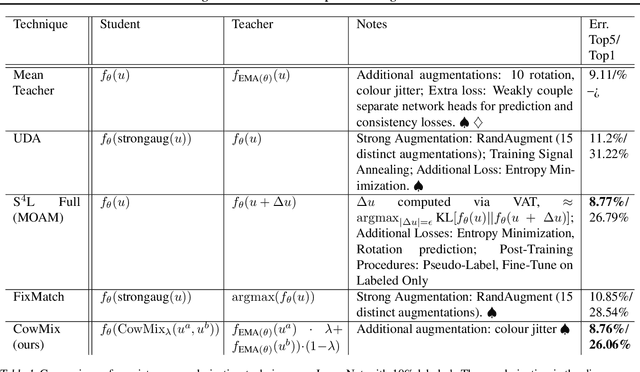

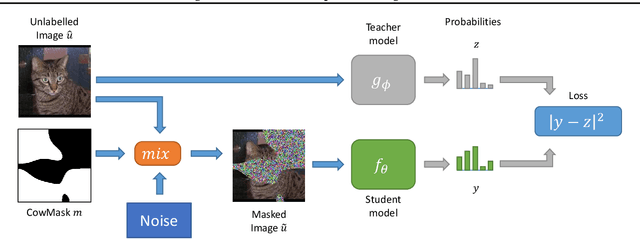
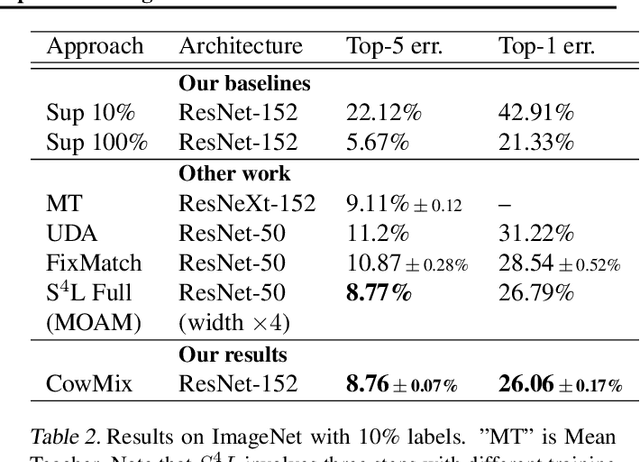
Consistency regularization is a technique for semi-supervised learning that has recently been shown to yield strong results for classification with few labeled data. The method works by perturbing input data using augmentation or adversarial examples, and encouraging the learned model to be robust to these perturbations on unlabeled data. Here, we evaluate the use of a recently proposed augmentation method, called CowMasK, for this purpose. Using CowMask as the augmentation method in semi-supervised consistency regularization, we establish a new state-of-the-art result on Imagenet with 10% labeled data, with a top-5 error of 8.76% and top-1 error of 26.06%. Moreover, we do so with a method that is much simpler than alternative methods. We further investigate the behavior of CowMask for semi-supervised learning by running many smaller scale experiments on the small image benchmarks SVHN, CIFAR-10 and CIFAR-100, where we achieve results competitive with the state of the art, and where we find evidence that the CowMask perturbation is widely applicable. We open source our code at https://github.com/google-research/google-research/tree/master/milking_cowmask
Excavating the Potential Capacity of Self-Supervised Monocular Depth Estimation
Sep 26, 2021
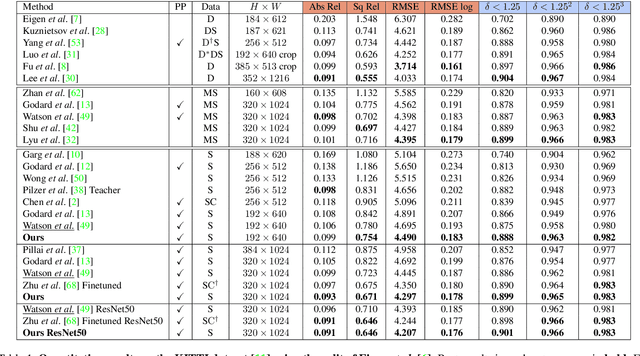
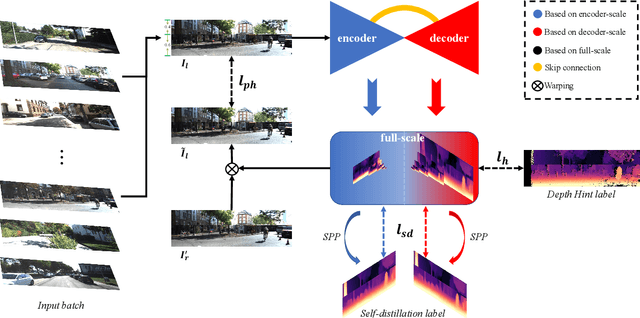
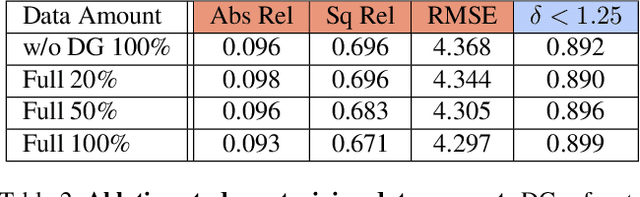
Self-supervised methods play an increasingly important role in monocular depth estimation due to their great potential and low annotation cost. To close the gap with supervised methods, recent works take advantage of extra constraints, e.g., semantic segmentation. However, these methods will inevitably increase the burden on the model. In this paper, we show theoretical and empirical evidence that the potential capacity of self-supervised monocular depth estimation can be excavated without increasing this cost. In particular, we propose (1) a novel data augmentation approach called data grafting, which forces the model to explore more cues to infer depth besides the vertical image position, (2) an exploratory self-distillation loss, which is supervised by the self-distillation label generated by our new post-processing method - selective post-processing, and (3) the full-scale network, designed to endow the encoder with the specialization of depth estimation task and enhance the representational power of the model. Extensive experiments show that our contributions can bring significant performance improvement to the baseline with even less computational overhead, and our model, named EPCDepth, surpasses the previous state-of-the-art methods even those supervised by additional constraints.
Learning Facial Representations from the Cycle-consistency of Face
Aug 07, 2021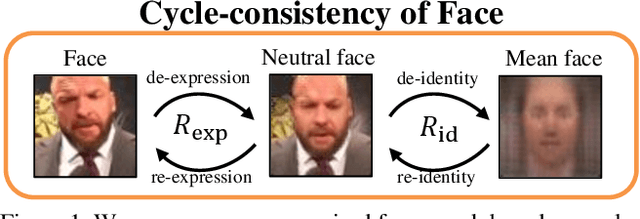
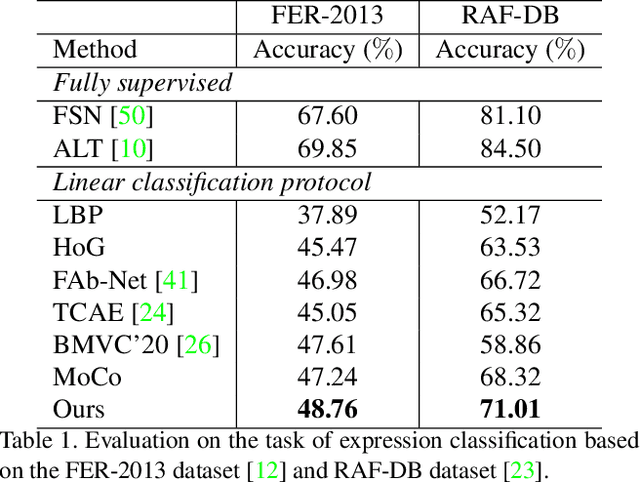
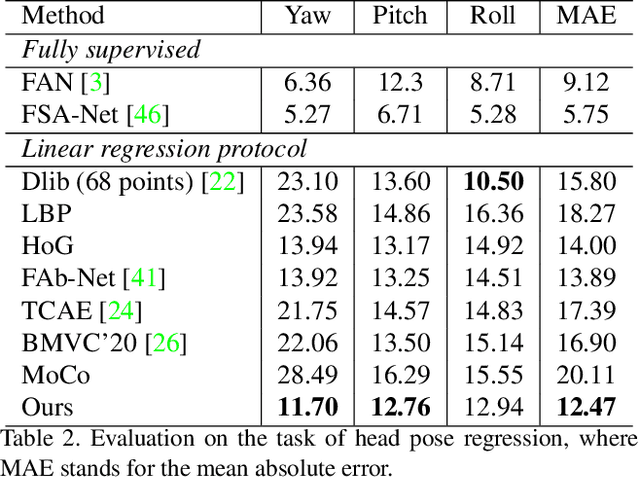
Faces manifest large variations in many aspects, such as identity, expression, pose, and face styling. Therefore, it is a great challenge to disentangle and extract these characteristics from facial images, especially in an unsupervised manner. In this work, we introduce cycle-consistency in facial characteristics as free supervisory signal to learn facial representations from unlabeled facial images. The learning is realized by superimposing the facial motion cycle-consistency and identity cycle-consistency constraints. The main idea of the facial motion cycle-consistency is that, given a face with expression, we can perform de-expression to a neutral face via the removal of facial motion and further perform re-expression to reconstruct back to the original face. The main idea of the identity cycle-consistency is to exploit both de-identity into mean face by depriving the given neutral face of its identity via feature re-normalization and re-identity into neutral face by adding the personal attributes to the mean face. At training time, our model learns to disentangle two distinct facial representations to be useful for performing cycle-consistent face reconstruction. At test time, we use the linear protocol scheme for evaluating facial representations on various tasks, including facial expression recognition and head pose regression. We also can directly apply the learnt facial representations to person recognition, frontalization and image-to-image translation. Our experiments show that the results of our approach is competitive with those of existing methods, demonstrating the rich and unique information embedded in the disentangled representations. Code is available at https://github.com/JiaRenChang/FaceCycle .
Indoor image representation by high-level semantic features
Jul 12, 2019
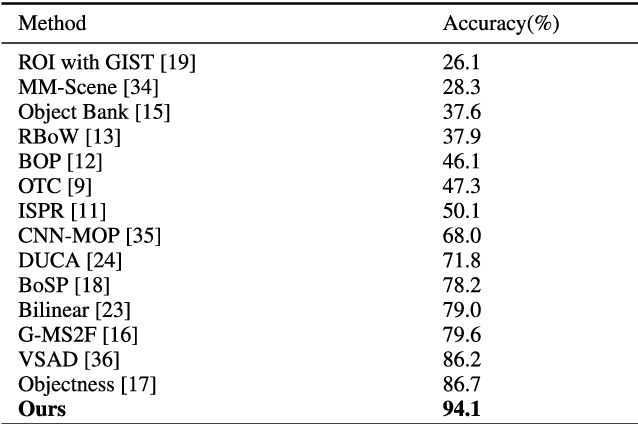

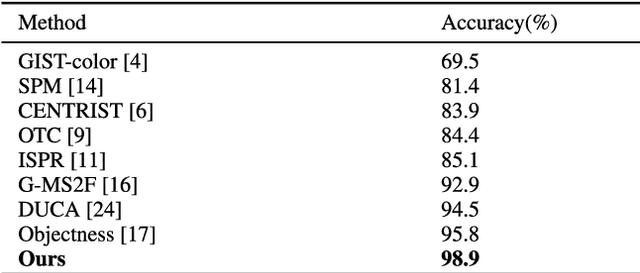
Indoor image features extraction is a fundamental problem in multiple fields such as image processing, pattern recognition, robotics and so on. Nevertheless, most of the existing feature extraction methods, which extract features based on pixels, color, shape/object parts or objects on images, suffer from limited capabilities in describing semantic information (e.g., object association). These techniques, therefore, involve undesired classification performance. To tackle this issue, we propose the notion of high-level semantic features and design four steps to extract them. Specifically, we first construct the objects pattern dictionary through extracting raw objects in the images, and then retrieve and extract semantic objects from the objects pattern dictionary. We finally extract our high-level semantic features based on the calculated probability and delta parameter. Experiments on three publicly available datasets (MIT-67, Scene15 and NYU V1) show that our feature extraction approach outperforms state-of-the-art feature extraction methods for indoor image classification, given a lower dimension of our features than those methods.
Venc Design and Velocity Estimation for Phase Contrast MRI
Sep 26, 2021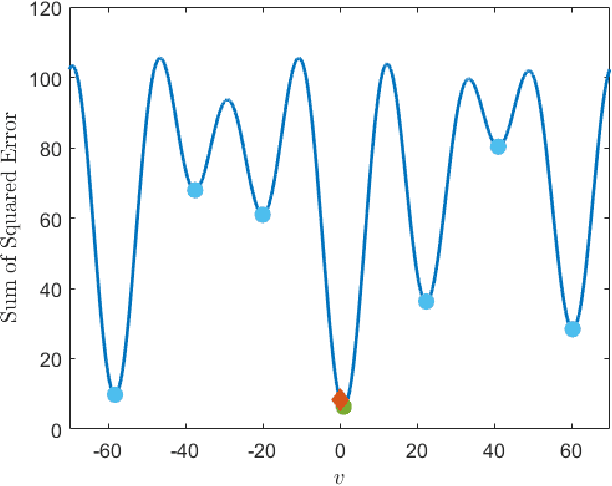
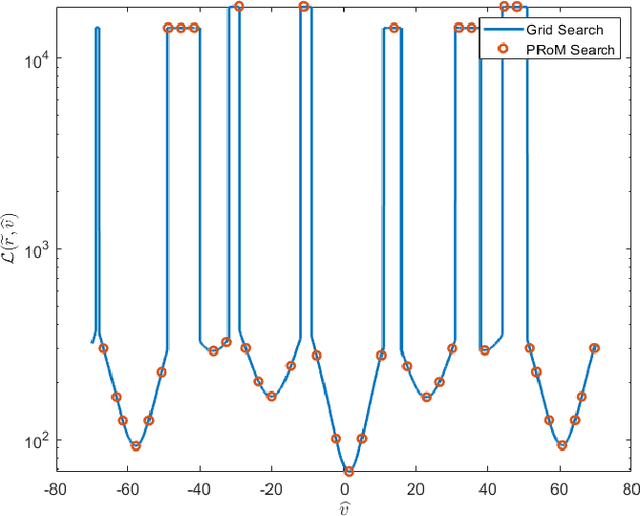
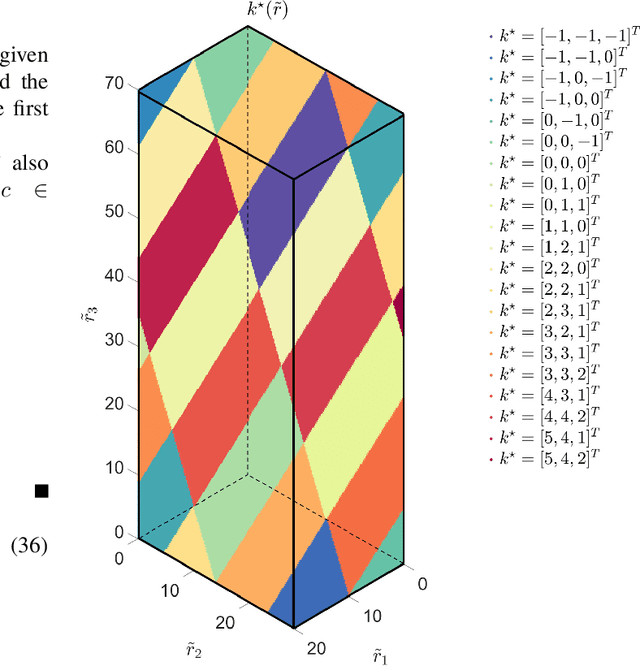

In phase-contrast magnetic resonance imaging (PC-MRI), the velocity of spins at a voxel is encoded in the image phase. The strength of the velocity encoding (venc) gradient offers a trade-off between the velocity-to-noise ratio (VNR) and the extent of phase aliasing. In the three-point encoding employed in traditional dual-venc acquisition, two velocity-encoded acquisitions are acquired along with a third velocity-compensated measurement; their phase differences result in an unaliased high-venc measurement used to unwrap the less noisy low-venc measurement. Alternatively, the velocity may be more accurately estimated by jointly processing all three potentially wrapped phase differences. We present a fast, grid-free approximate maximum likelihood estimator, Phase Recovery from Multiple Wrapped Measurements (PRoM), for solving a noisy set of congruence equations with correlated noise. PRoM is applied to three-point acquisition for estimating velocity. The proposed approach can significantly expand the range of correctly unwrapped velocities compared to the traditional dual-venc method, while also providing improvement in velocity-to-noise ratio. Moreover, its closed-form expressions for the probability distribution of the estimated velocity enable the optimized design of acquisition.