 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Style Generator Inversion for Image Enhancement and Animation
Jun 05, 2019

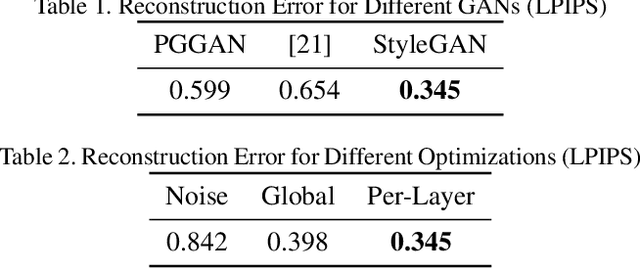


One of the main motivations for training high quality image generative models is their potential use as tools for image manipulation. Recently, generative adversarial networks (GANs) have been able to generate images of remarkable quality. Unfortunately, adversarially-trained unconditional generator networks have not been successful as image priors. One of the main requirements for a network to act as a generative image prior, is being able to generate every possible image from the target distribution. Adversarial learning often experiences mode-collapse, which manifests in generators that cannot generate some modes of the target distribution. Another requirement often not satisfied is invertibility i.e. having an efficient way of finding a valid input latent code given a required output image. In this work, we show that differently from earlier GANs, the very recently proposed style-generators are quite easy to invert. We use this important observation to propose style generators as general purpose image priors. We show that style generators outperform other GANs as well as Deep Image Prior as priors for image enhancement tasks. The latent space spanned by style-generators satisfies linear identity-pose relations. The latent space linearity, combined with invertibility, allows us to animate still facial images without supervision. Extensive experiments are performed to support the main contributions of this paper.
Using Wavelets and Spectral Methods to Study Patterns in Image-Classification Datasets
Jun 17, 2020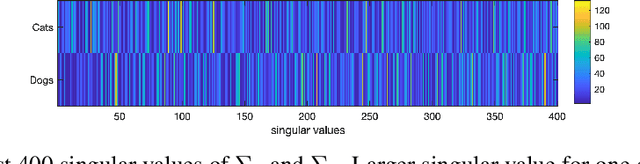

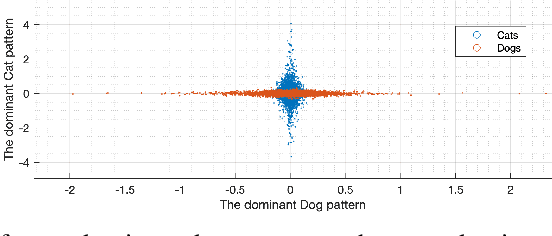

Deep learning models extract, before a final classification layer, features or patterns which are key for their unprecedented advantageous performance. However, the process of complex nonlinear feature extraction is not well understood, a major reason why interpretation, adversarial robustness, and generalization of deep neural nets are all open research problems. In this paper, we use wavelet transformation and spectral methods to analyze the contents of image classification datasets, extract specific patterns from the datasets and find the associations between patterns and classes. We show that each image can be written as the summation of a finite number of rank-1 patterns in the wavelet space, providing a low rank approximation that captures the structures and patterns essential for learning. Regarding the studies on memorization vs learning, our results clearly reveal disassociation of patterns from classes, when images are randomly labeled. Our method can be used as a pattern recognition approach to understand and interpret learnability of these datasets. It may also be used for gaining insights about the features and patterns that deep classifiers learn from the datasets.
Efficient Folded Attention for 3D Medical Image Reconstruction and Segmentation
Sep 13, 2020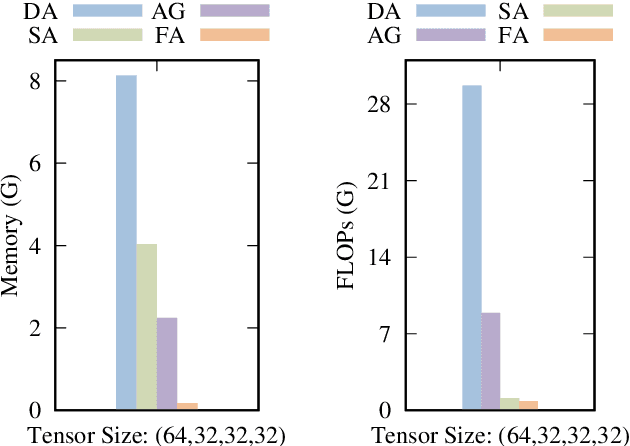
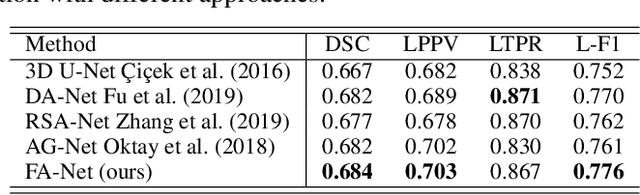
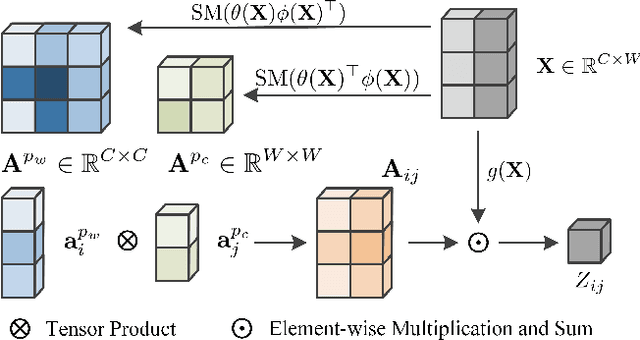
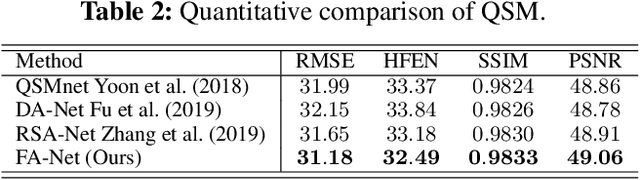
Recently, 3D medical image reconstruction (MIR) and segmentation (MIS) based on deep neural networks have been developed with promising results, and attention mechanism has been further designed to capture global contextual information for performance enhancement. However, the large size of 3D volume images poses a great computational challenge to traditional attention methods. In this paper, we propose a folded attention (FA) approach to improve the computational efficiency of traditional attention methods on 3D medical images. The main idea is that we apply tensor folding and unfolding operations with four permutations to build four small sub-affinity matrices to approximate the original affinity matrix. Through four consecutive sub-attention modules of FA, each element in the feature tensor can aggregate spatial-channel information from all other elements. Compared to traditional attention methods, with moderate improvement of accuracy, FA can substantially reduce the computational complexity and GPU memory consumption. We demonstrate the superiority of our method on two challenging tasks for 3D MIR and MIS, which are quantitative susceptibility mapping and multiple sclerosis lesion segmentation.
Knowledge Cross-Distillation for Membership Privacy
Nov 02, 2021
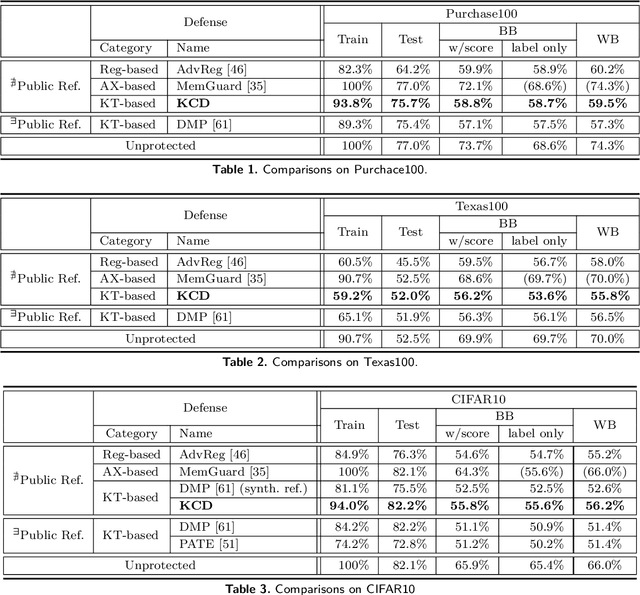
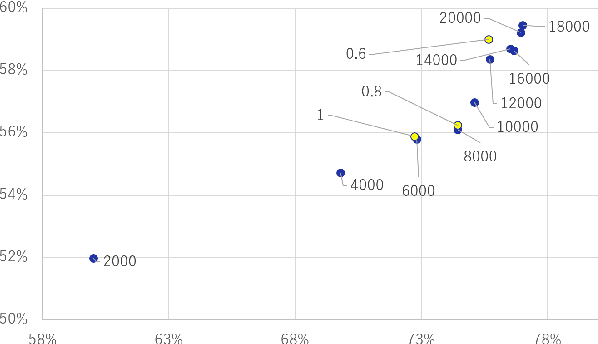
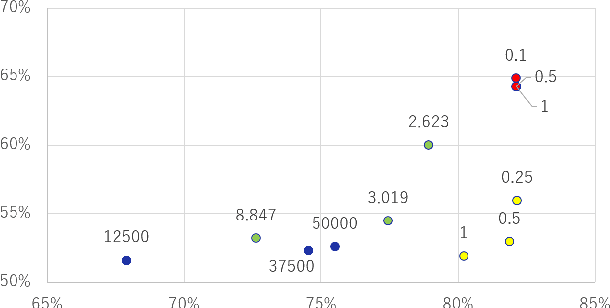
A membership inference attack (MIA) poses privacy risks on the training data of a machine learning model. With an MIA, an attacker guesses if the target data are a member of the training dataset. The state-of-the-art defense against MIAs, distillation for membership privacy (DMP), requires not only private data to protect but a large amount of unlabeled public data. However, in certain privacy-sensitive domains, such as medical and financial, the availability of public data is not obvious. Moreover, a trivial method to generate the public data by using generative adversarial networks significantly decreases the model accuracy, as reported by the authors of DMP. To overcome this problem, we propose a novel defense against MIAs using knowledge distillation without requiring public data. Our experiments show that the privacy protection and accuracy of our defense are comparable with those of DMP for the benchmark tabular datasets used in MIA researches, Purchase100 and Texas100, and our defense has much better privacy-utility trade-off than those of the existing defenses without using public data for image dataset CIFAR10.
Reasoning Graph Networks for Kinship Verification: from Star-shaped to Hierarchical
Sep 06, 2021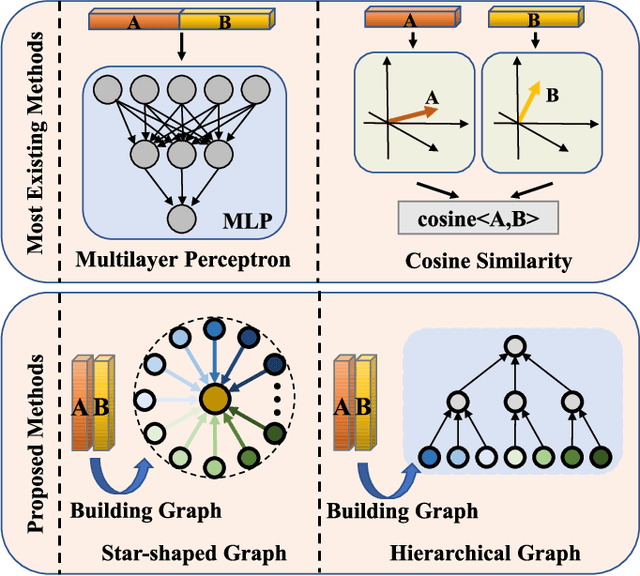
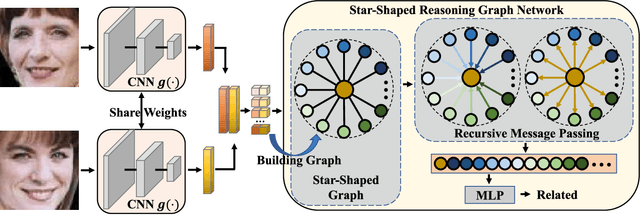

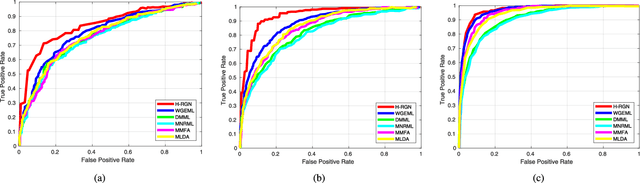
In this paper, we investigate the problem of facial kinship verification by learning hierarchical reasoning graph networks. Conventional methods usually focus on learning discriminative features for each facial image of a paired sample and neglect how to fuse the obtained two facial image features and reason about the relations between them. To address this, we propose a Star-shaped Reasoning Graph Network (S-RGN). Our S-RGN first constructs a star-shaped graph where each surrounding node encodes the information of comparisons in a feature dimension and the central node is employed as the bridge for the interaction of surrounding nodes. Then we perform relational reasoning on this star graph with iterative message passing. The proposed S-RGN uses only one central node to analyze and process information from all surrounding nodes, which limits its reasoning capacity. We further develop a Hierarchical Reasoning Graph Network (H-RGN) to exploit more powerful and flexible capacity. More specifically, our H-RGN introduces a set of latent reasoning nodes and constructs a hierarchical graph with them. Then bottom-up comparative information abstraction and top-down comprehensive signal propagation are iteratively performed on the hierarchical graph to update the node features. Extensive experimental results on four widely used kinship databases show that the proposed methods achieve very competitive results.
* Accepted by IEEE Transactions on Image Processing (TIP)
Structure-Preserving Multi-Domain Stain Color Augmentation using Style-Transfer with Disentangled Representations
Jul 26, 2021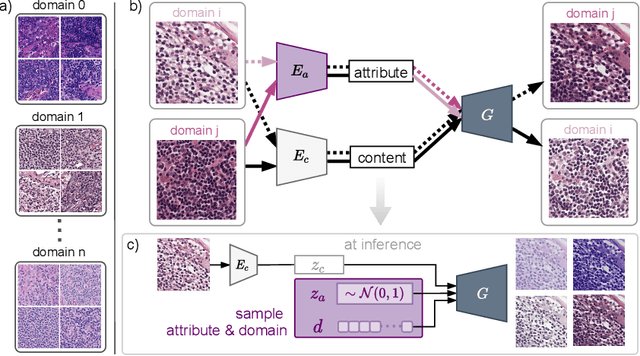
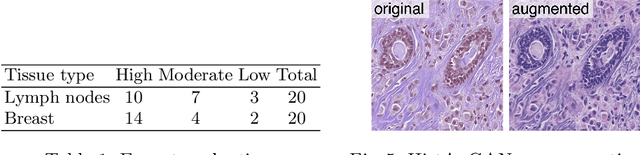
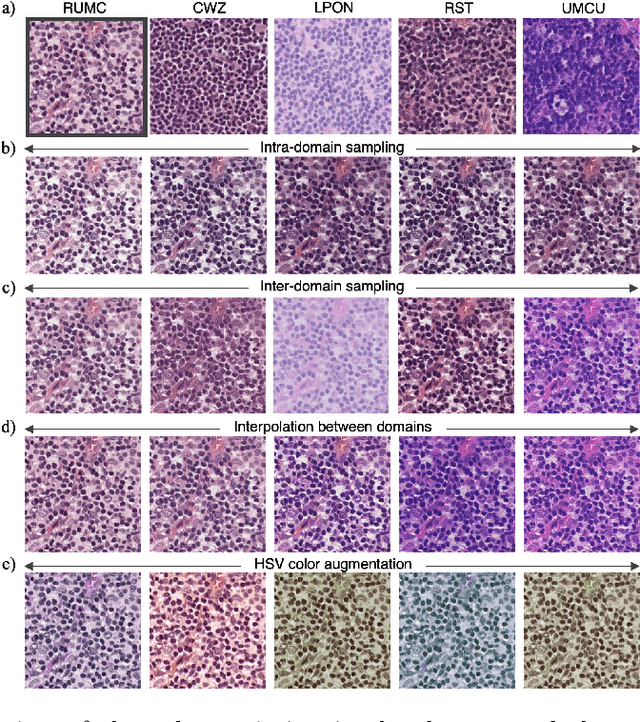
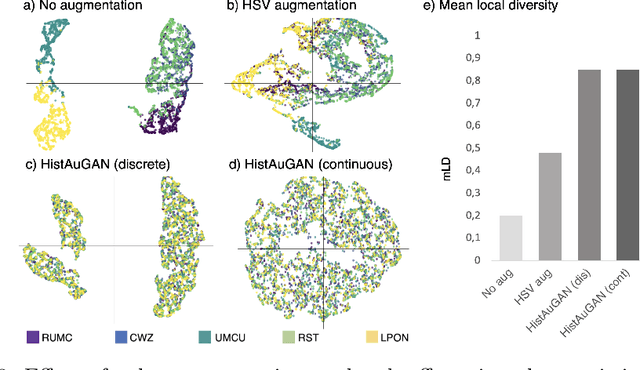
In digital pathology, different staining procedures and scanners cause substantial color variations in whole-slide images (WSIs), especially across different laboratories. These color shifts result in a poor generalization of deep learning-based methods from the training domain to external pathology data. To increase test performance, stain normalization techniques are used to reduce the variance between training and test domain. Alternatively, color augmentation can be applied during training leading to a more robust model without the extra step of color normalization at test time. We propose a novel color augmentation technique, HistAuGAN, that can simulate a wide variety of realistic histology stain colors, thus making neural networks stain-invariant when applied during training. Based on a generative adversarial network (GAN) for image-to-image translation, our model disentangles the content of the image, i.e., the morphological tissue structure, from the stain color attributes. It can be trained on multiple domains and, therefore, learns to cover different stain colors as well as other domain-specific variations introduced in the slide preparation and imaging process. We demonstrate that HistAuGAN outperforms conventional color augmentation techniques on a classification task on the publicly available dataset Camelyon17 and show that it is able to mitigate present batch effects.
Semantic Image Search for Robotic Applications
Apr 02, 2020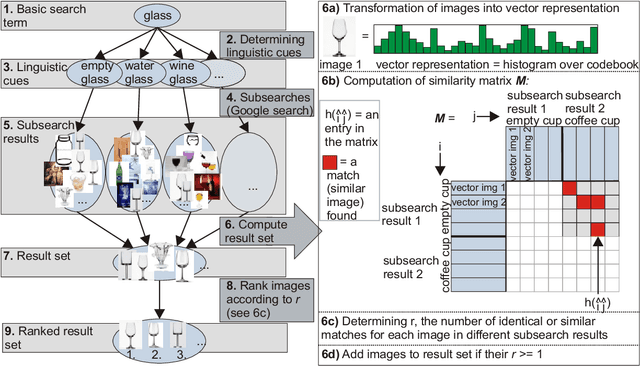
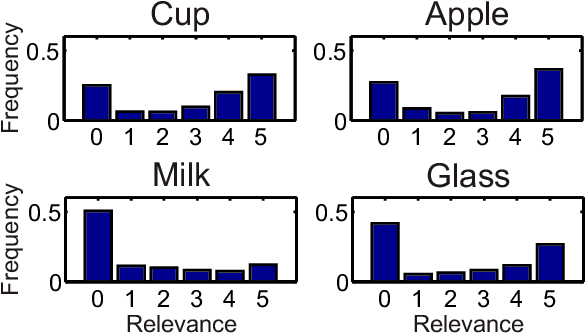
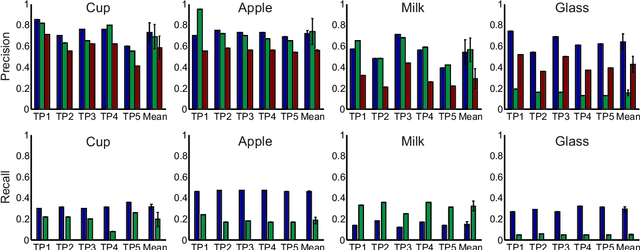

Generalization in robotics is one of the most important problems. New generalization approaches use internet databases in order to solve new tasks. Modern search engines can return a large amount of information according to a query within milliseconds. However, not all of the returned information is task relevant, partly due to the problem of polysemes. Here we specifically address the problem of object generalization by using image search. We suggest a bi-modal solution, combining visual and textual information, based on the observation that humans use additional linguistic cues to demarcate intended word meaning. We evaluate the quality of our approach by comparing it to human labelled data and find that, on average, our approach leads to improved results in comparison to Google searches, and that it can treat the problem of polysemes.
Spectral unmixing of Raman microscopic images of single human cells using Independent Component Analysis
Oct 25, 2021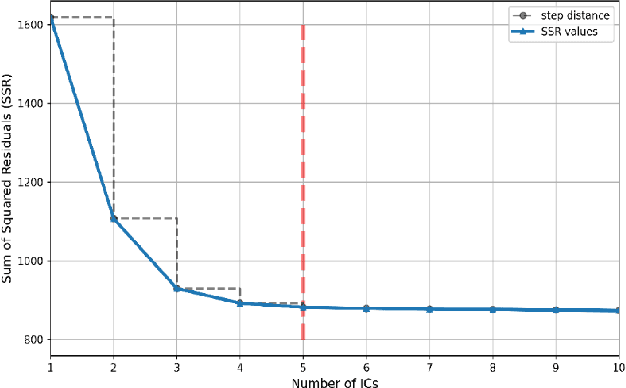
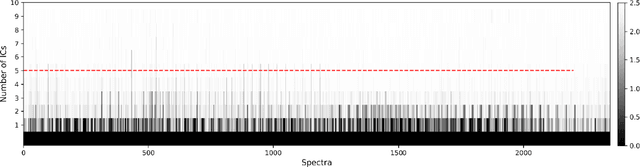
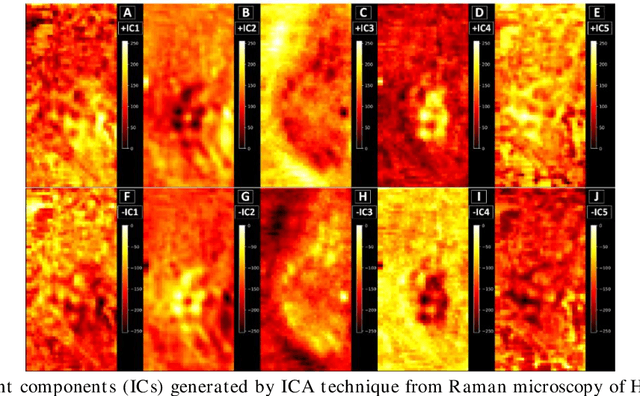
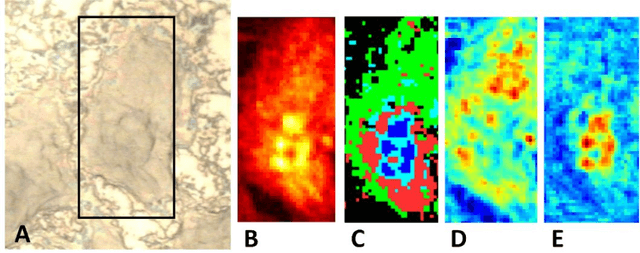
Application of independent component analysis (ICA) as an unmixing and image clustering technique for high spatial resolution Raman maps is reported. A hyperspectral map of a fixed human cell was collected by a Raman micro spectrometer in a raster pattern on a 0.5um grid. Unlike previously used unsupervised machine learning techniques such as principal component analysis, ICA is based on non-Gaussianity and statistical independence of data which is the case for mixture Raman spectra. Hence, ICA is a great candidate for assembling pseudo-colour maps from the spectral hypercube of Raman spectra. Our experimental results revealed that ICA is capable of reconstructing false colour maps of Raman hyperspectral data of human cells, showing the nuclear region constituents as well as subcellular organelle in the cytoplasm and distribution of mitochondria in the perinuclear region. Minimum preprocessing requirements and label-free nature of the ICA method make it a great unmixed method for extraction of endmembers in Raman hyperspectral maps of living cells.
Single Image Deraining: From Model-Based to Data-Driven and Beyond
Dec 27, 2019

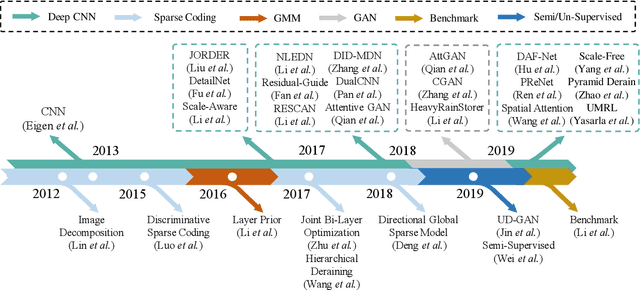
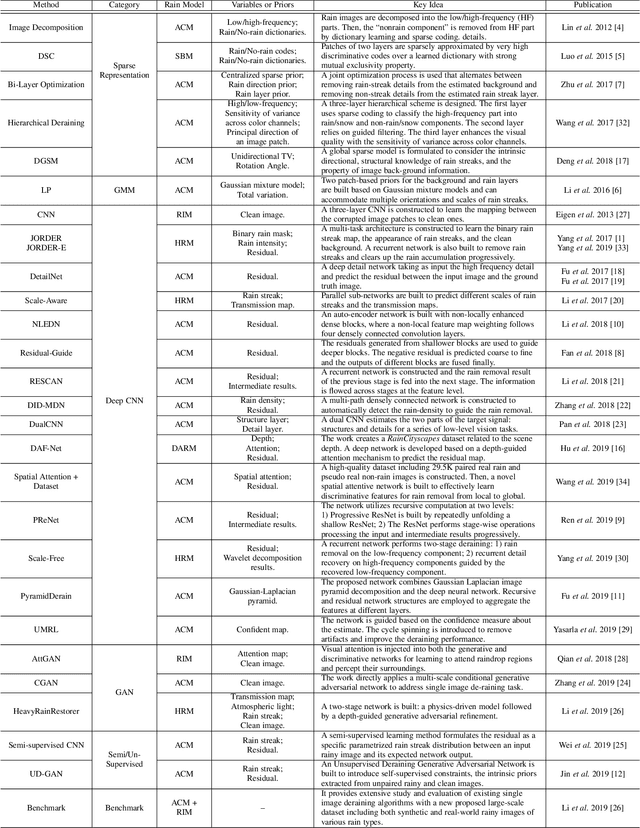
The goal of single-image deraining is to restore the rain-free background scenes of an image degraded by rain streaks and rain accumulation. The early single-image deraining methods employ a cost function, where various priors are developed to represent the properties of rain and background layers. Since 2017, single-image deraining methods step into a deep-learning era, and exploit various types of networks, i.e. convolutional neural networks, recurrent neural networks, generative adversarial networks, etc., demonstrating impressive performance. Given the current rapid development, in this paper, we provide a comprehensive survey of deraining methods over the last decade. We summarize the rain appearance models, and discuss two categories of deraining approaches: model-based and data-driven approaches. For the former, we organize the literature based on their basic models and priors. For the latter, we discuss developed ideas related to architectures, constraints, loss functions, and training datasets. We present milestones of single-image deraining methods, review a broad selection of previous works in different categories, and provide insights on the historical development route from the model-based to data-driven methods. We also summarize performance comparisons quantitatively and qualitatively. Beyond discussing the technicality of deraining methods, we also discuss the future directions.
Deep Clustering for Mars Rover image datasets
Nov 12, 2019In this paper, we build autoencoders to learn a latent space from unlabeled image datasets obtained from the Mars rover. Then, once the latent feature space has been learnt, we use k-means to cluster the data. We test the performance of the algorithm on a smaller labeled dataset, and report good accuracy and concordance with the ground truth labels. This is the first attempt to use deep learning based unsupervised algorithms to cluster Mars Rover images. This algorithm can be used to augment human annotations for such datasets (which are time consuming) and speed up the generation of ground truth labels for Mars Rover image data, and potentially other planetary and space images.