 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMathesis: Towards Formal Theorem Proving from Natural Languages
Jun 08, 2025



Recent advances in large language models show strong promise for formal reasoning. However, most LLM-based theorem provers have long been constrained by the need for expert-written formal statements as inputs, limiting their applicability to real-world problems expressed in natural language. We tackle this gap with Mathesis, the first end-to-end theorem proving pipeline processing informal problem statements. It contributes Mathesis-Autoformalizer, the first autoformalizer using reinforcement learning to enhance the formalization ability of natural language problems, aided by our novel LeanScorer framework for nuanced formalization quality assessment. It also proposes a Mathesis-Prover, which generates formal proofs from the formalized statements. To evaluate the real-world applicability of end-to-end formal theorem proving, we introduce Gaokao-Formal, a benchmark of 488 complex problems from China's national college entrance exam. Our approach is carefully designed, with a thorough study of each component. Experiments demonstrate Mathesis's effectiveness, with the autoformalizer outperforming the best baseline by 22% in pass-rate on Gaokao-Formal. The full system surpasses other model combinations, achieving 64% accuracy on MiniF2F with pass@32 and a state-of-the-art 18% on Gaokao-Formal.
APOLLO: Automated LLM and Lean Collaboration for Advanced Formal Reasoning
May 09, 2025



Formal reasoning and automated theorem proving constitute a challenging subfield of machine learning, in which machines are tasked with proving mathematical theorems using formal languages like Lean. A formal verification system can check whether a formal proof is correct or not almost instantaneously, but generating a completely correct formal proof with large language models (LLMs) remains a formidable task. The usual approach in the literature is to prompt the LLM many times (up to several thousands) until one of the generated proofs passes the verification system. In this work, we present APOLLO (Automated PrOof repair via LLM and Lean cOllaboration), a modular, model-agnostic pipeline that combines the strengths of the Lean compiler with an LLM's reasoning abilities to achieve better proof-generation results at a low sampling budget. Apollo directs a fully automated process in which the LLM generates proofs for theorems, a set of agents analyze the proofs, fix the syntax errors, identify the mistakes in the proofs using Lean, isolate failing sub-lemmas, utilize automated solvers, and invoke an LLM on each remaining goal with a low top-K budget. The repaired sub-proofs are recombined and reverified, iterating up to a user-controlled maximum number of attempts. On the miniF2F benchmark, we establish a new state-of-the-art accuracy of 75.0% among 7B-parameter models while keeping the sampling budget below one thousand. Moreover, Apollo raises the state-of-the-art accuracy for Goedel-Prover-SFT to 65.6% while cutting sample complexity from 25,600 to a few hundred. General-purpose models (o3-mini, o4-mini) jump from 3-7% to over 40% accuracy. Our results demonstrate that targeted, compiler-guided repair of LLM outputs yields dramatic gains in both efficiency and correctness, suggesting a general paradigm for scalable automated theorem proving.
A Lean Dataset for International Math Olympiad: Small Steps towards Writing Math Proofs for Hard Problems
Nov 28, 2024Using AI to write formal proofs for mathematical problems is a challenging task that has seen some advancements in recent years. Automated systems such as Lean can verify the correctness of proofs written in formal language, yet writing the proofs in formal language can be challenging for humans and machines. The miniF2F benchmark has 20 IMO problems in its testing set, yet formal proofs are available only for 7 of these problems (3 of which are written only by mathematicians). The model with best accuracy can only prove 4 of these 20 IMO problems, from 1950s and 60s, while its training set is a secret. In this work, we write complete, original formal proofs for the remaining 13 IMO problems in Lean along with 3 extra problems from IMO 2022 and 2023. This effort expands the availability of proof currently in the public domain by creating 5,150 lines of Lean proof. The goal of the paper is to pave the way for developing AI models that can automatically write the formal proofs for all the IMO problems in miniF2F and beyond. In this pursuit, we devise a method to decompose the proof of these problems into their building blocks, constructing a dataset of about 900 lemmas with 25,500 lines of Lean code. These lemmas are not trivial, yet they are approachable, providing the opportunity to evaluate and diagnose the failures and successes of AI models. We then evaluate the ability of GPT-4 in writing formal proofs for these lemmas with zero shot prompting, CoT reasoning and lemma retrieval. In evaluating the responses, we also analyze the confounding factor of LLM's ability to write the proofs in natural language vs Lean language.
An Ambiguity Measure for Recognizing the Unknowns in Deep Learning
Dec 11, 2023



We study the understanding of deep neural networks from the scope in which they are trained on. While the accuracy of these models is usually impressive on the aggregate level, they still make mistakes, sometimes on cases that appear to be trivial. Moreover, these models are not reliable in realizing what they do not know leading to failures such as adversarial vulnerability and out-of-distribution failures. Here, we propose a measure for quantifying the ambiguity of inputs for any given model with regard to the scope of its training. We define the ambiguity based on the geometric arrangements of the decision boundaries and the convex hull of training set in the feature space learned by the trained model, and demonstrate that a single ambiguity measure may detect a considerable portion of mistakes of a model on in-distribution samples, adversarial inputs, as well as out-of-distribution inputs. Using our ambiguity measure, a model may abstain from classification when it encounters ambiguous inputs leading to a better model accuracy not just on a given testing set, but on the inputs it may encounter at the world at large. In pursuit of this measure, we develop a theoretical framework that can identify the unknowns of the model in relation to its scope. We put this in perspective with the confidence of the model and develop formulations to identify the regions of the domain which are unknown to the model, yet the model is guaranteed to have high confidence.
Large Language Models' Understanding of Math: Source Criticism and Extrapolation
Nov 12, 2023It has been suggested that large language models such as GPT-4 have acquired some form of understanding beyond the correlations among the words in text including some understanding of mathematics as well. Here, we perform a critical inquiry into this claim by evaluating the mathematical understanding of the GPT-4 model. Considering that GPT-4's training set is a secret, it is not straightforward to evaluate whether the model's correct answers are based on a mathematical understanding or based on replication of proofs that the model has seen before. We specifically craft mathematical questions which their formal proofs are not readily available on the web, proofs that are more likely not seen by the GPT-4. We see that GPT-4 is unable to solve those problems despite their simplicity. It is hard to find scientific evidence suggesting that GPT-4 has acquired an understanding of even basic mathematical concepts. A straightforward way to find failure modes of GPT-4 in theorem proving is to craft questions where their formal proofs are not available on the web. Our finding suggests that GPT-4's ability is to reproduce, rephrase, and polish the mathematical proofs that it has seen before, and not in grasping mathematical concepts. We also see that GPT-4's ability to prove mathematical theorems is continuously expanding over time despite the claim that it is a fixed model. We suggest that the task of proving mathematical theorems in formal language is comparable to the methods used in search engines such as Google while predicting the next word in a sentence may be a misguided approach, a recipe that often leads to excessive extrapolation and eventual failures. Prompting the GPT-4 over and over may benefit the GPT-4 and the OpenAI, but we question whether it is valuable for machine learning or for theorem proving.
Should Machine Learning Models Report to Us When They Are Clueless?
Mar 23, 2022The right to AI explainability has consolidated as a consensus in the research community and policy-making. However, a key component of explainability has been missing: extrapolation, which describes the extent to which AI models can be clueless when they encounter unfamiliar samples (i.e., samples outside a convex hull of their training sets, as we will explain down below). We report that AI models extrapolate outside their range of familiar data, frequently and without notifying the users and stakeholders. Knowing whether a model has extrapolated or not is a fundamental insight that should be included in explaining AI models in favor of transparency and accountability. Instead of dwelling on the negatives, we offer ways to clear the roadblocks in promoting AI transparency. Our analysis commentary accompanying practical clauses useful to include in AI regulations such as the National AI Initiative Act in the US and the AI Act by the European Commission.
Over-parameterization: A Necessary Condition for Models that Extrapolate
Mar 20, 2022In this work, we study over-parameterization as a necessary condition for having the ability for the models to extrapolate outside the convex hull of training set. We specifically, consider classification models, e.g., image classification and other applications of deep learning. Such models are classification functions that partition their domain and assign a class to each partition \cite{strang2019linear}. Partitions are defined by decision boundaries and so is the classification model/function. Convex hull of training set may occupy only a subset of the domain, but trained model may partition the entire domain and not just the convex hull of training set. This is important because many of the testing samples may be outside the convex hull of training set and the way in which a model partitions its domain outside the convex hull would be influential in its generalization. Using approximation theory, we prove that over-parameterization is a necessary condition for having control over the partitioning of the domain outside the convex hull of training set. We also propose a more clear definition for the notion of over-parametrization based on the learning task and the training set at hand. We present empirical evidence about geometry of datasets, both image and non-image, to provide insights about the extent of extrapolation performed by the models. We consider a 64-dimensional feature space learned by a ResNet model and investigate the geometric arrangements of convex hulls and decision boundaries in that space. We also formalize the notion of extrapolation and relate it to the scope of the model. Finally, we review the rich extrapolation literature in pure and applied mathematics, e.g., the Whitney's Extension Problem, and place our theory in that context.
Deep Learning Generalization, Extrapolation, and Over-parameterization
Mar 19, 2022We study the generalization of over-parameterized deep networks (for image classification) in relation to the convex hull of their training sets. Despite their great success, generalization of deep networks is considered a mystery. These models have orders of magnitude more parameters than their training samples, and they can achieve perfect accuracy on their training sets, even when training images are randomly labeled, or the contents of images are replaced with random noise. The training loss function of these models has infinite number of near zero minimizers, where only a small subset of those minimizers generalize well. Overall, it is not clear why models need to be over-parameterized, why we should use a very specific training regime to train them, and why their classifications are so susceptible to imperceivable adversarial perturbations (phenomenon known as adversarial vulnerability) \cite{papernot2016limitations,shafahi2018adversarial,tsipras2018robustness}. Some recent studies have made advances in answering these questions, however, they only consider interpolation. We show that interpolation is not adequate to understand generalization of deep networks and we should broaden our perspective.
Decision boundaries and convex hulls in the feature space that deep learning functions learn from images
Feb 17, 2022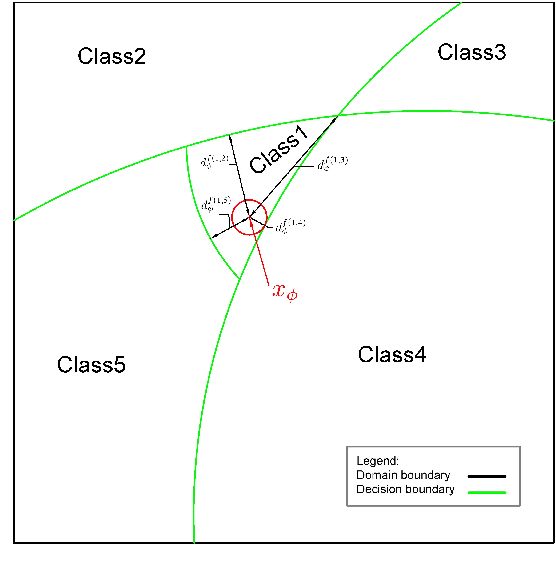
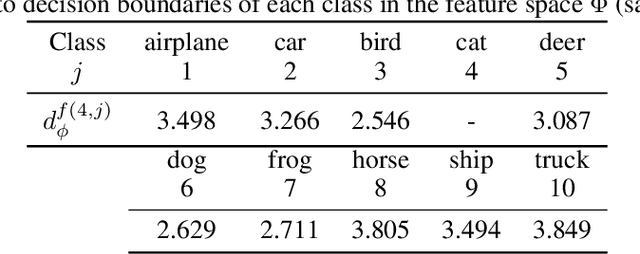
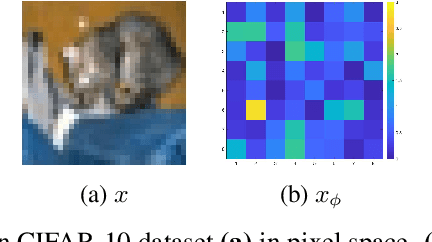
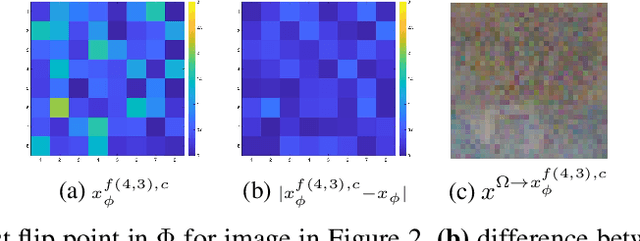
The success of deep neural networks in image classification and learning can be partly attributed to the features they extract from images. It is often speculated about the properties of a low-dimensional manifold that models extract and learn from images. However, there is not sufficient understanding about this low-dimensional space based on theory or empirical evidence. For image classification models, their last hidden layer is the one where images of each class is separated from other classes and it also has the least number of features. Here, we develop methods and formulations to study that feature space for any model. We study the partitioning of the domain in feature space, identify regions guaranteed to have certain classifications, and investigate its implications for the pixel space. We observe that geometric arrangements of decision boundaries in feature space is significantly different compared to pixel space, providing insights about adversarial vulnerabilities, image morphing, extrapolation, ambiguity in classification, and the mathematical understanding of image classification models.
To what extent should we trust AI models when they extrapolate?
Jan 27, 2022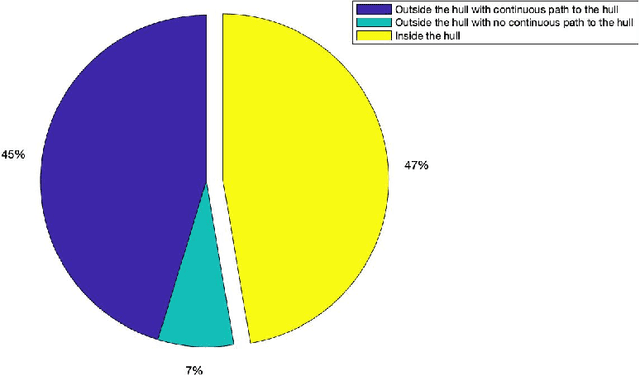
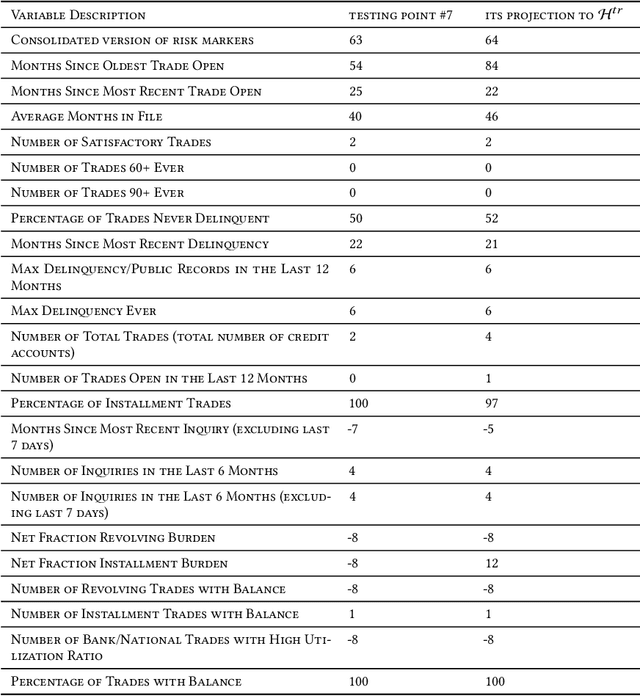
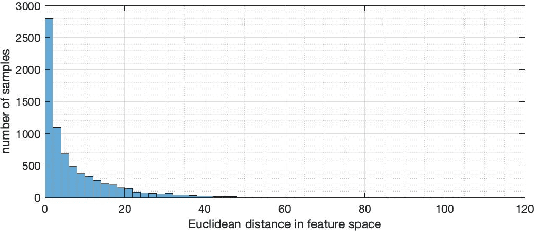
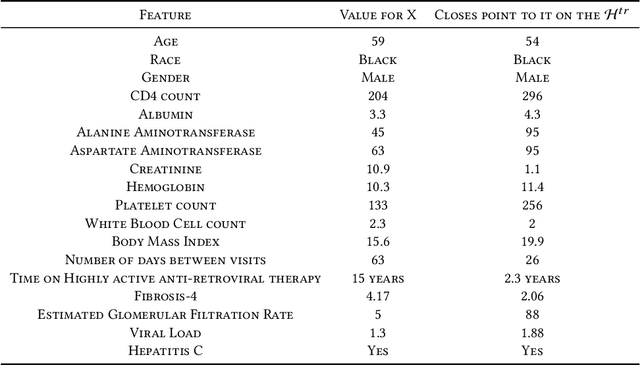
Many applications affecting human lives rely on models that have come to be known under the umbrella of machine learning and artificial intelligence. These AI models are usually complicated mathematical functions that map from an input space to an output space. Stakeholders are interested to know the rationales behind models' decisions and functional behavior. We study this functional behavior in relation to the data used to create the models. On this topic, scholars have often assumed that models do not extrapolate, i.e., they learn from their training samples and process new input by interpolation. This assumption is questionable: we show that models extrapolate frequently; the extent of extrapolation varies and can be socially consequential. We demonstrate that extrapolation happens for a substantial portion of datasets more than one would consider reasonable. How can we trust models if we do not know whether they are extrapolating? Given a model trained to recommend clinical procedures for patients, can we trust the recommendation when the model considers a patient older or younger than all the samples in the training set? If the training set is mostly Whites, to what extent can we trust its recommendations about Black and Hispanic patients? Which dimension (race, gender, or age) does extrapolation happen? Even if a model is trained on people of all races, it still may extrapolate in significant ways related to race. The leading question is, to what extent can we trust AI models when they process inputs that fall outside their training set? This paper investigates several social applications of AI, showing how models extrapolate without notice. We also look at different sub-spaces of extrapolation for specific individuals subject to AI models and report how these extrapolations can be interpreted, not mathematically, but from a humanistic point of view.