 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Unlearning for Causal Inference
Aug 24, 2023Machine learning models play a vital role in making predictions and deriving insights from data and are being increasingly used for causal inference. To preserve user privacy, it is important to enable the model to forget some of its learning/captured information about a given user (machine unlearning). This paper introduces the concept of machine unlearning for causal inference, particularly propensity score matching and treatment effect estimation, which aims to refine and improve the performance of machine learning models for causal analysis given the above unlearning requirements. The paper presents a methodology for machine unlearning using a neural network-based propensity score model. The dataset used in the study is the Lalonde dataset, a widely used dataset for evaluating the effectiveness i.e. the treatment effect of job training programs. The methodology involves training an initial propensity score model on the original dataset and then creating forget sets by selectively removing instances, as well as matched instance pairs. based on propensity score matching. These forget sets are used to evaluate the retrained model, allowing for the elimination of unwanted associations. The actual retraining of the model is performed using the retain set. The experimental results demonstrate the effectiveness of the machine unlearning approach. The distribution and histogram analysis of propensity scores before and after unlearning provide insights into the impact of the unlearning process on the data. This study represents the first attempt to apply machine unlearning techniques to causal inference.
Weather event severity prediction using buoy data and machine learning
Nov 17, 2019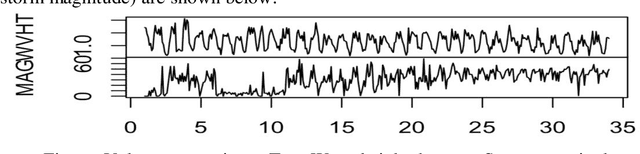
In this paper, we predict severity of extreme weather events (tropical storms, hurricanes, etc.) using buoy data time series variables such as wind speed and air temperature. The prediction/forecasting method is based on various forecasting and machine learning models. The following steps are used. Data sources for the buoys and weather events are identified, aggregated and merged. For missing data imputation, we use Kalman filters as well as splines for multivariate time series. Then, statistical tests are run to ascertain increasing trends in weather event severity. Next, we use machine learning to predict/forecast event severity using buoy variables, and report good accuracies for the models built.
Deep Clustering for Mars Rover image datasets
Nov 12, 2019In this paper, we build autoencoders to learn a latent space from unlabeled image datasets obtained from the Mars rover. Then, once the latent feature space has been learnt, we use k-means to cluster the data. We test the performance of the algorithm on a smaller labeled dataset, and report good accuracy and concordance with the ground truth labels. This is the first attempt to use deep learning based unsupervised algorithms to cluster Mars Rover images. This algorithm can be used to augment human annotations for such datasets (which are time consuming) and speed up the generation of ground truth labels for Mars Rover image data, and potentially other planetary and space images.
Causal inference for climate change events from satellite image time series using computer vision and deep learning
Oct 25, 2019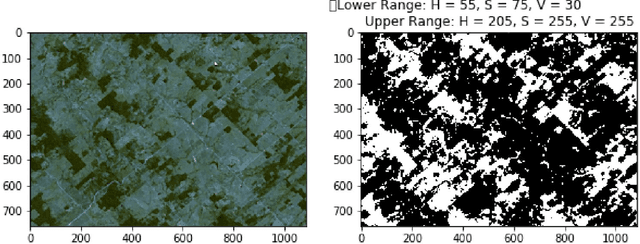
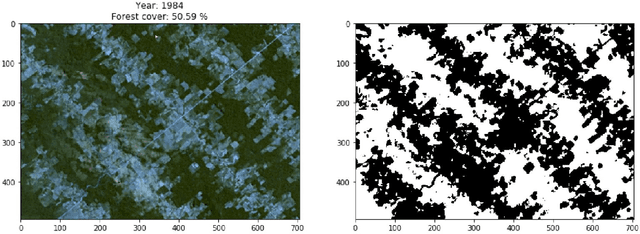
We propose a method for causal inference using satellite image time series, in order to determine the treatment effects of interventions which impact climate change, such as deforestation. Simply put, the aim is to quantify the 'before versus after' effect of climate related human driven interventions, such as urbanization; as well as natural disasters, such as hurricanes and forest fires. As a concrete example, we focus on quantifying forest tree cover change/ deforestation due to human led causes. The proposed method involves the following steps. First, we uae computer vision and machine learning/deep learning techniques to detect and quantify forest tree coverage levels over time, at every time epoch. We then look at this time series to identify changepoints. Next, we estimate the expected (forest tree cover) values using a Bayesian structural causal model and projecting/forecasting the counterfactual. This is compared to the values actually observed post intervention, and the difference in the two values gives us the effect of the intervention (as compared to the non intervention scenario, i.e. what would have possibly happened without the intervention). As a specific use case, we analyze deforestation levels before and after the hyperinflation event (intervention) in Brazil (which ended in 1993-94), for the Amazon rainforest region, around Rondonia, Brazil. For this deforestation use case, using our causal inference framework can help causally attribute change/reduction in forest tree cover and increasing deforestation rates due to human activities at various points in time.
Deep Learning for Causal Inference
Mar 01, 2018In this paper, we propose deep learning techniques for econometrics, specifically for causal inference and for estimating individual as well as average treatment effects. The contribution of this paper is twofold: 1. For generalized neighbor matching to estimate individual and average treatment effects, we analyze the use of autoencoders for dimensionality reduction while maintaining the local neighborhood structure among the data points in the embedding space. This deep learning based technique is shown to perform better than simple k nearest neighbor matching for estimating treatment effects, especially when the data points have several features/covariates but reside in a low dimensional manifold in high dimensional space. We also observe better performance than manifold learning methods for neighbor matching. 2. Propensity score matching is one specific and popular way to perform matching in order to estimate average and individual treatment effects. We propose the use of deep neural networks (DNNs) for propensity score matching, and present a network called PropensityNet for this. This is a generalization of the logistic regression technique traditionally used to estimate propensity scores and we show empirically that DNNs perform better than logistic regression at propensity score matching. Code for both methods will be made available shortly on Github at: https://github.com/vikas84bf