 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fight Detection from Still Images in the Wild
Nov 17, 2021
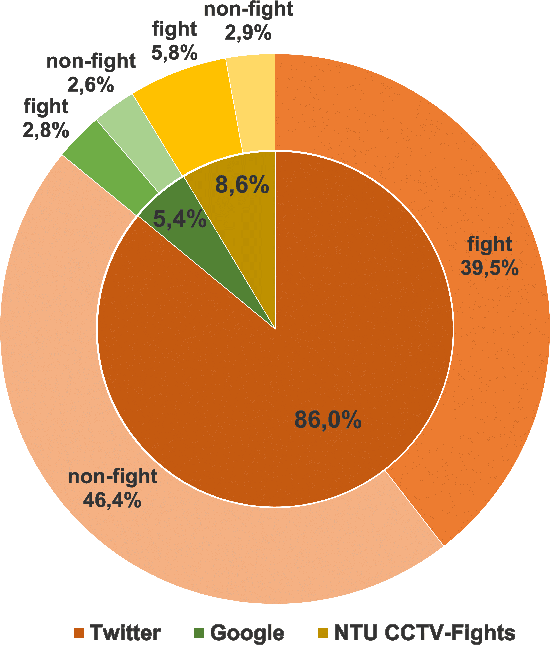
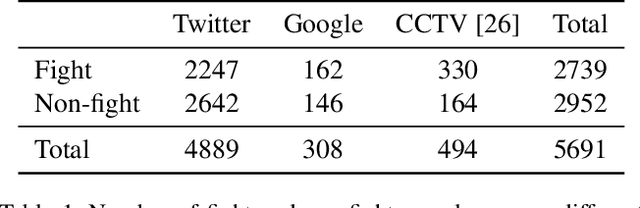
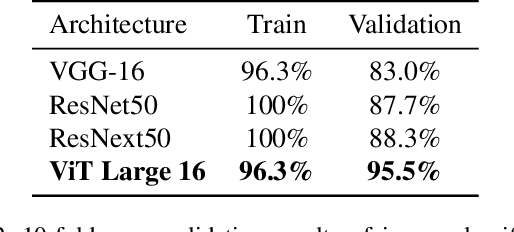

Detecting fights from still images shared on social media is an important task required to limit the distribution of violent scenes in order to prevent their negative effects. For this reason, in this study, we address the problem of fight detection from still images collected from the web and social media. We explore how well one can detect fights from just a single still image. We also propose a new dataset, named Social Media Fight Images (SMFI), comprising real-world images of fight actions. Results of the extensive experiments on the proposed dataset show that fight actions can be recognized successfully from still images. That is, even without exploiting the temporal information, it is possible to detect fights with high accuracy by utilizing appearance only. We also perform cross-dataset experiments to evaluate the representation capacity of the collected dataset. These experiments indicate that, as in the other computer vision problems, there exists a dataset bias for the fight recognition problem. Although the methods achieve close to 100% accuracy when trained and tested on the same fight dataset, the cross-dataset accuracies are significantly lower, i.e., around 70% when more representative datasets are used for training. SMFI dataset is found to be one of the two most representative datasets among the utilized five fight datasets.
Label Consistent Transform Learning for Hyperspectral Image Classification
Dec 11, 2019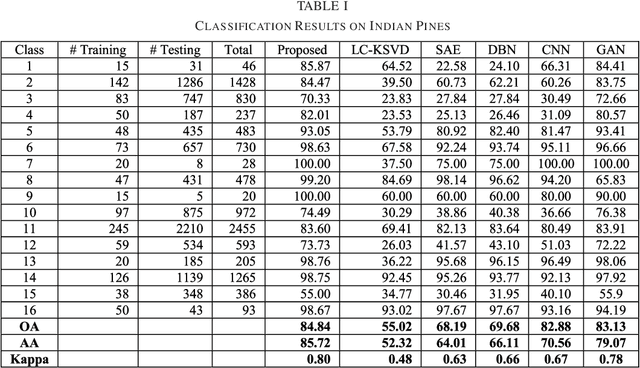
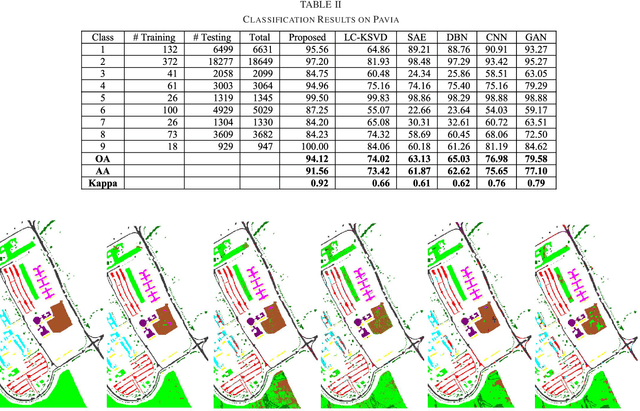
This work proposes a new image analysis tool called Label Consistent Transform Learning (LCTL). Transform learning is a recent unsupervised representation learning approach; we add supervision by incorporating a label consistency constraint. The proposed technique is especially suited for hyper-spectral image classification problems owing to its ability to learn from fewer samples. We have compared our proposed method on state-of-the-art techniques like label consistent KSVD, Stacked Autoencoder, Deep Belief Network and Convolutional Neural Network. Our method yields considerably better results (more than 0.1 improvement in Kappa coefficient) than all the aforesaid techniques.
Authentication Attacks on Projection-based Cancelable Biometric Schemes
Oct 28, 2021
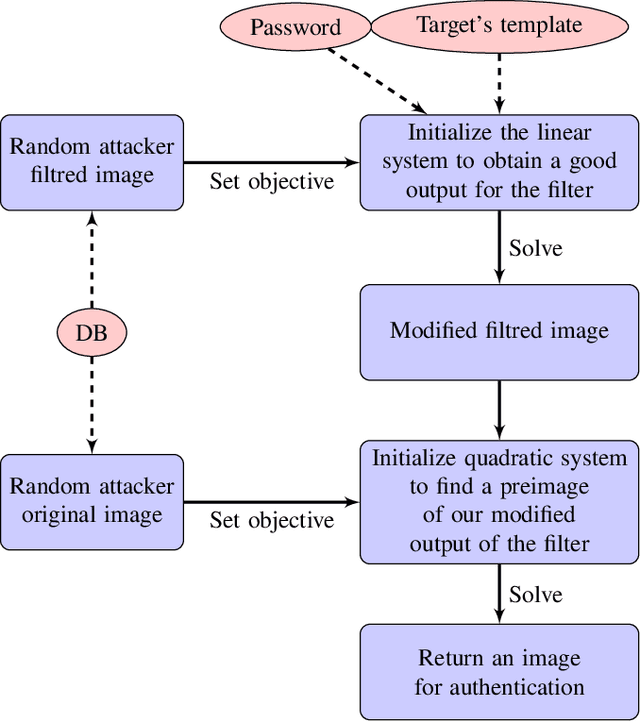
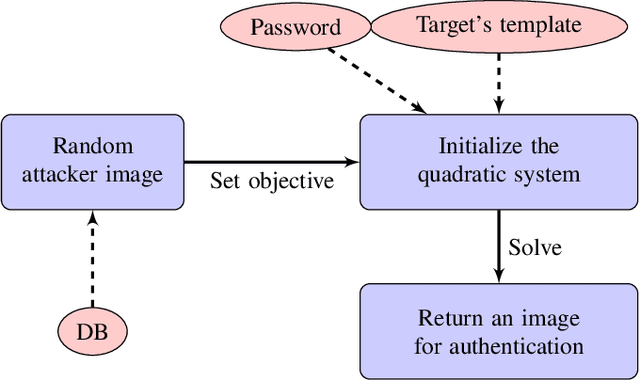
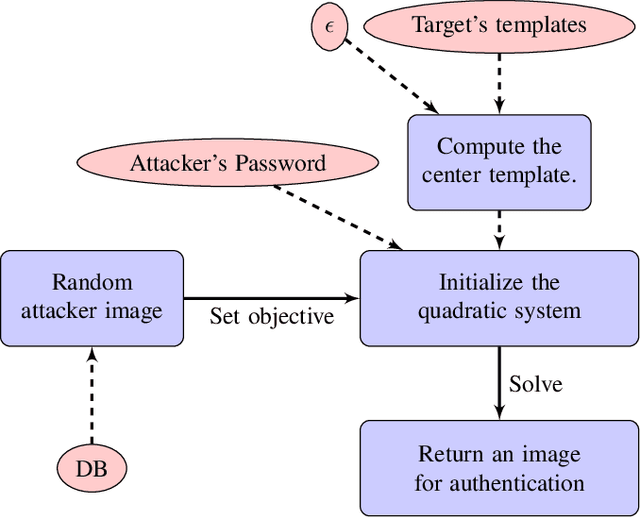
Cancelable biometric schemes aim at generating secure biometric templates by combining user specific tokens, such as password, stored secret or salt, along with biometric data. This type of transformation is constructed as a composition of a biometric transformation with a feature extraction algorithm. The security requirements of cancelable biometric schemes concern the irreversibility, unlinkability and revocability of templates, without losing in accuracy of comparison. While several schemes were recently attacked regarding these requirements, full reversibility of such a composition in order to produce colliding biometric characteristics, and specifically presentation attacks, were never demonstrated to the best of our knowledge. In this paper, we formalize these attacks for a traditional cancelable scheme with the help of integer linear programming (ILP) and quadratically constrained quadratic programming (QCQP). Solving these optimization problems allows an adversary to slightly alter its fingerprint image in order to impersonate any individual. Moreover, in an even more severe scenario, it is possible to simultaneously impersonate several individuals.
F-CAM: Full Resolution CAM via Guided Parametric Upscaling
Sep 15, 2021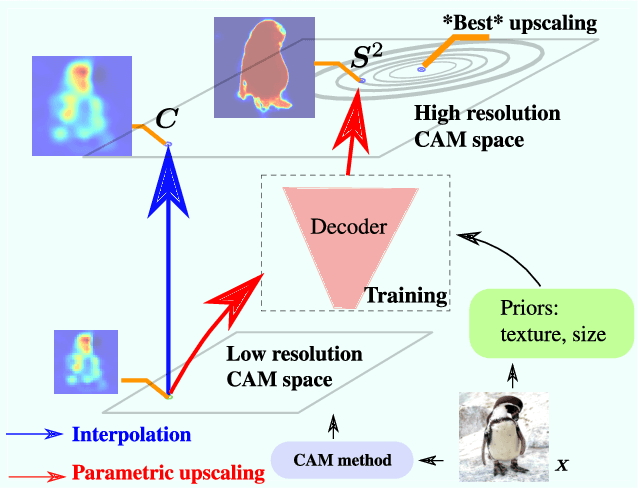
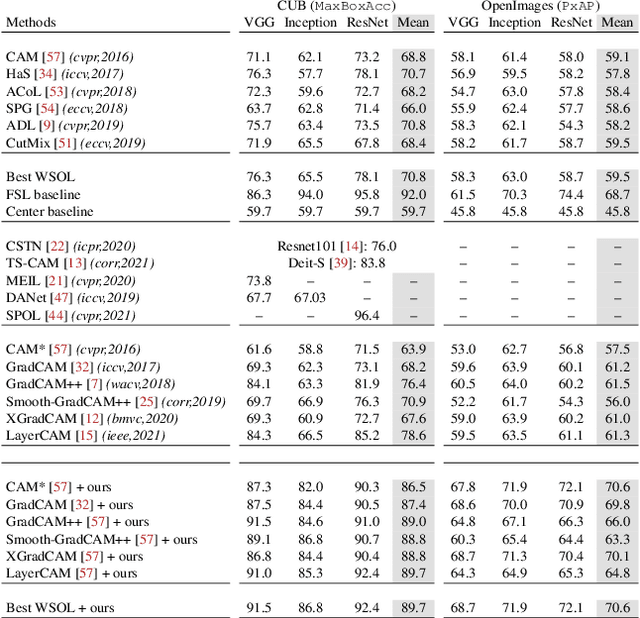
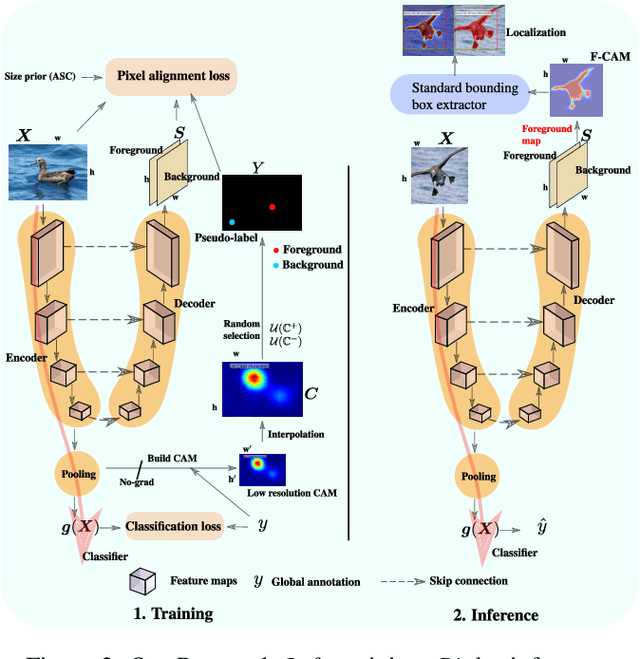
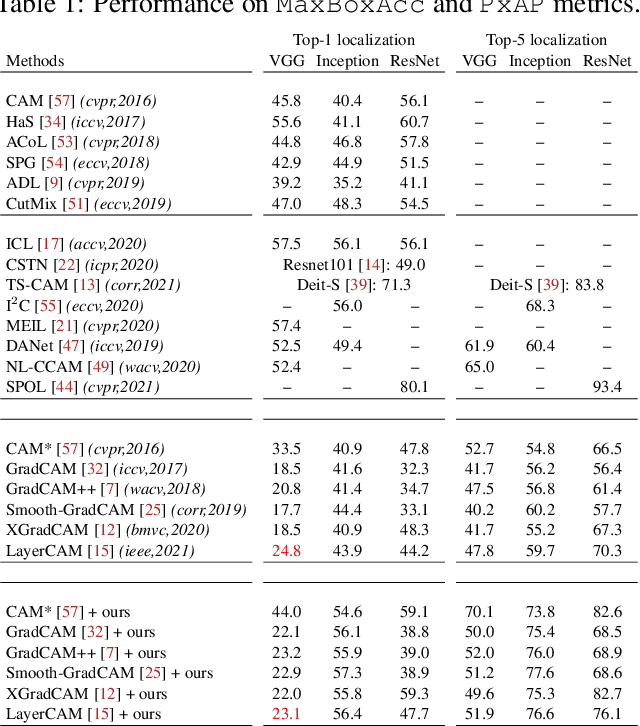
Class Activation Mapping (CAM) methods have recently gained much attention for weakly-supervised object localization (WSOL) tasks, allowing for CNN visualization and interpretation without training on fully annotated image datasets. CAM methods are typically integrated within off-the-shelf CNN backbones, such as ResNet50. Due to convolution and downsampling/pooling operations, these backbones yield low resolution CAMs with a down-scaling factor of up to 32, making accurate localization more difficult. Interpolation is required to restore a full size CAMs, but without considering the statistical properties of the objects, leading to activations with inconsistent boundaries and inaccurate localizations. As an alternative, we introduce a generic method for parametric upscaling of CAMs that allows constructing accurate full resolution CAMs (F-CAMs). In particular, we propose a trainable decoding architecture that can be connected to any CNN classifier to produce more accurate CAMs. Given an original (low resolution) CAM, foreground and background pixels are randomly sampled for fine-tuning the decoder. Additional priors such as image statistics, and size constraints are also considered to expand and refine object boundaries. Extensive experiments using three CNN backbones and six WSOL baselines on the CUB-200-2011 and OpenImages datasets, indicate that our F-CAM method yields a significant improvement in CAM localization accuracy. F-CAM performance is competitive with state-of-art WSOL methods, yet it requires fewer computational resources during inference.
Adversarial Examples on Segmentation Models Can be Easy to Transfer
Nov 22, 2021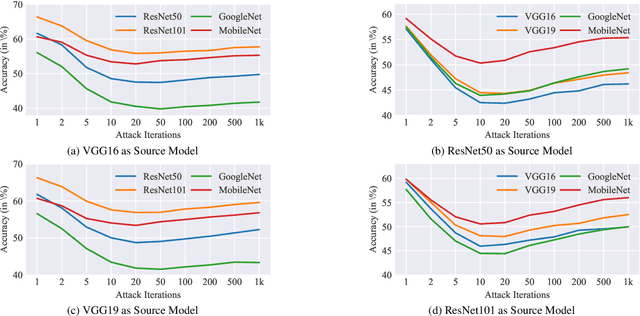
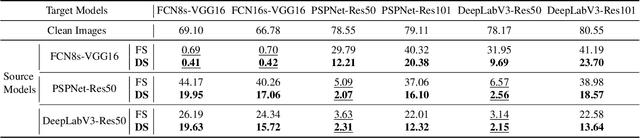
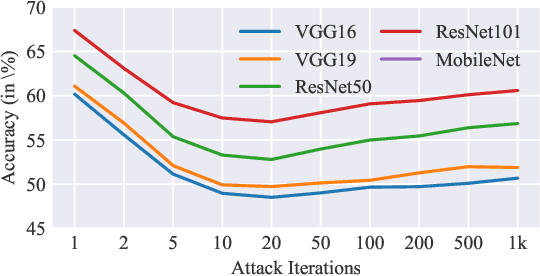
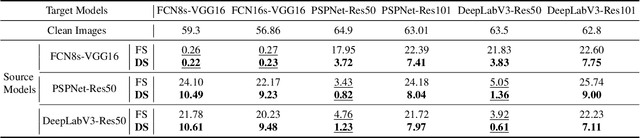
Deep neural network-based image classification can be misled by adversarial examples with small and quasi-imperceptible perturbations. Furthermore, the adversarial examples created on one classification model can also fool another different model. The transferability of the adversarial examples has recently attracted a growing interest since it makes black-box attacks on classification models feasible. As an extension of classification, semantic segmentation has also received much attention towards its adversarial robustness. However, the transferability of adversarial examples on segmentation models has not been systematically studied. In this work, we intensively study this topic. First, we explore the overfitting phenomenon of adversarial examples on classification and segmentation models. In contrast to the observation made on classification models that the transferability is limited by overfitting to the source model, we find that the adversarial examples on segmentations do not always overfit the source models. Even when no overfitting is presented, the transferability of adversarial examples is limited. We attribute the limitation to the architectural traits of segmentation models, i.e., multi-scale object recognition. Then, we propose a simple and effective method, dubbed dynamic scaling, to overcome the limitation. The high transferability achieved by our method shows that, in contrast to the observations in previous work, adversarial examples on a segmentation model can be easy to transfer to other segmentation models. Our analysis and proposals are supported by extensive experiments.
Hybrid SNN-ANN: Energy-Efficient Classification and Object Detection for Event-Based Vision
Dec 06, 2021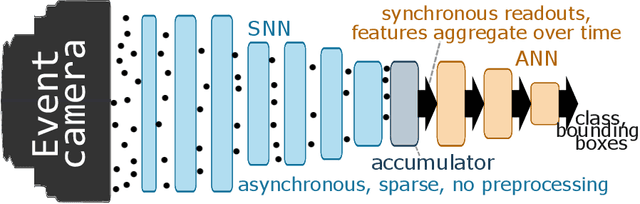
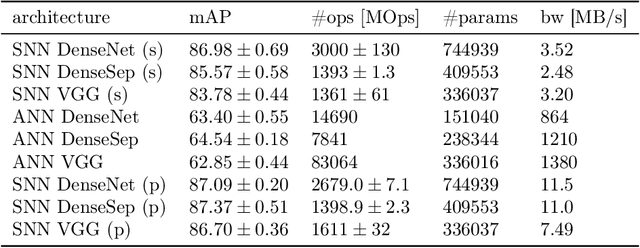
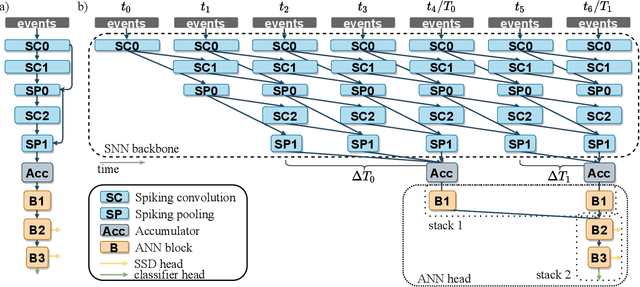
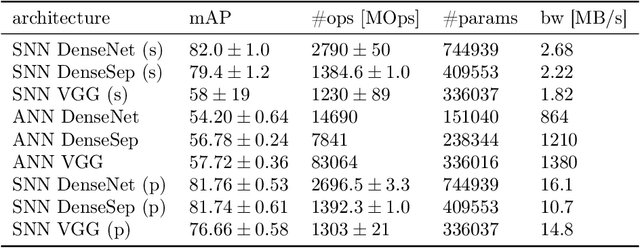
Event-based vision sensors encode local pixel-wise brightness changes in streams of events rather than image frames and yield sparse, energy-efficient encodings of scenes, in addition to low latency, high dynamic range, and lack of motion blur. Recent progress in object recognition from event-based sensors has come from conversions of deep neural networks, trained with backpropagation. However, using these approaches for event streams requires a transformation to a synchronous paradigm, which not only loses computational efficiency, but also misses opportunities to extract spatio-temporal features. In this article we propose a hybrid architecture for end-to-end training of deep neural networks for event-based pattern recognition and object detection, combining a spiking neural network (SNN) backbone for efficient event-based feature extraction, and a subsequent analog neural network (ANN) head to solve synchronous classification and detection tasks. This is achieved by combining standard backpropagation with surrogate gradient training to propagate gradients through the SNN. Hybrid SNN-ANNs can be trained without conversion, and result in highly accurate networks that are substantially more computationally efficient than their ANN counterparts. We demonstrate results on event-based classification and object detection datasets, in which only the architecture of the ANN heads need to be adapted to the tasks, and no conversion of the event-based input is necessary. Since ANNs and SNNs require different hardware paradigms to maximize their efficiency, we envision that SNN backbone and ANN head can be executed on different processing units, and thus analyze the necessary bandwidth to communicate between the two parts. Hybrid networks are promising architectures to further advance machine learning approaches for event-based vision, without having to compromise on efficiency.
MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding
Oct 16, 2021

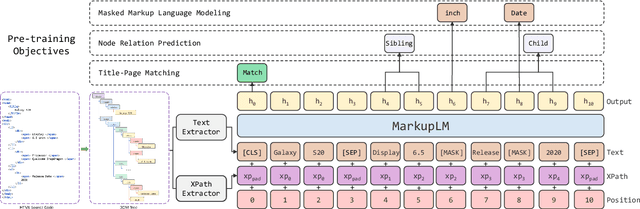
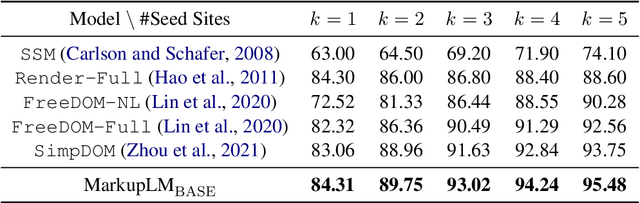
Multimodal pre-training with text, layout, and image has made significant progress for Visually-rich Document Understanding (VrDU), especially the fixed-layout documents such as scanned document images. While, there are still a large number of digital documents where the layout information is not fixed and needs to be interactively and dynamically rendered for visualization, making existing layout-based pre-training approaches not easy to apply. In this paper, we propose MarkupLM for document understanding tasks with markup languages as the backbone such as HTML/XML-based documents, where text and markup information is jointly pre-trained. Experiment results show that the pre-trained MarkupLM significantly outperforms the existing strong baseline models on several document understanding tasks. The pre-trained model and code will be publicly available at https://aka.ms/markuplm.
Improved Few-shot Segmentation by Redefinition of the Roles of Multi-level CNN Features
Sep 15, 2021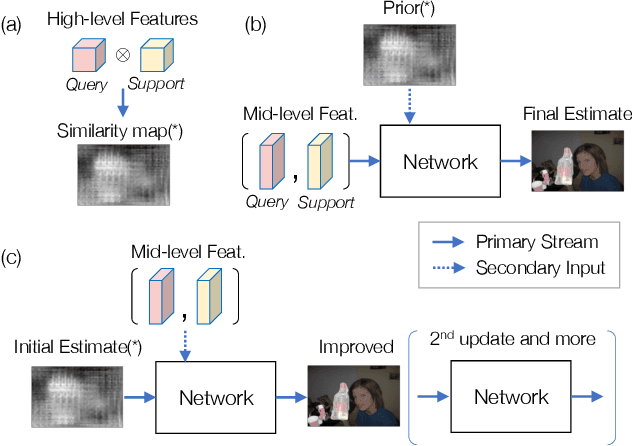

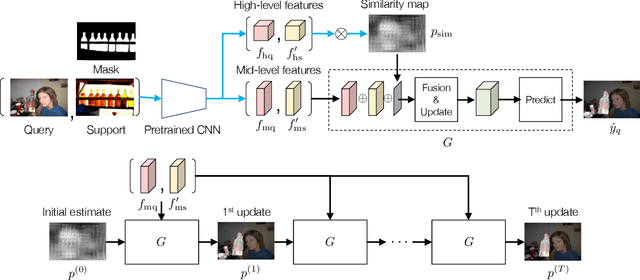
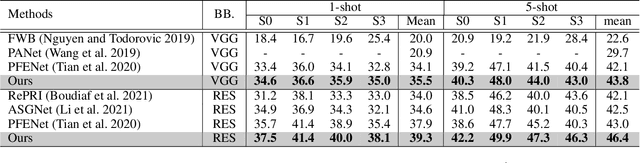
This study is concerned with few-shot segmentation, i.e., segmenting the region of an unseen object class in a query image, given support image(s) of its instances. The current methods rely on the pretrained CNN features of the support and query images. The key to good performance depends on the proper fusion of their mid-level and high-level features; the former contains shape-oriented information, while the latter has class-oriented information. Current state-of-the-art methods follow the approach of Tian et al., which gives the mid-level features the primary role and the high-level features the secondary role. In this paper, we reinterpret this widely employed approach by redifining the roles of the multi-level features; we swap the primary and secondary roles. Specifically, we regard that the current methods improve the initial estimate generated from the high-level features using the mid-level features. This reinterpretation suggests a new application of the current methods: to apply the same network multiple times to iteratively update the estimate of the object's region, starting from its initial estimate. Our experiments show that this method is effective and has updated the previous state-of-the-art on COCO-20$^i$ in the 1-shot and 5-shot settings and on PASCAL-5$^i$ in the 1-shot setting.
ESOD:Edge-based Task Scheduling for Object Detection
Oct 20, 2021

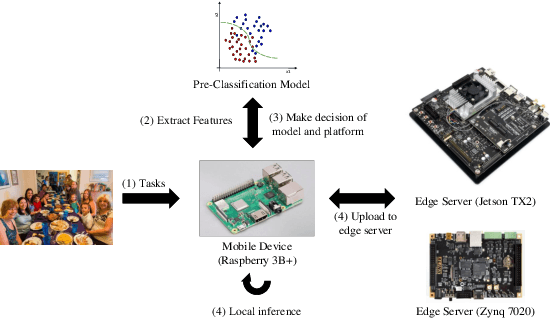
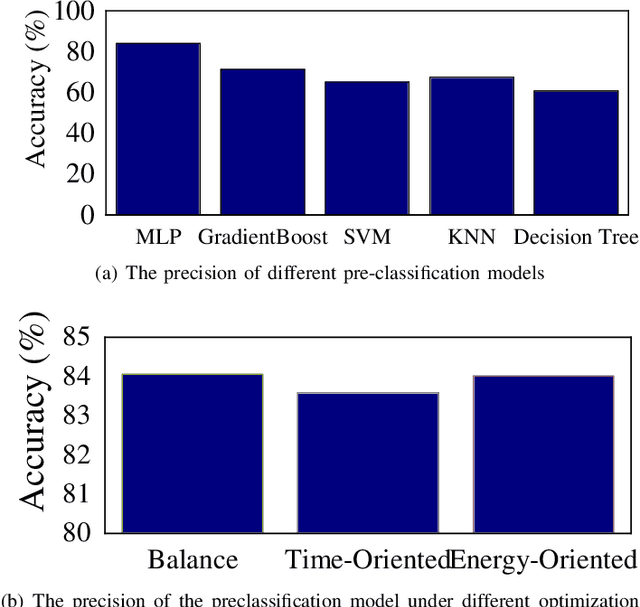
Object Detection on the mobile system is a challenge in terms of everything. Nowadays, many object detection models have been designed, and most of them concentrate on precision. However, the computation burden of those models on mobile systems is unacceptable. Researchers have designed some lightweight networks for mobiles by sacrificing precision. We present a novel edge-based task scheduling framework for object detection (termed as ESOD). In detail, we train a DNN model (termed as pre-model) to predict which object detection model to use for the coming task and offloads to which edge servers by physical characteristics of the image task (e.g., brightness, saturation). The results show that ESOD can reduce latency and energy consumption by an average of 22.13% and 29.60% and improve the mAP to 45.8(with 0.9 mAP better), respectively, compared with the SOTA DETR model.
Self-Supervised Monocular Depth Estimation with Internal Feature Fusion
Oct 20, 2021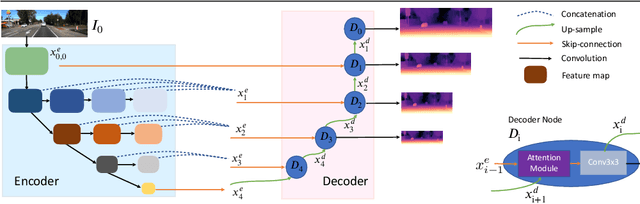
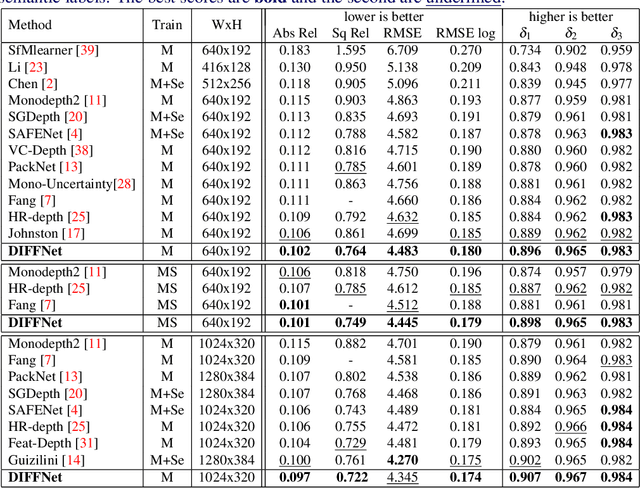

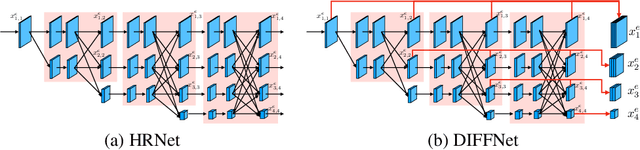
Self-supervised learning for depth estimation uses geometry in image sequences for supervision and shows promising results. Like many computer vision tasks, depth network performance is determined by the capability to learn accurate spatial and semantic representations from images. Therefore, it is natural to exploit semantic segmentation networks for depth estimation. In this work, based on a well-developed semantic segmentation network HRNet, we propose a novel depth estimation networkDIFFNet, which can make use of semantic information in down and upsampling procedures. By applying feature fusion and an attention mechanism, our proposed method outperforms the state-of-the-art monocular depth estimation methods on the KITTI benchmark. Our method also demonstrates greater potential on higher resolution training data. We propose an additional extended evaluation strategy by establishing a test set of challenging cases, empirically derived from the standard benchmark.