 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Software Implementation of the Krylov Methods Based Reconstruction for the 3D Cone Beam CT Operator
Oct 26, 2021
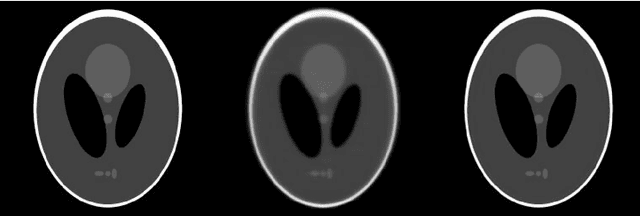
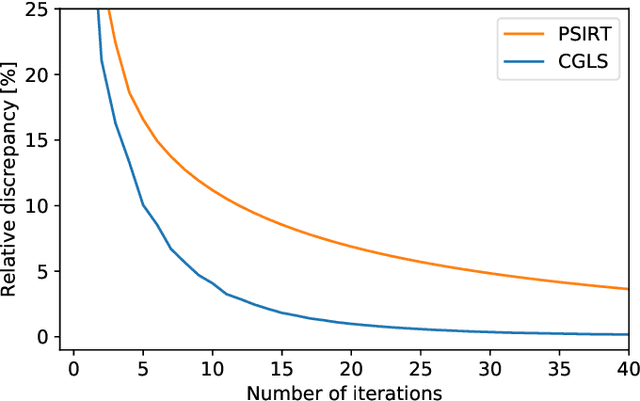
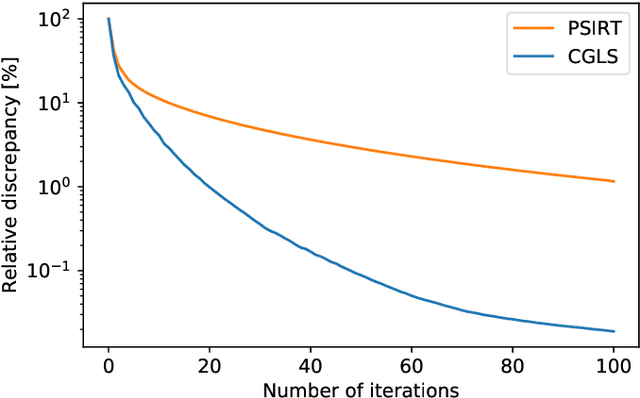
Krylov subspace methods are considered a standard tool to solve large systems of linear algebraic equations in many scientific disciplines such as image restoration or solving partial differential equations in mechanics of continuum. In the context of computer tomography however, the mostly used algebraic reconstruction techniques are based on classical iterative schemes. In this work we present software package that implements fully 3D cone beam projection operator and uses Krylov subspace methods, namely CGLS and LSQR to solve related tomographic reconstruction problems. It also implements basic preconditioning strategies. On the example of the cone beam CT reconstruction of 3D Shepp-Logan phantom we show that the speed of convergence of the CGLS clearly outperforms PSIRT algorithm. Therefore Krylov subspace methods present an interesting option for the reconstruction of large 3D cone beam CT problems.
* 5 pages, 3 figures, published in Proceedings of the 16th Virtual International Meeting on Fully 3D Image Reconstruction in Radiology and Nuclear Medicine 2021 arXiv:2110.04143
Two-dimensional multi-target detection
May 14, 2021

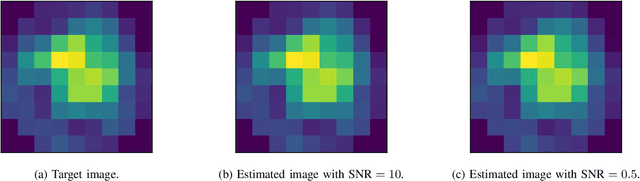
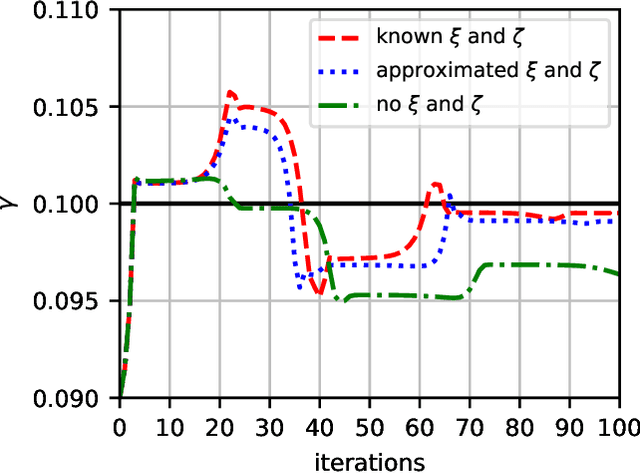
We consider the two-dimensional multi-target detection problem of recovering a target image from a noisy measurement that contains multiple copies of the image, each randomly rotated and translated. Motivated by the structure reconstruction problem in single-particle cryo-electron microscopy, we focus on the high noise regime, where the noise hampers accurate detection of the image occurrences. We develop an autocorrelation analysis framework to estimate the image directly from a measurement with an arbitrary spacing distribution of image occurrences, bypassing the estimation of individual locations and rotations. We conduct extensive numerical experiments, and demonstrate image recovery in highly noisy environments. The code to reproduce all numerical experiments is publicly available at https://github.com/krshay/MTD-2D.
Fast whole-slide cartography in colon cancer histology using superpixels and CNN classification
Jun 30, 2021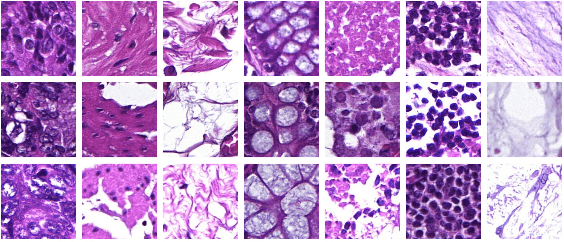
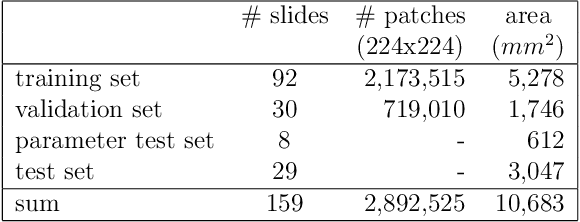
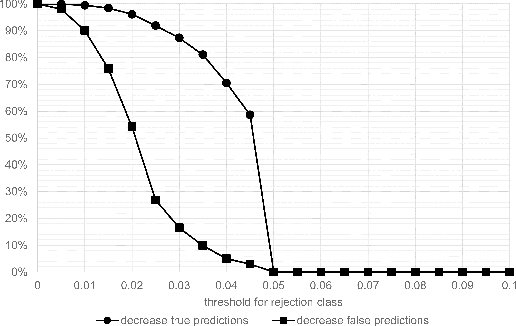
Whole-slide-image cartography is the process of automatically detecting and outlining different tissue types in digitized histological specimen. This semantic segmentation provides a basis for many follow-up analyses and can potentially guide subsequent medical decisions. Due to their large size, whole-slide-images typically have to be divided into smaller patches which are then analyzed individually using machine learning-based approaches. Thereby, local dependencies of image regions get lost and since a whole-slide-image comprises many thousands of such patches this process is inherently slow. We propose to subdivide the image into coherent regions prior to classification by grouping visually similar adjacent image pixels into larger segments, i.e. superpixels. Afterwards, only a random subset of patches per superpixel is classified and patch labels are combined into a single superpixel label. The algorithm has been developed and validated on a dataset of 159 hand-annotated whole-slide-images of colon resections and its performance has been compared to a standard patch-based approach. The algorithm shows an average speed-up of 41% on the test data and the overall accuracy is increased from 93.8% to 95.7%. We additionally propose a metric for identifying superpixels with an uncertain classification so they can be excluded from further analysis. Finally, we evaluate two potential medical applications, namely tumor area estimation including tumor invasive margin generation and tumor composition analysis.
Automated Testing of AI Models
Oct 07, 2021
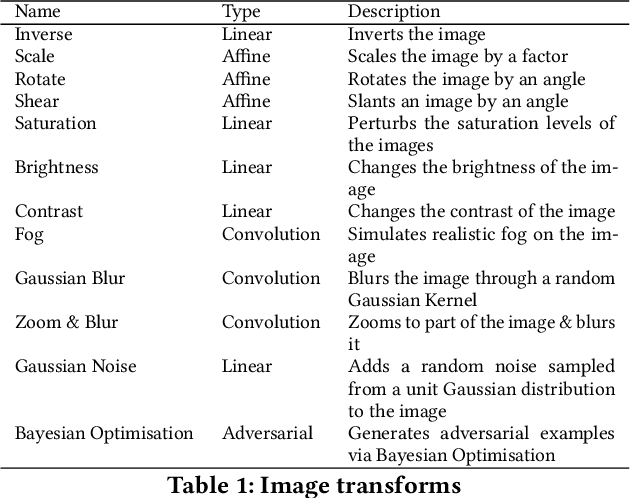
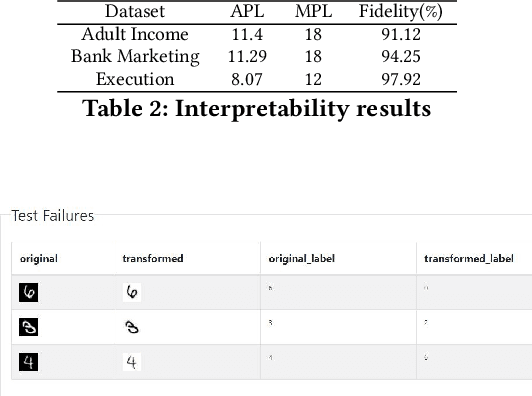
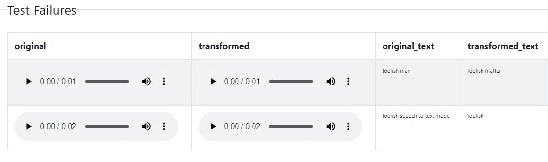
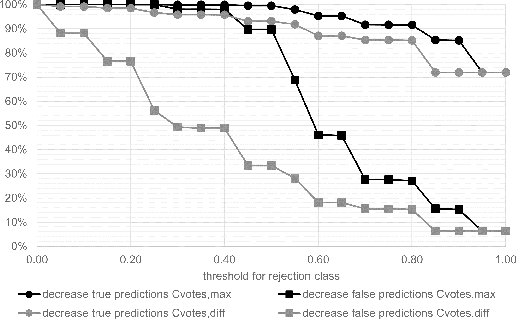
The last decade has seen tremendous progress in AI technology and applications. With such widespread adoption, ensuring the reliability of the AI models is crucial. In past, we took the first step of creating a testing framework called AITEST for metamorphic properties such as fairness, robustness properties for tabular, time-series, and text classification models. In this paper, we extend the capability of the AITEST tool to include the testing techniques for Image and Speech-to-text models along with interpretability testing for tabular models. These novel extensions make AITEST a comprehensive framework for testing AI models.
Image Clustering using an Augmented Generative Adversarial Network and Information Maximization
Nov 08, 2020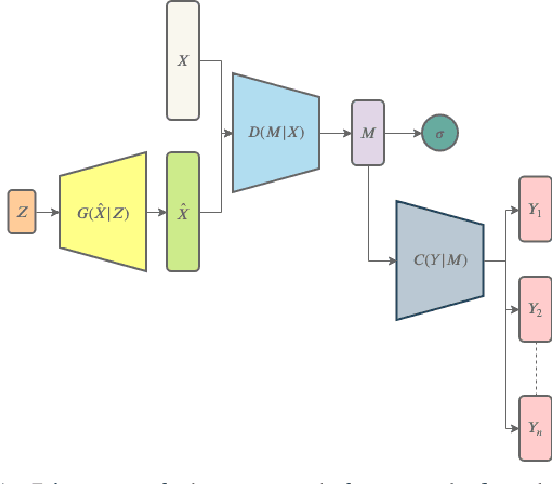
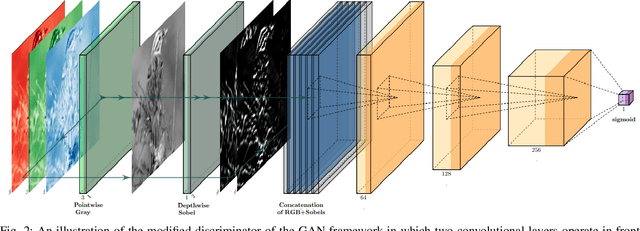

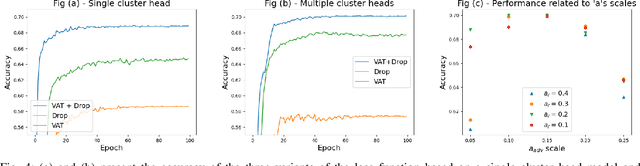
Image clustering has recently attracted significant attention due to the increased availability of unlabelled datasets. The efficiency of traditional clustering algorithms heavily depends on the distance functions used and the dimensionality of the features. Therefore, performance degradation is often observed when tackling either unprocessed images or high-dimensional features extracted from processed images. To deal with these challenges, we propose a deep clustering framework consisting of a modified generative adversarial network (GAN) and an auxiliary classifier. The modification employs Sobel operations prior to the discriminator of the GAN to enhance the separability of the learned features. The discriminator is then leveraged to generate representations as the input to an auxiliary classifier. An adaptive objective function is utilised to train the auxiliary classifier for clustering the representations, aiming to increase the robustness by minimizing the divergence of multiple representations generated by the discriminator. The auxiliary classifier is implemented with a group of multiple cluster-heads, where a tolerance hyper-parameter is used to tackle imbalanced data. Our results indicate that the proposed method significantly outperforms state-of-the-art clustering methods on CIFAR-10 and CIFAR-100, and is competitive on the STL10 and MNIST datasets.
Segmentation of Lungs COVID Infected Regions by Attention Mechanism and Synthetic Data
Aug 25, 2021
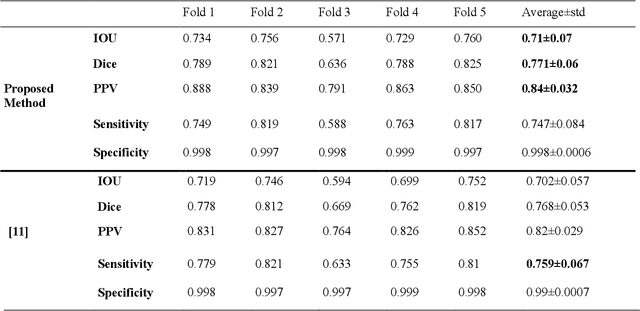
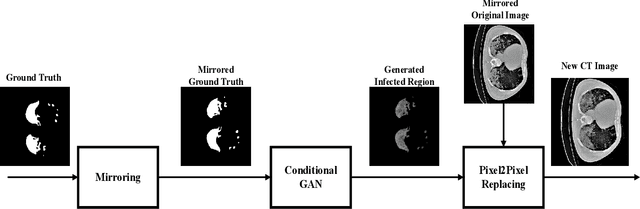
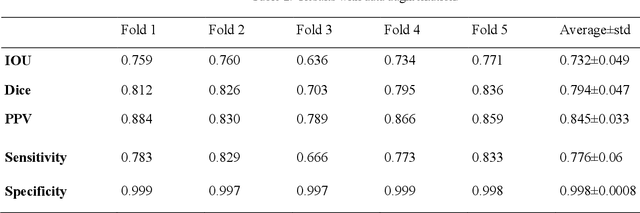
Coronavirus has caused hundreds of thousands of deaths. Fatalities could decrease if every patient could get suitable treatment by the healthcare system. Machine learning, especially computer vision methods based on deep learning, can help healthcare professionals diagnose and treat COVID-19 infected cases more efficiently. Hence, infected patients can get better service from the healthcare system and decrease the number of deaths caused by the coronavirus. This research proposes a method for segmenting infected lung regions in a CT image. For this purpose, a convolutional neural network with an attention mechanism is used to detect infected areas with complex patterns. Attention blocks improve the segmentation accuracy by focusing on informative parts of the image. Furthermore, a generative adversarial network generates synthetic images for data augmentation and expansion of small available datasets. Experimental results show the superiority of the proposed method compared to some existing procedures.
A Closer Look at Loss Weighting in Multi-Task Learning
Nov 20, 2021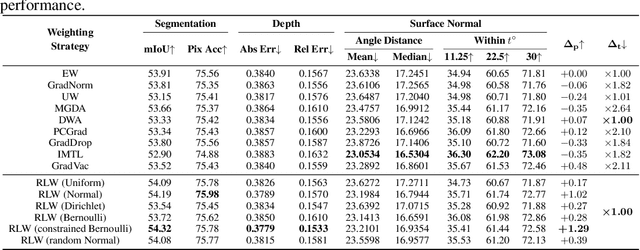
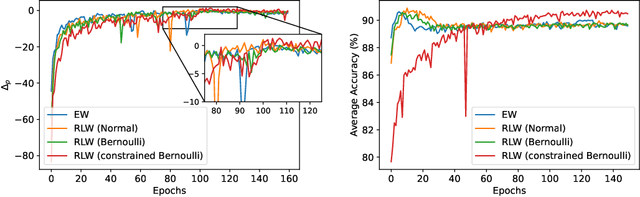
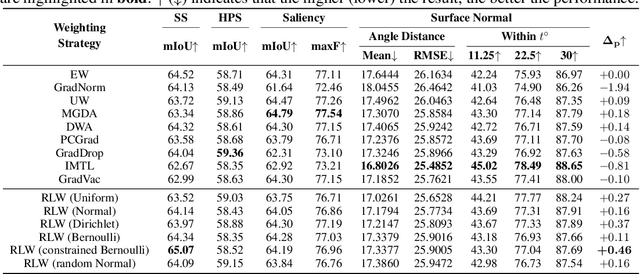
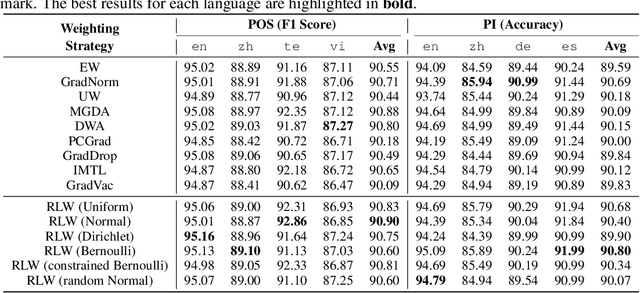
Multi-Task Learning (MTL) has achieved great success in various fields, however, how to balance different tasks to avoid negative effects is still a key problem. To achieve the task balancing, there exist many works to balance task losses or gradients. In this paper, we unify eight representative task balancing methods from the perspective of loss weighting and provide a consistent experimental comparison. Moreover, we surprisingly find that training a MTL model with random weights sampled from a distribution can achieve comparable performance over state-of-the-art baselines. Based on this finding, we propose a simple yet effective weighting strategy called Random Loss Weighting (RLW), which can be implemented in only one additional line of code over existing works. Theoretically, we analyze the convergence of RLW and reveal that RLW has a higher probability to escape local minima than existing models with fixed task weights, resulting in a better generalization ability. Empirically, we extensively evaluate the proposed RLW method on six image datasets and four multilingual tasks from the XTREME benchmark to show the effectiveness of the proposed RLW strategy when compared with state-of-the-art strategies.
SCIDA: Self-Correction Integrated Domain Adaptation from Single- to Multi-label Aerial Images
Aug 15, 2021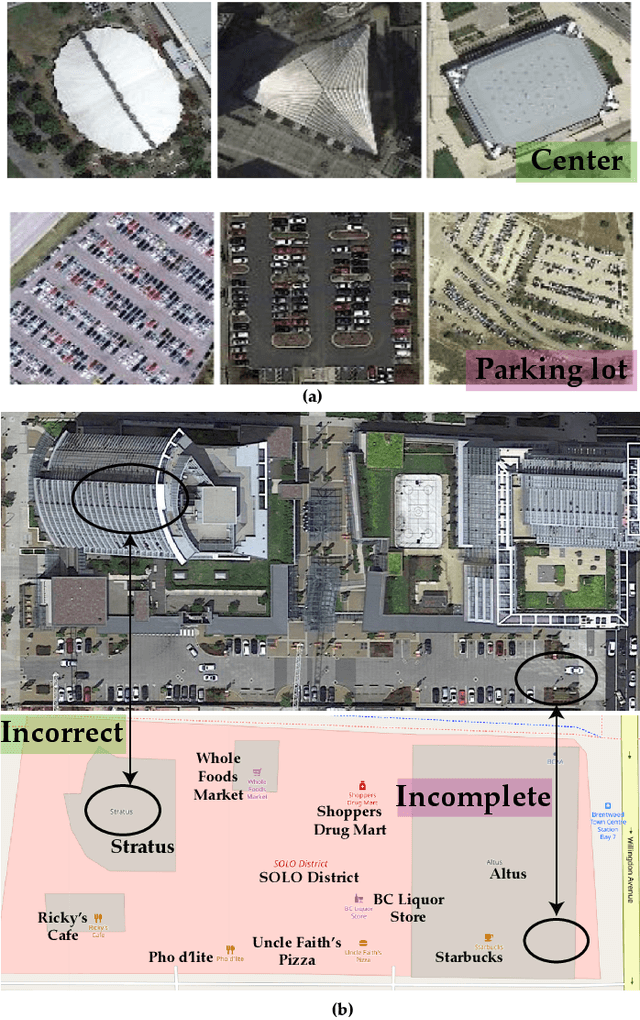
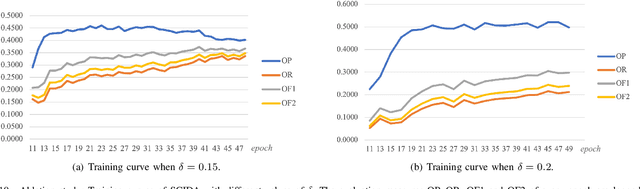
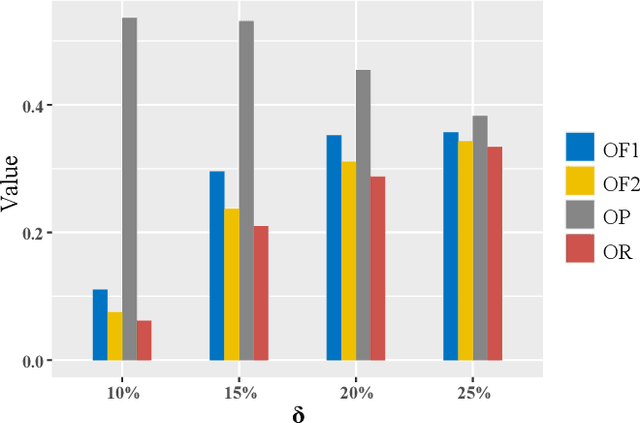
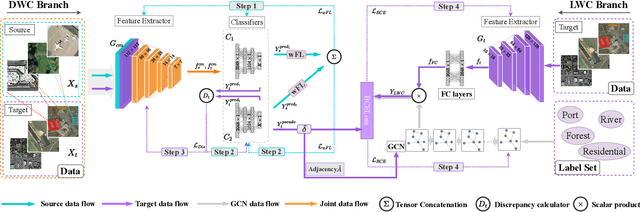
Most publicly available datasets for image classification are with single labels, while images are inherently multi-labeled in our daily life. Such an annotation gap makes many pre-trained single-label classification models fail in practical scenarios. This annotation issue is more concerned for aerial images: Aerial data collected from sensors naturally cover a relatively large land area with multiple labels, while annotated aerial datasets, which are publicly available (e.g., UCM, AID), are single-labeled. As manually annotating multi-label aerial images would be time/labor-consuming, we propose a novel self-correction integrated domain adaptation (SCIDA) method for automatic multi-label learning. SCIDA is weakly supervised, i.e., automatically learning the multi-label image classification model from using massive, publicly available single-label images. To achieve this goal, we propose a novel Label-Wise self-Correction (LWC) module to better explore underlying label correlations. This module also makes the unsupervised domain adaptation (UDA) from single- to multi-label data possible. For model training, the proposed model only uses single-label information yet requires no prior knowledge of multi-labeled data; and it predicts labels for multi-label aerial images. In our experiments, trained with single-labeled MAI-AID-s and MAI-UCM-s datasets, the proposed model is tested directly on our collected Multi-scene Aerial Image (MAI) dataset.
Grasp-Oriented Fine-grained Cloth Segmentation without Real Supervision
Oct 06, 2021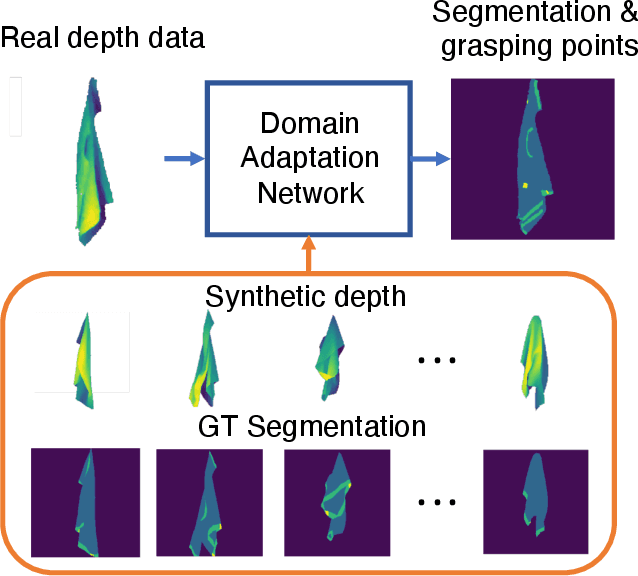
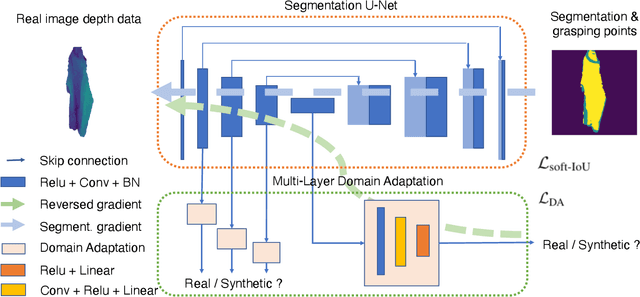

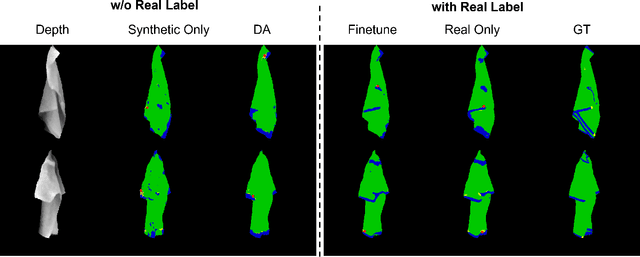
Automatically detecting graspable regions from a single depth image is a key ingredient in cloth manipulation. The large variability of cloth deformations has motivated most of the current approaches to focus on identifying specific grasping points rather than semantic parts, as the appearance and depth variations of local regions are smaller and easier to model than the larger ones. However, tasks like cloth folding or assisted dressing require recognising larger segments, such as semantic edges that carry more information than points. The first goal of this paper is therefore to tackle the problem of fine-grained region detection in deformed clothes using only a depth image. As a proof of concept, we implement an approach for T-shirts, and define up to 6 semantic regions of varying extent, including edges on the neckline, sleeve cuffs, and hem, plus top and bottom grasping points. We introduce a U-net based network to segment and label these parts. The second contribution of our work is concerned with the level of supervision that we require to train the proposed network. While most approaches learn to detect grasping points by combining real and synthetic annotations, in this work we defy the limitations of the synthetic data, and propose a multilayered domain adaptation (DA) strategy that does not use real annotations at all. We thoroughly evaluate our approach on real depth images of a T-shirt annotated with fine-grained labels. We show that training our network solely with synthetic data and the proposed DA yields results competitive with models trained on real data.
Feature-Filter: Detecting Adversarial Examples through Filtering off Recessive Features
Jul 19, 2021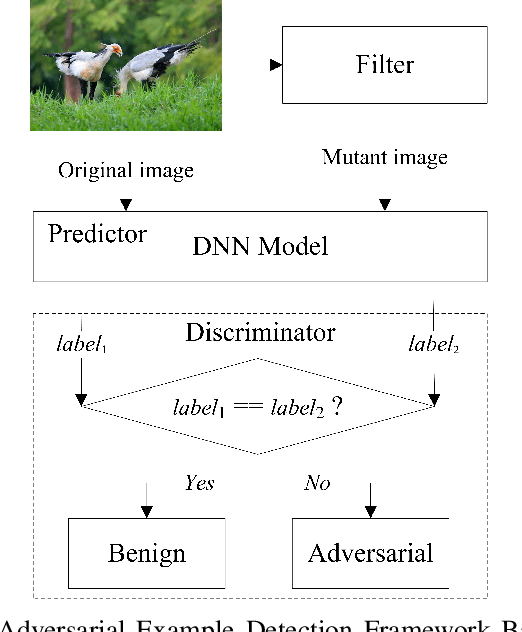

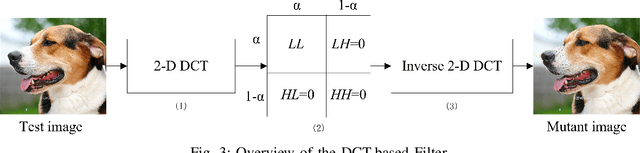

Deep neural networks (DNNs) are under threat from adversarial example attacks. The adversary can easily change the outputs of DNNs by adding small well-designed perturbations to inputs. Adversarial example detection is a fundamental work for robust DNNs-based service. Adversarial examples show the difference between humans and DNNs in image recognition. From a human-centric perspective, image features could be divided into dominant features that are comprehensible to humans, and recessive features that are incomprehensible to humans, yet are exploited by DNNs. In this paper, we reveal that imperceptible adversarial examples are the product of recessive features misleading neural networks, and an adversarial attack is essentially a kind of method to enrich these recessive features in the image. The imperceptibility of the adversarial examples indicates that the perturbations enrich recessive features, yet hardly affect dominant features. Therefore, adversarial examples are sensitive to filtering off recessive features, while benign examples are immune to such operation. Inspired by this idea, we propose a label-only adversarial detection approach that is referred to as feature-filter. Feature-filter utilizes discrete cosine transform to approximately separate recessive features from dominant features, and gets a mutant image that is filtered off recessive features. By only comparing DNN's prediction labels on the input and its mutant, feature-filter can real-time detect imperceptible adversarial examples at high accuracy and few false positives.