 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Automatic Signboard Detection from Natural Scene Image in Context of Bangladesh Google Street View
Mar 06, 2020


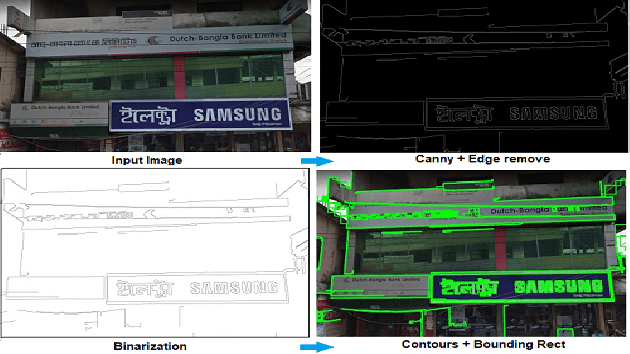

Automatic signboard region detection is the first step of information extraction about establishments from an image, especially when there is a complex background and multiple signboard regions are present in the image. Automatic signboard detection in Bangladesh is a challenging task because of low quality street view image, presence of overlapping objects and presence of signboard like objects which are not actually signboards. In this research, we provide a novel dataset from the perspective of Bangladesh city streets with an aim of signboard detection, namely Bangladesh Street View Signboard Objects (BSVSO) image dataset. We introduce a novel approach to detect signboard accurately by applying smart image processing techniques and statistically determined hyperparameter based deep learning method, Faster R-CNN. Comparison of different variations of this segmentation based learning method have also been performed in this research.
Joint Calibrationless Reconstruction and Segmentation of Parallel MRI
May 19, 2021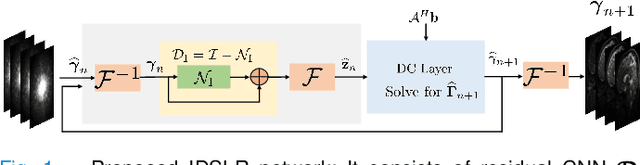
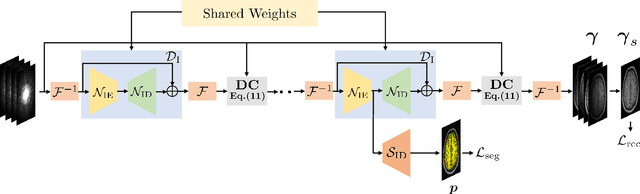
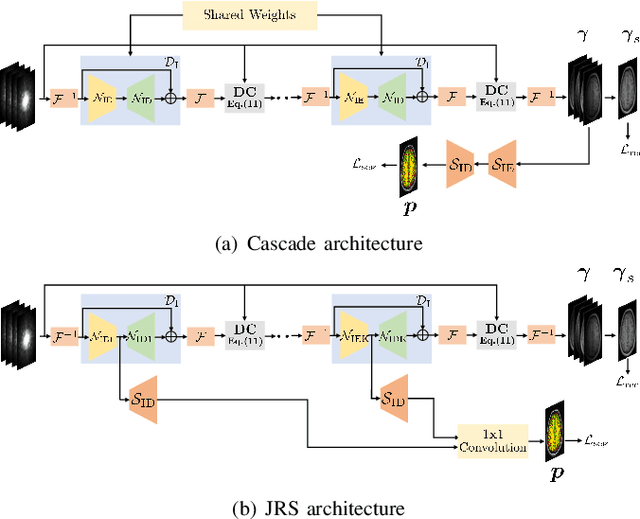
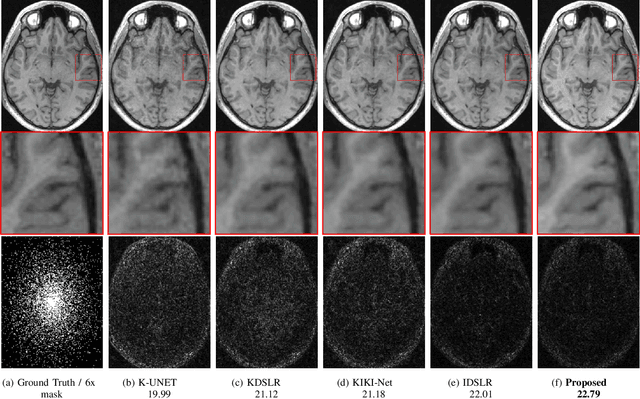
The volume estimation of brain regions from MRI data is a key problem in many clinical applications, where the acquisition of data at high spatial resolution is desirable. While parallel MRI and constrained image reconstruction algorithms can accelerate the scans, image reconstruction artifacts are inevitable, especially at high acceleration factors. We introduce a novel image domain deep-learning framework for calibrationless parallel MRI reconstruction, coupled with a segmentation network to improve image quality and to reduce the vulnerability of current segmentation algorithms to image artifacts resulting from acceleration. The combination of the proposed image domain deep calibrationless approach with the segmentation algorithm offers improved image quality, while increasing the accuracy of the segmentations. The novel architecture with an encoder shared between the reconstruction and segmentation tasks is seen to reduce the need for segmented training datasets. In particular, the proposed few-shot training strategy requires only 10% of segmented datasets to offer good performance.
Medical Image Enhancement Using Histogram Processing and Feature Extraction for Cancer Classification
Mar 14, 2020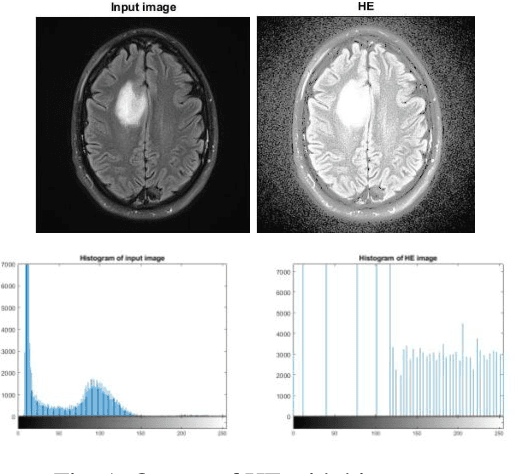
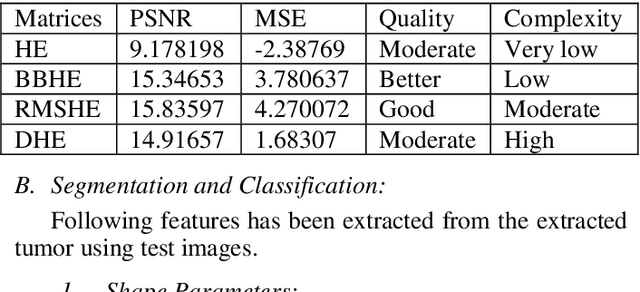
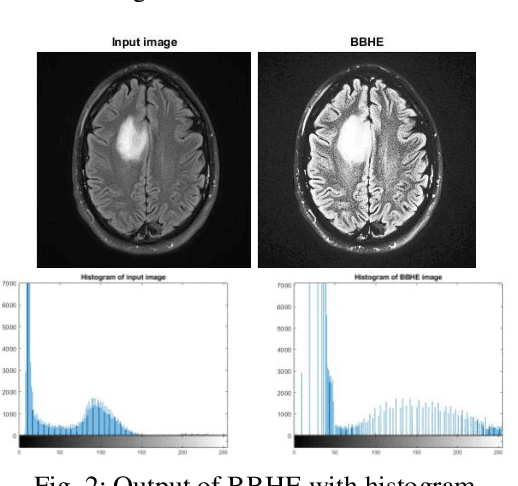
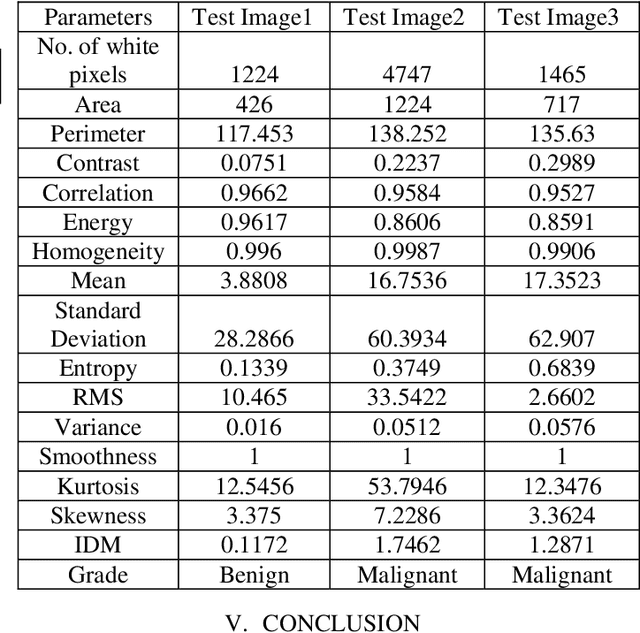
MRI (Magnetic Resonance Imaging) is a technique used to analyze and diagnose the problem defined by images like cancer or tumor in a brain. Physicians require good contrast images for better treatment purpose as it contains maximum information of the disease. MRI images are low contrast images which make diagnoses difficult; hence better localization of image pixels is required. Histogram Equalization techniques help to enhance the image so that it gives an improved visual quality and a well defined problem. The contrast and brightness is enhanced in such a way that it does not lose its original information and the brightness is preserved. We compare the different equalization techniques in this paper; the techniques are critically studied and elaborated. They are also tabulated to compare various parameters present in the image. In addition we have also segmented and extracted the tumor part out of the brain using K-means algorithm. For classification and feature extraction the method used is Support Vector Machine (SVM). The main goal of this research work is to help the medical field with a light of image processing.
Image Super-Resolution with Cross-Scale Non-Local Attention and Exhaustive Self-Exemplars Mining
Jun 02, 2020
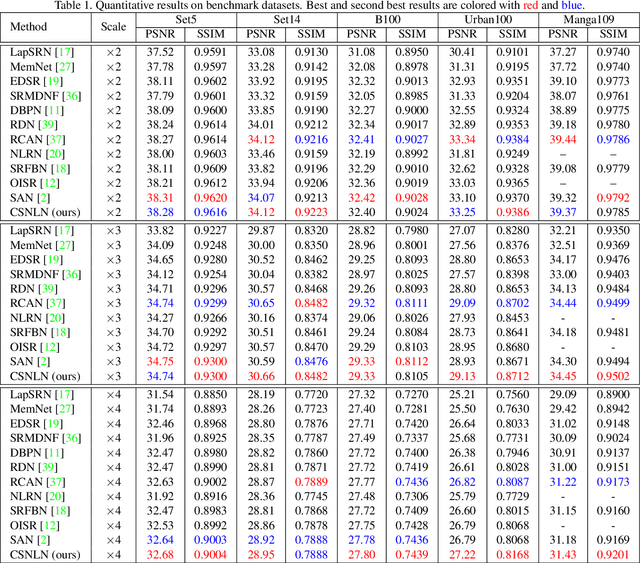
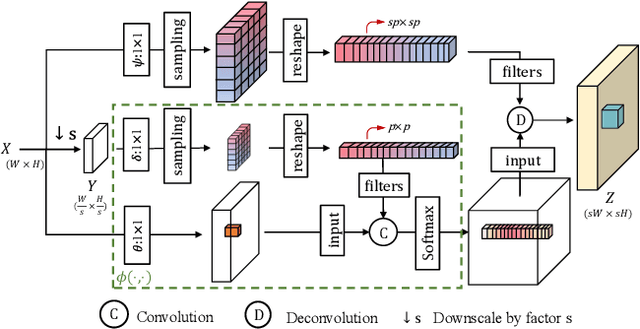
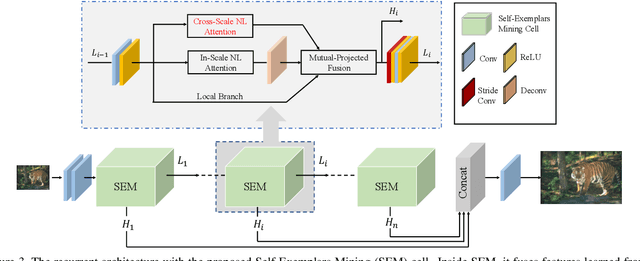
Deep convolution-based single image super-resolution (SISR) networks embrace the benefits of learning from large-scale external image resources for local recovery, yet most existing works have ignored the long-range feature-wise similarities in natural images. Some recent works have successfully leveraged this intrinsic feature correlation by exploring non-local attention modules. However, none of the current deep models have studied another inherent property of images: cross-scale feature correlation. In this paper, we propose the first Cross-Scale Non-Local (CS-NL) attention module with integration into a recurrent neural network. By combining the new CS-NL prior with local and in-scale non-local priors in a powerful recurrent fusion cell, we can find more cross-scale feature correlations within a single low-resolution (LR) image. The performance of SISR is significantly improved by exhaustively integrating all possible priors. Extensive experiments demonstrate the effectiveness of the proposed CS-NL module by setting new state-of-the-arts on multiple SISR benchmarks.
Hierarchy-based Image Embeddings for Semantic Image Retrieval
Sep 26, 2018
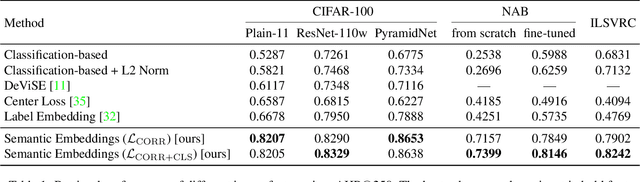
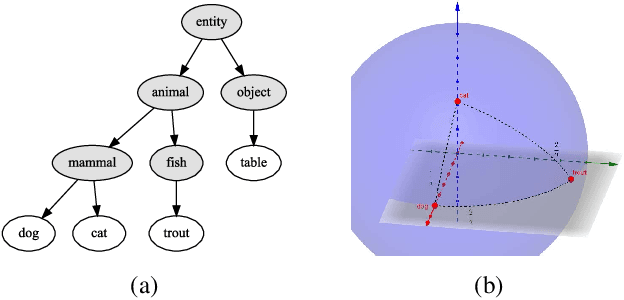
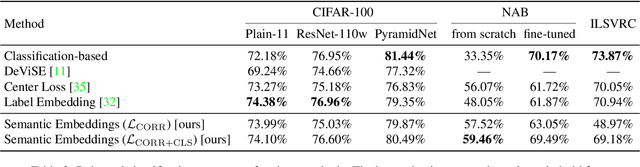
Deep neural networks trained for classification have been found to learn powerful image representations, which are also often used for other tasks such as comparing images w.r.t. their visual similarity. However, visual similarity does not imply semantic similarity. In order to learn semantically discriminative features, we propose to map images onto class centroids whose pair-wise dot products correspond to a measure of semantic similarity between classes. Such an embedding would not only improve image retrieval results, but could also facilitate integrating semantics for other tasks, e.g., novelty detection or few-shot learning. We introduce a deterministic algorithm for computing the class centroids directly based on prior world-knowledge encoded in a hierarchy of classes such as WordNet. Experiments on CIFAR-100 and ImageNet show that our learned semantic image embeddings improve the semantic consistency of image retrieval results by a large margin.
Search Space of Adversarial Perturbations against Image Filters
Mar 05, 2020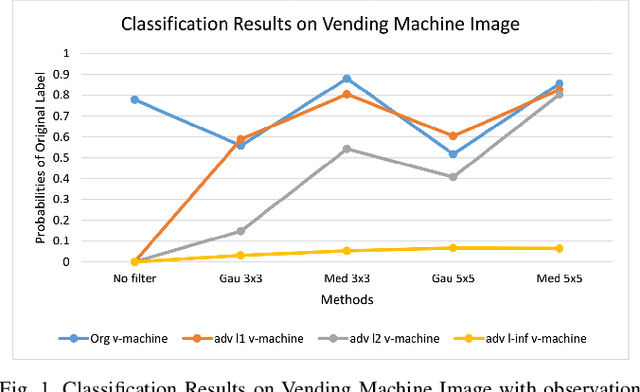
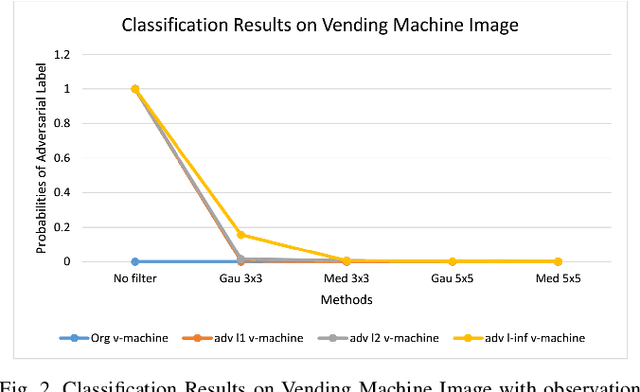

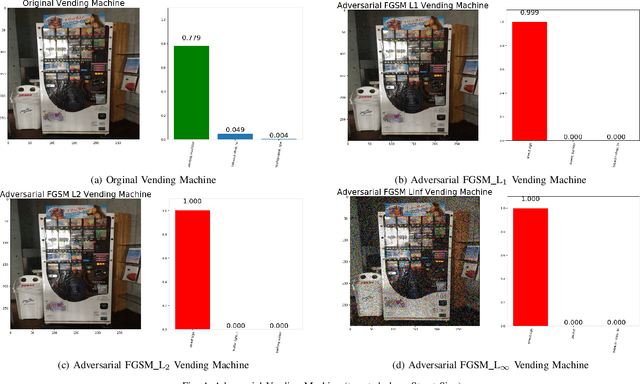
The superiority of deep learning performance is threatened by safety issues for itself. Recent findings have shown that deep learning systems are very weak to adversarial examples, an attack form that was altered by the attacker's intent to deceive the deep learning system. There are many proposed defensive methods to protect deep learning systems against adversarial examples. However, there is still a lack of principal strategies to deceive those defensive methods. Any time a particular countermeasure is proposed, a new powerful adversarial attack will be invented to deceive that countermeasure. In this study, we focus on investigating the ability to create adversarial patterns in search space against defensive methods that use image filters. Experimental results conducted on the ImageNet dataset with image classification tasks showed the correlation between the search space of adversarial perturbation and filters. These findings open a new direction for building stronger offensive methods towards deep learning systems.
On the Effect of Selfie Beautification Filters on Face Detection and Recognition
Oct 17, 2021
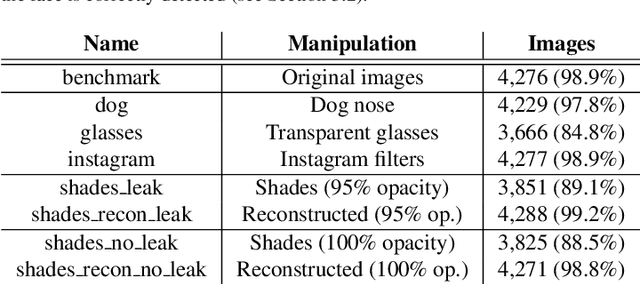

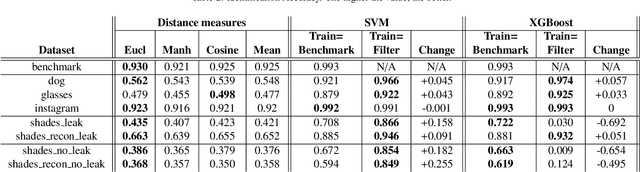
Beautification and augmented reality filters are very popular in applications that use selfie images captured with smartphones or personal devices. However, they can distort or modify biometric features, severely affecting the capability of recognizing individuals' identity or even detecting the face. Accordingly, we address the effect of such filters on the accuracy of automated face detection and recognition. The social media image filters studied either modify the image contrast or illumination or occlude parts of the face with for example artificial glasses or animal noses. We observe that the effect of some of these filters is harmful both to face detection and identity recognition, specially if they obfuscate the eye or (to a lesser extent) the nose. To counteract such effect, we develop a method to reconstruct the applied manipulation with a modified version of the U-NET segmentation network. This is observed to contribute to a better face detection and recognition accuracy. From a recognition perspective, we employ distance measures and trained machine learning algorithms applied to features extracted using a ResNet-34 network trained to recognize faces. We also evaluate if incorporating filtered images to the training set of machine learning approaches are beneficial for identity recognition. Our results show good recognition when filters do not occlude important landmarks, specially the eyes (identification accuracy >99%, EER<2%). The combined effect of the proposed approaches also allow to mitigate the effect produced by filters that occlude parts of the face, achieving an identification accuracy of >92% with the majority of perturbations evaluated, and an EER <8%. Although there is room for improvement, when neither U-NET reconstruction nor training with filtered images is applied, the accuracy with filters that severely occlude the eye is <72% (identification) and >12% (EER)
Load-balanced Gather-scatter Patterns for Sparse Deep Neural Networks
Dec 20, 2021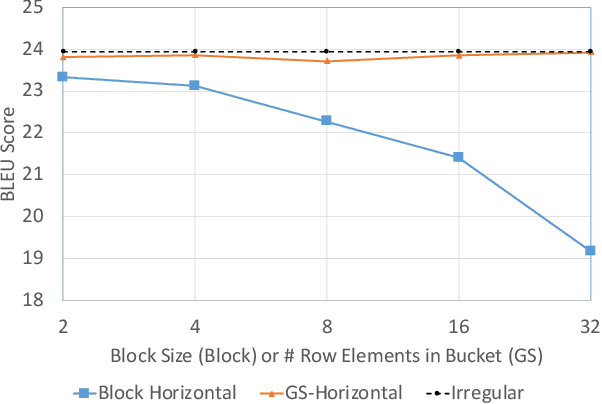
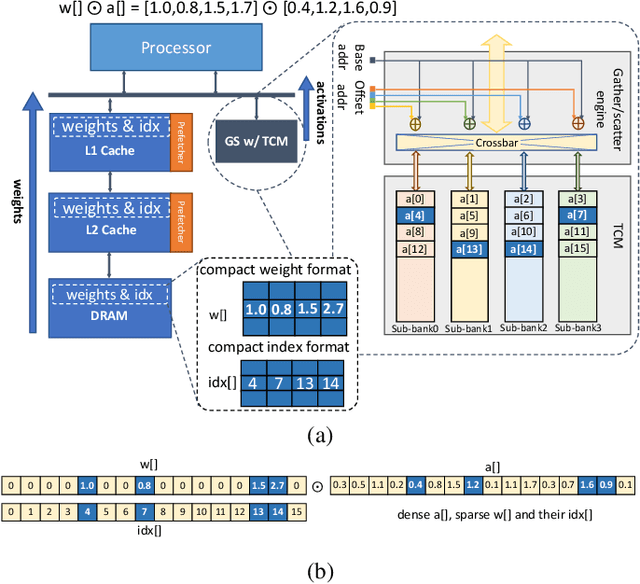

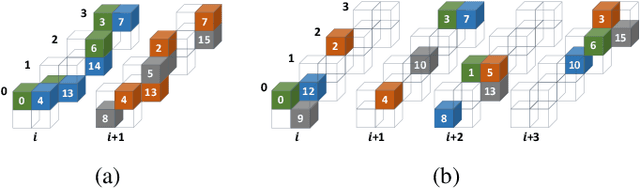
Deep neural networks (DNNs) have been proven to be effective in solving many real-life problems, but its high computation cost prohibits those models from being deployed to edge devices. Pruning, as a method to introduce zeros to model weights, has shown to be an effective method to provide good trade-offs between model accuracy and computation efficiency, and is a widely-used method to generate compressed models. However, the granularity of pruning makes important trade-offs. At the same sparsity level, a coarse-grained structured sparse pattern is more efficient on conventional hardware but results in worse accuracy, while a fine-grained unstructured sparse pattern can achieve better accuracy but is inefficient on existing hardware. On the other hand, some modern processors are equipped with fast on-chip scratchpad memories and gather/scatter engines that perform indirect load and store operations on such memories. In this work, we propose a set of novel sparse patterns, named gather-scatter (GS) patterns, to utilize the scratchpad memories and gather/scatter engines to speed up neural network inferences. Correspondingly, we present a compact sparse format. The proposed set of sparse patterns, along with a novel pruning methodology, address the load imbalance issue and result in models with quality close to unstructured sparse models and computation efficiency close to structured sparse models. Our experiments show that GS patterns consistently make better trade-offs between accuracy and computation efficiency compared to conventional structured sparse patterns. GS patterns can reduce the runtime of the DNN components by two to three times at the same accuracy levels. This is confirmed on three different deep learning tasks and popular models, namely, GNMT for machine translation, ResNet50 for image recognition, and Japser for acoustic speech recognition.
Plant Disease Detection Using Image Processing and Machine Learning
Jun 20, 2021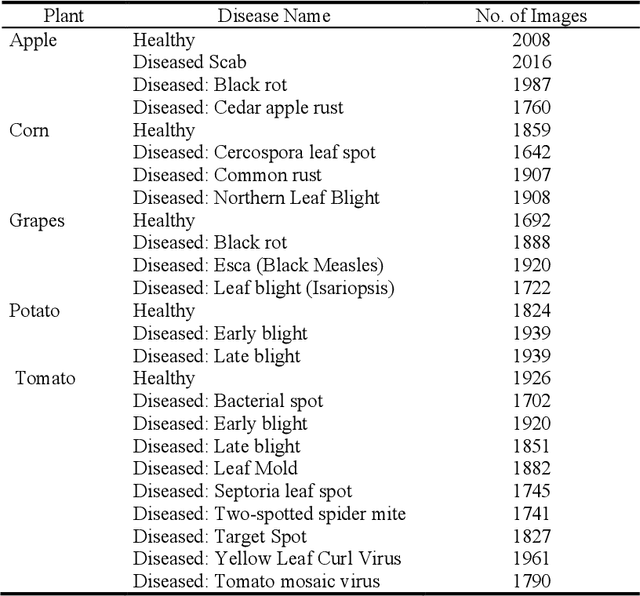

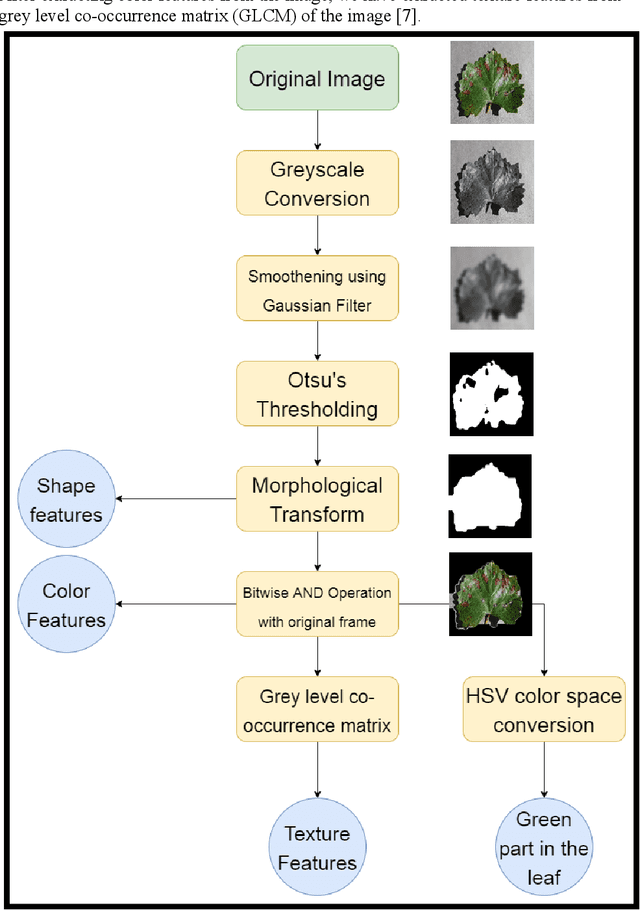

One of the important and tedious task in agricultural practices is the detection of the disease on crops. It requires huge time as well as skilled labor. This paper proposes a smart and efficient technique for detection of crop disease which uses computer vision and machine learning techniques. The proposed system is able to detect 20 different diseases of 5 common plants with 93% accuracy.
Burst Imaging for Light-Constrained Structure-From-Motion
Aug 23, 2021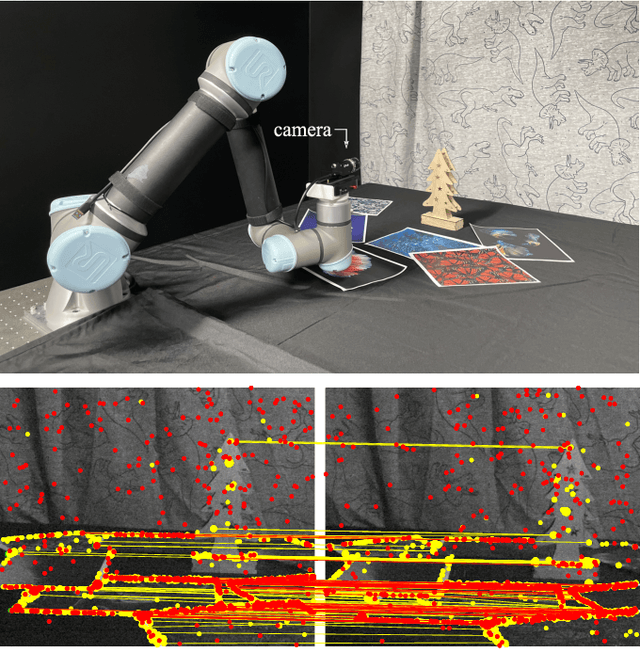
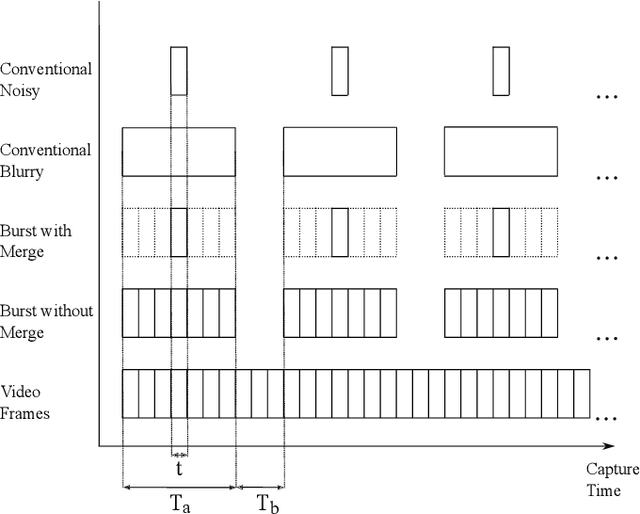
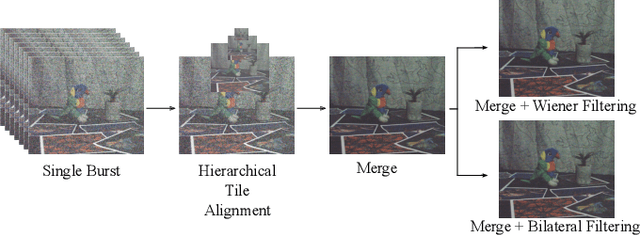

Images captured under extremely low light conditions are noise-limited, which can cause existing robotic vision algorithms to fail. In this paper we develop an image processing technique for aiding 3D reconstruction from images acquired in low light conditions. Our technique, based on burst photography, uses direct methods for image registration within bursts of short exposure time images to improve the robustness and accuracy of feature-based structure-from-motion (SfM). We demonstrate improved SfM performance in challenging light-constrained scenes, including quantitative evaluations that show improved feature performance and camera pose estimates. Additionally, we show that our method converges more frequently to correct reconstructions than the state-of-the-art. Our method is a significant step towards allowing robots to operate in low light conditions, with potential applications to robots operating in environments such as underground mines and night time operation.