 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Two-dimensional Deep Regression for Early Yield Prediction of Winter Wheat
Nov 15, 2021
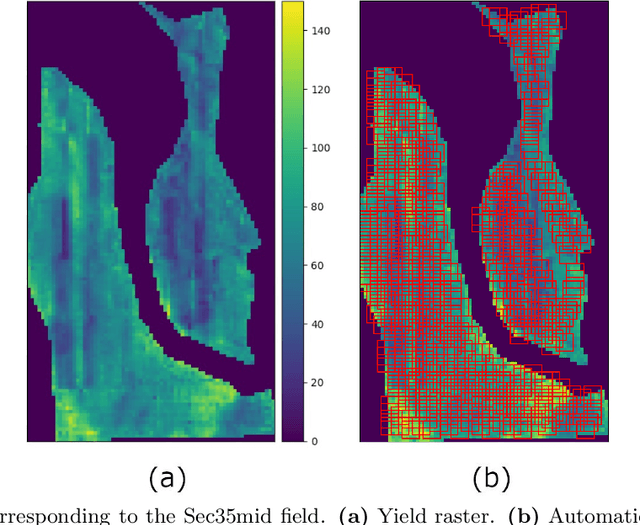
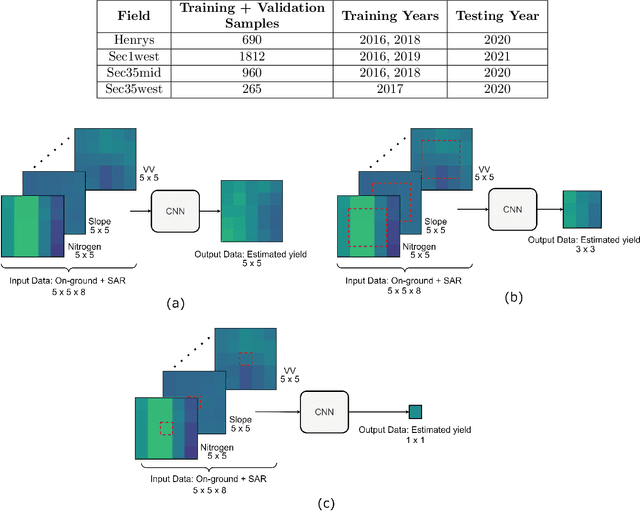
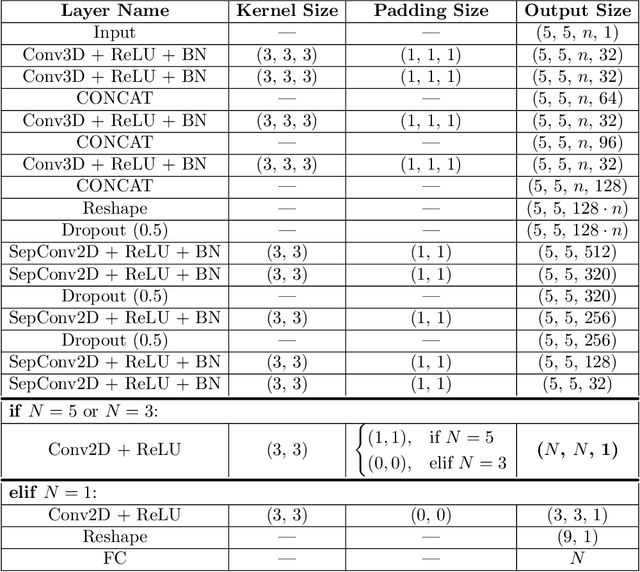
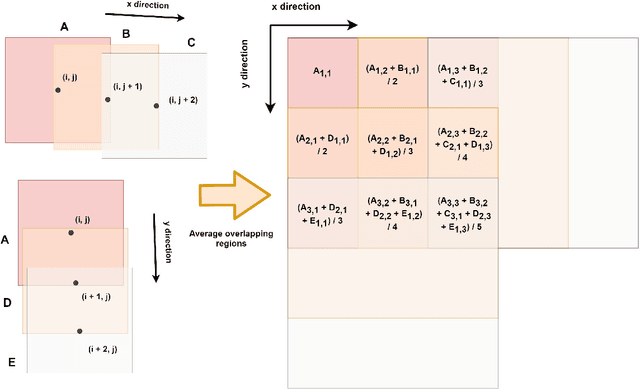
Crop yield prediction is one of the tasks of Precision Agriculture that can be automated based on multi-source periodic observations of the fields. We tackle the yield prediction problem using a Convolutional Neural Network (CNN) trained on data that combines radar satellite imagery and on-ground information. We present a CNN architecture called Hyper3DNetReg that takes in a multi-channel input image and outputs a two-dimensional raster, where each pixel represents the predicted yield value of the corresponding input pixel. We utilize radar data acquired from the Sentinel-1 satellites, while the on-ground data correspond to a set of six raster features: nitrogen rate applied, precipitation, slope, elevation, topographic position index (TPI), and aspect. We use data collected during the early stage of the winter wheat growing season (March) to predict yield values during the harvest season (August). We present experiments over four fields of winter wheat and show that our proposed methodology yields better results than five compared methods, including multiple linear regression, an ensemble of feedforward networks using AdaBoost, a stacked autoencoder, and two other CNN architectures.
Learned holographic light transport
Aug 01, 2021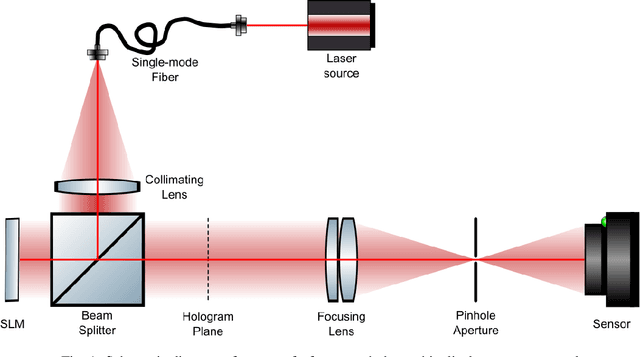

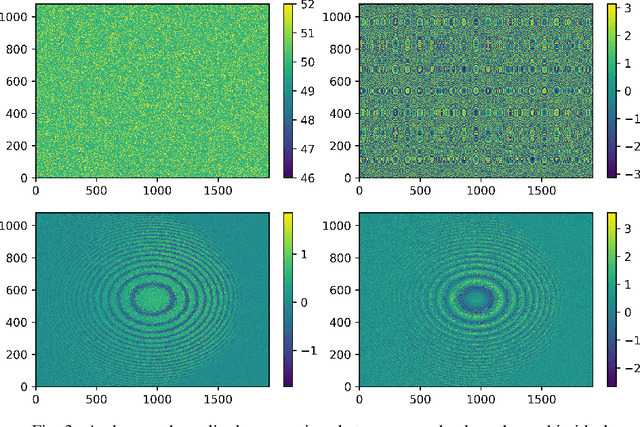

Computer-Generated Holography (CGH) algorithms often fall short in matching simulations with results from a physical holographic display. Our work addresses this mismatch by learning the holographic light transport in holographic displays. Using a camera and a holographic display, we capture the image reconstructions of optimized holograms that rely on ideal simulations to generate a dataset. Inspired by the ideal simulations, we learn a complex-valued convolution kernel that can propagate given holograms to captured photographs in our dataset. Our method can dramatically improve simulation accuracy and image quality in holographic displays while paving the way for physically informed learning approaches.
Towards Super-Resolution CEST MRI for Visualization of Small Structures
Dec 03, 2021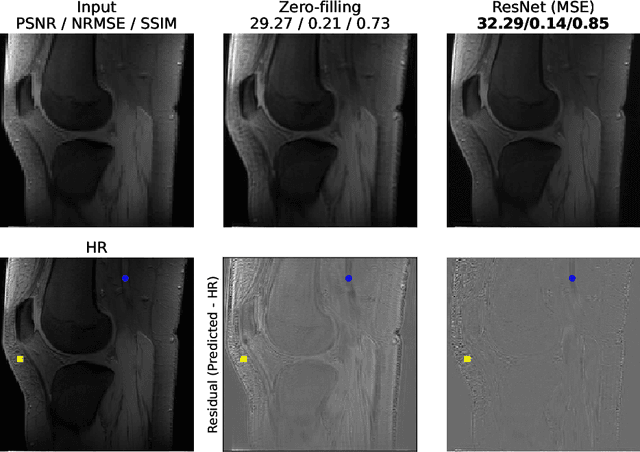
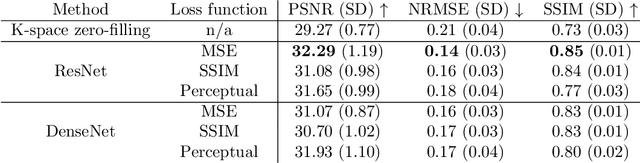
The onset of rheumatic diseases such as rheumatoid arthritis is typically subclinical, which results in challenging early detection of the disease. However, characteristic changes in the anatomy can be detected using imaging techniques such as MRI or CT. Modern imaging techniques such as chemical exchange saturation transfer (CEST) MRI drive the hope to improve early detection even further through the imaging of metabolites in the body. To image small structures in the joints of patients, typically one of the first regions where changes due to the disease occur, a high resolution for the CEST MR imaging is necessary. Currently, however, CEST MR suffers from an inherently low resolution due to the underlying physical constraints of the acquisition. In this work we compared established up-sampling techniques to neural network-based super-resolution approaches. We could show, that neural networks are able to learn the mapping from low-resolution to high-resolution unsaturated CEST images considerably better than present methods. On the test set a PSNR of 32.29dB (+10%), a NRMSE of 0.14 (+28%), and a SSIM of 0.85 (+15%) could be achieved using a ResNet neural network, improving the baseline considerably. This work paves the way for the prospective investigation of neural networks for super-resolution CEST MRI and, followingly, might lead to a earlier detection of the onset of rheumatic diseases.
Medical Image Enhancement Using Histogram Processing and Feature Extraction for Cancer Classification
Mar 14, 2020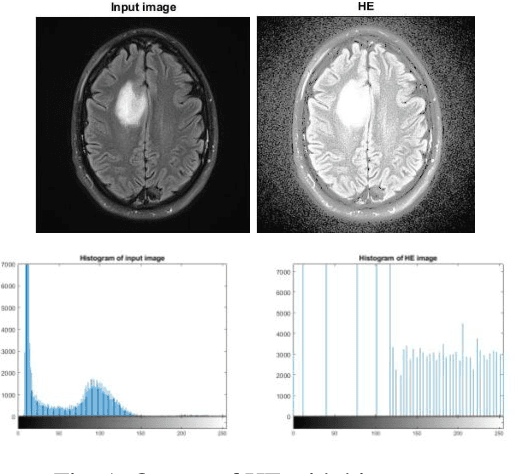
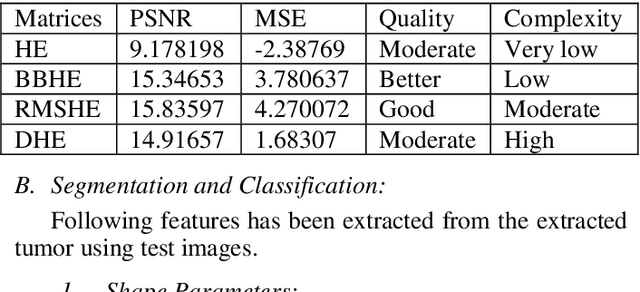
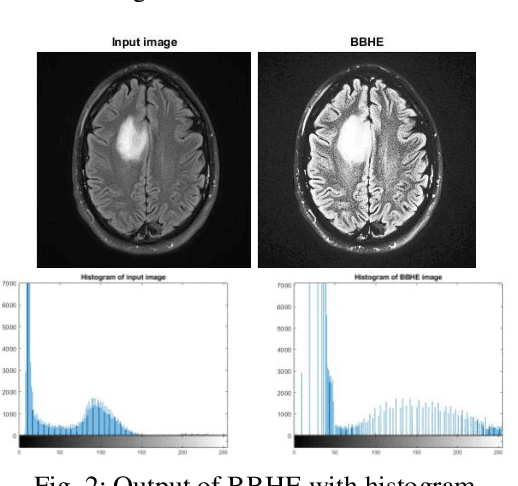
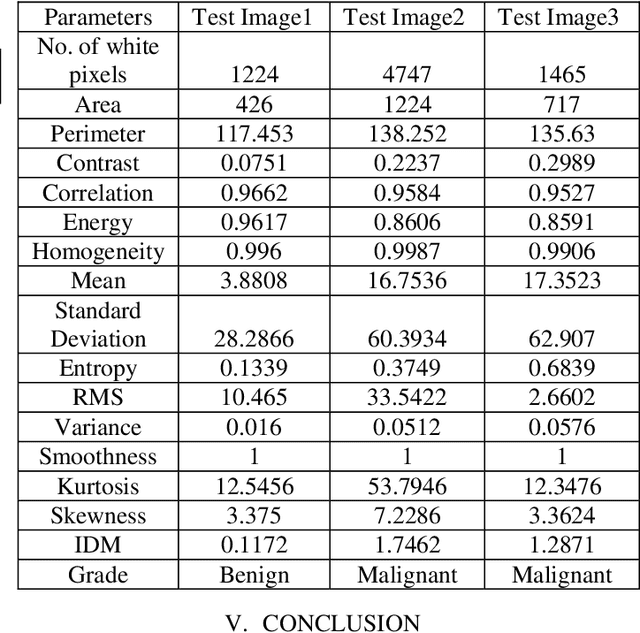
MRI (Magnetic Resonance Imaging) is a technique used to analyze and diagnose the problem defined by images like cancer or tumor in a brain. Physicians require good contrast images for better treatment purpose as it contains maximum information of the disease. MRI images are low contrast images which make diagnoses difficult; hence better localization of image pixels is required. Histogram Equalization techniques help to enhance the image so that it gives an improved visual quality and a well defined problem. The contrast and brightness is enhanced in such a way that it does not lose its original information and the brightness is preserved. We compare the different equalization techniques in this paper; the techniques are critically studied and elaborated. They are also tabulated to compare various parameters present in the image. In addition we have also segmented and extracted the tumor part out of the brain using K-means algorithm. For classification and feature extraction the method used is Support Vector Machine (SVM). The main goal of this research work is to help the medical field with a light of image processing.
PACE: Posthoc Architecture-Agnostic Concept Extractor for Explaining CNNs
Aug 31, 2021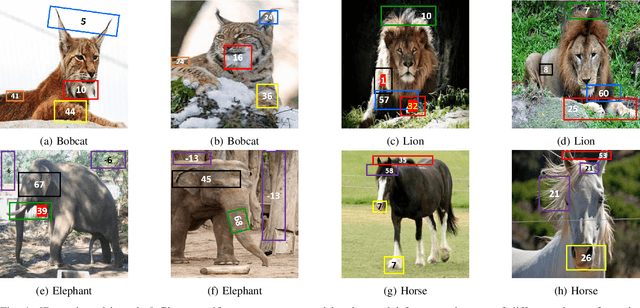
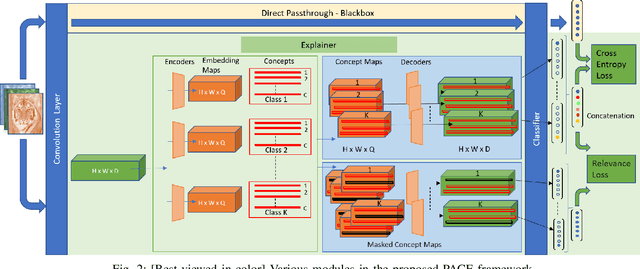
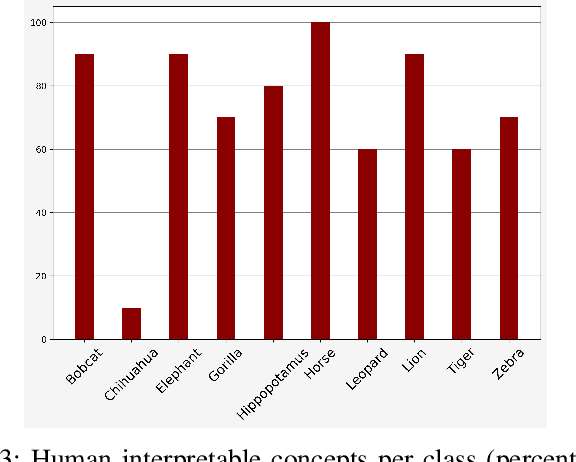

Deep CNNs, though have achieved the state of the art performance in image classification tasks, remain a black-box to a human using them. There is a growing interest in explaining the working of these deep models to improve their trustworthiness. In this paper, we introduce a Posthoc Architecture-agnostic Concept Extractor (PACE) that automatically extracts smaller sub-regions of the image called concepts relevant to the black-box prediction. PACE tightly integrates the faithfulness of the explanatory framework to the black-box model. To the best of our knowledge, this is the first work that extracts class-specific discriminative concepts in a posthoc manner automatically. The PACE framework is used to generate explanations for two different CNN architectures trained for classifying the AWA2 and Imagenet-Birds datasets. Extensive human subject experiments are conducted to validate the human interpretability and consistency of the explanations extracted by PACE. The results from these experiments suggest that over 72% of the concepts extracted by PACE are human interpretable.
IC-U-Net: A U-Net-based Denoising Autoencoder Using Mixtures of Independent Components for Automatic EEG Artifact Removal
Nov 22, 2021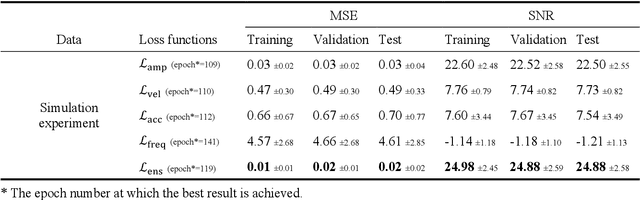
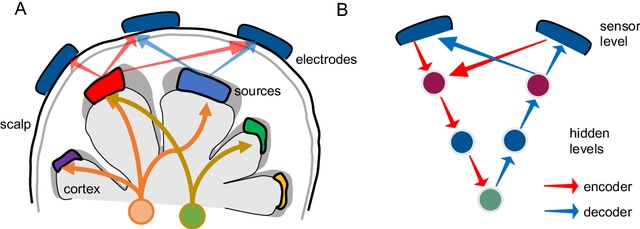
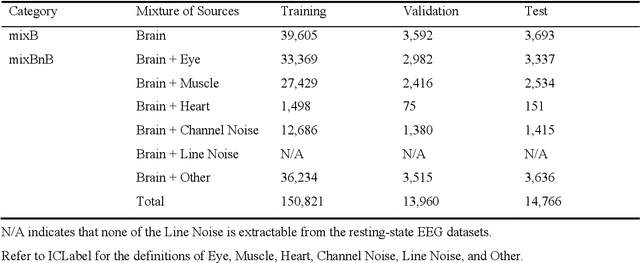
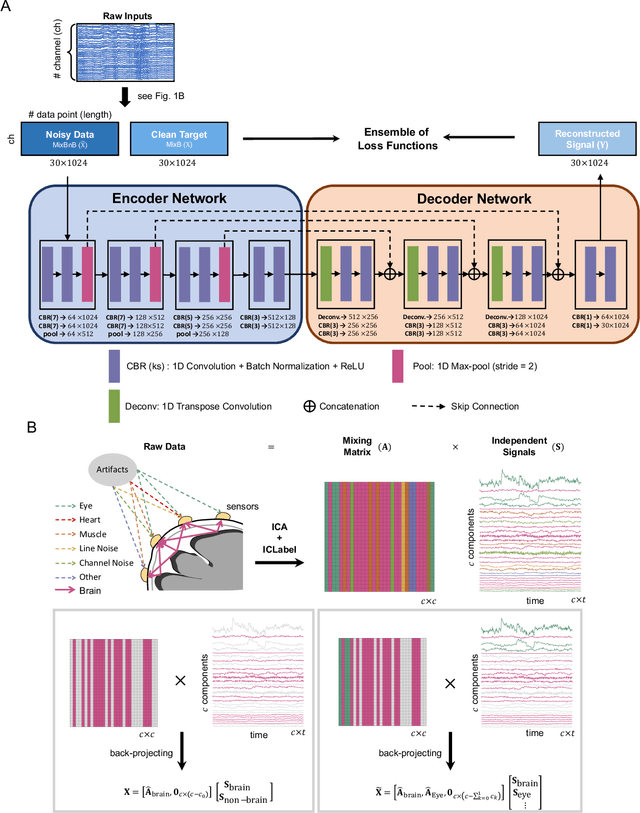
Electroencephalography (EEG) signals are often contaminated with artifacts. It is imperative to develop a practical and reliable artifact removal method to prevent misinterpretations of neural signals and underperformance of brain-computer interfaces. This study developed a new artifact removal method, IC-U-Net, which is based on the U-Net architecture for removing pervasive EEG artifacts and reconstructing brain sources. The IC-U-Net was trained using mixtures of brain and non-brain sources decomposed by independent component analysis and employed an ensemble of loss functions to model complex signal fluctuations in EEG recordings. The effectiveness of the proposed method in recovering brain sources and removing various artifacts (e.g., eye blinks/movements, muscle activities, and line/channel noises) was demonstrated in a simulation study and three real-world EEG datasets collected at rest and while driving and walking. IC-U-Net is user-friendly and publicly available, does not require parameter tuning or artifact type designations, and has no limitations on channel numbers. Given the increasing need to image natural brain dynamics in a mobile setting, IC-U-Net offers a promising end-to-end solution for automatically removing artifacts from EEG recordings.
Search Space of Adversarial Perturbations against Image Filters
Mar 05, 2020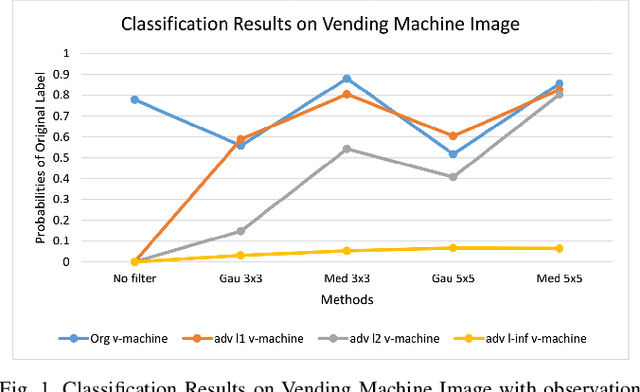
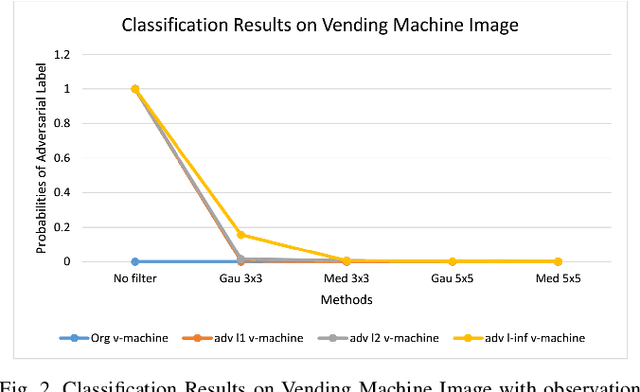

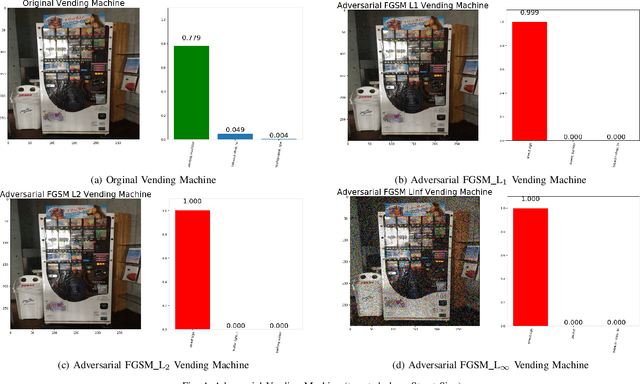
The superiority of deep learning performance is threatened by safety issues for itself. Recent findings have shown that deep learning systems are very weak to adversarial examples, an attack form that was altered by the attacker's intent to deceive the deep learning system. There are many proposed defensive methods to protect deep learning systems against adversarial examples. However, there is still a lack of principal strategies to deceive those defensive methods. Any time a particular countermeasure is proposed, a new powerful adversarial attack will be invented to deceive that countermeasure. In this study, we focus on investigating the ability to create adversarial patterns in search space against defensive methods that use image filters. Experimental results conducted on the ImageNet dataset with image classification tasks showed the correlation between the search space of adversarial perturbation and filters. These findings open a new direction for building stronger offensive methods towards deep learning systems.
Boosting few-shot classification with view-learnable contrastive learning
Jul 20, 2021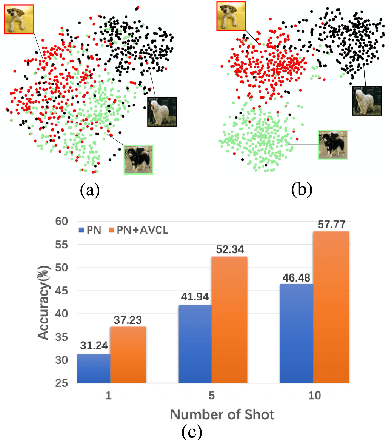
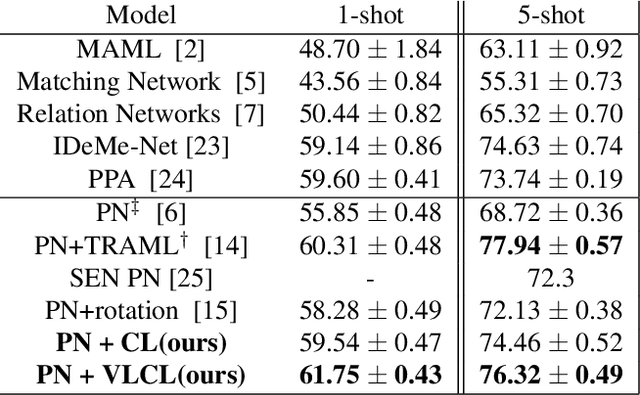
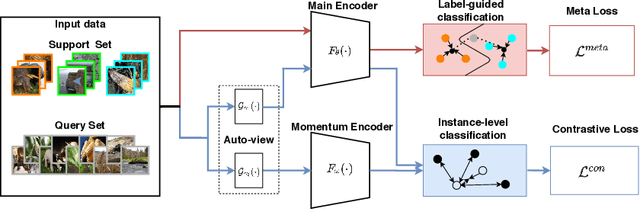
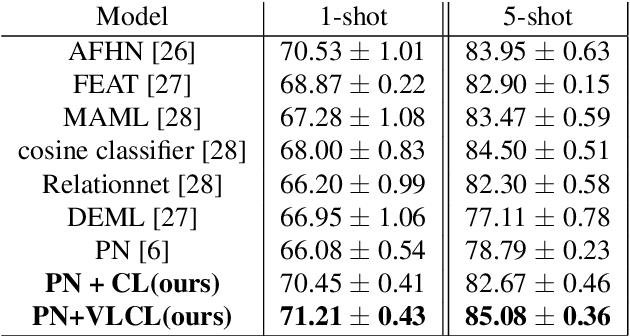
The goal of few-shot classification is to classify new categories with few labeled examples within each class. Nowadays, the excellent performance in handling few-shot classification problems is shown by metric-based meta-learning methods. However, it is very hard for previous methods to discriminate the fine-grained sub-categories in the embedding space without fine-grained labels. This may lead to unsatisfactory generalization to fine-grained subcategories, and thus affects model interpretation. To tackle this problem, we introduce the contrastive loss into few-shot classification for learning latent fine-grained structure in the embedding space. Furthermore, to overcome the drawbacks of random image transformation used in current contrastive learning in producing noisy and inaccurate image pairs (i.e., views), we develop a learning-to-learn algorithm to automatically generate different views of the same image. Extensive experiments on standard few-shot learning benchmarks demonstrate the superiority of our method.
Common Language for Goal-Oriented Semantic Communications: A Curriculum Learning Framework
Nov 15, 2021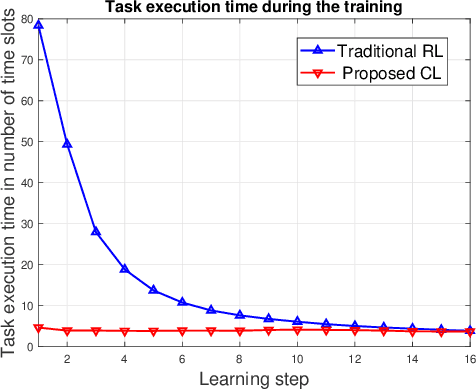
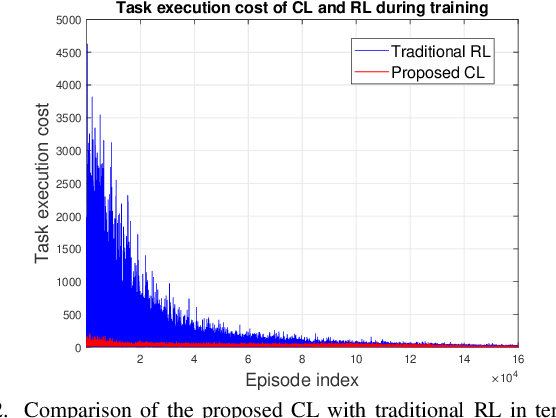
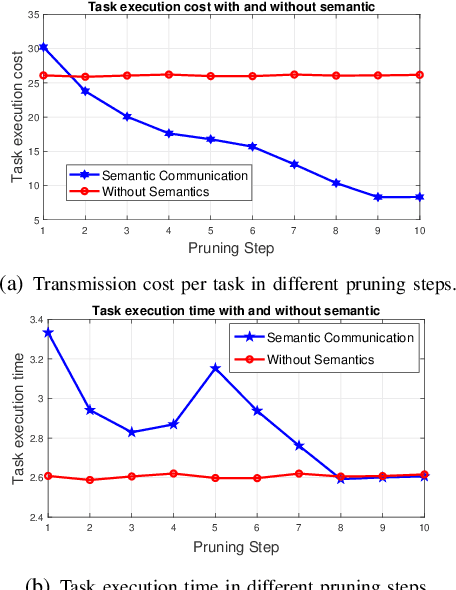
Semantic communications will play a critical role in enabling goal-oriented services over next-generation wireless systems. However, most prior art in this domain is restricted to specific applications (e.g., text or image), and it does not enable goal-oriented communications in which the effectiveness of the transmitted information must be considered along with the semantics so as to execute a certain task. In this paper, a comprehensive semantic communications framework is proposed for enabling goal-oriented task execution. To capture the semantics between a speaker and a listener, a common language is defined using the concept of beliefs to enable the speaker to describe the environment observations to the listener. Then, an optimization problem is posed to choose the minimum set of beliefs that perfectly describes the observation while minimizing the task execution time and transmission cost. A novel top-down framework that combines curriculum learning (CL) and reinforcement learning (RL) is proposed to solve this problem. Simulation results show that the proposed CL method outperforms traditional RL in terms of convergence time, task execution time, and transmission cost during training.
Image Super-Resolution with Cross-Scale Non-Local Attention and Exhaustive Self-Exemplars Mining
Jun 02, 2020
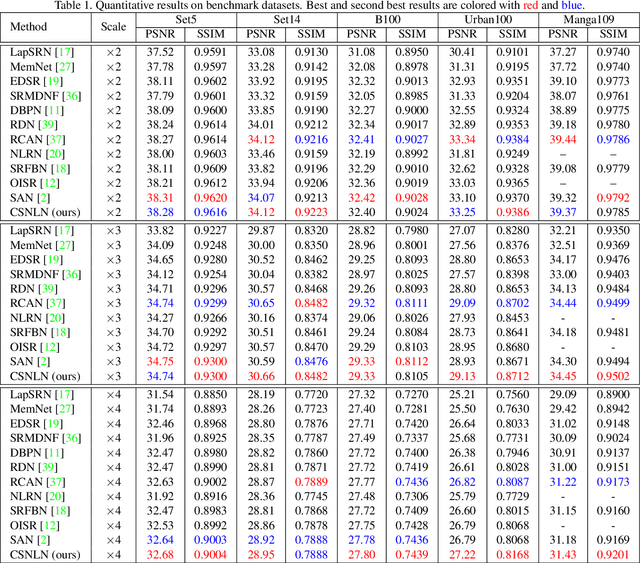
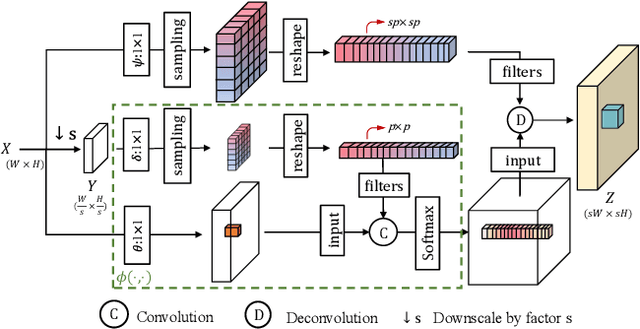
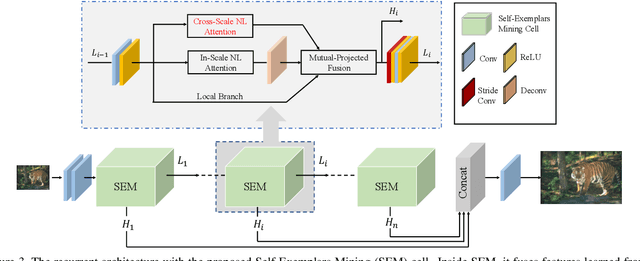
Deep convolution-based single image super-resolution (SISR) networks embrace the benefits of learning from large-scale external image resources for local recovery, yet most existing works have ignored the long-range feature-wise similarities in natural images. Some recent works have successfully leveraged this intrinsic feature correlation by exploring non-local attention modules. However, none of the current deep models have studied another inherent property of images: cross-scale feature correlation. In this paper, we propose the first Cross-Scale Non-Local (CS-NL) attention module with integration into a recurrent neural network. By combining the new CS-NL prior with local and in-scale non-local priors in a powerful recurrent fusion cell, we can find more cross-scale feature correlations within a single low-resolution (LR) image. The performance of SISR is significantly improved by exhaustively integrating all possible priors. Extensive experiments demonstrate the effectiveness of the proposed CS-NL module by setting new state-of-the-arts on multiple SISR benchmarks.