 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MARMOT: A Deep Learning Framework for Constructing Multimodal Representations for Vision-and-Language Tasks
Sep 23, 2021

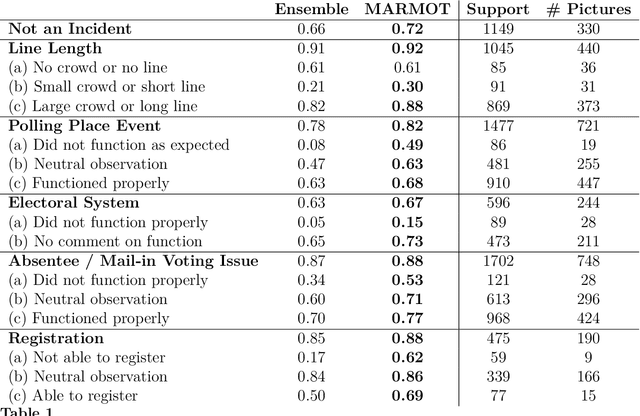
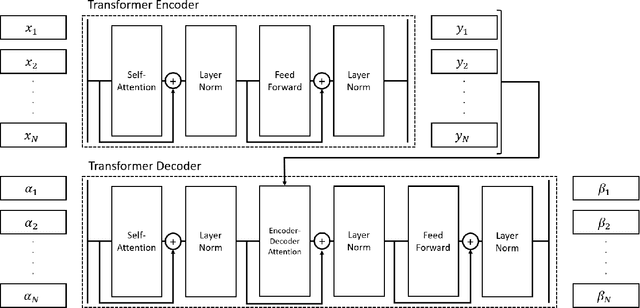
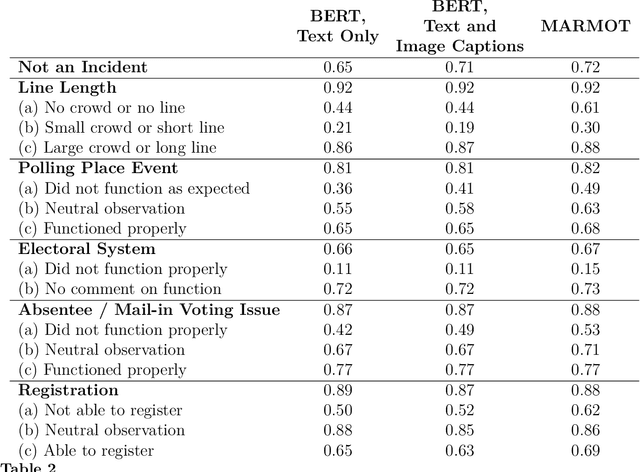
Political activity on social media presents a data-rich window into political behavior, but the vast amount of data means that almost all content analyses of social media require a data labeling step. However, most automated machine classification methods ignore the multimodality of posted content, focusing either on text or images. State-of-the-art vision-and-language models are unusable for most political science research: they require all observations to have both image and text and require computationally expensive pretraining. This paper proposes a novel vision-and-language framework called multimodal representations using modality translation (MARMOT). MARMOT presents two methodological contributions: it can construct representations for observations missing image or text, and it replaces the computationally expensive pretraining with modality translation. MARMOT outperforms an ensemble text-only classifier in 19 of 20 categories in multilabel classifications of tweets reporting election incidents during the 2016 U.S. general election. Moreover, MARMOT shows significant improvements over the results of benchmark multimodal models on the Hateful Memes dataset, improving the best result set by VisualBERT in terms of accuracy from 0.6473 to 0.6760 and area under the receiver operating characteristic curve (AUC) from 0.7141 to 0.7530.
WeakSTIL: Weak whole-slide image level stromal tumor infiltrating lymphocyte scores are all you need
Sep 13, 2021
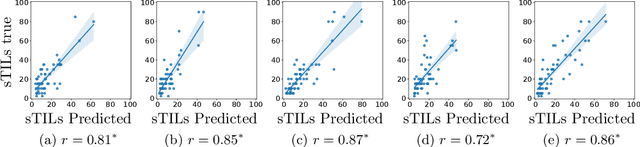
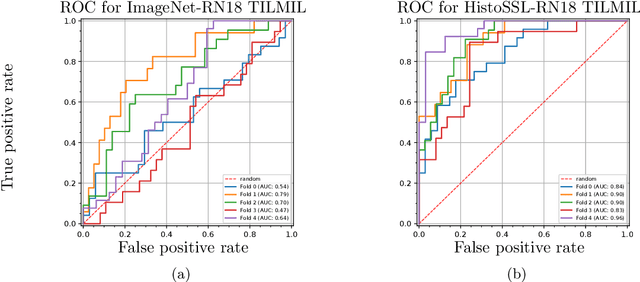
We present WeakSTIL, an interpretable two-stage weak label deep learning pipeline for scoring the percentage of stromal tumor infiltrating lymphocytes (sTIL%) in H&E-stained whole-slide images (WSIs) of breast cancer tissue. The sTIL% score is a prognostic and predictive biomarker for many solid tumor types. However, due to the high labeling efforts and high intra- and interobserver variability within and between expert annotators, this biomarker is currently not used in routine clinical decision making. WeakSTIL compresses tiles of a WSI using a feature extractor pre-trained with self-supervised learning on unlabeled histopathology data and learns to predict precise sTIL% scores for each tile in the tumor bed by using a multiple instance learning regressor that only requires a weak WSI-level label. By requiring only a weak label, we overcome the large annotation efforts required to train currently existing TIL detection methods. We show that WeakSTIL is at least as good as other TIL detection methods when predicting the WSI-level sTIL% score, reaching a coefficient of determination of $0.45\pm0.15$ when compared to scores generated by an expert pathologist, and an AUC of $0.89\pm0.05$ when treating it as the clinically interesting sTIL-high vs sTIL-low classification task. Additionally, we show that the intermediate tile-level predictions of WeakSTIL are highly interpretable, which suggests that WeakSTIL pays attention to latent features related to the number of TILs and the tissue type. In the future, WeakSTIL may be used to provide consistent and interpretable sTIL% predictions to stratify breast cancer patients into targeted therapy arms.
An Acceleration Method Based on Deep Learning and Multilinear Feature Space
Oct 16, 2021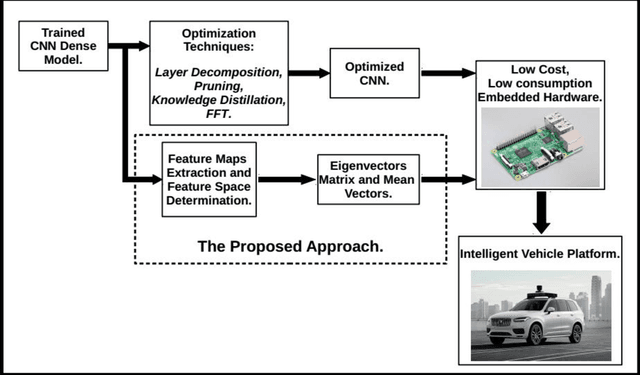
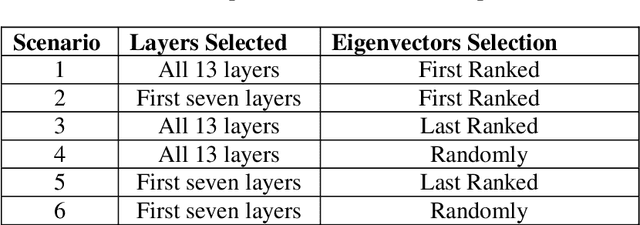
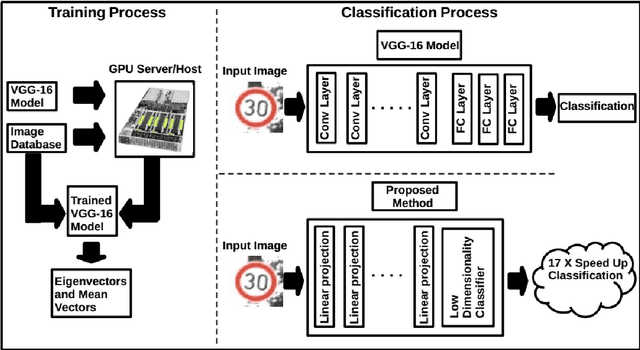
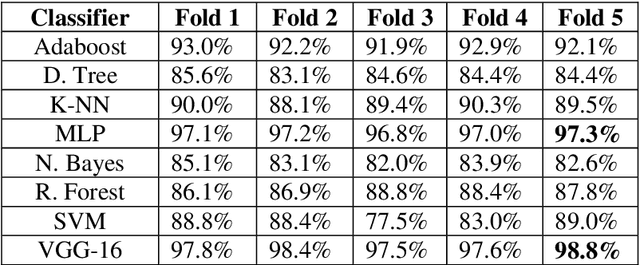
Computer vision plays a crucial role in Advanced Assistance Systems. Most computer vision systems are based on Deep Convolutional Neural Networks (deep CNN) architectures. However, the high computational resource to run a CNN algorithm is demanding. Therefore, the methods to speed up computation have become a relevant research issue. Even though several works on architecture reduction found in the literature have not yet been achieved satisfactory results for embedded real-time system applications. This paper presents an alternative approach based on the Multilinear Feature Space (MFS) method resorting to transfer learning from large CNN architectures. The proposed method uses CNNs to generate feature maps, although it does not work as complexity reduction approach. After the training process, the generated features maps are used to create vector feature space. We use this new vector space to make projections of any new sample to classify them. Our method, named AMFC, uses the transfer learning from pre-trained CNN to reduce the classification time of new sample image, with minimal accuracy loss. Our method uses the VGG-16 model as the base CNN architecture for experiments; however, the method works with any similar CNN model. Using the well-known Vehicle Image Database and the German Traffic Sign Recognition Benchmark, we compared the classification time of the original VGG-16 model with the AMFC method, and our method is, on average, 17 times faster. The fast classification time reduces the computational and memory demands in embedded applications requiring a large CNN architecture.
KRNET: Image Denoising with Kernel Regulation Network
Oct 20, 2019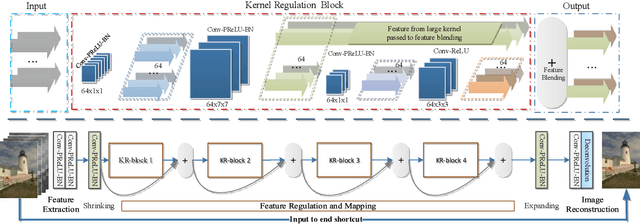



One popular strategy for image denoising is to design a generalized regularization term that is capable of exploring the implicit prior underlying data observation. Convolutional neural networks (CNN) have shown the powerful capability to learn image prior information through a stack of layers defined by a combination of kernels (filters) on the input. However, existing CNN-based methods mainly focus on synthetic gray-scale images. These methods still exhibit low performance when tackling multi-channel color image denoising. In this paper, we optimize CNN regularization capability by developing a kernel regulation module. In particular, we propose a kernel regulation network-block, referred to as KR-block, by integrating the merits of both large and small kernels, that can effectively estimate features in solving image denoising. We build a deep CNN-based denoiser, referred to as KRNET, via concatenating multiple KR-blocks. We evaluate KRNET on additive white Gaussian noise (AWGN), multi-channel (MC) noise, and realistic noise, where KRNET obtains significant performance gains over state-of-the-art methods across a wide spectrum of noise levels.
Low-resource Learning with Knowledge Graphs: A Comprehensive Survey
Dec 28, 2021
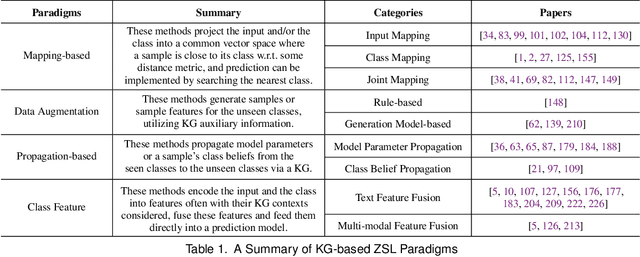
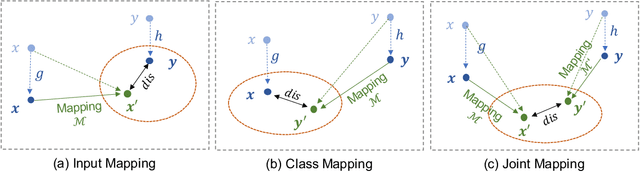
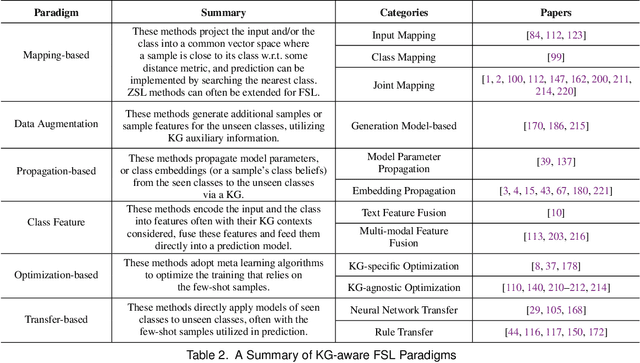
Machine learning methods especially deep neural networks have achieved great success but many of them often rely on a number of labeled samples for training. In real-world applications, we often need to address sample shortage due to e.g., dynamic contexts with emerging prediction targets and costly sample annotation. Therefore, low-resource learning, which aims to learn robust prediction models with no enough resources (especially training samples), is now being widely investigated. Among all the low-resource learning studies, many prefer to utilize some auxiliary information in the form of Knowledge Graph (KG), which is becoming more and more popular for knowledge representation, to reduce the reliance on labeled samples. In this survey, we very comprehensively reviewed over $90$ papers about KG-aware research for two major low-resource learning settings -- zero-shot learning (ZSL) where new classes for prediction have never appeared in training, and few-shot learning (FSL) where new classes for prediction have only a small number of labeled samples that are available. We first introduced the KGs used in ZSL and FSL studies as well as the existing and potential KG construction solutions, and then systematically categorized and summarized KG-aware ZSL and FSL methods, dividing them into different paradigms such as the mapping-based, the data augmentation, the propagation-based and the optimization-based. We next presented different applications, including not only KG augmented tasks in Computer Vision and Natural Language Processing (e.g., image classification, text classification and knowledge extraction), but also tasks for KG curation (e.g., inductive KG completion), and some typical evaluation resources for each task. We eventually discussed some challenges and future directions on aspects such as new learning and reasoning paradigms, and the construction of high quality KGs.
Homogeneous Learning: Self-Attention Decentralized Deep Learning
Oct 11, 2021
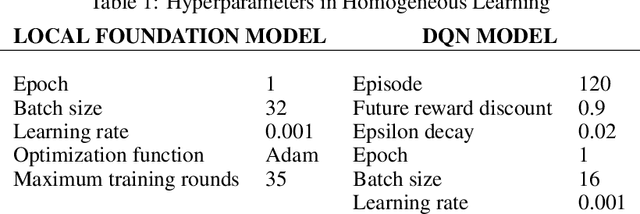
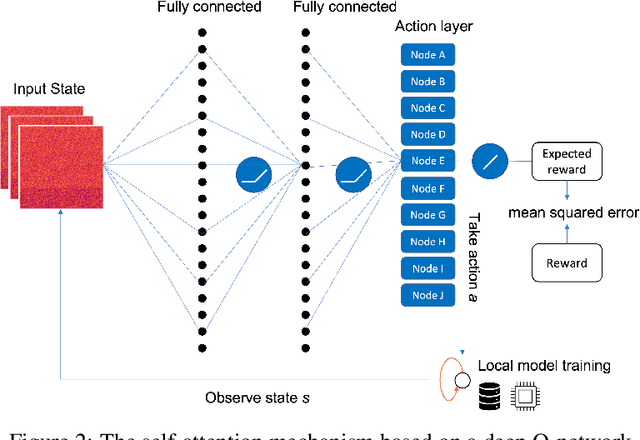
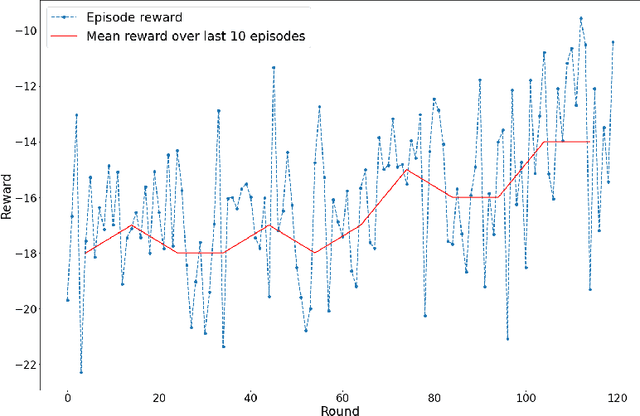
Federated learning (FL) has been facilitating privacy-preserving deep learning in many walks of life such as medical image classification, network intrusion detection, and so forth. Whereas it necessitates a central parameter server for model aggregation, which brings about delayed model communication and vulnerability to adversarial attacks. A fully decentralized architecture like Swarm Learning allows peer-to-peer communication among distributed nodes, without the central server. One of the most challenging issues in decentralized deep learning is that data owned by each node are usually non-independent and identically distributed (non-IID), causing time-consuming convergence of model training. To this end, we propose a decentralized learning model called Homogeneous Learning (HL) for tackling non-IID data with a self-attention mechanism. In HL, training performs on each round's selected node, and the trained model of a node is sent to the next selected node at the end of each round. Notably, for the selection, the self-attention mechanism leverages reinforcement learning to observe a node's inner state and its surrounding environment's state, and find out which node should be selected to optimize the training. We evaluate our method with various scenarios for an image classification task. The result suggests that HL can produce a better performance compared with standalone learning and greatly reduce both the total training rounds by 50.8% and the communication cost by 74.6% compared with random policy-based decentralized learning for training on non-IID data.
Don't Generate Me: Training Differentially Private Generative Models with Sinkhorn Divergence
Nov 29, 2021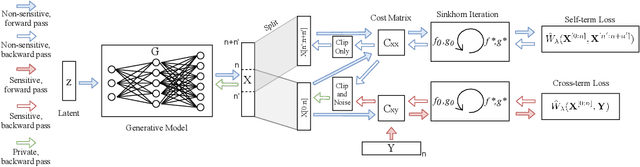
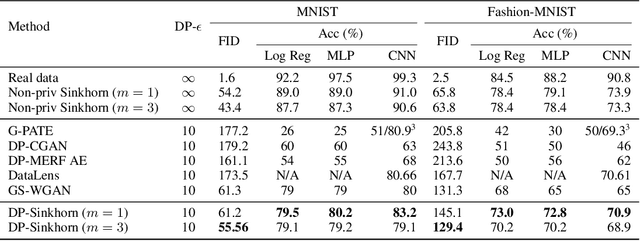

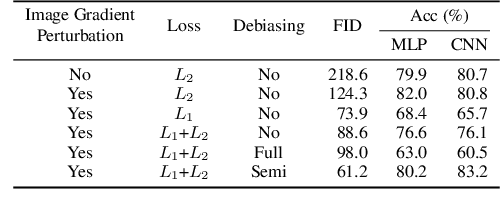
Although machine learning models trained on massive data have led to break-throughs in several areas, their deployment in privacy-sensitive domains remains limited due to restricted access to data. Generative models trained with privacy constraints on private data can sidestep this challenge, providing indirect access to private data instead. We propose DP-Sinkhorn, a novel optimal transport-based generative method for learning data distributions from private data with differential privacy. DP-Sinkhorn minimizes the Sinkhorn divergence, a computationally efficient approximation to the exact optimal transport distance, between the model and data in a differentially private manner and uses a novel technique for control-ling the bias-variance trade-off of gradient estimates. Unlike existing approaches for training differentially private generative models, which are mostly based on generative adversarial networks, we do not rely on adversarial objectives, which are notoriously difficult to optimize, especially in the presence of noise imposed by privacy constraints. Hence, DP-Sinkhorn is easy to train and deploy. Experimentally, we improve upon the state-of-the-art on multiple image modeling benchmarks and show differentially private synthesis of informative RGB images. Project page:https://nv-tlabs.github.io/DP-Sinkhorn.
HarmoFL: Harmonizing Local and Global Drifts in Federated Learning on Heterogeneous Medical Images
Dec 20, 2021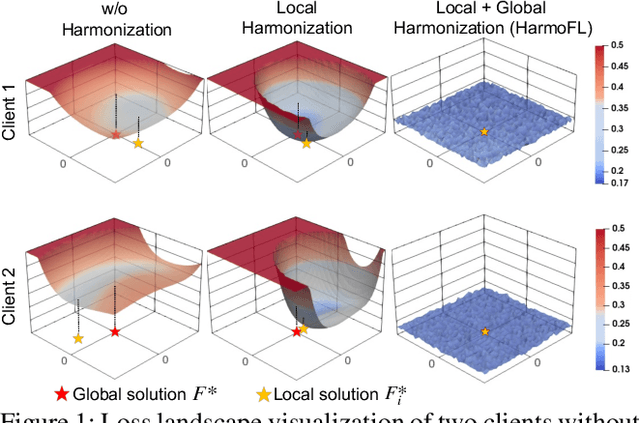
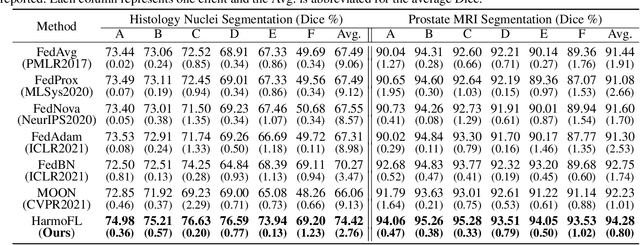
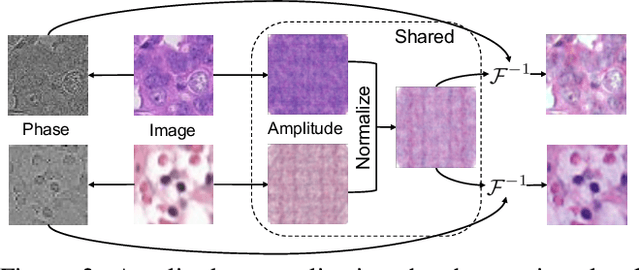
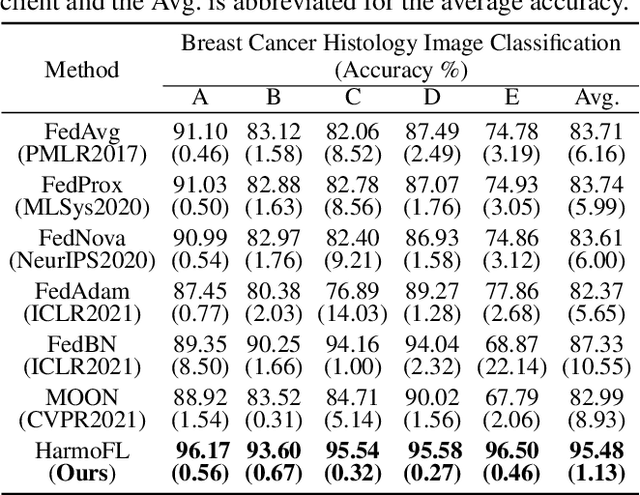
Multiple medical institutions collaboratively training a model using federated learning (FL) has become a promising solution for maximizing the potential of data-driven models, yet the non-independent and identically distributed (non-iid) data in medical images is still an outstanding challenge in real-world practice. The feature heterogeneity caused by diverse scanners or protocols introduces a drift in the learning process, in both local (client) and global (server) optimizations, which harms the convergence as well as model performance. Many previous works have attempted to address the non-iid issue by tackling the drift locally or globally, but how to jointly solve the two essentially coupled drifts is still unclear. In this work, we concentrate on handling both local and global drifts and introduce a new harmonizing framework called HarmoFL. First, we propose to mitigate the local update drift by normalizing amplitudes of images transformed into the frequency domain to mimic a unified imaging setting, in order to generate a harmonized feature space across local clients. Second, based on harmonized features, we design a client weight perturbation guiding each local model to reach a flat optimum, where a neighborhood area of the local optimal solution has a uniformly low loss. Without any extra communication cost, the perturbation assists the global model to optimize towards a converged optimal solution by aggregating several local flat optima. We have theoretically analyzed the proposed method and empirically conducted extensive experiments on three medical image classification and segmentation tasks, showing that HarmoFL outperforms a set of recent state-of-the-art methods with promising convergence behavior.
CNN Filter Learning from Drawn Markers for the Detection of Suggestive Signs of COVID-19 in CT Images
Nov 16, 2021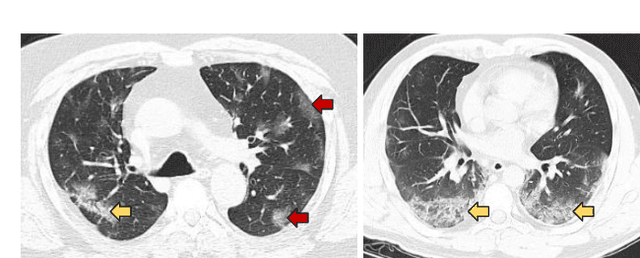
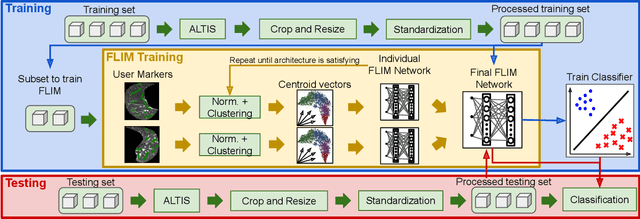
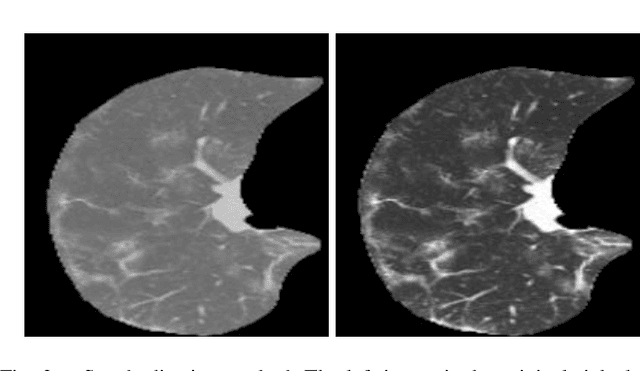

Early detection of COVID-19 is vital to control its spread. Deep learning methods have been presented to detect suggestive signs of COVID-19 from chest CT images. However, due to the novelty of the disease, annotated volumetric data are scarce. Here we propose a method that does not require either large annotated datasets or backpropagation to estimate the filters of a convolutional neural network (CNN). For a few CT images, the user draws markers at representative normal and abnormal regions. The method generates a feature extractor composed of a sequence of convolutional layers, whose kernels are specialized in enhancing regions similar to the marked ones, and the decision layer of our CNN is a support vector machine. As we have no control over the CT image acquisition, we also propose an intensity standardization approach. Our method can achieve mean accuracy and kappa values of $0.97$ and $0.93$, respectively, on a dataset with 117 CT images extracted from different sites, surpassing its counterpart in all scenarios.
Content-based image retrieval using Mix histogram
Sep 20, 2019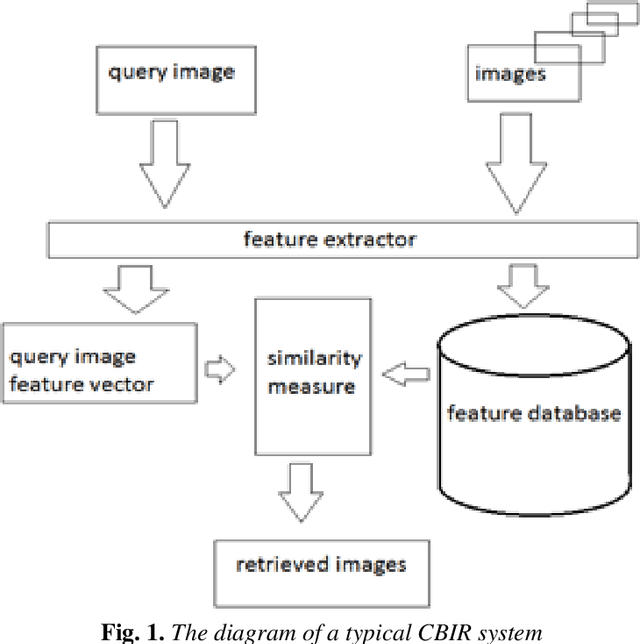
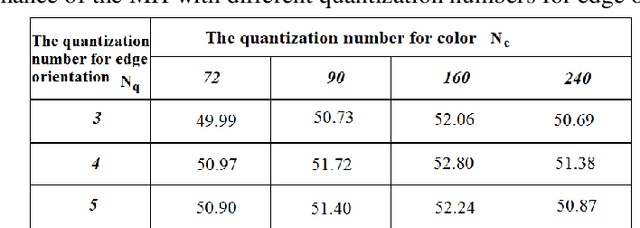
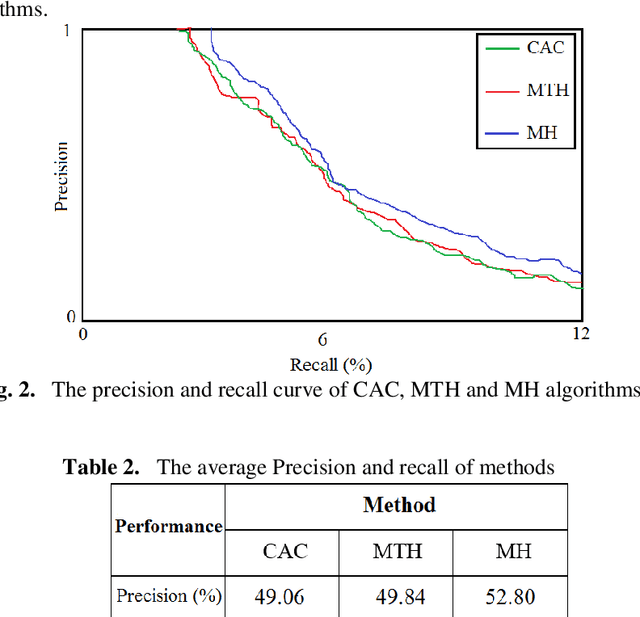

This paper presents a new method to extract image low-level features, namely mix histogram (MH), for content-based image retrieval. Since color and edge orientation features are important visual information which help the human visual system percept and discriminate different images, this method extracts and integrates color and edge orientation information in order to measure similarity between different images. Traditional color histograms merely focus on the global distribution of color in the image and therefore fail to extract other visual features. The MH is attempting to overcome this problem by extracting edge orientations as well as color feature. The unique characteristic of the MH is that it takes into consideration both color and edge orientation information in an effective manner. Experimental results show that it outperforms many existing methods which were originally developed for image retrieval purposes.