 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CondenseNeXt: An Ultra-Efficient Deep Neural Network for Embedded Systems
Dec 01, 2021
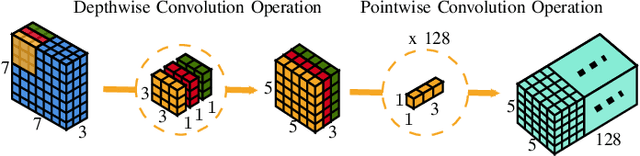
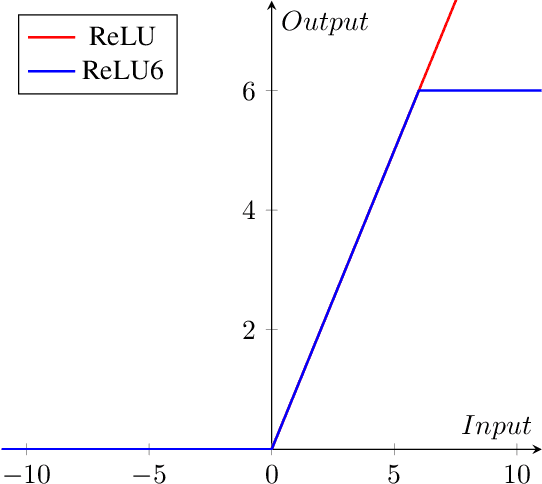
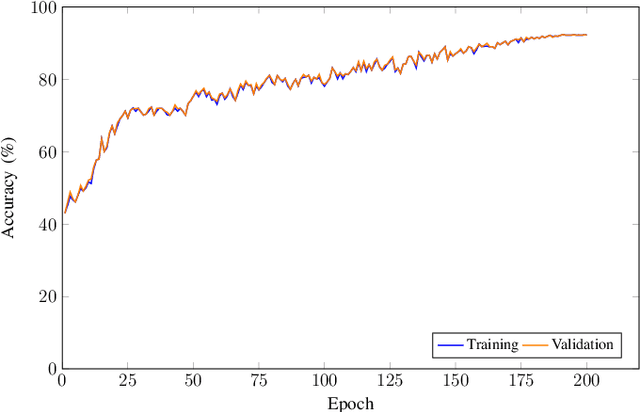

Due to the advent of modern embedded systems and mobile devices with constrained resources, there is a great demand for incredibly efficient deep neural networks for machine learning purposes. There is also a growing concern of privacy and confidentiality of user data within the general public when their data is processed and stored in an external server which has further fueled the need for developing such efficient neural networks for real-time inference on local embedded systems. The scope of our work presented in this paper is limited to image classification using a convolutional neural network. A Convolutional Neural Network (CNN) is a class of Deep Neural Network (DNN) widely used in the analysis of visual images captured by an image sensor, designed to extract information and convert it into meaningful representations for real-time inference of the input data. In this paper, we propose a neoteric variant of deep convolutional neural network architecture to ameliorate the performance of existing CNN architectures for real-time inference on embedded systems. We show that this architecture, dubbed CondenseNeXt, is remarkably efficient in comparison to the baseline neural network architecture, CondenseNet, by reducing trainable parameters and FLOPs required to train the network whilst maintaining a balance between the trained model size of less than 3.0 MB and accuracy trade-off resulting in an unprecedented computational efficiency.
AGA-GAN: Attribute Guided Attention Generative Adversarial Network with U-Net for Face Hallucination
Nov 20, 2021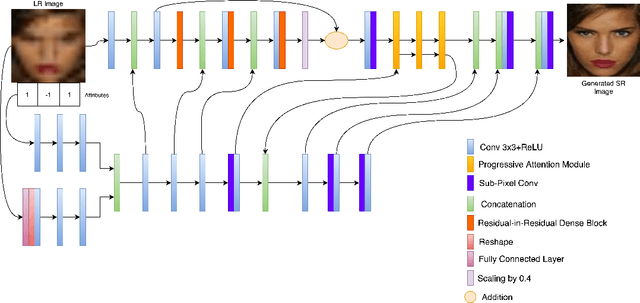
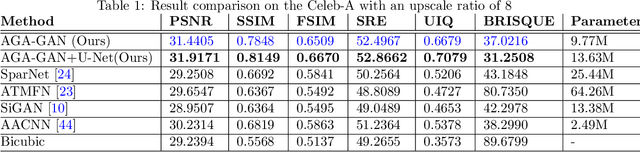
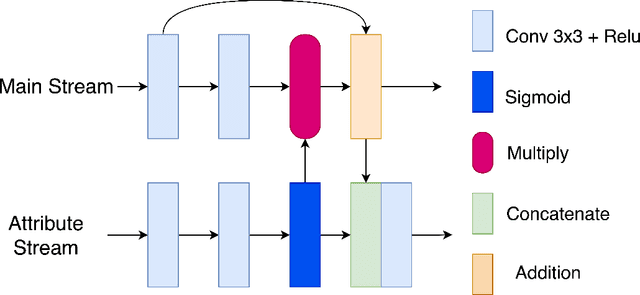
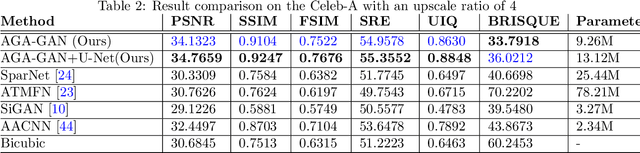
The performance of facial super-resolution methods relies on their ability to recover facial structures and salient features effectively. Even though the convolutional neural network and generative adversarial network-based methods deliver impressive performances on face hallucination tasks, the ability to use attributes associated with the low-resolution images to improve performance is unsatisfactory. In this paper, we propose an Attribute Guided Attention Generative Adversarial Network which employs novel attribute guided attention (AGA) modules to identify and focus the generation process on various facial features in the image. Stacking multiple AGA modules enables the recovery of both high and low-level facial structures. We design the discriminator to learn discriminative features exploiting the relationship between the high-resolution image and their corresponding facial attribute annotations. We then explore the use of U-Net based architecture to refine existing predictions and synthesize further facial details. Extensive experiments across several metrics show that our AGA-GAN and AGA-GAN+U-Net framework outperforms several other cutting-edge face hallucination state-of-the-art methods. We also demonstrate the viability of our method when every attribute descriptor is not known and thus, establishing its application in real-world scenarios.
Self-Supervised 3D Face Reconstruction via Conditional Estimation
Oct 10, 2021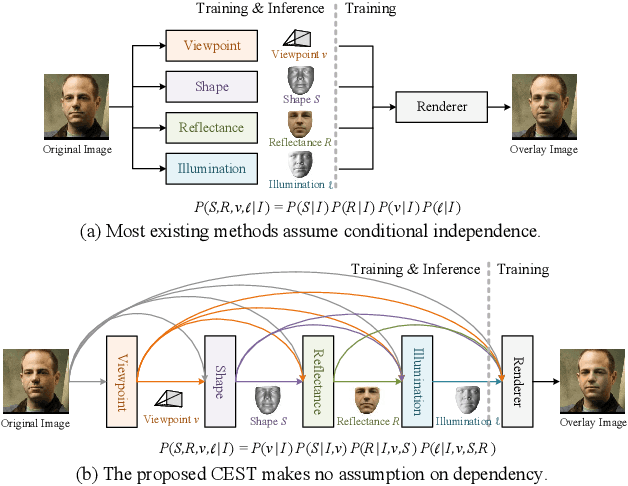

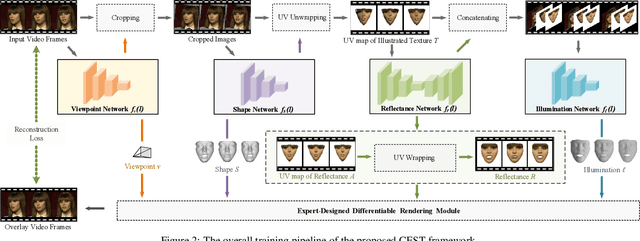
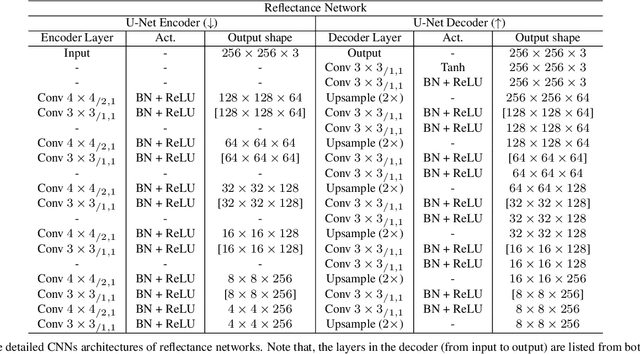
We present a conditional estimation (CEST) framework to learn 3D facial parameters from 2D single-view images by self-supervised training from videos. CEST is based on the process of analysis by synthesis, where the 3D facial parameters (shape, reflectance, viewpoint, and illumination) are estimated from the face image, and then recombined to reconstruct the 2D face image. In order to learn semantically meaningful 3D facial parameters without explicit access to their labels, CEST couples the estimation of different 3D facial parameters by taking their statistical dependency into account. Specifically, the estimation of any 3D facial parameter is not only conditioned on the given image, but also on the facial parameters that have already been derived. Moreover, the reflectance symmetry and consistency among the video frames are adopted to improve the disentanglement of facial parameters. Together with a novel strategy for incorporating the reflectance symmetry and consistency, CEST can be efficiently trained with in-the-wild video clips. Both qualitative and quantitative experiments demonstrate the effectiveness of CEST.
Self-Supervision based Task-Specific Image Collection Summarization
Dec 26, 2020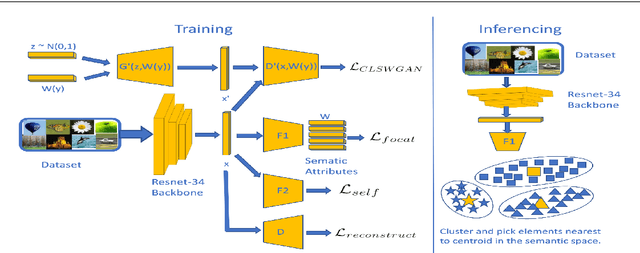
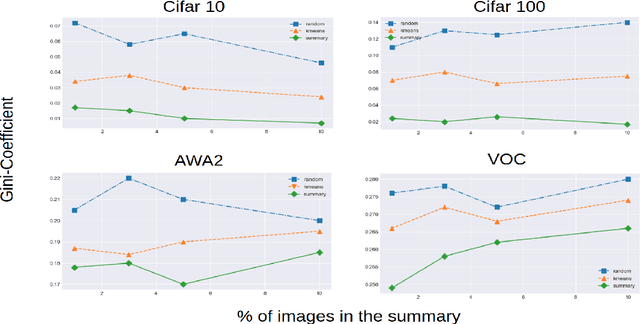
Successful applications of deep learning (DL) requires large amount of annotated data. This often restricts the benefits of employing DL to businesses and individuals with large budgets for data-collection and computation. Summarization offers a possible solution by creating much smaller representative datasets that can allow real-time deep learning and analysis of big data and thus democratize use of DL. In the proposed work, our aim is to explore a novel approach to task-specific image corpus summarization using semantic information and self-supervision. Our method uses a classification-based Wasserstein generative adversarial network (CLSWGAN) as a feature generating network. The model also leverages rotational invariance as self-supervision and classification on another task. All these objectives are added on a features from resnet34 to make it discriminative and robust. The model then generates a summary at inference time by using K-means clustering in the semantic embedding space. Thus, another main advantage of this model is that it does not need to be retrained each time to obtain summaries of different lengths which is an issue with current end-to-end models. We also test our model efficacy by means of rigorous experiments both qualitatively and quantitatively.
Self-supervised asymmetric deep hashing with margin-scalable constraint for image retrieval
Dec 07, 2020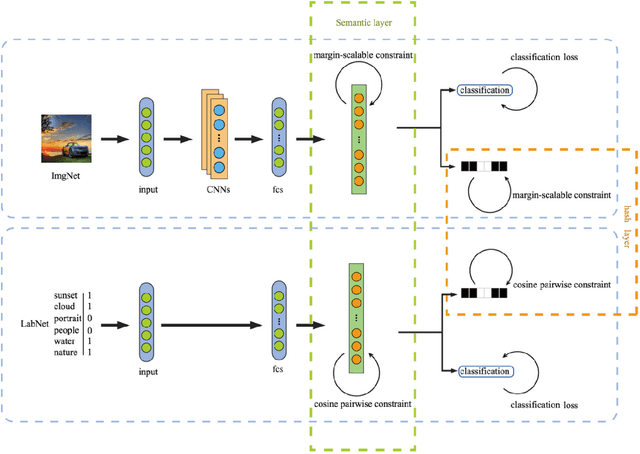
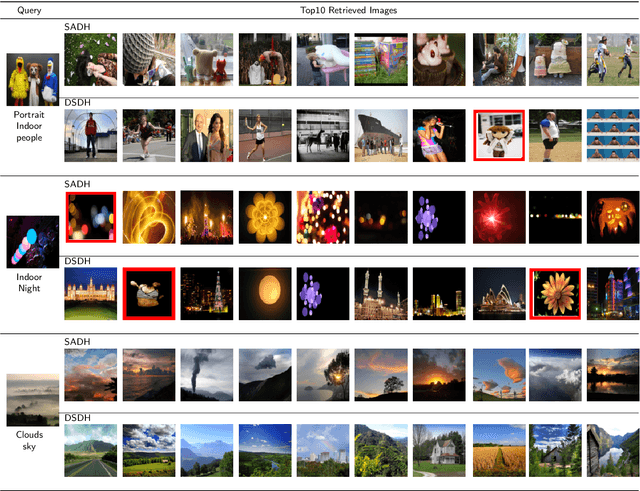
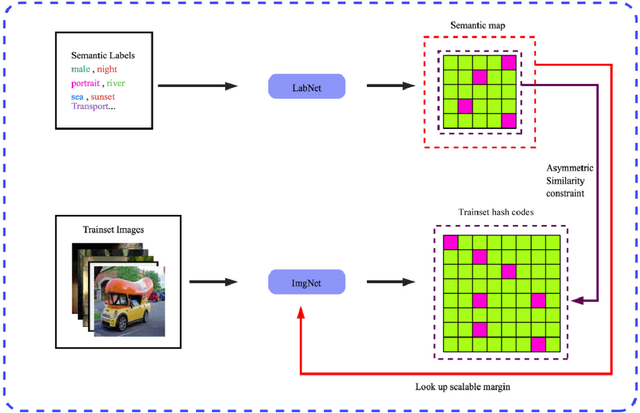
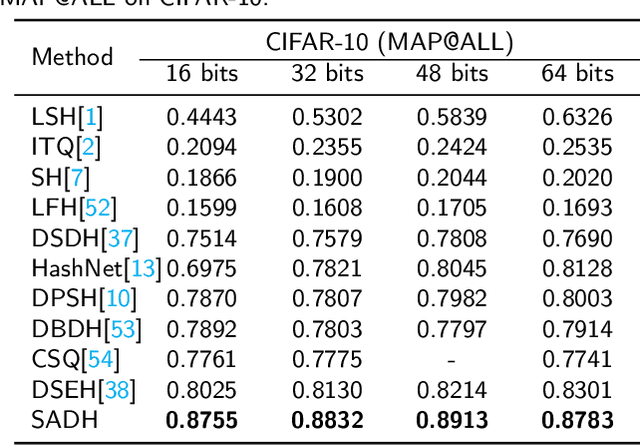
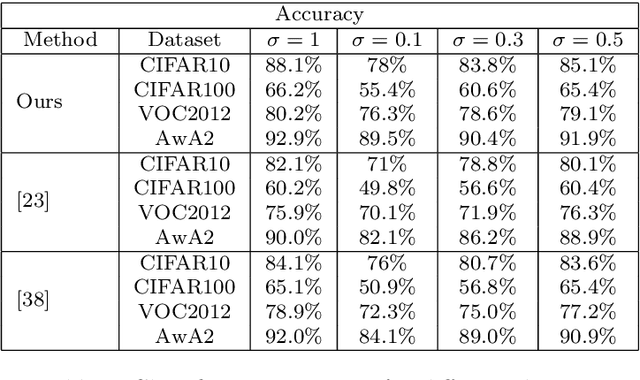
Due to its validity and rapidity, image retrieval based on deep hashing approaches is widely concerned especially in large-scale visual search. However, many existing deep hashing methods inadequately utilize label information as guidance of feature learning network without more advanced exploration in semantic space, besides the similarity correlations in hamming space are not fully discovered and embedded into hash codes, by which the retrieval quality is diminished with inefficient preservation of pairwise correlations and multi-label semantics. To cope with these problems, we propose a novel self-supervised asymmetric deep hashing with margin-scalable constraint(SADH) approach for image retrieval. SADH implements a self-supervised network to preserve supreme semantic information in a semantic feature map and a semantic code map for each semantics of the given dataset, which efficiently-and-precisely guides a feature learning network to preserve multi-label semantic information with asymmetric learning strategy. Moreover, for the feature learning part, by further exploiting semantic maps, a new margin-scalable constraint is employed for both highly-accurate construction of pairwise correlation in the hamming space and more discriminative hash code representation. Extensive empirical research on three benchmark datasets validate that the proposed method outperforms several state-of-the-art approaches.
Encouraging Disentangled and Convex Representation with Controllable Interpolation Regularization
Dec 06, 2021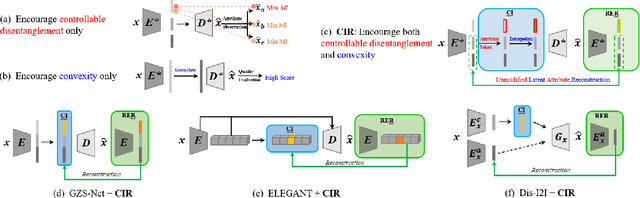
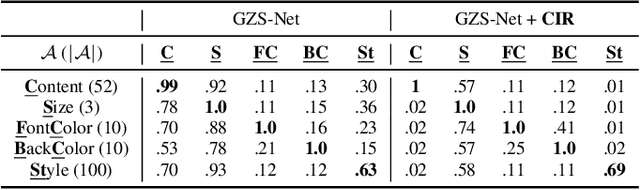

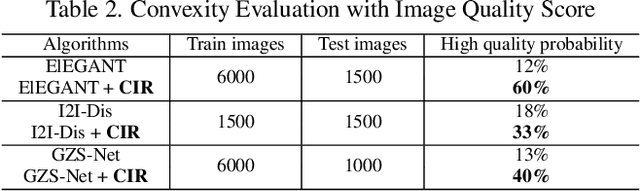
We focus on controllable disentangled representation learning (C-Dis-RL), where users can control the partition of the disentangled latent space to factorize dataset attributes (concepts) for downstream tasks. Two general problems remain under-explored in current methods: (1) They lack comprehensive disentanglement constraints, especially missing the minimization of mutual information between different attributes across latent and observation domains. (2) They lack convexity constraints in disentangled latent space, which is important for meaningfully manipulating specific attributes for downstream tasks. To encourage both comprehensive C-Dis-RL and convexity simultaneously, we propose a simple yet efficient method: Controllable Interpolation Regularization (CIR), which creates a positive loop where the disentanglement and convexity can help each other. Specifically, we conduct controlled interpolation in latent space during training and 'reuse' the encoder to help form a 'perfect disentanglement' regularization. In that case, (a) disentanglement loss implicitly enlarges the potential 'understandable' distribution to encourage convexity; (b) convexity can in turn improve robust and precise disentanglement. CIR is a general module and we merge CIR with three different algorithms: ELEGANT, I2I-Dis, and GZS-Net to show the compatibility and effectiveness. Qualitative and quantitative experiments show improvement in C-Dis-RL and latent convexity by CIR. This further improves downstream tasks: controllable image synthesis, cross-modality image translation and zero-shot synthesis. More experiments demonstrate CIR can also improve other downstream tasks, such as new attribute value mining, data augmentation, and eliminating bias for fairness.
Deep Joint Demosaicing and High Dynamic Range Imaging within a Single Shot
Nov 14, 2021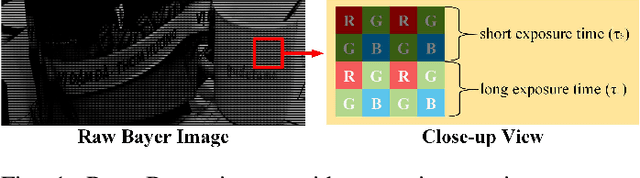
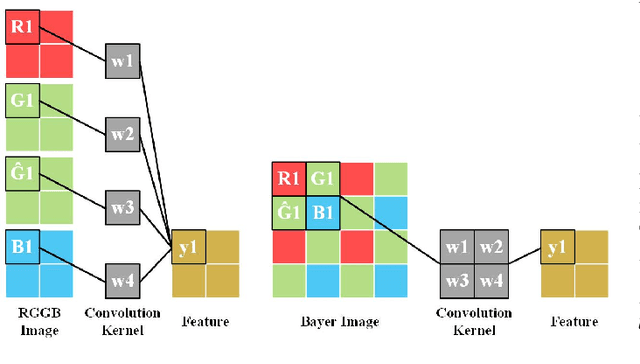


Spatially varying exposure (SVE) is a promising choice for high-dynamic-range (HDR) imaging (HDRI). The SVE-based HDRI, which is called single-shot HDRI, is an efficient solution to avoid ghosting artifacts. However, it is very challenging to restore a full-resolution HDR image from a real-world image with SVE because: a) only one-third of pixels with varying exposures are captured by camera in a Bayer pattern, b) some of the captured pixels are over- and under-exposed. For the former challenge, a spatially varying convolution (SVC) is designed to process the Bayer images carried with varying exposures. For the latter one, an exposure-guidance method is proposed against the interference from over- and under-exposed pixels. Finally, a joint demosaicing and HDRI deep learning framework is formalized to include the two novel components and to realize an end-to-end single-shot HDRI. Experiments indicate that the proposed end-to-end framework avoids the problem of cumulative errors and surpasses the related state-of-the-art methods.
Boundary Aware Learning for Out-of-distribution Detection
Jan 14, 2022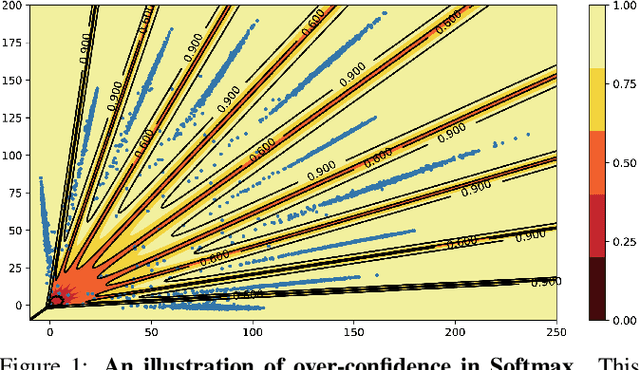
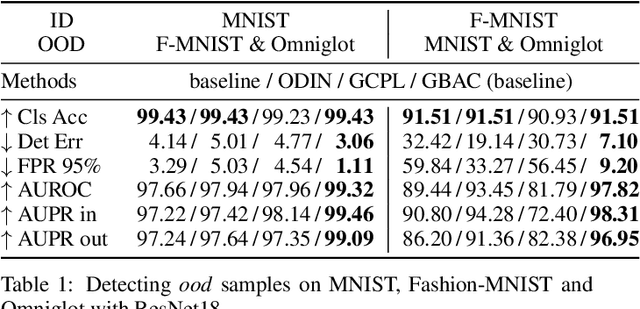
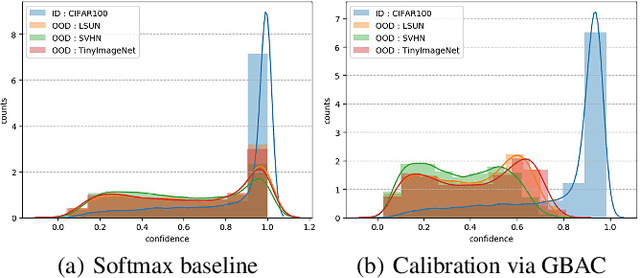
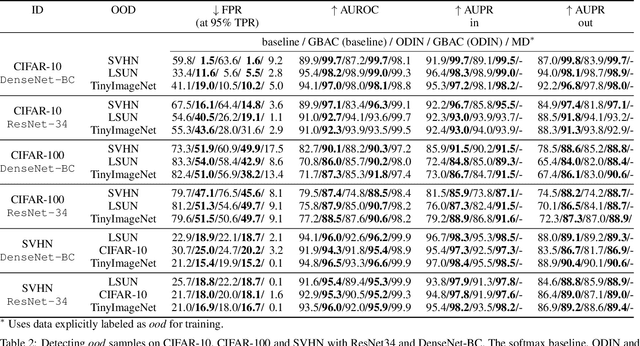
This paper focuses on the problem of detecting out-of-distribution (ood) samples with neural nets. In image recognition tasks, the trained classifier often gives high confidence score for input images which are remote from the in-distribution (id) data, and this has greatly limited its application in real world. For alleviating this problem, we propose a GAN based boundary aware classifier (GBAC) for generating a closed hyperspace which only contains most id data. Our method is based on the fact that the traditional neural net seperates the feature space as several unclosed regions which are not suitable for ood detection. With GBAC as an auxiliary module, the ood data distributed outside the closed hyperspace will be assigned with much lower score, allowing more effective ood detection while maintaining the classification performance. Moreover, we present a fast sampling method for generating hard ood representations which lie on the boundary of pre-mentioned closed hyperspace. Experiments taken on several datasets and neural net architectures promise the effectiveness of GBAC.
Zoom, Enhance! Measuring Surveillance GAN Up-sampling
Aug 20, 2021
Deep Neural Networks have been very successfully used for many computer vision and pattern recognition applications. While Convolutional Neural Networks(CNNs) have shown the path to state of art image classifications, Generative Adversarial Networks or GANs have provided state of art capabilities in image generation. In this paper we extend the applications of CNNs and GANs to experiment with up-sampling techniques in the domains of security and surveillance. Through this work we evaluate, compare and contrast the state of art techniques in both CNN and GAN based image and video up-sampling in the surveillance domain. As a result of this study we also provide experimental evidence to establish DISTS as a stronger Image Quality Assessment(IQA) metric for comparing GAN Based Image Up-sampling in the surveillance domain.
A Sneak Attack on Segmentation of Medical Images Using Deep Neural Network Classifiers
Jan 08, 2022
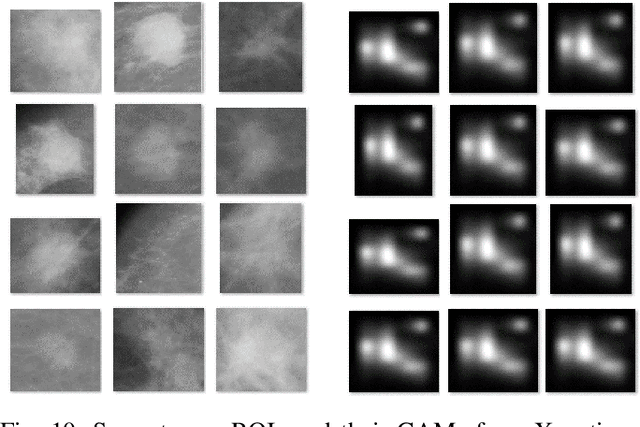
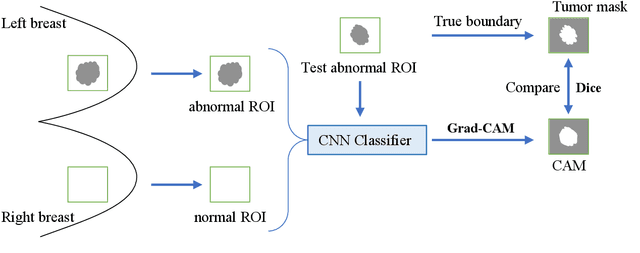
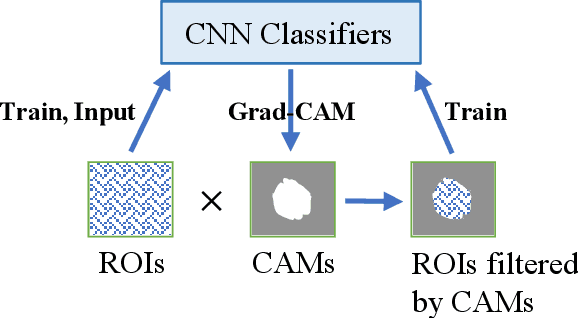
Instead of using current deep-learning segmentation models (like the UNet and variants), we approach the segmentation problem using trained Convolutional Neural Network (CNN) classifiers, which automatically extract important features from classified targets for image classification. Those extracted features can be visualized and formed heatmaps using Gradient-weighted Class Activation Mapping (Grad-CAM). This study tested whether the heatmaps could be used to segment the classified targets. We also proposed an evaluation method for the heatmaps; that is, to re-train the CNN classifier using images filtered by heatmaps and examine its performance. We used the mean-Dice coefficient to evaluate segmentation results. Results from our experiments show that heatmaps can locate and segment partial tumor areas. But only use of the heatmaps from CNN classifiers may not be an optimal approach for segmentation. In addition, we have verified that the predictions of CNN classifiers mainly depend on tumor areas, and dark regions in Grad-CAM's heatmaps also contribute to classification.