 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Underwater Image Enhancement Based on Structure-Texture Reconstruction
Apr 11, 2020
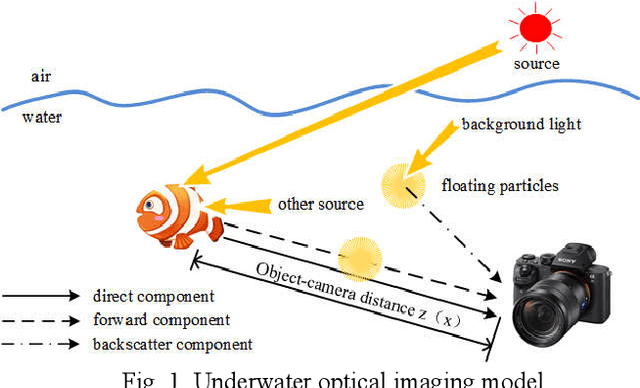

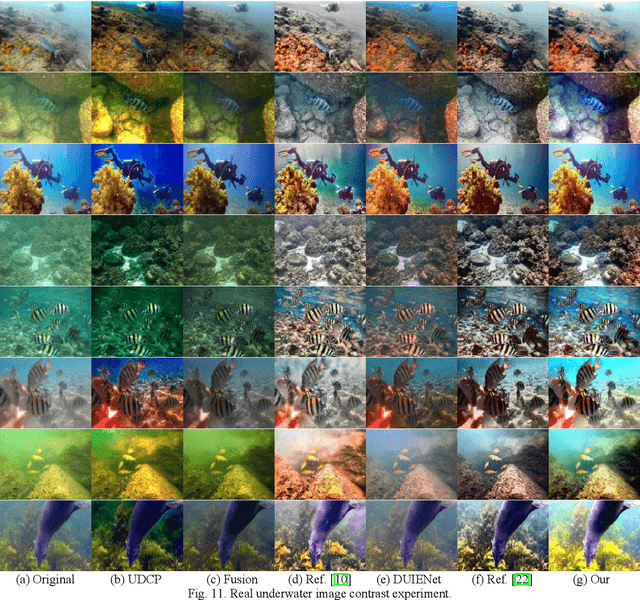

Aiming at the problems of color distortion, blur and excessive noise of underwater image, an underwater image enhancement algorithm based on structure-texture reconstruction is proposed. Firstly, the color equalization of the degraded image is realized by the automatic color enhancement algorithm; Secondly, the relative total variation is introduced to decompose the image into the structure layer and texture layer; Then, the best background light point is selected based on brightness, gradient discrimination, and hue judgment, the transmittance of the backscatter component is obtained by the red dark channel prior, which is substituted into the imaging model to remove the fogging phenomenon in the structure layer. Enhancement of effective details in the texture layer by multi scale detail enhancement algorithm and binary mask; Finally, the structure layer and texture layer are reconstructed to get the final image. The experimental results show that the algorithm can effectively balance the hue, saturation, and clarity of underwater image, and has good performance in different underwater environments.
Accelerating Translational Image Registration for HDR Images on GPU
Jul 13, 2020
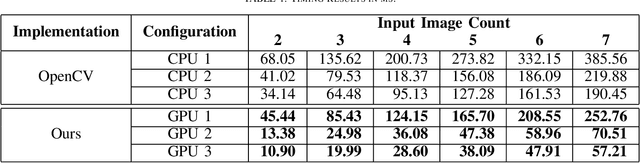

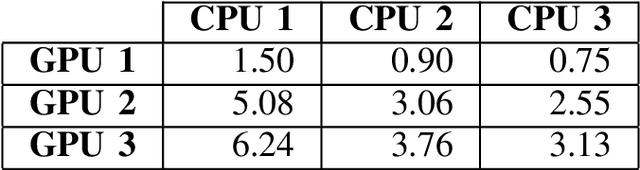
High Dynamic Range (HDR) images are generated using multiple exposures of a scene. When a hand-held camera is used to capture a static scene, these images need to be aligned by globally shifting each image in both dimensions. For a fast and robust alignment, the shift amount is commonly calculated using Median Threshold Bitmaps (MTB) and creating an image pyramid. In this study, we optimize these computations using a parallel processing approach utilizing GPU. Experimental evaluation shows that the proposed implementation achieves a speed-up of up to 6.24 times over the baseline multi-threaded CPU implementation on the alignment of one image pair. The source code is available at https://github.com/kadircenk/WardMTBCuda
High Perceptual Quality Image Denoising with a Posterior Sampling CGAN
Mar 06, 2021
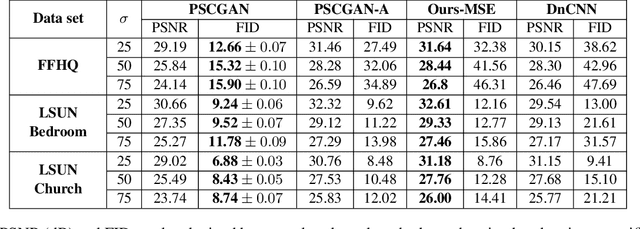

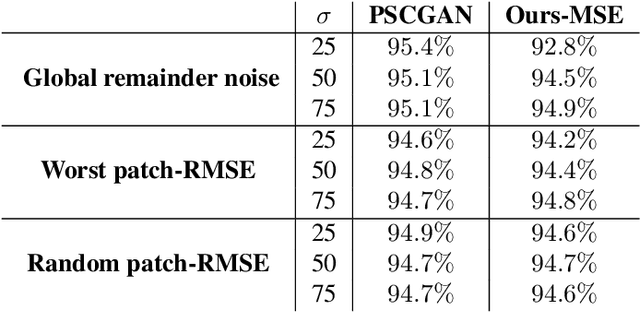
The vast work in Deep Learning (DL) has led to a leap in image denoising research. Most DL solutions for this task have chosen to put their efforts on the denoiser's architecture while maximizing distortion performance. However, distortion driven solutions lead to blurry results with sub-optimal perceptual quality, especially in immoderate noise levels. In this paper we propose a different perspective, aiming to produce sharp and visually pleasing denoised images that are still faithful to their clean sources. Formally, our goal is to achieve high perceptual quality with acceptable distortion. This is attained by a stochastic denoiser that samples from the posterior distribution, trained as a generator in the framework of conditional generative adversarial networks (CGANs). Contrary to distortion-based regularization terms that conflict with perceptual quality, we introduce to the CGANs objective a theoretically founded penalty term that does not force a distortion requirement on individual samples, but rather on their mean. We showcase our proposed method with a novel denoiser architecture that achieves the reformed denoising goal and produces vivid and diverse outcomes in immoderate noise levels.
DTGAN: Dual Attention Generative Adversarial Networks for Text-to-Image Generation
Nov 16, 2020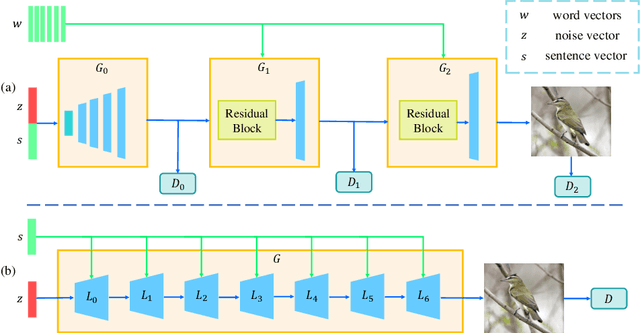
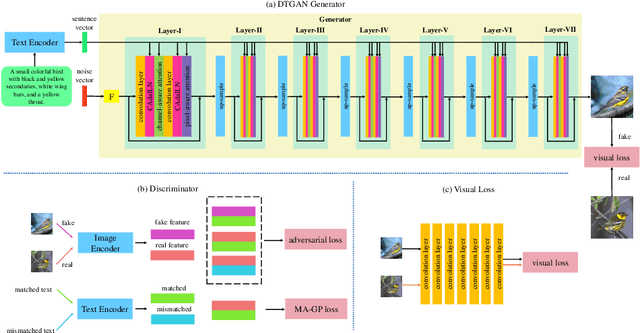
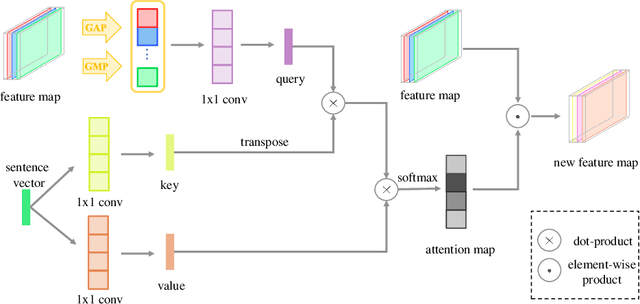
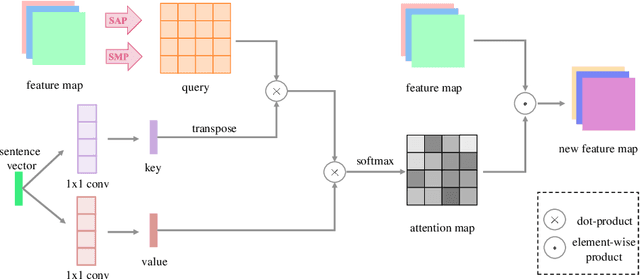
Most existing text-to-image generation methods adopt a multi-stage modular architecture which has three significant problems: 1) Training multiple networks increases the run time and affects the convergence and stability of the generative model; 2) These approaches ignore the quality of early-stage generator images; 3) Many discriminators need to be trained. To this end, we propose the Dual Attention Generative Adversarial Network (DTGAN) which can synthesize high-quality and semantically consistent images only employing a single generator/discriminator pair. The proposed model introduces channel-aware and pixel-aware attention modules that can guide the generator to focus on text-relevant channels and pixels based on the global sentence vector and to fine-tune original feature maps using attention weights. Also, Conditional Adaptive Instance-Layer Normalization (CAdaILN) is presented to help our attention modules flexibly control the amount of change in shape and texture by the input natural-language description. Furthermore, a new type of visual loss is utilized to enhance the image resolution by ensuring vivid shape and perceptually uniform color distributions of generated images. Experimental results on benchmark datasets demonstrate the superiority of our proposed method compared to the state-of-the-art models with a multi-stage framework. Visualization of the attention maps shows that the channel-aware attention module is able to localize the discriminative regions, while the pixel-aware attention module has the ability to capture the globally visual contents for the generation of an image.
Deep Iterative Residual Convolutional Network for Single Image Super-Resolution
Sep 07, 2020



Deep convolutional neural networks (CNNs) have recently achieved great success for single image super-resolution (SISR) task due to their powerful feature representation capabilities. The most recent deep learning based SISR methods focus on designing deeper / wider models to learn the non-linear mapping between low-resolution (LR) inputs and high-resolution (HR) outputs. These existing SR methods do not take into account the image observation (physical) model and thus require a large number of network's trainable parameters with a great volume of training data. To address these issues, we propose a deep Iterative Super-Resolution Residual Convolutional Network (ISRResCNet) that exploits the powerful image regularization and large-scale optimization techniques by training the deep network in an iterative manner with a residual learning approach. Extensive experimental results on various super-resolution benchmarks demonstrate that our method with a few trainable parameters improves the results for different scaling factors in comparison with the state-of-art methods.
End-to-end optimized image compression for multiple machine tasks
Mar 06, 2021
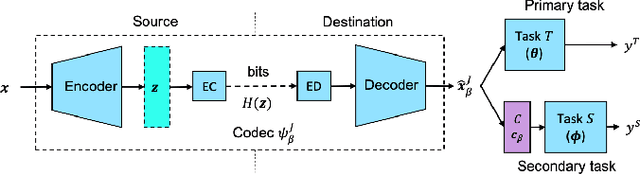
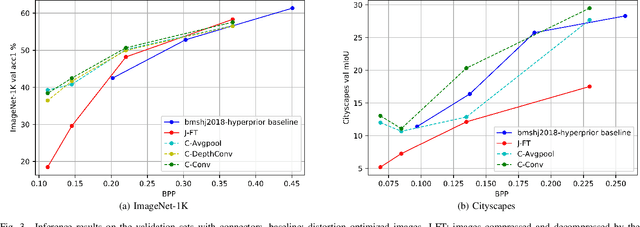
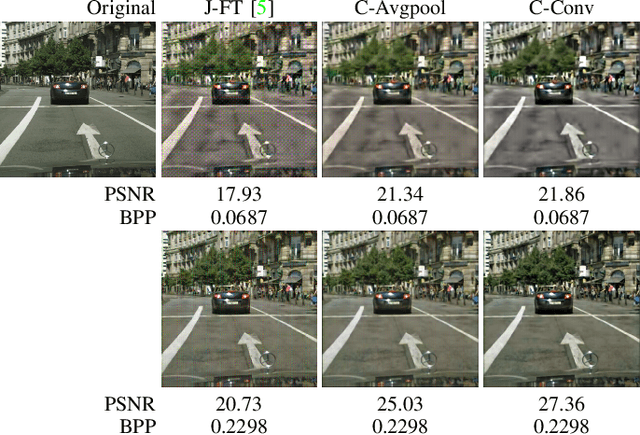
An increasing share of captured images and videos are transmitted for storage and remote analysis by computer vision algorithms, rather than to be viewed by humans. Contrary to traditional standard codecs with engineered tools, neural network based codecs can be trained end-to-end to optimally compress images with respect to a target rate and any given differentiable performance metric. Although it is possible to train such compression tools to achieve better rate-accuracy performance for a particular computer vision task, it could be practical and relevant to re-use the compressed bit-stream for multiple machine tasks. For this purpose, we introduce 'Connectors' that are inserted between the decoder and the task algorithms to enable a direct transformation of the compressed content, which was previously optimized for a specific task, to multiple other machine tasks. We demonstrate the effectiveness of the proposed method by achieving significant rate-accuracy performance improvement for both image classification and object segmentation, using the same bit-stream, originally optimized for object detection.
You Only Look Yourself: Unsupervised and Untrained Single Image Dehazing Neural Network
Jun 30, 2020
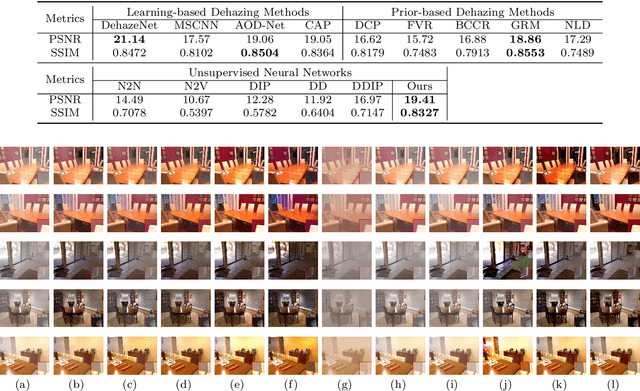
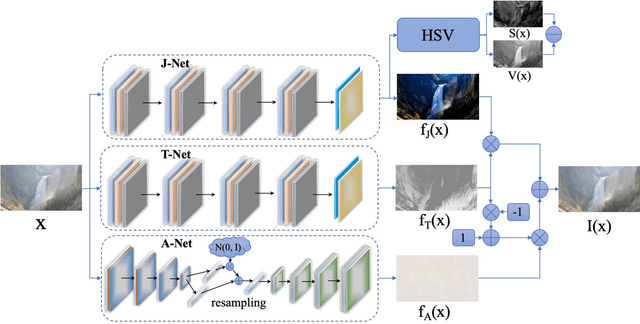
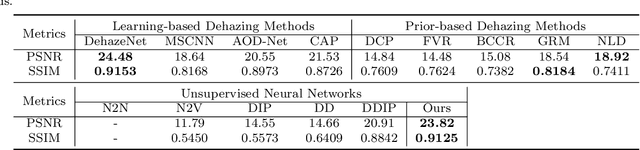
In this paper, we study two challenging and less-touched problems in single image dehazing, namely, how to make deep learning achieve image dehazing without training on the ground-truth clean image (unsupervised) and a image collection (untrained). An unsupervised neural network will avoid the intensive labor collection of hazy-clean image pairs, and an untrained model is a ``real'' single image dehazing approach which could remove haze based on only the observed hazy image itself and no extra images is used. Motivated by the layer disentanglement idea, we propose a novel method, called you only look yourself (\textbf{YOLY}) which could be one of the first unsupervised and untrained neural networks for image dehazing. In brief, YOLY employs three jointly subnetworks to separate the observed hazy image into several latent layers, \textit{i.e.}, scene radiance layer, transmission map layer, and atmospheric light layer. After that, these three layers are further composed to the hazy image in a self-supervised manner. Thanks to the unsupervised and untrained characteristics of YOLY, our method bypasses the conventional training paradigm of deep models on hazy-clean pairs or a large scale dataset, thus avoids the labor-intensive data collection and the domain shift issue. Besides, our method also provides an effective learning-based haze transfer solution thanks to its layer disentanglement mechanism. Extensive experiments show the promising performance of our method in image dehazing compared with 14 methods on four databases.
FacialGAN: Style Transfer and Attribute Manipulation on Synthetic Faces
Oct 18, 2021



Facial image manipulation is a generation task where the output face is shifted towards an intended target direction in terms of facial attribute and styles. Recent works have achieved great success in various editing techniques such as style transfer and attribute translation. However, current approaches are either focusing on pure style transfer, or on the translation of predefined sets of attributes with restricted interactivity. To address this issue, we propose FacialGAN, a novel framework enabling simultaneous rich style transfers and interactive facial attributes manipulation. While preserving the identity of a source image, we transfer the diverse styles of a target image to the source image. We then incorporate the geometry information of a segmentation mask to provide a fine-grained manipulation of facial attributes. Finally, a multi-objective learning strategy is introduced to optimize the loss of each specific tasks. Experiments on the CelebA-HQ dataset, with CelebAMask-HQ as semantic mask labels, show our model's capacity in producing visually compelling results in style transfer, attribute manipulation, diversity and face verification. For reproducibility, we provide an interactive open-source tool to perform facial manipulations, and the Pytorch implementation of the model.
SketchyCOCO: Image Generation from Freehand Scene Sketches
Mar 31, 2020
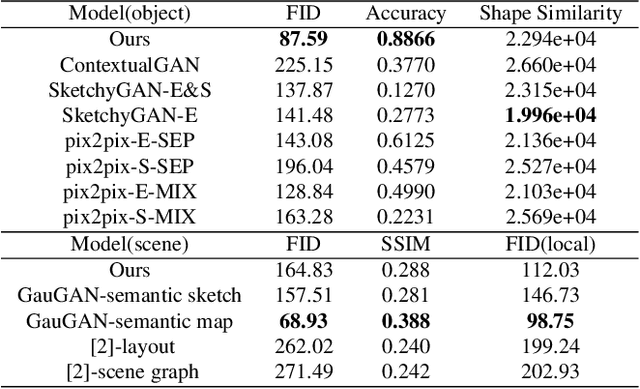
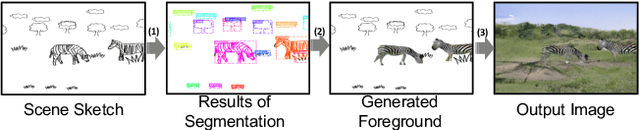
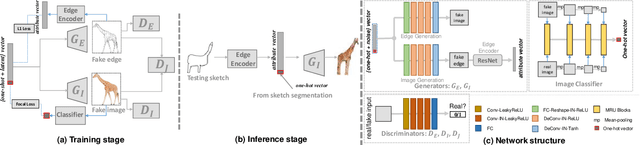
We introduce the first method for automatic image generation from scene-level freehand sketches. Our model allows for controllable image generation by specifying the synthesis goal via freehand sketches. The key contribution is an attribute vector bridged Generative Adversarial Network called EdgeGAN, which supports high visual-quality object-level image content generation without using freehand sketches as training data. We have built a large-scale composite dataset called SketchyCOCO to support and evaluate the solution. We validate our approach on the tasks of both object-level and scene-level image generation on SketchyCOCO. Through quantitative, qualitative results, human evaluation and ablation studies, we demonstrate the method's capacity to generate realistic complex scene-level images from various freehand sketches.
A Graph-Matching Approach for Cross-view Registration of Over-view 2 and Street-view based Point Clouds
Feb 14, 2022

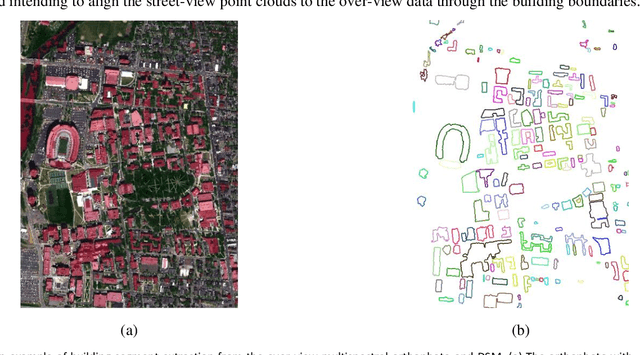

In this paper, based on the assumption that the object boundaries (e.g., buildings) from the over-view data should coincide with footprints of fa\c{c}ade 3D points generated from street-view photogrammetric images, we aim to address this problem by proposing a fully automated geo-registration method for cross-view data, which utilizes semantically segmented object boundaries as view-invariant features under a global optimization framework through graph-matching: taking the over-view point clouds generated from stereo/multi-stereo satellite images and the street-view point clouds generated from monocular video images as the inputs, the proposed method models segments of buildings as nodes of graphs, both detected from the satellite-based and street-view based point clouds, thus to form the registration as a graph-matching problem to allow non-rigid matches; to enable a robust solution and fully utilize the topological relations between these segments, we propose to address the graph-matching problem on its conjugate graph solved through a belief-propagation algorithm. The matched nodes will be subject to a further optimization to allow precise-registration, followed by a constrained bundle adjustment on the street-view image to keep 2D29 3D consistencies, which yields well-registered street-view images and point clouds to the satellite point clouds.
* 24 pages, 12 figures