 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MedMNIST Classification Decathlon: A Lightweight AutoML Benchmark for Medical Image Analysis
Oct 28, 2020
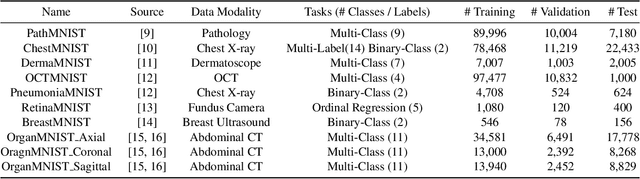
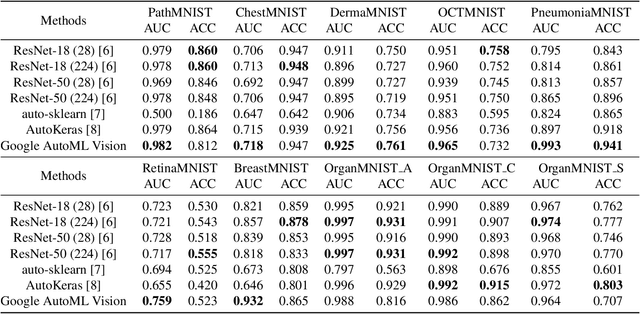

We present MedMNIST, a collection of 10 pre-processed medical open datasets. MedMNIST is standardized to perform classification tasks on lightweight 28x28 images, which requires no background knowledge. Covering the primary data modalities in medical image analysis, it is diverse on data scale (from 100 to 100,000) and tasks (binary/multi-class, ordinal regression and multi-label). MedMNIST could be used for educational purpose, rapid prototyping, multi-modal machine learning or AutoML in medical image analysis. Moreover, MedMNIST Classification Decathlon is designed to benchmark AutoML algorithms on all 10 datasets; We have compared several baseline methods, including open-source or commercial AutoML tools. The datasets, evaluation code and baseline methods for MedMNIST are publicly available at https://medmnist.github.io/.
Uncertainty-Aware Cascaded Dilation Filtering for High-Efficiency Deraining
Jan 07, 2022



Deraining is a significant and fundamental computer vision task, aiming to remove the rain streaks and accumulations in an image or video captured under a rainy day. Existing deraining methods usually make heuristic assumptions of the rain model, which compels them to employ complex optimization or iterative refinement for high recovery quality. This, however, leads to time-consuming methods and affects the effectiveness for addressing rain patterns deviated from from the assumptions. In this paper, we propose a simple yet efficient deraining method by formulating deraining as a predictive filtering problem without complex rain model assumptions. Specifically, we identify spatially-variant predictive filtering (SPFilt) that adaptively predicts proper kernels via a deep network to filter different individual pixels. Since the filtering can be implemented via well-accelerated convolution, our method can be significantly efficient. We further propose the EfDeRain+ that contains three main contributions to address residual rain traces, multi-scale, and diverse rain patterns without harming the efficiency. First, we propose the uncertainty-aware cascaded predictive filtering (UC-PFilt) that can identify the difficulties of reconstructing clean pixels via predicted kernels and remove the residual rain traces effectively. Second, we design the weight-sharing multi-scale dilated filtering (WS-MS-DFilt) to handle multi-scale rain streaks without harming the efficiency. Third, to eliminate the gap across diverse rain patterns, we propose a novel data augmentation method (i.e., RainMix) to train our deep models. By combining all contributions with sophisticated analysis on different variants, our final method outperforms baseline methods on four single-image deraining datasets and one video deraining dataset in terms of both recovery quality and speed.
DelTact: A Vision-based Tactile Sensor Using Dense Color Pattern
Feb 04, 2022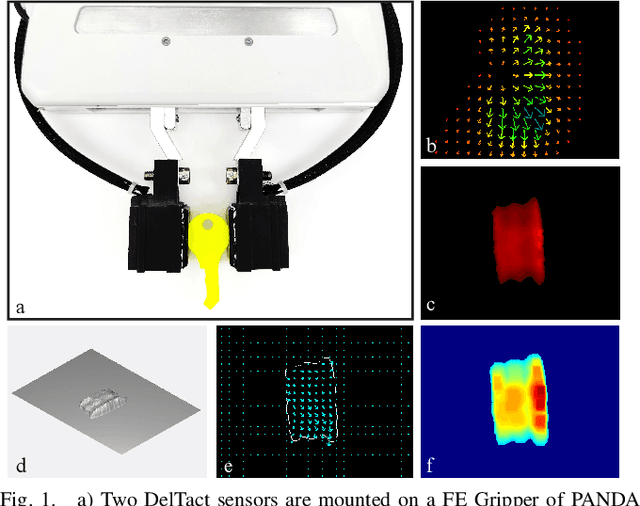
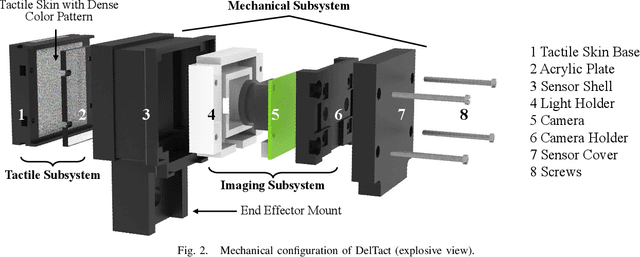

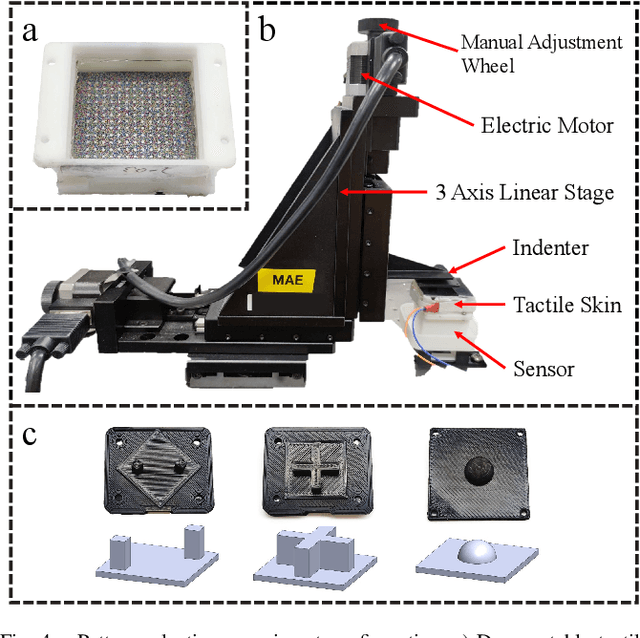
Tactile sensing is an essential perception for robots to complete dexterous tasks. As a promising tactile sensing technique, vision-based tactile sensors have been developed to improve robot manipulation performance. Here we propose a new design of our vision-based tactile sensor, DelTact, with its high-resolution sensing abilities of multiple modality surface contact information. The sensor adopts an improved dense random color pattern based on previous version, using a modular hardware architecture to achieve higher accuracy of contact deformation tracking whilst at the same time maintaining a compact and robust overall design. In particular, we optimized the color pattern generation process and selected the appropriate pattern for coordinating with a dense optical flow in a real-world experimental sensory setting using varied contact objects. A dense tactile flow was obtained from the raw image in order to determine shape and force distribution on the contact surface. This sensor can be easily integrated with a parallel gripper where experimental results using qualitative and quantitative analysis demonstrated that the sensor is capable of providing tactile measurements with high temporal and spatial resolution.
Beyond Image to Depth: Improving Depth Prediction using Echoes
Mar 15, 2021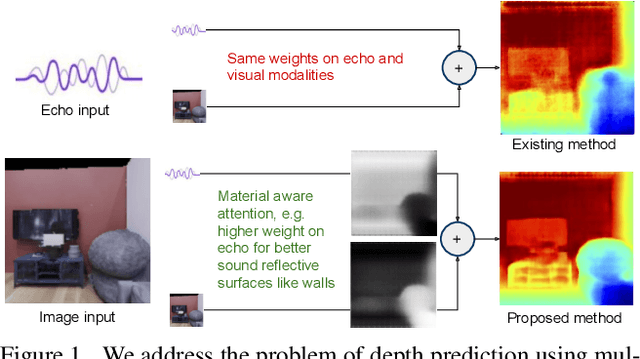
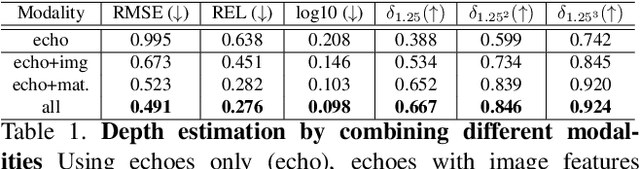
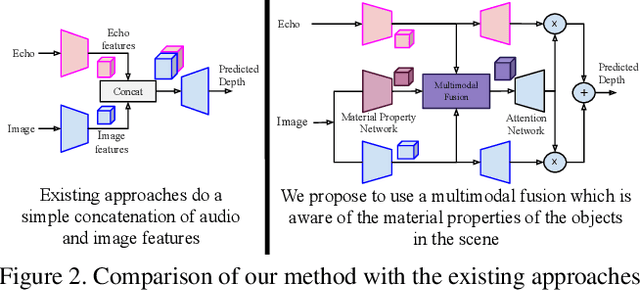
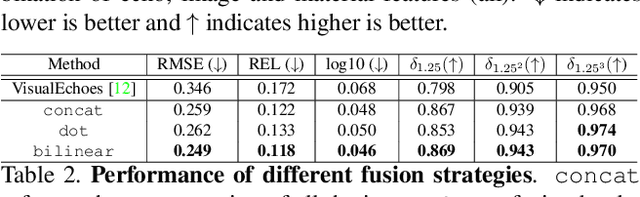
We address the problem of estimating depth with multi modal audio visual data. Inspired by the ability of animals, such as bats and dolphins, to infer distance of objects with echolocation, some recent methods have utilized echoes for depth estimation. We propose an end-to-end deep learning based pipeline utilizing RGB images, binaural echoes and estimated material properties of various objects within a scene. We argue that the relation between image, echoes and depth, for different scene elements, is greatly influenced by the properties of those elements, and a method designed to leverage this information can lead to significantly improve depth estimation from audio visual inputs. We propose a novel multi modal fusion technique, which incorporates the material properties explicitly while combining audio (echoes) and visual modalities to predict the scene depth. We show empirically, with experiments on Replica dataset, that the proposed method obtains 28% improvement in RMSE compared to the state-of-the-art audio-visual depth prediction method. To demonstrate the effectiveness of our method on larger dataset, we report competitive performance on Matterport3D, proposing to use it as a multimodal depth prediction benchmark with echoes for the first time. We also analyse the proposed method with exhaustive ablation experiments and qualitative results. The code and models are available at https://krantiparida.github.io/projects/bimgdepth.html
Screen Tracking for Clinical Translation of Live Ultrasound Image Analysis Methods
Jul 13, 2020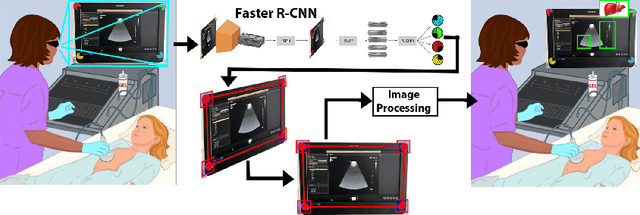
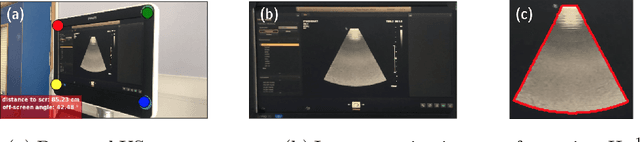
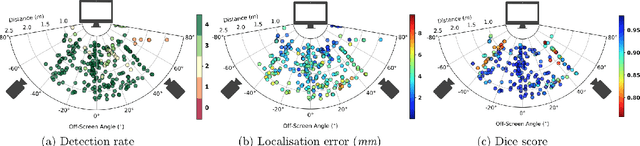
Ultrasound (US) imaging is one of the most commonly used non-invasive imaging techniques. However, US image acquisition requires simultaneous guidance of the transducer and interpretation of images, which is a highly challenging task that requires years of training. Despite many recent developments in intra-examination US image analysis, the results are not easy to translate to a clinical setting. We propose a generic framework to extract the US images and superimpose the results of an analysis task, without any need for physical connection or alteration to the US system. The proposed method captures the US image by tracking the screen with a camera fixed at the sonographer's view point and reformats the captured image to the right aspect ratio, in 87.66 +- 3.73ms on average. It is hypothesized that this would enable to input such retrieved image into an image processing pipeline to extract information that can help improve the examination. This information could eventually be projected back to the sonographer's field of view in real time using, for example, an augmented reality (AR) headset.
Saliency Enhancement using Superpixel Similarity
Dec 01, 2021
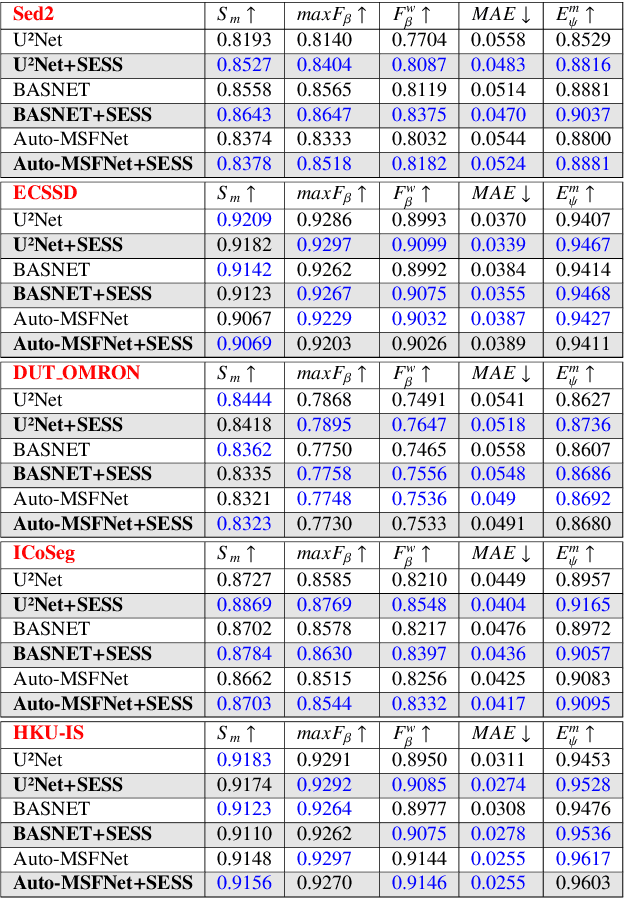

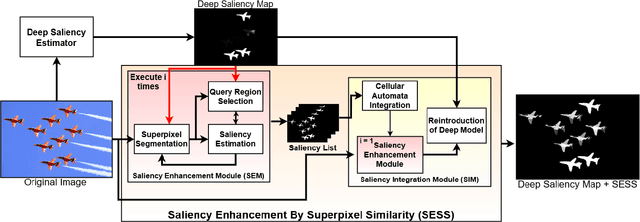
Saliency Object Detection (SOD) has several applications in image analysis. Deep-learning-based SOD methods are among the most effective, but they may miss foreground parts with similar colors. To circumvent the problem, we introduce a post-processing method, named \textit{Saliency Enhancement over Superpixel Similarity} (SESS), which executes two operations alternately for saliency completion: object-based superpixel segmentation and superpixel-based saliency estimation. SESS uses an input saliency map to estimate seeds for superpixel delineation and define superpixel queries in foreground and background. A new saliency map results from color similarities between queries and superpixels. The process repeats for a given number of iterations, such that all generated saliency maps are combined into a single one by cellular automata. Finally, post-processed and initial maps are merged using their average values per superpixel. We demonstrate that SESS can consistently and considerably improve the results of three deep-learning-based SOD methods on five image datasets.
Underwater Image Enhancement Based on Structure-Texture Reconstruction
Apr 11, 2020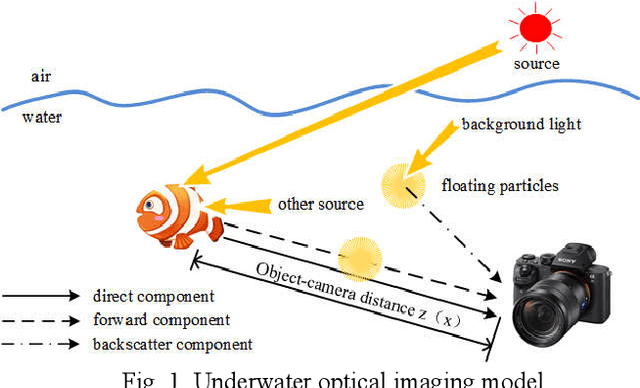

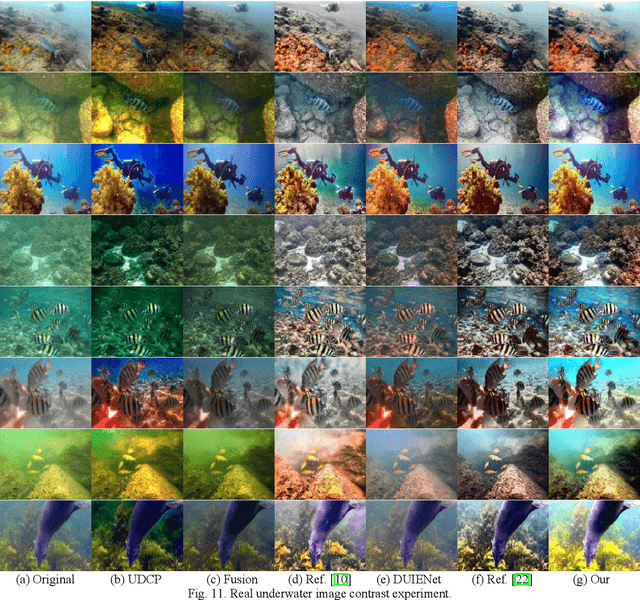

Aiming at the problems of color distortion, blur and excessive noise of underwater image, an underwater image enhancement algorithm based on structure-texture reconstruction is proposed. Firstly, the color equalization of the degraded image is realized by the automatic color enhancement algorithm; Secondly, the relative total variation is introduced to decompose the image into the structure layer and texture layer; Then, the best background light point is selected based on brightness, gradient discrimination, and hue judgment, the transmittance of the backscatter component is obtained by the red dark channel prior, which is substituted into the imaging model to remove the fogging phenomenon in the structure layer. Enhancement of effective details in the texture layer by multi scale detail enhancement algorithm and binary mask; Finally, the structure layer and texture layer are reconstructed to get the final image. The experimental results show that the algorithm can effectively balance the hue, saturation, and clarity of underwater image, and has good performance in different underwater environments.
FaceTuneGAN: Face Autoencoder for Convolutional Expression Transfer Using Neural Generative Adversarial Networks
Dec 01, 2021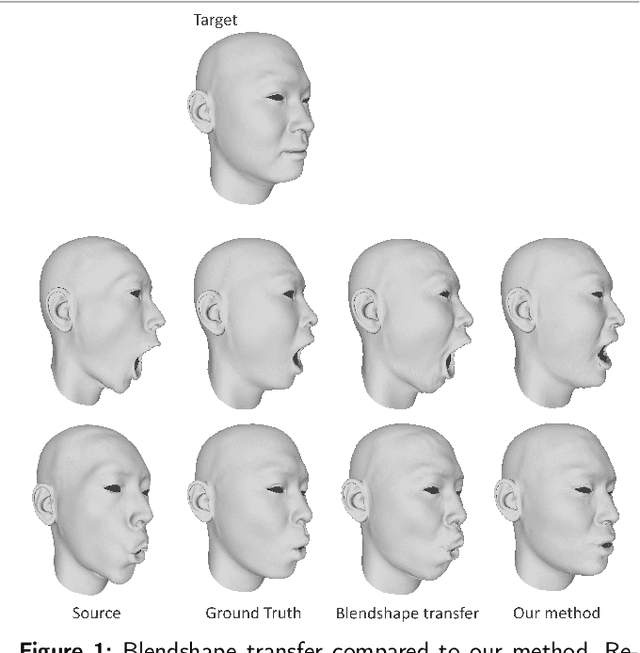

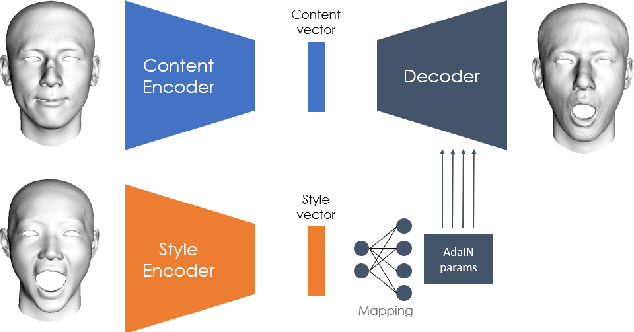
In this paper, we present FaceTuneGAN, a new 3D face model representation decomposing and encoding separately facial identity and facial expression. We propose a first adaptation of image-to-image translation networks, that have successfully been used in the 2D domain, to 3D face geometry. Leveraging recently released large face scan databases, a neural network has been trained to decouple factors of variations with a better knowledge of the face, enabling facial expressions transfer and neutralization of expressive faces. Specifically, we design an adversarial architecture adapting the base architecture of FUNIT and using SpiralNet++ for our convolutional and sampling operations. Using two publicly available datasets (FaceScape and CoMA), FaceTuneGAN has a better identity decomposition and face neutralization than state-of-the-art techniques. It also outperforms classical deformation transfer approach by predicting blendshapes closer to ground-truth data and with less of undesired artifacts due to too different facial morphologies between source and target.
Accelerating Translational Image Registration for HDR Images on GPU
Jul 13, 2020

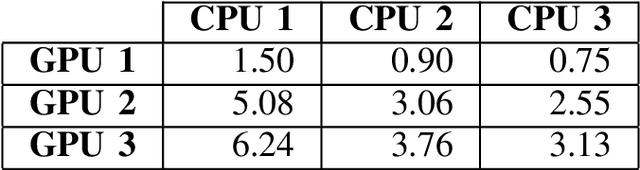
High Dynamic Range (HDR) images are generated using multiple exposures of a scene. When a hand-held camera is used to capture a static scene, these images need to be aligned by globally shifting each image in both dimensions. For a fast and robust alignment, the shift amount is commonly calculated using Median Threshold Bitmaps (MTB) and creating an image pyramid. In this study, we optimize these computations using a parallel processing approach utilizing GPU. Experimental evaluation shows that the proposed implementation achieves a speed-up of up to 6.24 times over the baseline multi-threaded CPU implementation on the alignment of one image pair. The source code is available at https://github.com/kadircenk/WardMTBCuda
Deep Iterative Residual Convolutional Network for Single Image Super-Resolution
Sep 07, 2020



Deep convolutional neural networks (CNNs) have recently achieved great success for single image super-resolution (SISR) task due to their powerful feature representation capabilities. The most recent deep learning based SISR methods focus on designing deeper / wider models to learn the non-linear mapping between low-resolution (LR) inputs and high-resolution (HR) outputs. These existing SR methods do not take into account the image observation (physical) model and thus require a large number of network's trainable parameters with a great volume of training data. To address these issues, we propose a deep Iterative Super-Resolution Residual Convolutional Network (ISRResCNet) that exploits the powerful image regularization and large-scale optimization techniques by training the deep network in an iterative manner with a residual learning approach. Extensive experimental results on various super-resolution benchmarks demonstrate that our method with a few trainable parameters improves the results for different scaling factors in comparison with the state-of-art methods.