 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TransFuse: Fusing Transformers and CNNs for Medical Image Segmentation
Feb 16, 2021
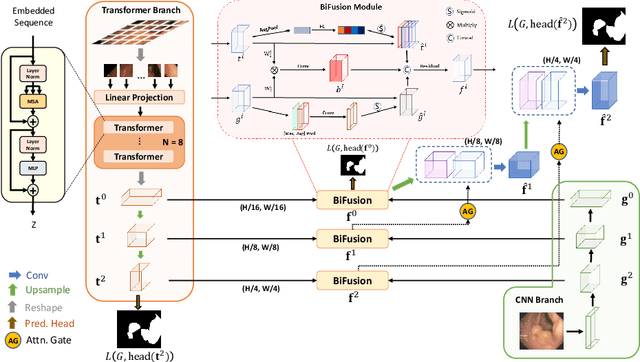
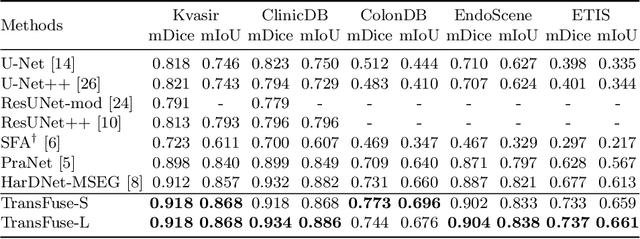
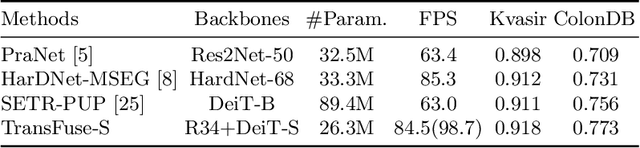
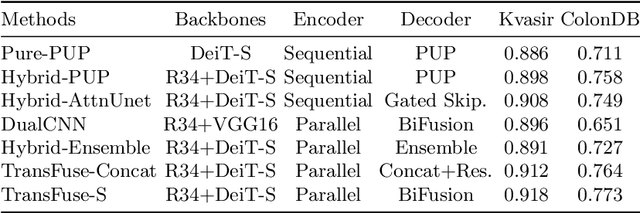
U-Net based convolutional neural networks with deep feature representation and skip-connections have significantly boosted the performance of medical image segmentation. In this paper, we study the more challenging problem of improving efficiency in modeling global contexts without losing localization ability for low-level details. TransFuse, a novel two-branch architecture is proposed, which combines Transformers and CNNs in a parallel style. With TransFuse, both global dependency and low-level spatial details can be efficiently captured in a much shallower manner. Besides, a novel fusion technique - BiFusion module is proposed to fuse the multi-level features from each branch. TransFuse achieves the newest state-of-the-arts on polyp segmentation task, with 20\% fewer parameters and the fastest inference speed at about 98.7 FPS.
Knowledge-enriched Attention Network with Group-wise Semantic for Visual Storytelling
Mar 10, 2022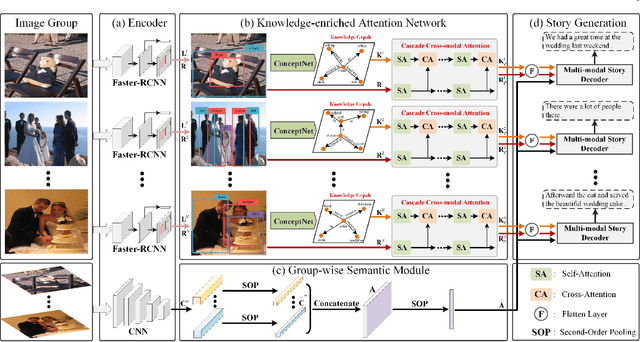
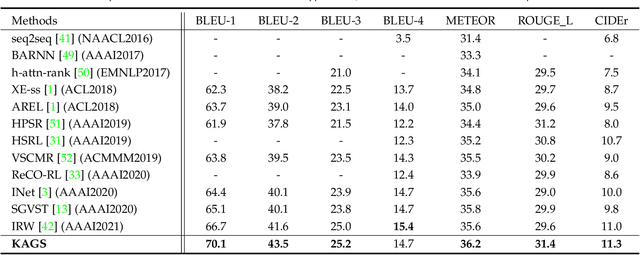
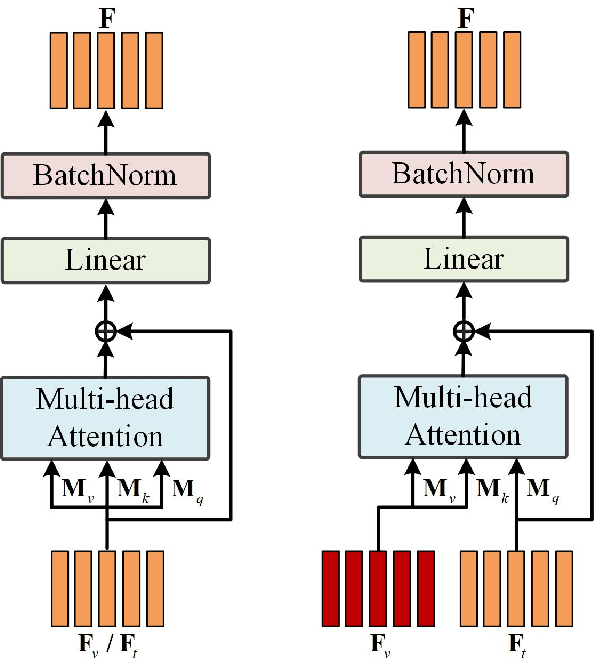
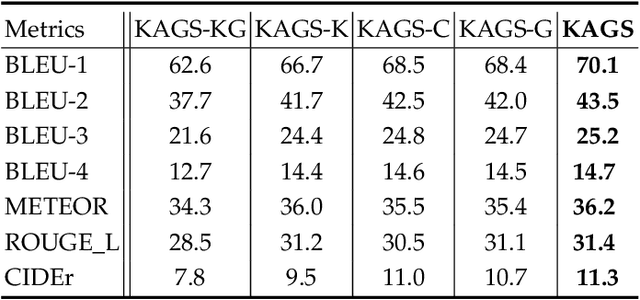
As a technically challenging topic, visual storytelling aims at generating an imaginary and coherent story with narrative multi-sentences from a group of relevant images. Existing methods often generate direct and rigid descriptions of apparent image-based contents, because they are not capable of exploring implicit information beyond images. Hence, these schemes could not capture consistent dependencies from holistic representation, impairing the generation of reasonable and fluent story. To address these problems, a novel knowledge-enriched attention network with group-wise semantic model is proposed. Three main novel components are designed and supported by substantial experiments to reveal practical advantages. First, a knowledge-enriched attention network is designed to extract implicit concepts from external knowledge system, and these concepts are followed by a cascade cross-modal attention mechanism to characterize imaginative and concrete representations. Second, a group-wise semantic module with second-order pooling is developed to explore the globally consistent guidance. Third, a unified one-stage story generation model with encoder-decoder structure is proposed to simultaneously train and infer the knowledge-enriched attention network, group-wise semantic module and multi-modal story generation decoder in an end-to-end fashion. Substantial experiments on the popular Visual Storytelling dataset with both objective and subjective evaluation metrics demonstrate the superior performance of the proposed scheme as compared with other state-of-the-art methods.
Semantic Example Guided Image-to-Image Translation
Oct 04, 2019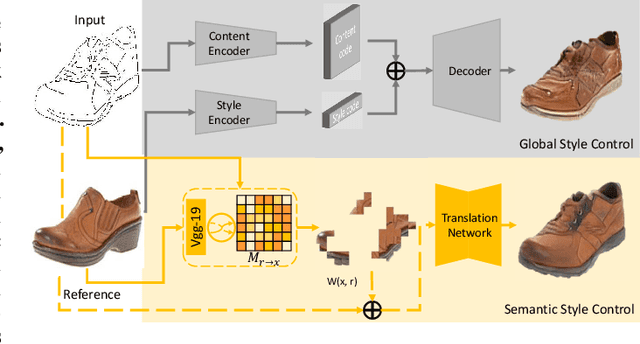


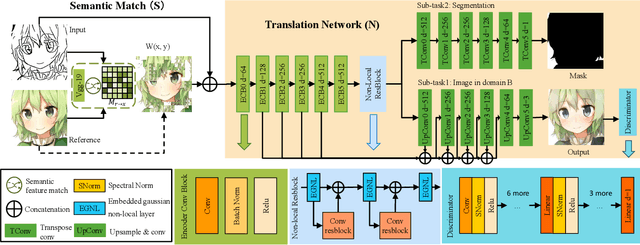
Many image-to-image (I2I) translation problems are in nature of high diversity that a single input may have various counterparts. Prior works proposed the multi-modal network that can build a many-to-many mapping between two visual domains. However, most of them are guided by sampled noises. Some others encode the reference images into a latent vector, by which the semantic information of the reference image will be washed away. In this work, we aim to provide a solution to control the output based on references semantically. Given a reference image and an input in another domain, a semantic matching is first performed between the two visual contents and generates the auxiliary image, which is explicitly encouraged to preserve semantic characteristics of the reference. A deep network then is used for I2I translation and the final outputs are expected to be semantically similar to both the input and the reference; however, no such paired data can satisfy that dual-similarity in a supervised fashion, so we build up a self-supervised framework to serve the training purpose. We improve the quality and diversity of the outputs by employing non-local blocks and a multi-task architecture. We assess the proposed method through extensive qualitative and quantitative evaluations and also presented comparisons with several state-of-art models.
When do GANs replicate? On the choice of dataset size
Feb 23, 2022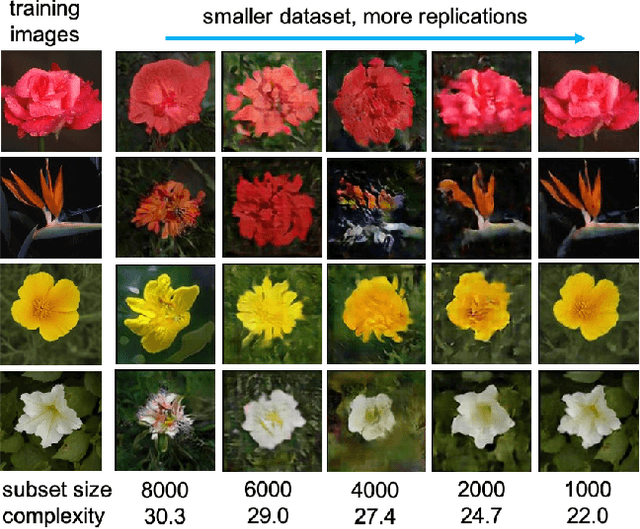


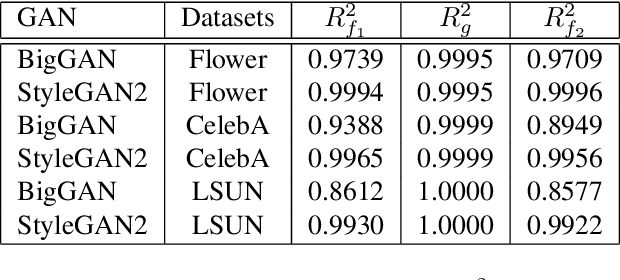
Do GANs replicate training images? Previous studies have shown that GANs do not seem to replicate training data without significant change in the training procedure. This leads to a series of research on the exact condition needed for GANs to overfit to the training data. Although a number of factors has been theoretically or empirically identified, the effect of dataset size and complexity on GANs replication is still unknown. With empirical evidence from BigGAN and StyleGAN2, on datasets CelebA, Flower and LSUN-bedroom, we show that dataset size and its complexity play an important role in GANs replication and perceptual quality of the generated images. We further quantify this relationship, discovering that replication percentage decays exponentially with respect to dataset size and complexity, with a shared decaying factor across GAN-dataset combinations. Meanwhile, the perceptual image quality follows a U-shape trend w.r.t dataset size. This finding leads to a practical tool for one-shot estimation on minimal dataset size to prevent GAN replication which can be used to guide datasets construction and selection.
Illiterate DALL-E Learns to Compose
Oct 27, 2021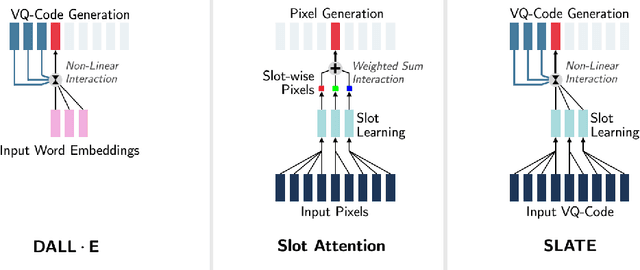
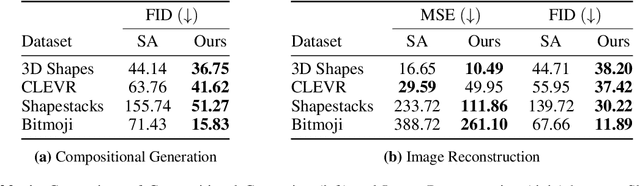
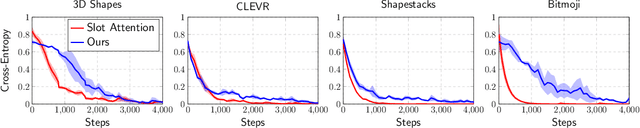

Although DALL-E has shown an impressive ability of composition-based systematic generalization in image generation, it requires the dataset of text-image pairs and the compositionality is provided by the text. In contrast, object-centric representation models like the Slot Attention model learn composable representations without the text prompt. However, unlike DALL-E its ability to systematically generalize for zero-shot generation is significantly limited. In this paper, we propose a simple but novel slot-based autoencoding architecture, called SLATE, for combining the best of both worlds: learning object-centric representations that allows systematic generalization in zero-shot image generation without text. As such, this model can also be seen as an illiterate DALL-E model. Unlike the pixel-mixture decoders of existing object-centric representation models, we propose to use the Image GPT decoder conditioned on the slots for capturing complex interactions among the slots and pixels. In experiments, we show that this simple and easy-to-implement architecture not requiring a text prompt achieves significant improvement in in-distribution and out-of-distribution (zero-shot) image generation and qualitatively comparable or better slot-attention structure than the models based on mixture decoders.
Universality of parametric Coupling Flows over parametric diffeomorphisms
Feb 08, 2022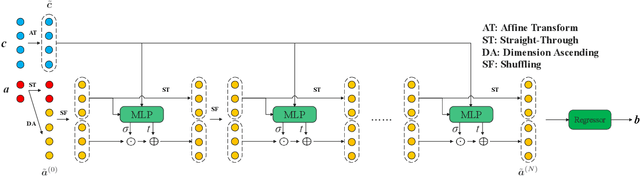

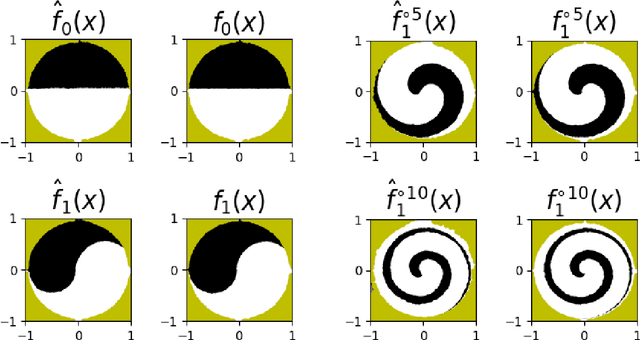

Invertible neural networks based on Coupling Flows CFlows) have various applications such as image synthesis and data compression. The approximation universality for CFlows is of paramount importance to ensure the model expressiveness. In this paper, we prove that CFlows can approximate any diffeomorphism in C^k-norm if its layers can approximate certain single-coordinate transforms. Specifically, we derive that a composition of affine coupling layers and invertible linear transforms achieves this universality. Furthermore, in parametric cases where the diffeomorphism depends on some extra parameters, we prove the corresponding approximation theorems for our proposed parametric coupling flows named Para-CFlows. In practice, we apply Para-CFlows as a neural surrogate model in contextual Bayesian optimization tasks, to demonstrate its superiority over other neural surrogate models in terms of optimization performance.
Improving Text to Image Generation using Mode-seeking Function
Sep 04, 2020
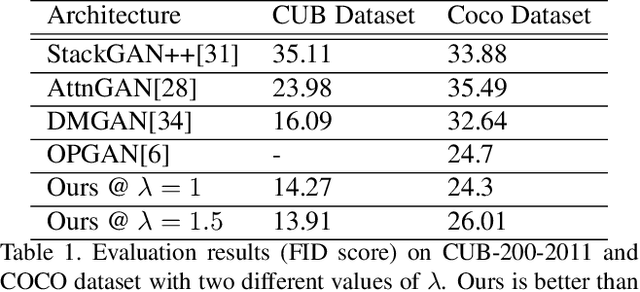


Generative Adversarial Networks (GANs) have long been used to understand the semantic relationship between the text and image. However, there are problems with mode collapsing in the image generation that causes some preferred output modes. Our aim is to improve the training of the network by using a specialized mode-seeking loss function to avoid this issue. In the text to image synthesis, our loss function differentiates two points in latent space for the generation of distinct images. We validate our model on the Caltech Birds (CUB) dataset and the Microsoft COCO dataset by changing the intensity of the loss function during the training. Experimental results demonstrate that our model works very well compared to some state-of-the-art approaches.
Efficient Transformer based Method for Remote Sensing Image Change Detection
Feb 27, 2021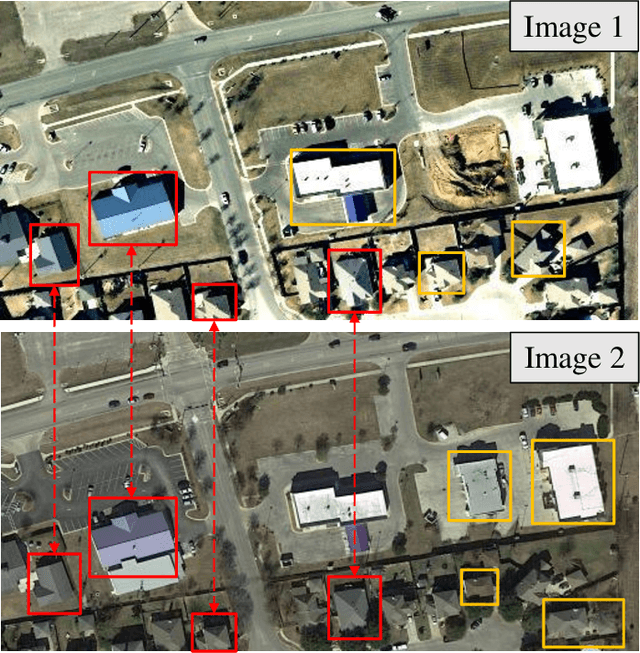
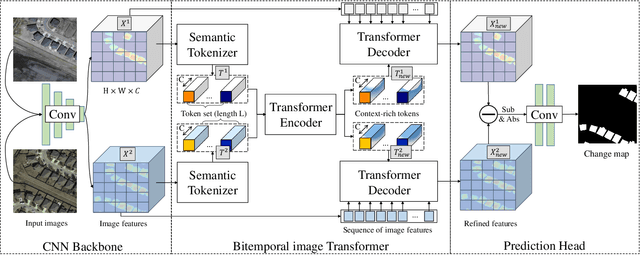
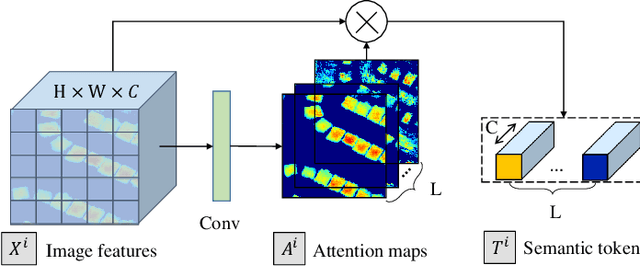
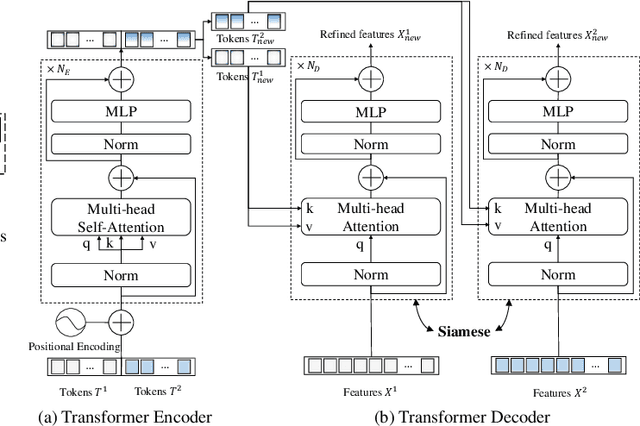
Modern change detection (CD) has achieved remarkable success by the powerful discriminative ability of deep convolutions. However, high-resolution remote sensing CD remains challenging due to the complexity of objects in the scene. The objects with the same semantic concept show distinct spectral behaviors at different times and different spatial locations. Modeling interactions between global semantic concepts is critical for change recognition. Most recent change detection pipelines using pure convolutions are still struggling to relate long-range concepts in space-time. Non-local self-attention approaches show promising performance via modeling dense relations among pixels, yet are computationally inefficient. In this paper, we propose a bitemporal image transformer (BiT) to efficiently and effectively model contexts within the spatial-temporal domain. Our intuition is that the high-level concepts of the change of interest can be represented by a few visual words, i.e., semantic tokens. To achieve this, we express the bitemporal image into a few tokens, and use a transformer encoder to model contexts in the compact token-based space-time. The learned context-rich tokens are then feedback to the pixel-space for refining the original features via a transformer decoder. We incorporate BiT in a deep feature differencing-based CD framework. Extensive experiments on three public CD datasets demonstrate the effectiveness and efficiency of the proposed method. Notably, our BiT-based model significantly outperforms the purely convolutional baseline using only 3 times lower computational costs and model parameters. Based on a naive backbone (ResNet18) without sophisticated structures (e.g., FPN, UNet), our model surpasses several state-of-the-art CD methods, including better than two recent attention-based methods in terms of efficiency and accuracy. Our code will be made public.
Cutting-edge 3D Medical Image Segmentation Methods in 2020: Are Happy Families All Alike?
Jan 01, 2021
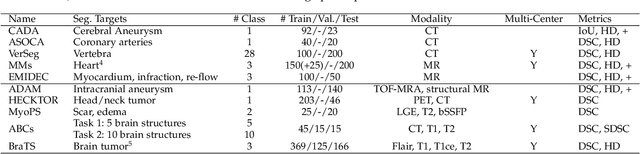
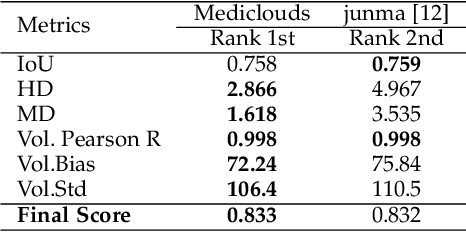
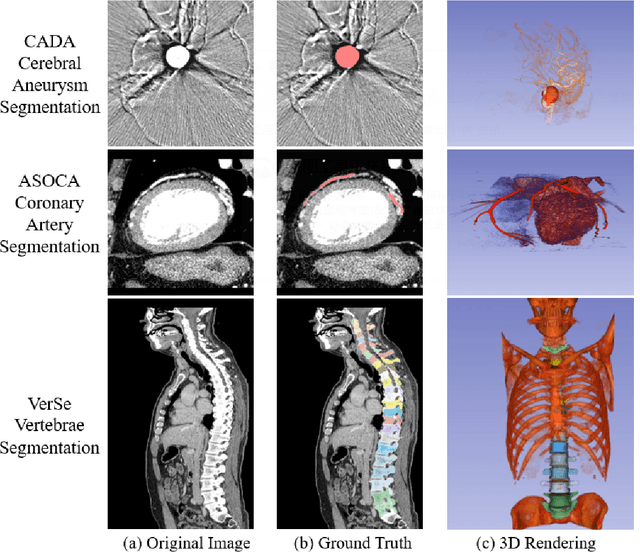
Segmentation is one of the most important and popular tasks in medical image analysis, which plays a critical role in disease diagnosis, surgical planning, and prognosis evaluation. During the past five years, on the one hand, thousands of medical image segmentation methods have been proposed for various organs and lesions in different medical images, which become more and more challenging to fairly compare different methods. On the other hand, international segmentation challenges can provide a transparent platform to fairly evaluate and compare different methods. In this paper, we present a comprehensive review of the top methods in ten 3D medical image segmentation challenges during 2020, covering a variety of tasks and datasets. We also identify the "happy-families" practices in the cutting-edge segmentation methods, which are useful for developing powerful segmentation approaches. Finally, we discuss open research problems that should be addressed in the future. We also maintain a list of cutting-edge segmentation methods at \url{https://github.com/JunMa11/SOTA-MedSeg}.
SSAT: A Symmetric Semantic-Aware Transformer Network for Makeup Transfer and Removal
Dec 07, 2021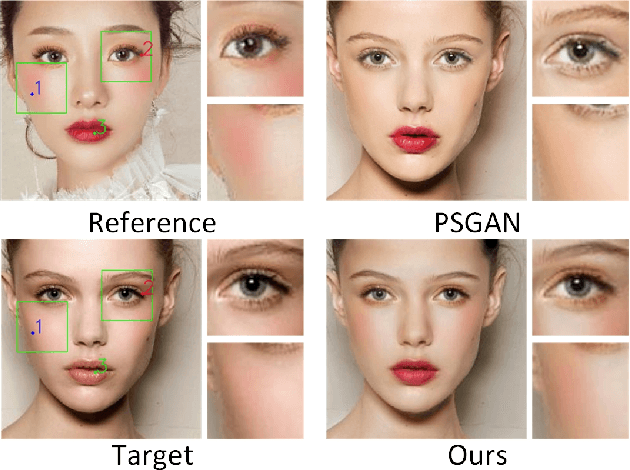
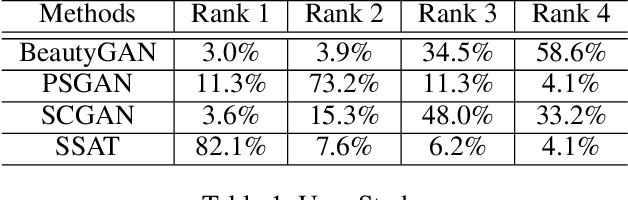
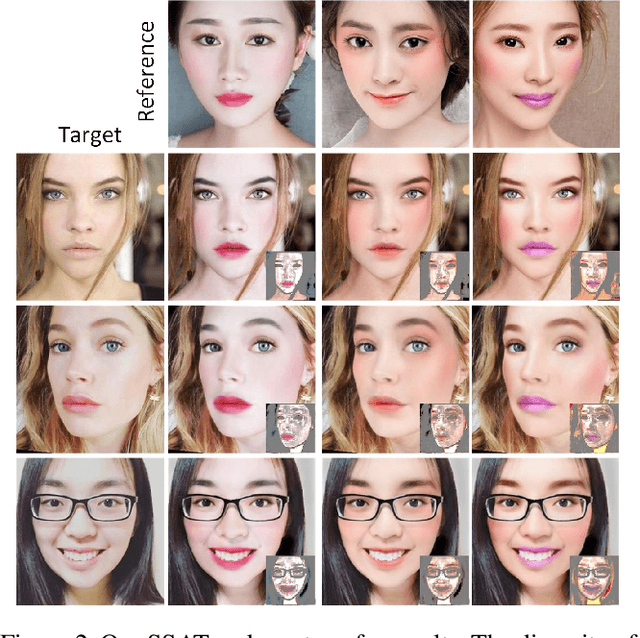
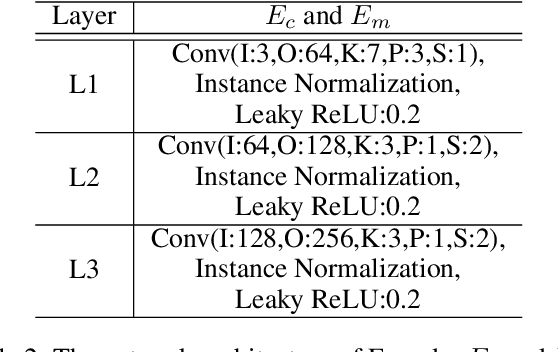
Makeup transfer is not only to extract the makeup style of the reference image, but also to render the makeup style to the semantic corresponding position of the target image. However, most existing methods focus on the former and ignore the latter, resulting in a failure to achieve desired results. To solve the above problems, we propose a unified Symmetric Semantic-Aware Transformer (SSAT) network, which incorporates semantic correspondence learning to realize makeup transfer and removal simultaneously. In SSAT, a novel Symmetric Semantic Corresponding Feature Transfer (SSCFT) module and a weakly supervised semantic loss are proposed to model and facilitate the establishment of accurate semantic correspondence. In the generation process, the extracted makeup features are spatially distorted by SSCFT to achieve semantic alignment with the target image, then the distorted makeup features are combined with unmodified makeup irrelevant features to produce the final result. Experiments show that our method obtains more visually accurate makeup transfer results, and user study in comparison with other state-of-the-art makeup transfer methods reflects the superiority of our method. Besides, we verify the robustness of the proposed method in the difference of expression and pose, object occlusion scenes, and extend it to video makeup transfer. Code will be available at https://gitee.com/sunzhaoyang0304/ssat-msp.