 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
UFA-FUSE: A novel deep supervised and hybrid model for multi-focus image fusion
Jan 12, 2021
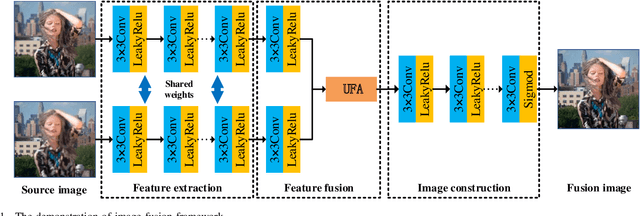
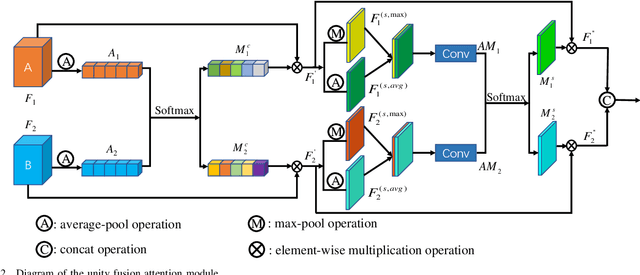


Traditional and deep learning-based fusion methods generated the intermediate decision map to obtain the fusion image through a series of post-processing procedures. However, the fusion results generated by these methods are easy to lose some source image details or results in artifacts. Inspired by the image reconstruction techniques based on deep learning, we propose a multi-focus image fusion network framework without any post-processing to solve these problems in the end-to-end and supervised learning way. To sufficiently train the fusion model, we have generated a large-scale multi-focus image dataset with ground-truth fusion images. What's more, to obtain a more informative fusion image, we further designed a novel fusion strategy based on unity fusion attention, which is composed of a channel attention module and a spatial attention module. Specifically, the proposed fusion approach mainly comprises three key components: feature extraction, feature fusion and image reconstruction. We firstly utilize seven convolutional blocks to extract the image features from source images. Then, the extracted convolutional features are fused by the proposed fusion strategy in the feature fusion layer. Finally, the fused image features are reconstructed by four convolutional blocks. Experimental results demonstrate that the proposed approach for multi-focus image fusion achieves remarkable fusion performance compared to 19 state-of-the-art fusion methods.
Enhanced Performance of Pre-Trained Networks by Matched Augmentation Distributions
Jan 19, 2022
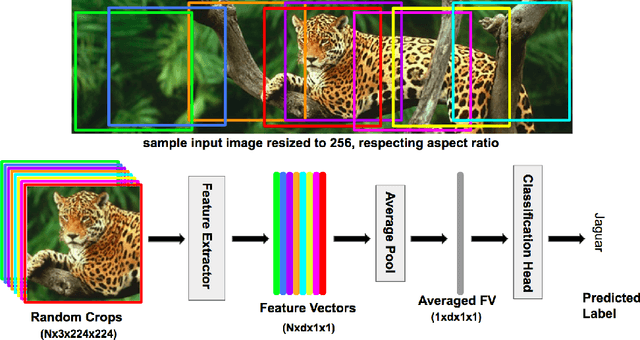
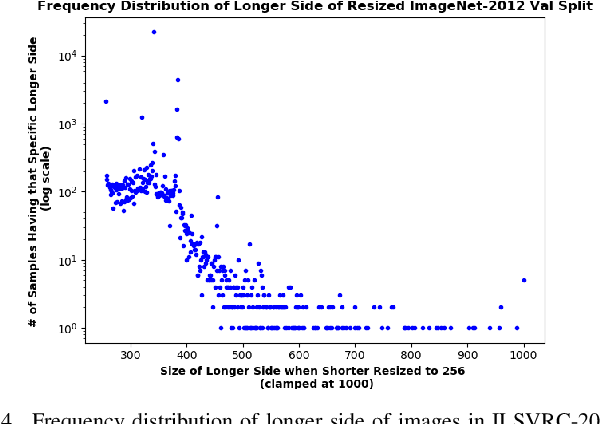
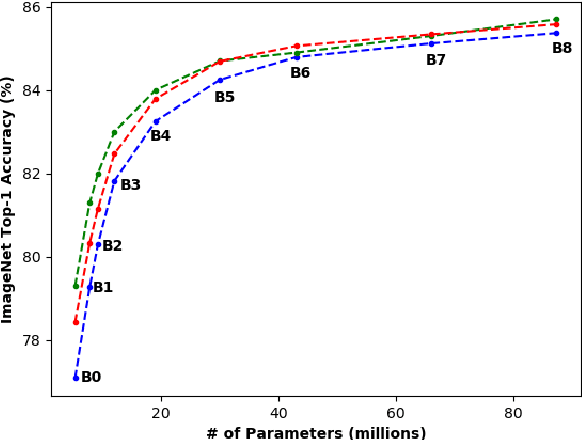
There exists a distribution discrepancy between training and testing, in the way images are fed to modern CNNs. Recent work tried to bridge this gap either by fine-tuning or re-training the network at different resolutions. However re-training a network is rarely cheap and not always viable. To this end, we propose a simple solution to address the train-test distributional shift and enhance the performance of pre-trained models -- which commonly ship as a package with deep learning platforms \eg, PyTorch. Specifically, we demonstrate that running inference on the center crop of an image is not always the best as important discriminatory information may be cropped-off. Instead we propose to combine results for multiple random crops for a test image. This not only matches the train time augmentation but also provides the full coverage of the input image. We explore combining representation of random crops through averaging at different levels \ie, deep feature level, logit level, and softmax level. We demonstrate that, for various families of modern deep networks, such averaging results in better validation accuracy compared to using a single central crop per image. The softmax averaging results in the best performance for various pre-trained networks without requiring any re-training or fine-tuning whatsoever. On modern GPUs with batch processing, the paper's approach to inference of pre-trained networks, is essentially free as all images in a batch can all be processed at once.
Perception Visualization: Seeing Through the Eyes of a DNN
Apr 21, 2022
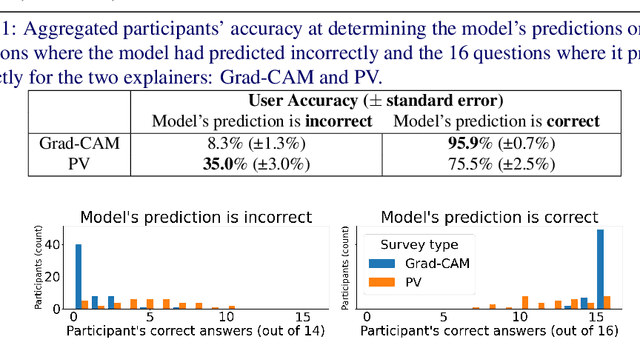

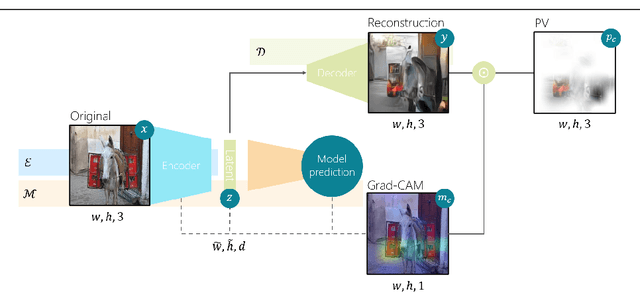
Artificial intelligence (AI) systems power the world we live in. Deep neural networks (DNNs) are able to solve tasks in an ever-expanding landscape of scenarios, but our eagerness to apply these powerful models leads us to focus on their performance and deprioritises our ability to understand them. Current research in the field of explainable AI tries to bridge this gap by developing various perturbation or gradient-based explanation techniques. For images, these techniques fail to fully capture and convey the semantic information needed to elucidate why the model makes the predictions it does. In this work, we develop a new form of explanation that is radically different in nature from current explanation methods, such as Grad-CAM. Perception visualization provides a visual representation of what the DNN perceives in the input image by depicting what visual patterns the latent representation corresponds to. Visualizations are obtained through a reconstruction model that inverts the encoded features, such that the parameters and predictions of the original models are not modified. Results of our user study demonstrate that humans can better understand and predict the system's decisions when perception visualizations are available, thus easing the debugging and deployment of deep models as trusted systems.
Neuro-Inspired Deep Neural Networks with Sparse, Strong Activations
Apr 12, 2022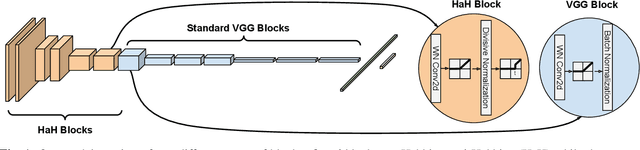

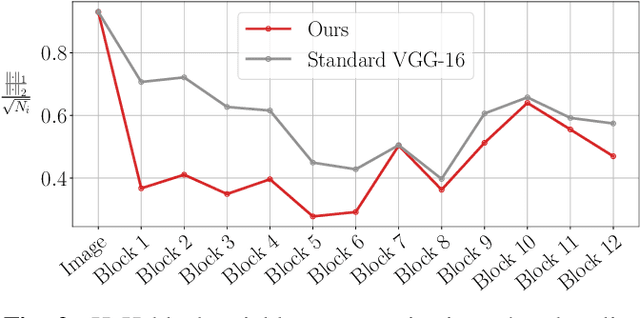
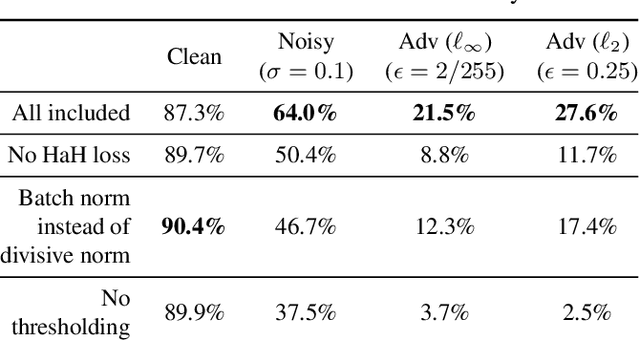
While end-to-end training of Deep Neural Networks (DNNs) yields state of the art performance in an increasing array of applications, it does not provide insight into, or control over, the features being extracted. We report here on a promising neuro-inspired approach to DNNs with sparser and stronger activations. We use standard stochastic gradient training, supplementing the end-to-end discriminative cost function with layer-wise costs promoting Hebbian ("fire together," "wire together") updates for highly active neurons, and anti-Hebbian updates for the remaining neurons. Instead of batch norm, we use divisive normalization of activations (suppressing weak outputs using strong outputs), along with implicit $\ell_2$ normalization of neuronal weights. Experiments with standard image classification tasks on CIFAR-10 demonstrate that, relative to baseline end-to-end trained architectures, our proposed architecture (a) leads to sparser activations (with only a slight compromise on accuracy), (b) exhibits more robustness to noise (without being trained on noisy data), (c) exhibits more robustness to adversarial perturbations (without adversarial training).
PhysioGAN: Training High Fidelity Generative Model for Physiological Sensor Readings
Apr 25, 2022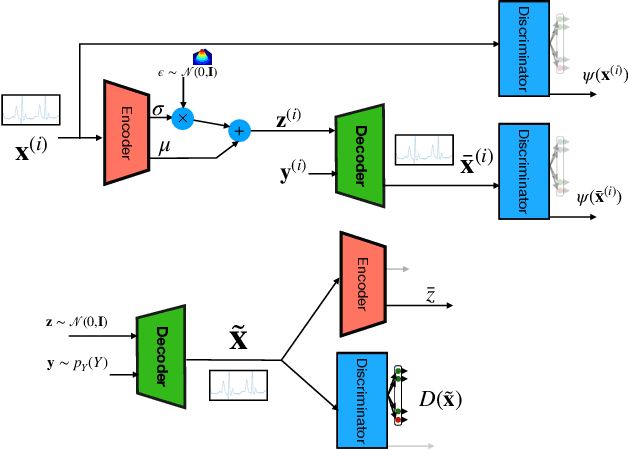
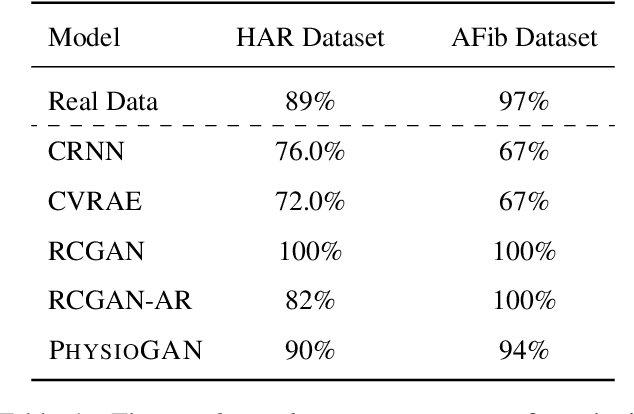
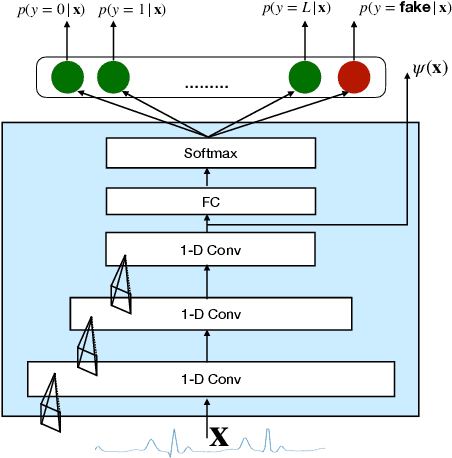
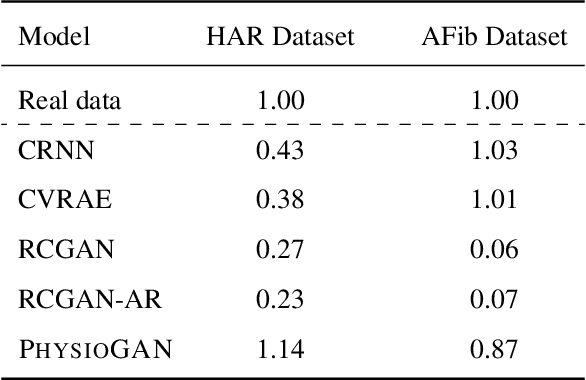
Generative models such as the variational autoencoder (VAE) and the generative adversarial networks (GAN) have proven to be incredibly powerful for the generation of synthetic data that preserves statistical properties and utility of real-world datasets, especially in the context of image and natural language text. Nevertheless, until now, there has no successful demonstration of how to apply either method for generating useful physiological sensory data. The state-of-the-art techniques in this context have achieved only limited success. We present PHYSIOGAN, a generative model to produce high fidelity synthetic physiological sensor data readings. PHYSIOGAN consists of an encoder, decoder, and a discriminator. We evaluate PHYSIOGAN against the state-of-the-art techniques using two different real-world datasets: ECG classification and activity recognition from motion sensors datasets. We compare PHYSIOGAN to the baseline models not only the accuracy of class conditional generation but also the sample diversity and sample novelty of the synthetic datasets. We prove that PHYSIOGAN generates samples with higher utility than other generative models by showing that classification models trained on only synthetic data generated by PHYSIOGAN have only 10% and 20% decrease in their classification accuracy relative to classification models trained on the real data. Furthermore, we demonstrate the use of PHYSIOGAN for sensor data imputation in creating plausible results.
RGB-D Semantic SLAM for Surgical Robot Navigation in the Operating Room
Apr 12, 2022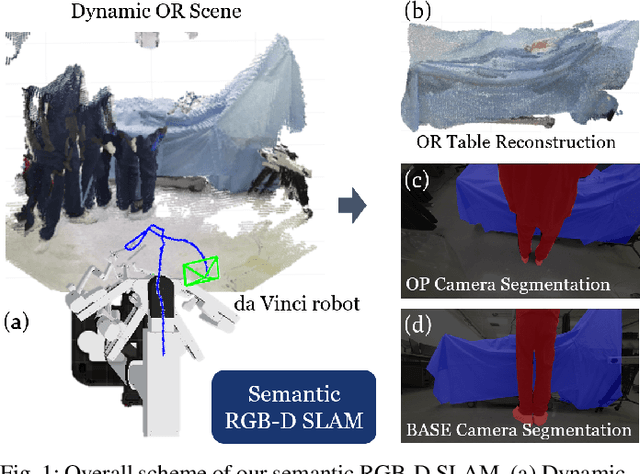
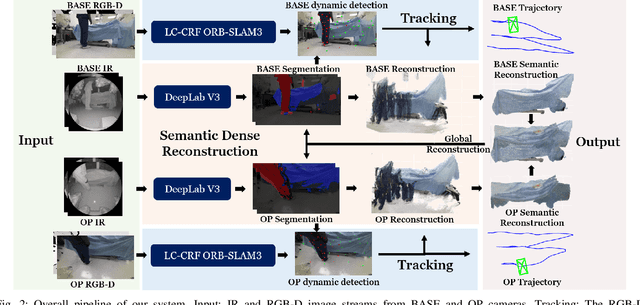
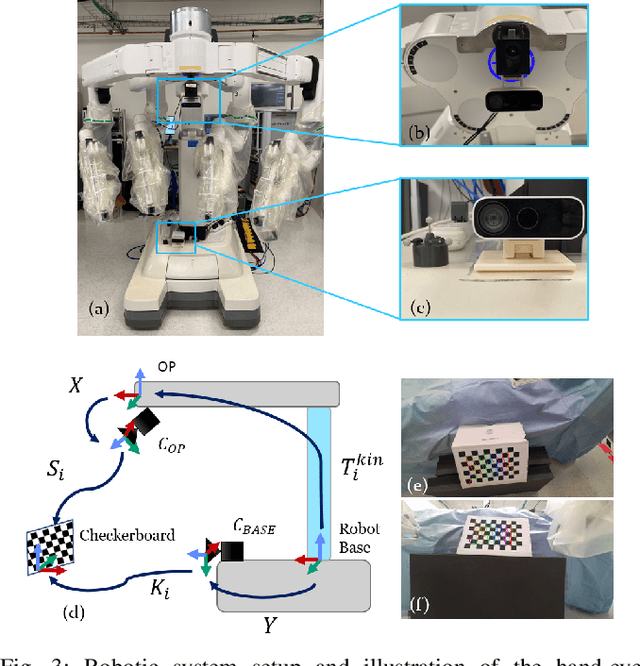

Gaining spatial awareness of the Operating Room (OR) for surgical robotic systems is a key technology that can enable intelligent applications aiming at improved OR workflow. In this work, we present a method for semantic dense reconstruction of the OR scene using multiple RGB-D cameras attached and registered to the da Vinci Xi surgical system. We developed a novel SLAM approach for robot pose tracking in dynamic OR environments and dense reconstruction of the static OR table object. We validated our techniques in a mock OR by collecting data sequences with corresponding optical tracking trajectories as ground truth and manually annotated 100 frame segmentation masks. The mean absolute trajectory error is $11.4\pm1.9$ mm and the mean relative pose error is $1.53\pm0.48$ degrees per second. The segmentation DICE score is improved from 0.814 to 0.902 by using our SLAM system compared to single frame. Our approach effectively produces a dense OR table reconstruction in dynamic clinical environments as well as improved semantic segmentation on individual image frames.
Six-channel Image Representation for Cross-domain Object Detection
Jan 03, 2021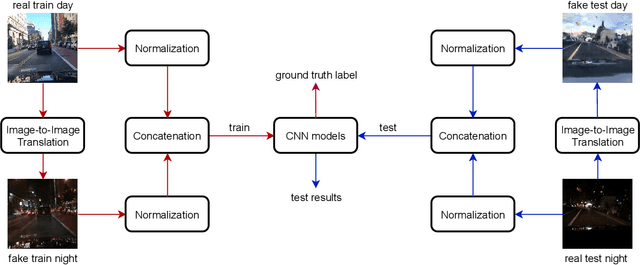



Most deep learning models are data-driven and the excellent performance is highly dependent on the abundant and diverse datasets. However, it is very hard to obtain and label the datasets of some specific scenes or applications. If we train the detector using the data from one domain, it cannot perform well on the data from another domain due to domain shift, which is one of the big challenges of most object detection models. To address this issue, some image-to-image translation techniques are employed to generate some fake data of some specific scenes to train the models. With the advent of Generative Adversarial Networks (GANs), we could realize unsupervised image-to-image translation in both directions from a source to a target domain and from the target to the source domain. In this study, we report a new approach to making use of the generated images. We propose to concatenate the original 3-channel images and their corresponding GAN-generated fake images to form 6-channel representations of the dataset, hoping to address the domain shift problem while exploiting the success of available detection models. The idea of augmented data representation may inspire further study on object detection and other applications.
Continuous and Diverse Image-to-Image Translation via Signed Attribute Vectors
Nov 03, 2020

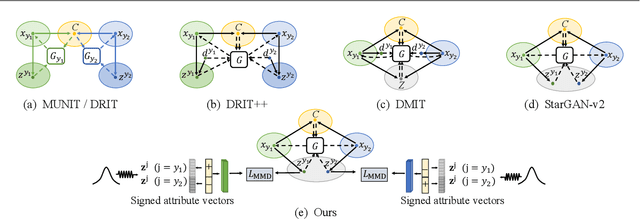
Recent image-to-image (I2I) translation algorithms focus on learning the mapping from a source to a target domain. However, the continuous translation problem that synthesizes intermediate results between the two domains has not been well-studied in the literature. Generating a smooth sequence of intermediate results bridges the gap of two different domains, facilitating the morphing effect across domains. Existing I2I approaches are limited to either intra-domain or deterministic inter-domain continuous translation. In this work, we present an effective signed attribute vector, which enables continuous translation on diverse mapping paths across various domains. In particular, utilizing the sign operation to encode the domain information, we introduce a unified attribute space shared by all domains, thereby allowing the interpolation on attribute vectors of different domains. To enhance the visual quality of continuous translation results, we generate a trajectory between two sign-symmetrical attribute vectors and leverage the domain information of the interpolated results along the trajectory for adversarial training. We evaluate the proposed method on a wide range of I2I translation tasks. Both qualitative and quantitative results demonstrate that the proposed framework generates more high-quality continuous translation results against the state-of-the-art methods.
Perceive, Represent, Generate: Translating Multimodal Information to Robotic Motion Trajectories
Apr 06, 2022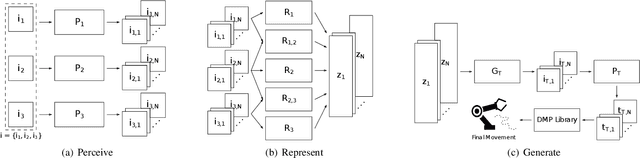



We present Perceive-Represent-Generate (PRG), a novel three-stage framework that maps perceptual information of different modalities (e.g., visual or sound), corresponding to a sequence of instructions, to an adequate sequence of movements to be executed by a robot. In the first stage, we perceive and pre-process the given inputs, isolating individual commands from the complete instruction provided by a human user. In the second stage we encode the individual commands into a multimodal latent space, employing a deep generative model. Finally, in the third stage we convert the multimodal latent values into individual trajectories and combine them into a single dynamic movement primitive, allowing its execution in a robotic platform. We evaluate our pipeline in the context of a novel robotic handwriting task, where the robot receives as input a word through different perceptual modalities (e.g., image, sound), and generates the corresponding motion trajectory to write it, creating coherent and readable handwritten words.
SOLIS: Autonomous Solubility Screening using Deep Neural Networks
Mar 18, 2022



Accelerating material discovery has tremendous societal and industrial impact, particularly for pharmaceuticals and clean energy production. Many experimental instruments have some degree of automation, facilitating continuous running and higher throughput. However, it is common that sample preparation is still carried out manually. This can result in researchers spending a significant amount of their time on repetitive tasks, which introduces errors and can prohibit production of statistically relevant data. Crystallisation experiments are common in many chemical fields, both for purification and in polymorph screening experiments. The initial step often involves a solubility screen of the molecule; that is, understanding whether molecular compounds have dissolved in a particular solvent. This usually can be time consuming and work intensive. Moreover, accurate knowledge of the precise solubility limit of the molecule is often not required, and simply measuring a threshold of solubility in each solvent would be sufficient. To address this, we propose a novel cascaded deep model that is inspired by how a human chemist would visually assess a sample to determine whether the solid has completely dissolved in the solution. In this paper, we design, develop, and evaluate the first fully autonomous solubility screening framework, which leverages state-of-the-art methods for image segmentation and convolutional neural networks for image classification. To realise that, we first create a dataset comprising different molecules and solvents, which is collected in a real-world chemistry laboratory. We then evaluated our method on the data recorded through an eye-in-hand camera mounted on a seven degree-of-freedom robotic manipulator, and show that our model can achieve 99.13% test accuracy across various setups.