 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Do Users Benefit From Interpretable Vision? A User Study, Baseline, And Dataset
Apr 25, 2022
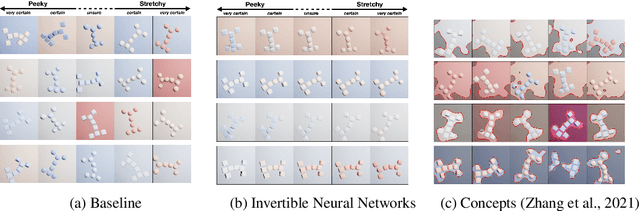
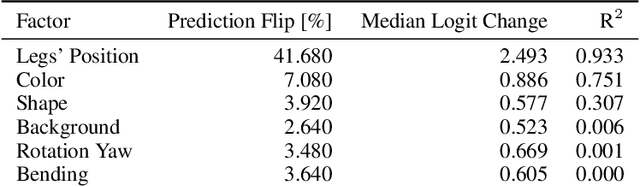


A variety of methods exist to explain image classification models. However, whether they provide any benefit to users over simply comparing various inputs and the model's respective predictions remains unclear. We conducted a user study (N=240) to test how such a baseline explanation technique performs against concept-based and counterfactual explanations. To this end, we contribute a synthetic dataset generator capable of biasing individual attributes and quantifying their relevance to the model. In a study, we assess if participants can identify the relevant set of attributes compared to the ground-truth. Our results show that the baseline outperformed concept-based explanations. Counterfactual explanations from an invertible neural network performed similarly as the baseline. Still, they allowed users to identify some attributes more accurately. Our results highlight the importance of measuring how well users can reason about biases of a model, rather than solely relying on technical evaluations or proxy tasks. We open-source our study and dataset so it can serve as a blue-print for future studies. For code see, https://github.com/berleon/do_users_benefit_from_interpretable_vision
UNETR: Transformers for 3D Medical Image Segmentation
Mar 18, 2021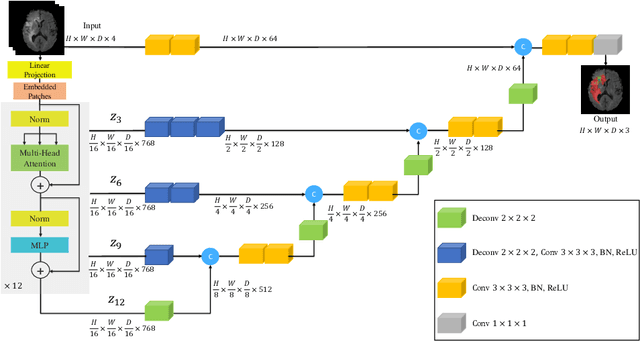
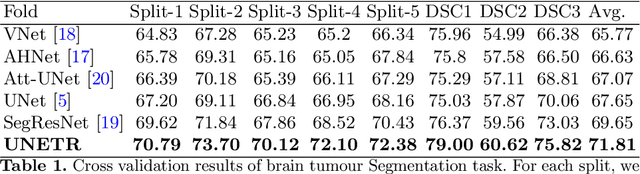
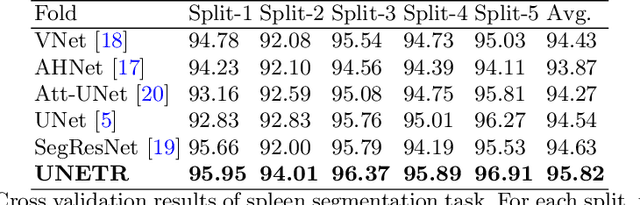
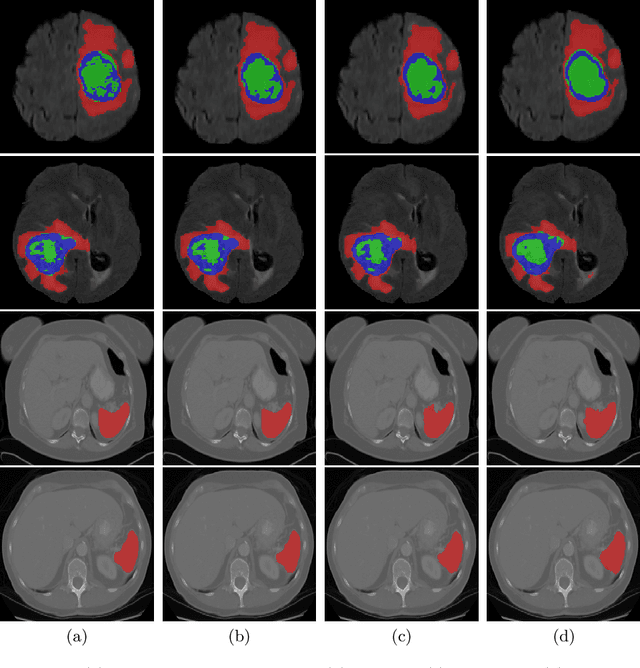
Fully Convolutional Neural Networks (FCNNs) with contracting and expansive paths (e.g. encoder and decoder) have shown prominence in various medical image segmentation applications during the recent years. In these architectures, the encoder plays an integral role by learning global contextual representations which will be further utilized for semantic output prediction by the decoder. Despite their success, the locality of convolutional layers , as the main building block of FCNNs limits the capability of learning long-range spatial dependencies in such networks. Inspired by the recent success of transformers in Natural Language Processing (NLP) in long-range sequence learning, we reformulate the task of volumetric (3D) medical image segmentation as a sequence-to-sequence prediction problem. In particular, we introduce a novel architecture, dubbed as UNEt TRansformers (UNETR), that utilizes a pure transformer as the encoder to learn sequence representations of the input volume and effectively capture the global multi-scale information. The transformer encoder is directly connected to a decoder via skip connections at different resolutions to compute the final semantic segmentation output. We have extensively validated the performance of our proposed model across different imaging modalities(i.e. MR and CT) on volumetric brain tumour and spleen segmentation tasks using the Medical Segmentation Decathlon (MSD) dataset, and our results consistently demonstrate favorable benchmarks.
Interpretable Deep Multimodal Image Super-Resolution
Sep 07, 2020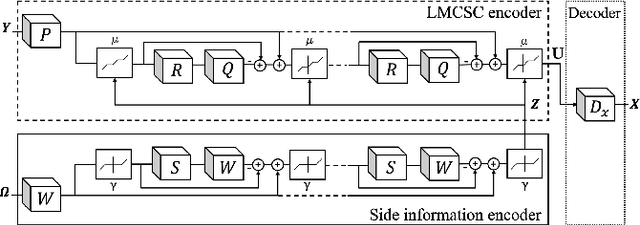
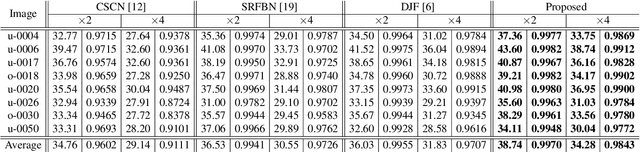

Multimodal image super-resolution (SR) is the reconstruction of a high resolution image given a low-resolution observation with the aid of another image modality. While existing deep multimodal models do not incorporate domain knowledge about image SR, we present a multimodal deep network design that integrates coupled sparse priors and allows the effective fusion of information from another modality into the reconstruction process. Our method is inspired by a novel iterative algorithm for coupled convolutional sparse coding, resulting in an interpretable network by design. We apply our model to the super-resolution of near-infrared image guided by RGB images. Experimental results show that our model outperforms state-of-the-art methods.
Look Closer to Supervise Better: One-Shot Font Generation via Component-Based Discriminator
Apr 30, 2022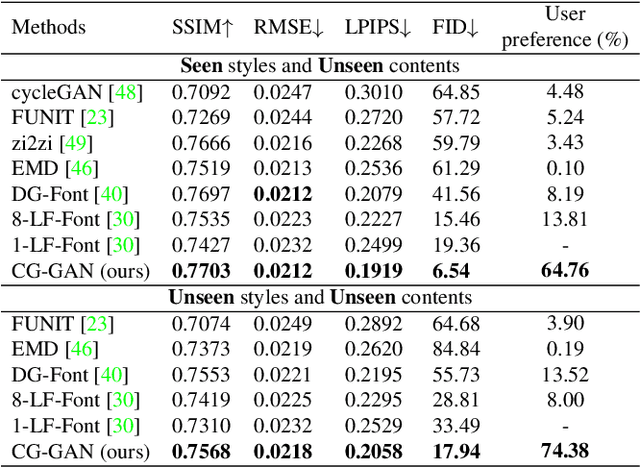
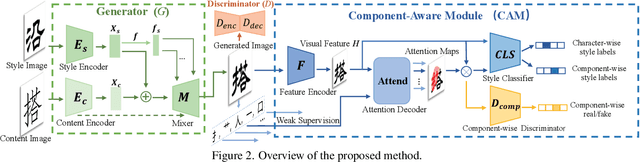


Automatic font generation remains a challenging research issue due to the large amounts of characters with complicated structures. Typically, only a few samples can serve as the style/content reference (termed few-shot learning), which further increases the difficulty to preserve local style patterns or detailed glyph structures. We investigate the drawbacks of previous studies and find that a coarse-grained discriminator is insufficient for supervising a font generator. To this end, we propose a novel Component-Aware Module (CAM), which supervises the generator to decouple content and style at a more fine-grained level, \textit{i.e.}, the component level. Different from previous studies struggling to increase the complexity of generators, we aim to perform more effective supervision for a relatively simple generator to achieve its full potential, which is a brand new perspective for font generation. The whole framework achieves remarkable results by coupling component-level supervision with adversarial learning, hence we call it Component-Guided GAN, shortly CG-GAN. Extensive experiments show that our approach outperforms state-of-the-art one-shot font generation methods. Furthermore, it can be applied to handwritten word synthesis and scene text image editing, suggesting the generalization of our approach.
Understanding out-of-distribution accuracies through quantifying difficulty of test samples
Mar 28, 2022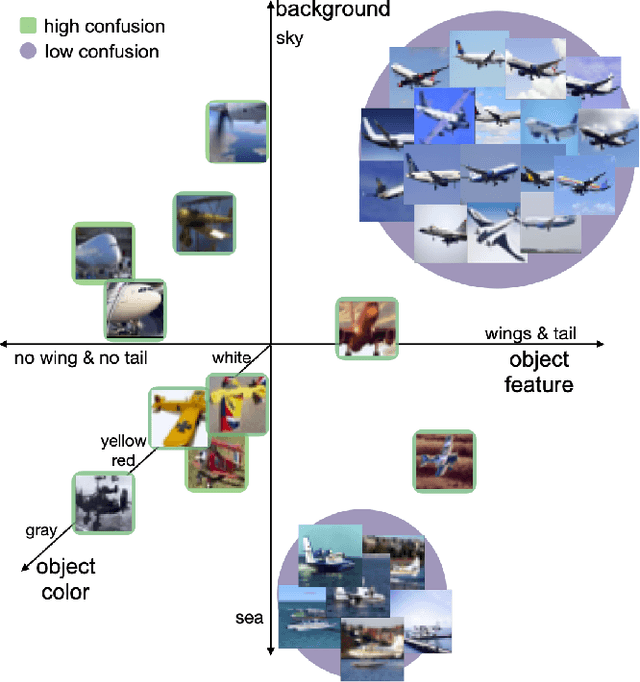
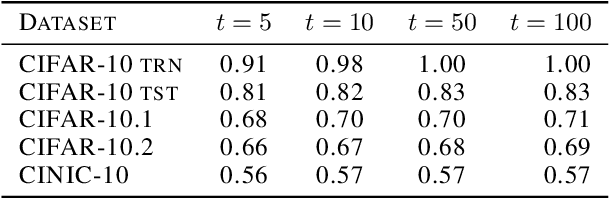
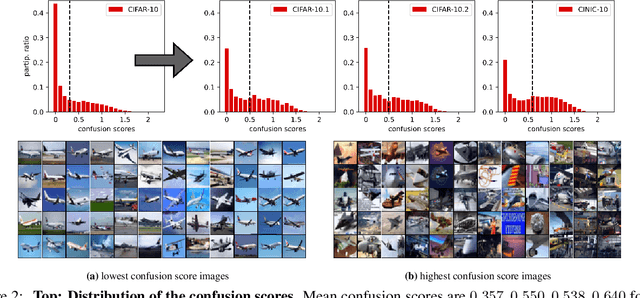
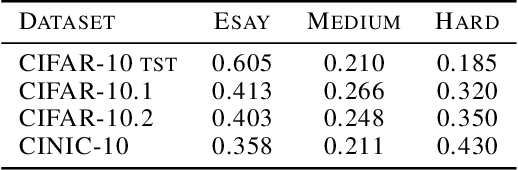
Existing works show that although modern neural networks achieve remarkable generalization performance on the in-distribution (ID) dataset, the accuracy drops significantly on the out-of-distribution (OOD) datasets \cite{recht2018cifar, recht2019imagenet}. To understand why a variety of models consistently make more mistakes in the OOD datasets, we propose a new metric to quantify the difficulty of the test images (either ID or OOD) that depends on the interaction of the training dataset and the model. In particular, we introduce \textit{confusion score} as a label-free measure of image difficulty which quantifies the amount of disagreement on a given test image based on the class conditional probabilities estimated by an ensemble of trained models. Using the confusion score, we investigate CIFAR-10 and its OOD derivatives. Next, by partitioning test and OOD datasets via their confusion scores, we predict the relationship between ID and OOD accuracies for various architectures. This allows us to obtain an estimator of the OOD accuracy of a given model only using ID test labels. Our observations indicate that the biggest contribution to the accuracy drop comes from images with high confusion scores. Upon further inspection, we report on the nature of the misclassified images grouped by their confusion scores: \textit{(i)} images with high confusion scores contain \textit{weak spurious correlations} that appear in multiple classes in the training data and lack clear \textit{class-specific features}, and \textit{(ii)} images with low confusion scores exhibit spurious correlations that belong to another class, namely \textit{class-specific spurious correlations}.
Event-based Timestamp Image Encoding Network for Human Action Recognition and Anticipation
Apr 13, 2021
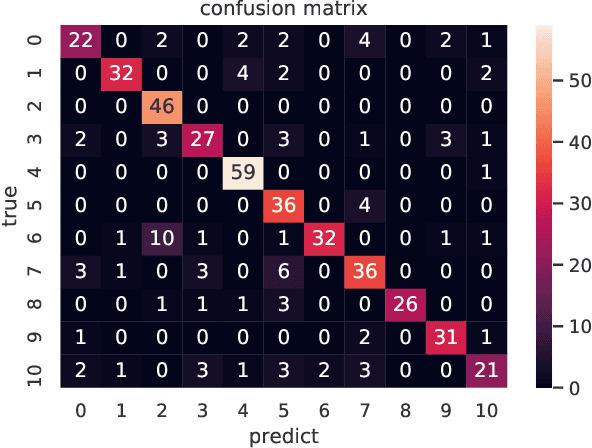

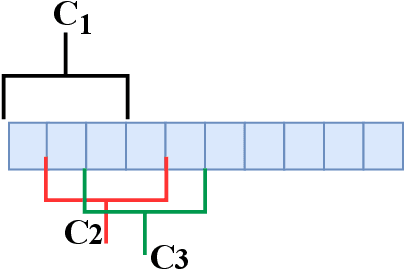
Event camera is an asynchronous, high frequency vision sensor with low power consumption, which is suitable for human action understanding task. It is vital to encode the spatial-temporal information of event data properly and use standard computer vision tool to learn from the data. In this work, we propose a timestamp image encoding 2D network, which takes the encoded spatial-temporal images with polarity information of the event data as input and output the action label. In addition, we propose a future timestamp image generator to generate futureaction information to aid the model to anticipate the human action when the action is not completed. Experiment results show that our method can achieve the same level of performance as those RGB-based benchmarks on real world action recognition,and also achieve the state of the art (SOTA) result on gesture recognition. Our future timestamp image generating model can effectively improve the prediction accuracy when the action is not completed. We also provide insight discussion on the importance of motion and appearance information in action recognition and anticipation.
Visual representation of negation: Real world data analysis on comic image design
May 21, 2021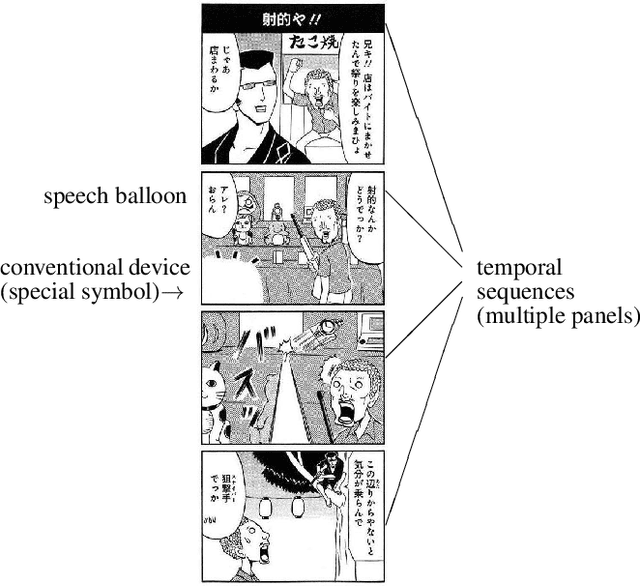

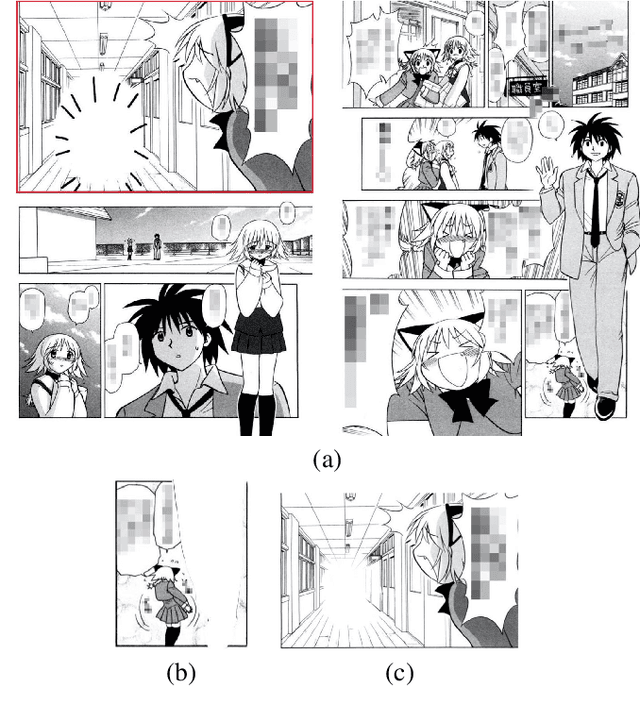

There has been a widely held view that visual representations (e.g., photographs and illustrations) do not depict negation, for example, one that can be expressed by a sentence "the train is not coming". This view is empirically challenged by analyzing the real-world visual representations of comic (manga) illustrations. In the experiment using image captioning tasks, we gave people comic illustrations and asked them to explain what they could read from them. The collected data showed that some comic illustrations could depict negation without any aid of sequences (multiple panels) or conventional devices (special symbols). This type of comic illustrations was subjected to further experiments, classifying images into those containing negation and those not containing negation. While this image classification was easy for humans, it was difficult for data-driven machines, i.e., deep learning models (CNN), to achieve the same high performance. Given the findings, we argue that some comic illustrations evoke background knowledge and thus can depict negation with purely visual elements.
A Deep Learning Technique using a Sequence of Follow Up X-Rays for Disease classification
Mar 28, 2022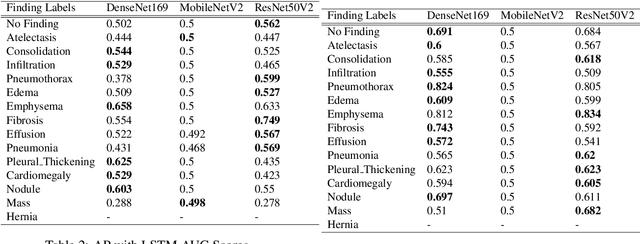
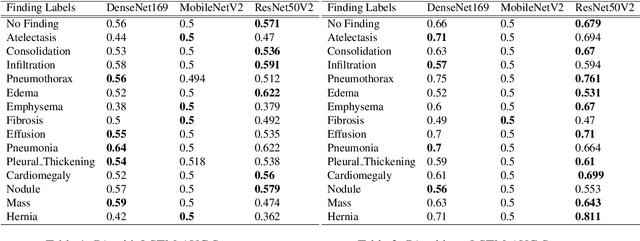
The ability to predict lung and heart based diseases using deep learning techniques is central to many researchers, particularly in the medical field around the world. In this paper, we present a unique outlook of a very familiar problem of disease classification using X-rays. We present a hypothesis that X-rays of patients included with the follow up history of their most recent three chest X-ray images would perform better in disease classification in comparison to one chest X-ray image input using an internal CNN to perform feature extraction. We have discovered that our generic deep learning architecture which we propose for solving this problem performs well with 3 input X ray images provided per sample for each patient. In this paper, we have also established that without additional layers before the output classification, the CNN models will improve the performance of predicting the disease labels for each patient. We have provided our results in ROC curves and AUROC scores. We define a fresh approach of collecting three X-ray images for training deep learning models, which we have concluded has clearly improved the performance of the models. We have shown that ResNet, in general, has a better result than any other CNN model used in the feature extraction phase. With our original approach to data pre-processing, image training, and pre-trained models, we believe that the current research will assist many medical institutions around the world, and this will improve the prediction of patients' symptoms and diagnose them with more accurate cure.
Lane detection with Position Embedding
Mar 23, 2022
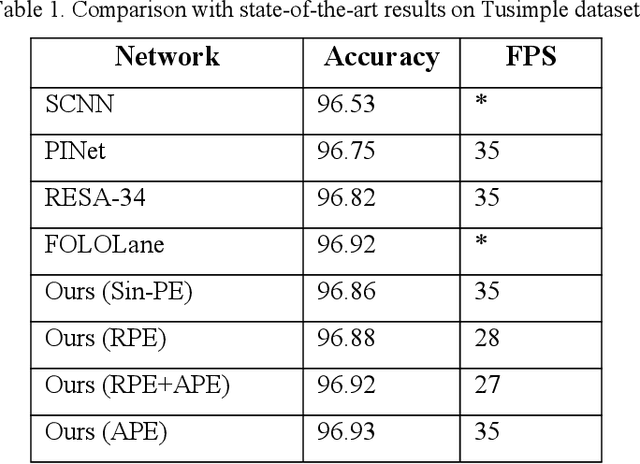

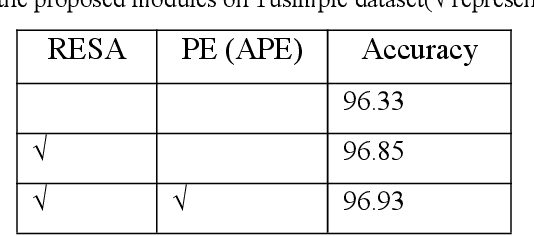
Recently, lane detection has made great progress in autonomous driving. RESA (REcurrent Feature-Shift Aggregator) is based on image segmentation. It presents a novel module to enrich lane feature after preliminary feature extraction with an ordinary CNN. For Tusimple dataset, there is not too complicated scene and lane has more prominent spatial features. On the basis of RESA, we introduce the method of position embedding to enhance the spatial features. The experimental results show that this method has achieved the best accuracy 96.93% on Tusimple dataset.
4-D Epanechnikov Mixture Regression in Light Field Image Compression
Aug 14, 2021With the emergence of light field imaging in recent years, the compression of its elementary image array (EIA) has become a significant problem. Our coding framework includes modeling and reconstruction. For the modeling, the covariance-matrix form of the 4-D Epanechnikov kernel (4-D EK) and its correlated statistics were deduced to obtain the 4-D Epanechnikov mixture models (4-D EMMs). A 4-D Epanechnikov mixture regression (4-D EMR) was proposed based on this 4-D EK, and a 4-D adaptive model selection (4-D AMLS) algorithm was designed to realize the optimal modeling for a pseudo video sequence (PVS) of the extracted key-EIA. A linear function based reconstruction (LFBR) was proposed based on the correlation between adjacent elementary images (EIs). The decoded images realized a clear outline reconstruction and superior coding efficiency compared to high-efficiency video coding (HEVC) and JPEG 2000 below approximately 0.05 bpp. This work realized an unprecedented theoretical application by (1) proposing the 4-D Epanechnikov kernel theory, (2) exploiting the 4-D Epanechnikov mixture regression and its application in the modeling of the pseudo video sequence of light field images, (3) using 4-D adaptive model selection for the optimal number of models, and (4) employing a linear function-based reconstruction according to the content similarity.
* 16 pages, 17 figures, IEEE Transactions on Circuits and Systems for Video Technology ( Early Access )