 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Diffusion and Volume Maximization-Based Clustering of Highly Mixed Hyperspectral Images
Mar 26, 2022
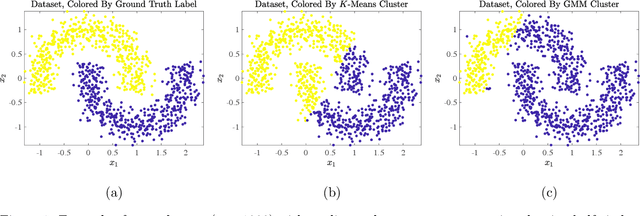
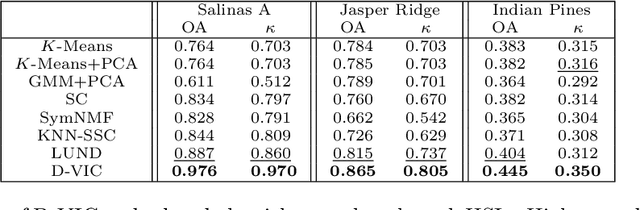
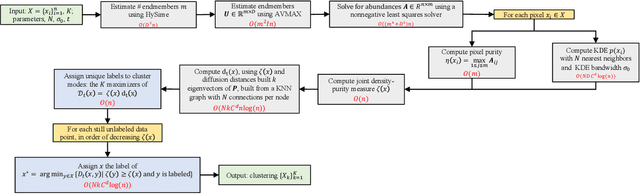
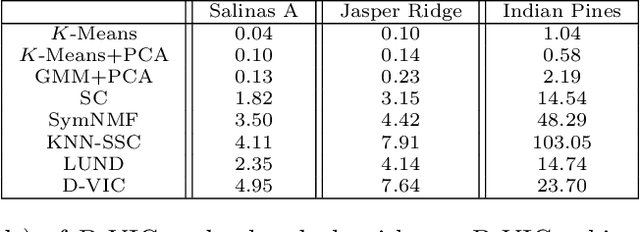
Hyperspectral images of a scene or object are a rich data source, often encoding a hundred or more spectral bands of reflectance at each pixel. Despite being very high-dimensional, these images typically encode latent low-dimensional structure that can be exploited for material discrimination. However, due to an inherent trade-off between spectral and spatial resolution, many hyperspectral images are generated at a coarse spatial scale, and single pixels may correspond to spatial regions containing multiple materials. This article introduces the Diffusion and Volume maximization-based Image Clustering (D-VIC) algorithm for unsupervised material discrimination. D-VIC locates cluster modes - high-density, high-purity pixels in the hyperspectral image that are far in diffusion distance (a data-dependent distance metric) from other high-density, high-purity pixels - and assigns these pixels unique labels, as these points are meant to exemplify underlying material structure. Non-modal pixels are labeled according to their diffusion distance nearest neighbor of higher density and purity that is already labeled. By directly incorporating pixel purity into its modal and non-modal labeling, D-VIC upweights pixels that correspond to a spatial region containing just a single material, yielding more interpretable clusterings. D-VIC is shown to outperform baseline and comparable state-of-the-art methods in extensive numerical experiments on a range of hyperspectral images, implying that it is well-equipped for material discrimination and clustering of these data.
Prediction of stent under-expansion in calcified coronary arteries using machine-learning on intravascular optical coherence tomography
May 16, 2022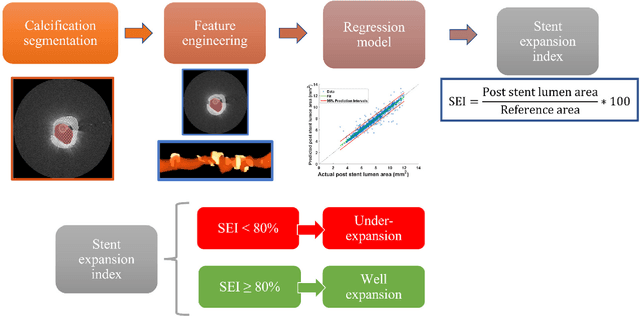
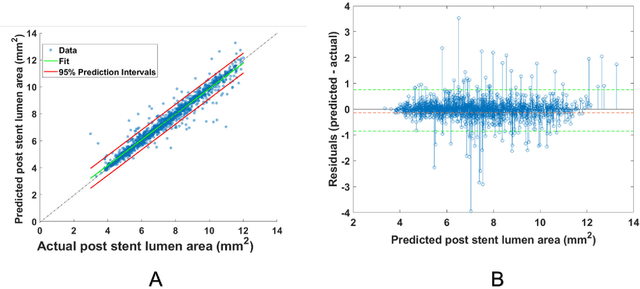
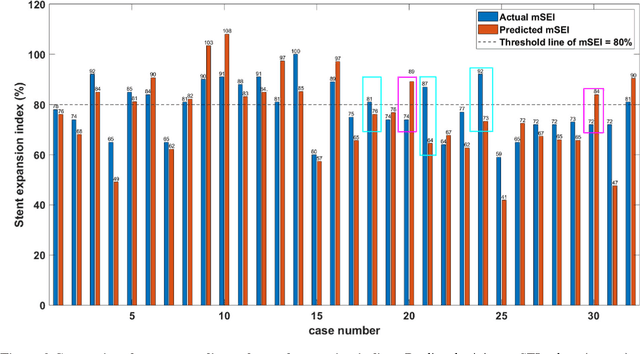
BACKGROUND Careful evaluation of the risk of stent under-expansions before the intervention will aid treatment planning, including the application of a pre-stent plaque modification strategy. OBJECTIVES It remains challenging to achieve a proper stent expansion in the presence of severely calcified coronary lesions. Building on our work in deep learning segmentation, we created an automated machine learning approach that uses lesion attributes to predict stent under-expansion from pre-stent images, suggesting the need for plaque modification. METHODS Pre- and post-stent intravascular optical coherence tomography image data were obtained from 110 coronary lesions. Lumen and calcifications in pre-stent images were segmented using deep learning, and numerous features per lesion were extracted. We analyzed stent expansion along the lesion, enabling frame, segmental, and whole-lesion analyses. We trained regression models to predict the poststent lumen area and then to compute the stent expansion index (SEI). Stents with an SEI < or >/= 80% were classified as "under-expanded" and "well-expanded," respectively. RESULTS Best performance (root-mean-square-error = 0.04+/-0.02 mm2, r = 0.94+/-0.04, p < 0.0001) was achieved when we used features from both the lumen and calcification to train a Gaussian regression model for a segmental analysis over a segment length of 31 frames. Under-expansion classification results (AUC=0.85+/-0.02) were significantly improved over other approaches. CONCLUSIONS We used calcifications and lumen features to identify lesions at risk of stent under-expansion. Results suggest that the use of pre-stent images can inform physicians of the need to apply plaque modification approaches.
Point Cloud Semantic Segmentation using Multi Scale Sparse Convolution Neural Network
May 09, 2022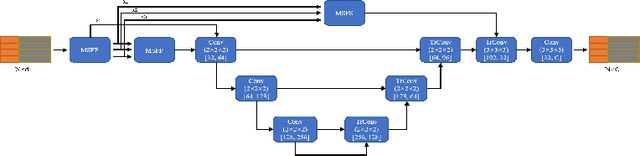
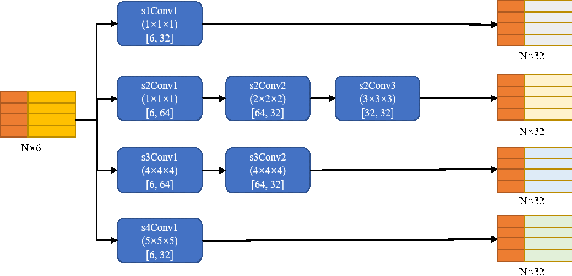
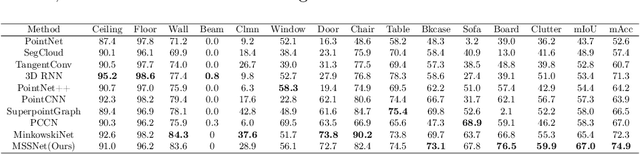
Point clouds have the characteristics of disorder, unstructured and sparseness.Aiming at the problem of the non-structural nature of point clouds, thanks to the excellent performance of convolutional neural networks in image processing, one of the solutions is to extract features from point clouds based on two-dimensional convolutional neural networks. The three-dimensional information carried in the point cloud can be converted to two-dimensional, and then processed by a two-dimensional convolutional neural network, and finally back-projected to three-dimensional.In the process of projecting 3D information to 2D and back-projection, certain information loss will inevitably be caused to the point cloud and category inconsistency will be introduced in the back-projection stage;Another solution is the voxel-based point cloud segmentation method, which divides the point cloud into small grids one by one.However, the point cloud is sparse, and the direct use of 3D convolutional neural network inevitably wastes computing resources. In this paper, we propose a feature extraction module based on multi-scale ultra-sparse convolution and a feature selection module based on channel attention, and build a point cloud segmentation network framework based on this.By introducing multi-scale sparse convolution, network could capture richer feature information based on convolution kernels of different sizes, improving the segmentation result of point cloud segmentation.
Image inpainting using frequency domain priors
Dec 03, 2020
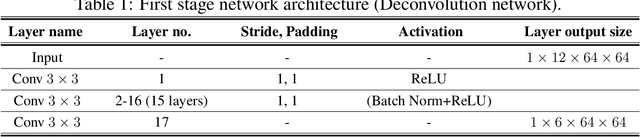
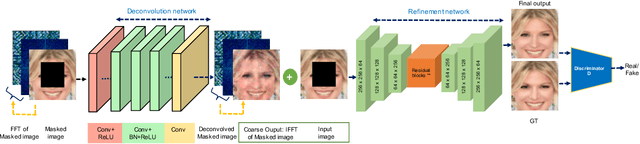
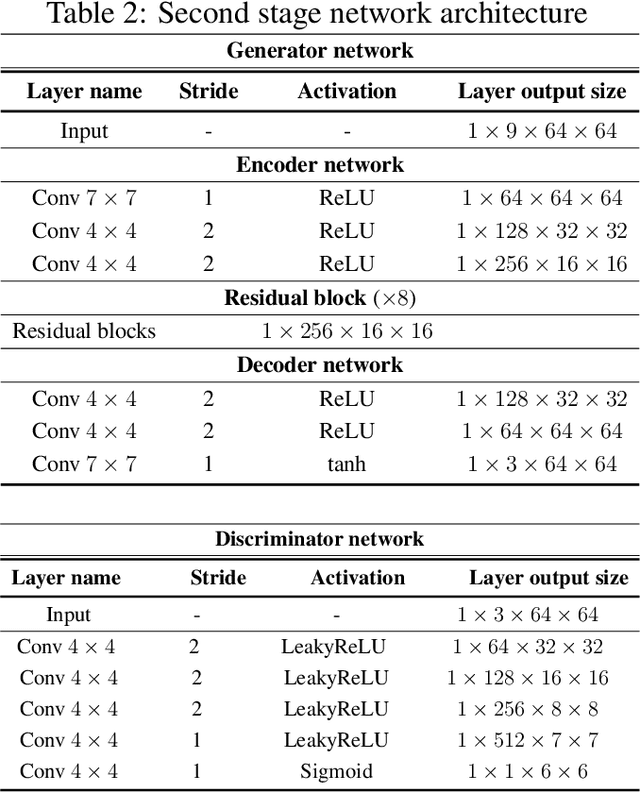
In this paper, we present a novel image inpainting technique using frequency domain information. Prior works on image inpainting predict the missing pixels by training neural networks using only the spatial domain information. However, these methods still struggle to reconstruct high-frequency details for real complex scenes, leading to a discrepancy in color, boundary artifacts, distorted patterns, and blurry textures. To alleviate these problems, we investigate if it is possible to obtain better performance by training the networks using frequency domain information (Discrete Fourier Transform) along with the spatial domain information. To this end, we propose a frequency-based deconvolution module that enables the network to learn the global context while selectively reconstructing the high-frequency components. We evaluate our proposed method on the publicly available datasets CelebA, Paris Streetview, and DTD texture dataset, and show that our method outperforms current state-of-the-art image inpainting techniques both qualitatively and quantitatively.
Planes vs. Chairs: Category-guided 3D shape learning without any 3D cues
Apr 21, 2022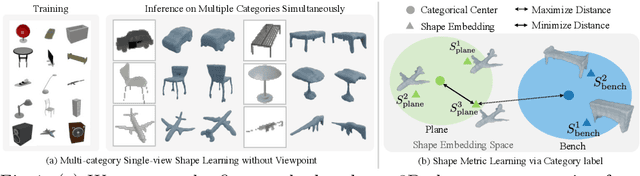

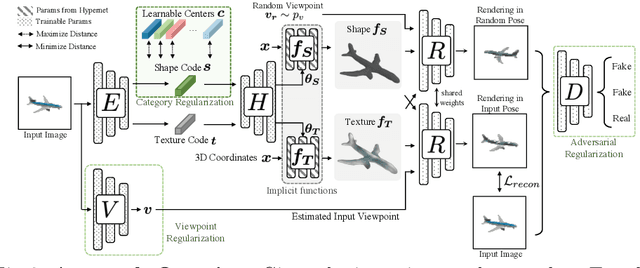
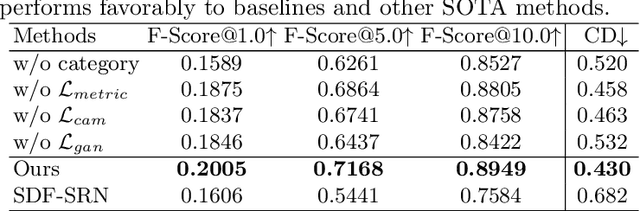
We present a novel 3D shape reconstruction method which learns to predict an implicit 3D shape representation from a single RGB image. Our approach uses a set of single-view images of multiple object categories without viewpoint annotation, forcing the model to learn across multiple object categories without 3D supervision. To facilitate learning with such minimal supervision, we use category labels to guide shape learning with a novel categorical metric learning approach. We also utilize adversarial and viewpoint regularization techniques to further disentangle the effects of viewpoint and shape. We obtain the first results for large-scale (more than 50 categories) single-viewpoint shape prediction using a single model without any 3D cues. We are also the first to examine and quantify the benefit of class information in single-view supervised 3D shape reconstruction. Our method achieves superior performance over state-of-the-art methods on ShapeNet-13, ShapeNet-55 and Pascal3D+.
Viko 2.0: A Hierarchical Gecko-inspired Adhesive Gripper with Visuotactile Sensor
Apr 21, 2022
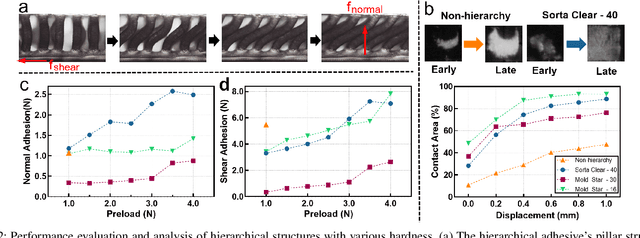
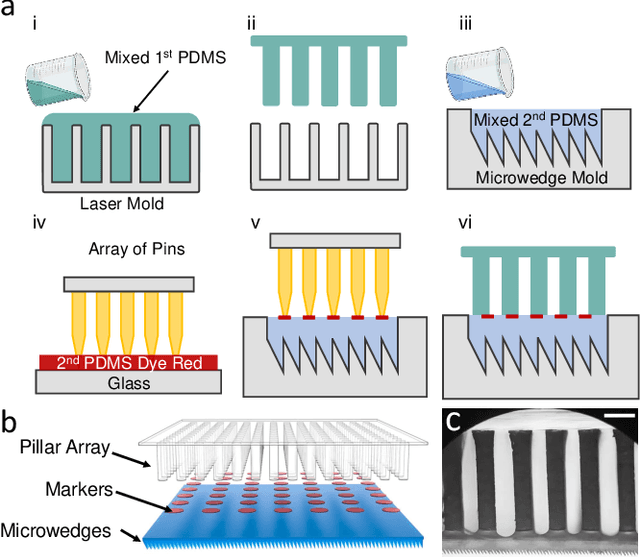
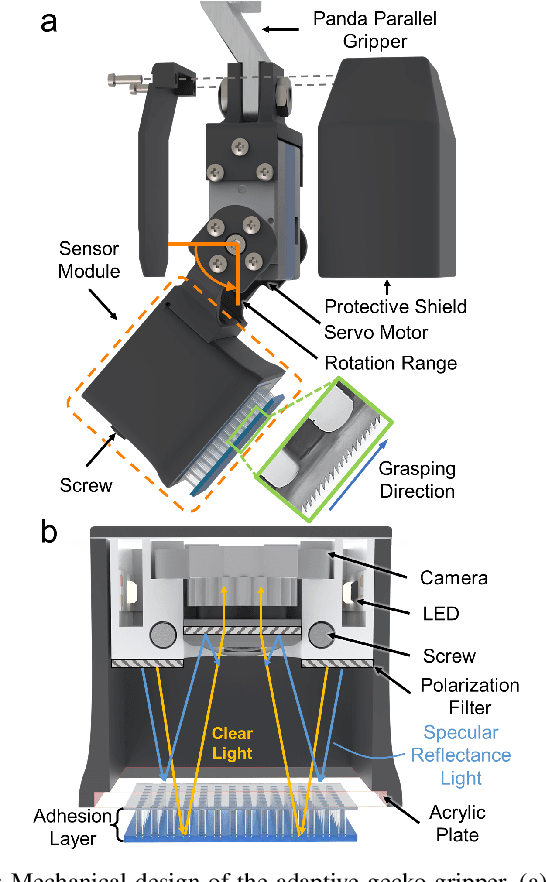
Robotic grippers with visuotactile sensors have access to rich tactile information for grasping tasks but encounter difficulty in partially encompassing large objects with sufficient grip force. While hierarchical gecko-inspired adhesives are a potential technique for bridging performance gaps, they require a large contact area for efficient usage. In this work, we present a new version of an adaptive gecko gripper called Viko 2.0 that effectively combines the advantage of adhesives and visuotactile sensors. Compared with a non-hierarchical structure, a hierarchical structure with a multimaterial design achieves approximately a 1.5 times increase in normal adhesion and double in contact area. The integrated visuotactile sensor captures a deformation image of the hierarchical structure and provides a real-time measurement of contact area, shear force, and incipient slip detection at 24 Hz. The gripper is implemented on a robotic arm to demonstrate an adaptive grasping pose based on contact area, and grasps objects with a wide range of geometries and textures.
A Comparison of Deep Learning Classification Methods on Small-scale Image Data set: from Converlutional Neural Networks to Visual Transformers
Jul 16, 2021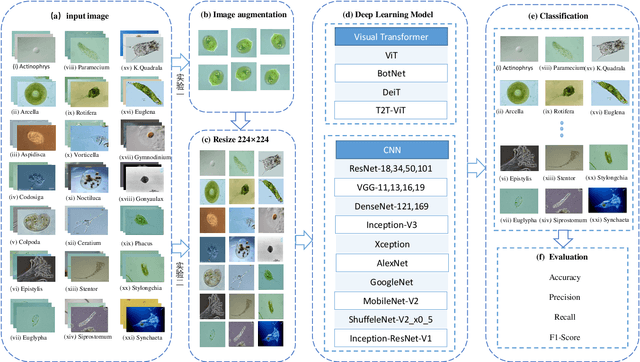
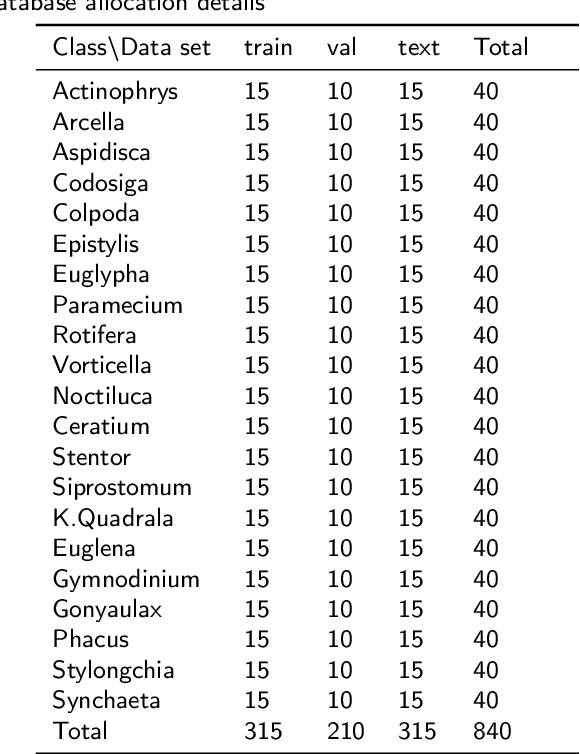
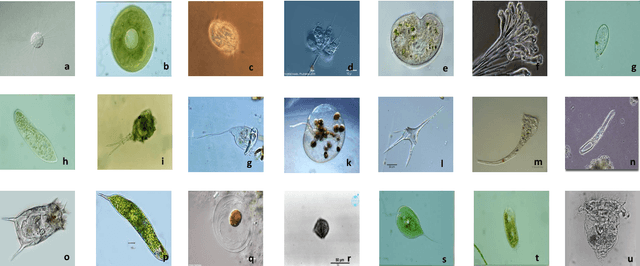

In recent years, deep learning has made brilliant achievements in image classification. However, image classification of small datasets is still not obtained good research results. This article first briefly explains the application and characteristics of convolutional neural networks and visual transformers. Meanwhile, the influence of small data set on classification and the solution are introduced. Then a series of experiments are carried out on the small datasets by using various models, and the problems of some models in the experiments are discussed. Through the comparison of experimental results, the recommended deep learning model is given according to the model application environment. Finally, we give directions for future work.
Segmentation-Renormalized Deep Feature Modulation for Unpaired Image Harmonization
Feb 11, 2021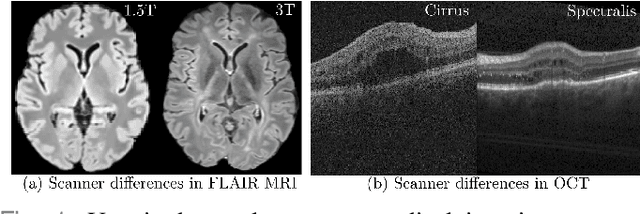
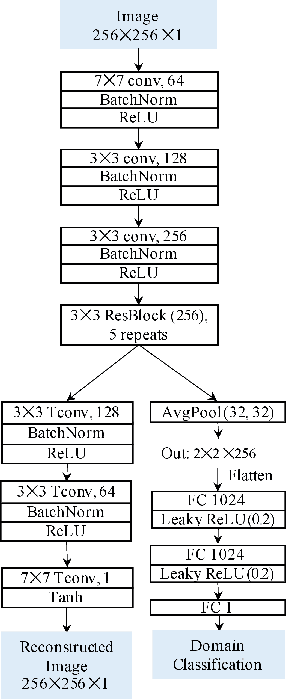
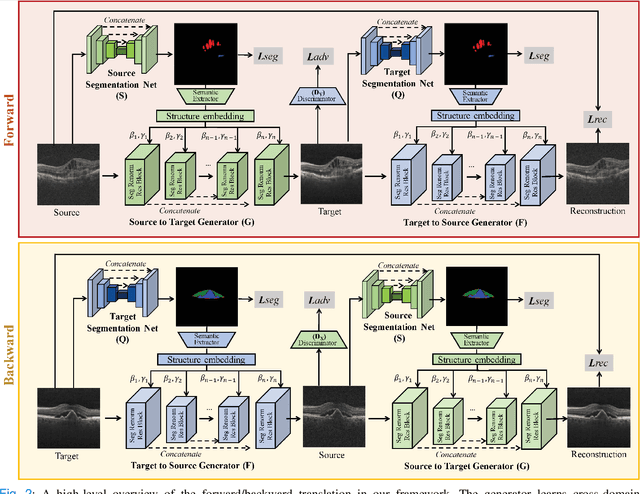
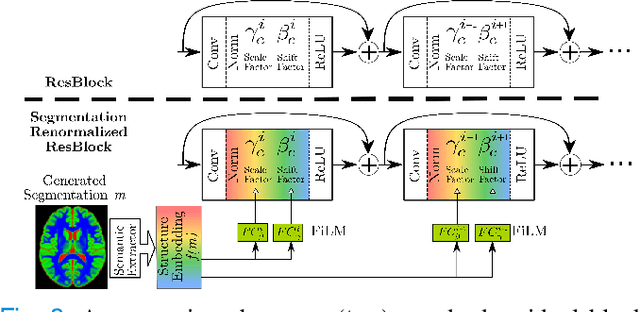
Deep networks are now ubiquitous in large-scale multi-center imaging studies. However, the direct aggregation of images across sites is contraindicated for downstream statistical and deep learning-based image analysis due to inconsistent contrast, resolution, and noise. To this end, in the absence of paired data, variations of Cycle-consistent Generative Adversarial Networks have been used to harmonize image sets between a source and target domain. Importantly, these methods are prone to instability, contrast inversion, intractable manipulation of pathology, and steganographic mappings which limit their reliable adoption in real-world medical imaging. In this work, based on an underlying assumption that morphological shape is consistent across imaging sites, we propose a segmentation-renormalized image translation framework to reduce inter-scanner heterogeneity while preserving anatomical layout. We replace the affine transformations used in the normalization layers within generative networks with trainable scale and shift parameters conditioned on jointly learned anatomical segmentation embeddings to modulate features at every level of translation. We evaluate our methodologies against recent baselines across several imaging modalities (T1w MRI, FLAIR MRI, and OCT) on datasets with and without lesions. Segmentation-renormalization for translation GANs yields superior image harmonization as quantified by Inception distances, demonstrates improved downstream utility via post-hoc segmentation accuracy, and improved robustness to translation perturbation and self-adversarial attacks.
Generating 3D Bio-Printable Patches Using Wound Segmentation and Reconstruction to Treat Diabetic Foot Ulcers
Mar 08, 2022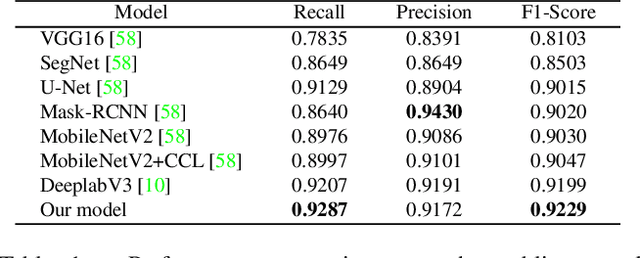
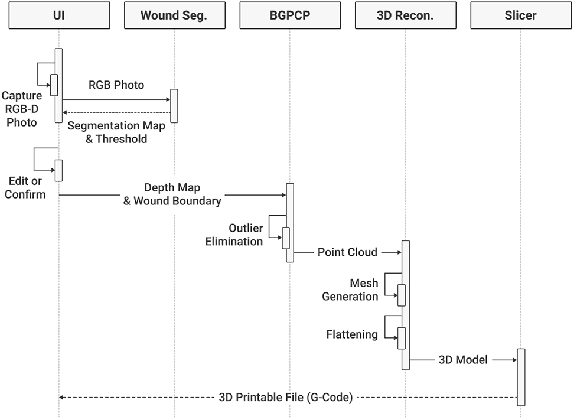
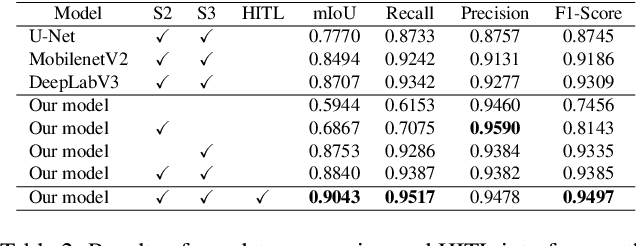
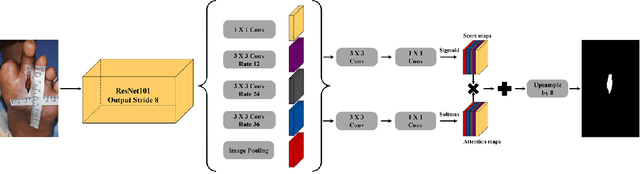
We introduce AiD Regen, a novel system that generates 3D wound models combining 2D semantic segmentation with 3D reconstruction so that they can be printed via 3D bio-printers during the surgery to treat diabetic foot ulcers (DFUs). AiD Regen seamlessly binds the full pipeline, which includes RGB-D image capturing, semantic segmentation, boundary-guided point-cloud processing, 3D model reconstruction, and 3D printable G-code generation, into a single system that can be used out of the box. We developed a multi-stage data preprocessing method to handle small and unbalanced DFU image datasets. AiD Regen's human-in-the-loop machine learning interface enables clinicians to not only create 3D regenerative patches with just a few touch interactions but also customize and confirm wound boundaries. As evidenced by our experiments, our model outperforms prior wound segmentation models and our reconstruction algorithm is capable of generating 3D wound models with compelling accuracy. We further conducted a case study on a real DFU patient and demonstrated the effectiveness of AiD Regen in treating DFU wounds.
3D Object Detection from Images for Autonomous Driving: A Survey
Feb 12, 2022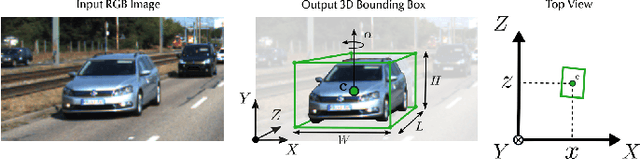
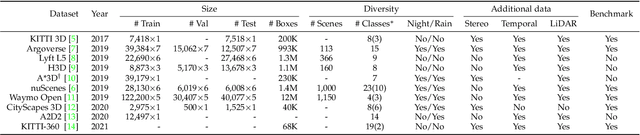
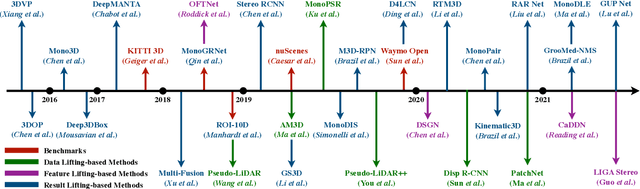
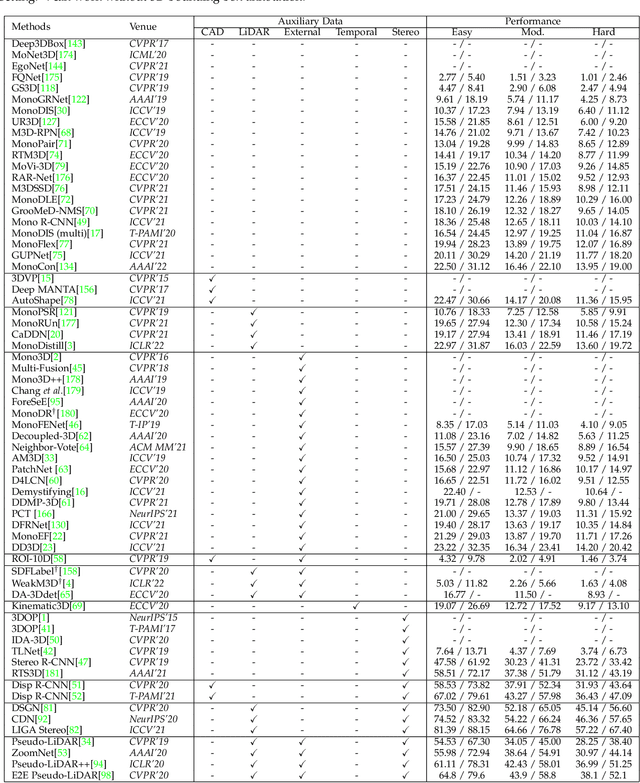
3D object detection from images, one of the fundamental and challenging problems in autonomous driving, has received increasing attention from both industry and academia in recent years. Benefiting from the rapid development of deep learning technologies, image-based 3D detection has achieved remarkable progress. Particularly, more than 200 works have studied this problem from 2015 to 2021, encompassing a broad spectrum of theories, algorithms, and applications. However, to date no recent survey exists to collect and organize this knowledge. In this paper, we fill this gap in the literature and provide the first comprehensive survey of this novel and continuously growing research field, summarizing the most commonly used pipelines for image-based 3D detection and deeply analyzing each of their components. Additionally, we also propose two new taxonomies to organize the state-of-the-art methods into different categories, with the intent of providing a more systematic review of existing methods and facilitating fair comparisons with future works. In retrospect of what has been achieved so far, we also analyze the current challenges in the field and discuss future directions for image-based 3D detection research.