 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage inpainting using frequency domain priors
Paper and Code

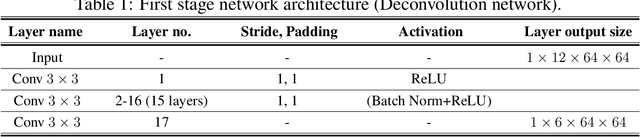
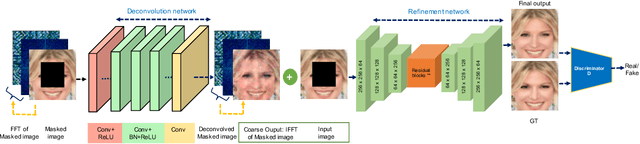
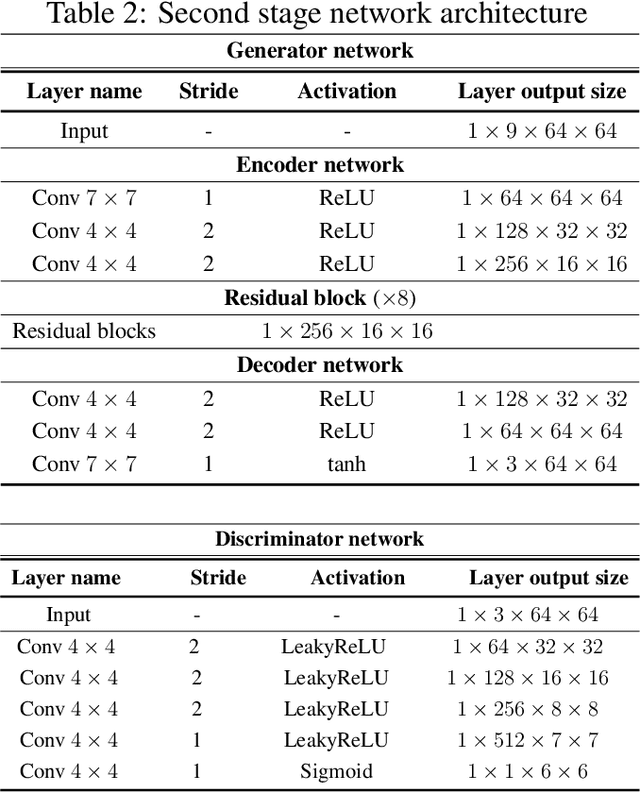
In this paper, we present a novel image inpainting technique using frequency domain information. Prior works on image inpainting predict the missing pixels by training neural networks using only the spatial domain information. However, these methods still struggle to reconstruct high-frequency details for real complex scenes, leading to a discrepancy in color, boundary artifacts, distorted patterns, and blurry textures. To alleviate these problems, we investigate if it is possible to obtain better performance by training the networks using frequency domain information (Discrete Fourier Transform) along with the spatial domain information. To this end, we propose a frequency-based deconvolution module that enables the network to learn the global context while selectively reconstructing the high-frequency components. We evaluate our proposed method on the publicly available datasets CelebA, Paris Streetview, and DTD texture dataset, and show that our method outperforms current state-of-the-art image inpainting techniques both qualitatively and quantitatively.