 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hybrid CNN Bi-LSTM neural network for Hyperspectral image classification
Feb 15, 2024
Hyper spectral images have drawn the attention of the researchers for its complexity to classify. It has nonlinear relation between the materials and the spectral information provided by the HSI image. Deep learning methods have shown superiority in learning this nonlinearity in comparison to traditional machine learning methods. Use of 3-D CNN along with 2-D CNN have shown great success for learning spatial and spectral features. However, it uses comparatively large number of parameters. Moreover, it is not effective to learn inter layer information. Hence, this paper proposes a neural network combining 3-D CNN, 2-D CNN and Bi-LSTM. The performance of this model has been tested on Indian Pines(IP) University of Pavia(PU) and Salinas Scene(SA) data sets. The results are compared with the state of-the-art deep learning-based models. This model performed better in all three datasets. It could achieve 99.83, 99.98 and 100 percent accuracy using only 30 percent trainable parameters of the state-of-art model in IP, PU and SA datasets respectively.
Region-Aware Exposure Consistency Network for Mixed Exposure Correction
Feb 28, 2024Exposure correction aims to enhance images suffering from improper exposure to achieve satisfactory visual effects. Despite recent progress, existing methods generally mitigate either overexposure or underexposure in input images, and they still struggle to handle images with mixed exposure, i.e., one image incorporates both overexposed and underexposed regions. The mixed exposure distribution is non-uniform and leads to varying representation, which makes it challenging to address in a unified process. In this paper, we introduce an effective Region-aware Exposure Correction Network (RECNet) that can handle mixed exposure by adaptively learning and bridging different regional exposure representations. Specifically, to address the challenge posed by mixed exposure disparities, we develop a region-aware de-exposure module that effectively translates regional features of mixed exposure scenarios into an exposure-invariant feature space. Simultaneously, as de-exposure operation inevitably reduces discriminative information, we introduce a mixed-scale restoration unit that integrates exposure-invariant features and unprocessed features to recover local information. To further achieve a uniform exposure distribution in the global image, we propose an exposure contrastive regularization strategy under the constraints of intra-regional exposure consistency and inter-regional exposure continuity. Extensive experiments are conducted on various datasets, and the experimental results demonstrate the superiority and generalization of our proposed method. The code is released at: https://github.com/kravrolens/RECNet.
DISORF: A Distributed Online NeRF Training and Rendering Framework for Mobile Robots
Mar 01, 2024

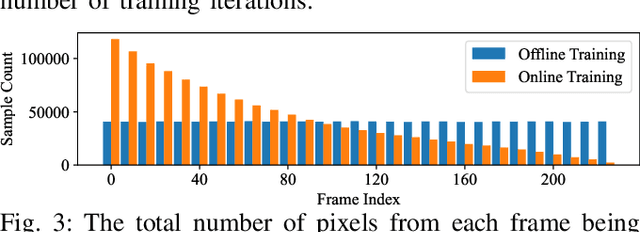
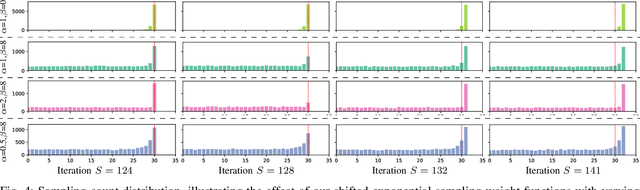
We present a framework, DISORF, to enable online 3D reconstruction and visualization of scenes captured by resource-constrained mobile robots and edge devices. To address the limited compute capabilities of edge devices and potentially limited network availability, we design a framework that efficiently distributes computation between the edge device and remote server. We leverage on-device SLAM systems to generate posed keyframes and transmit them to remote servers that can perform high quality 3D reconstruction and visualization at runtime by leveraging NeRF models. We identify a key challenge with online NeRF training where naive image sampling strategies can lead to significant degradation in rendering quality. We propose a novel shifted exponential frame sampling method that addresses this challenge for online NeRF training. We demonstrate the effectiveness of our framework in enabling high-quality real-time reconstruction and visualization of unknown scenes as they are captured and streamed from cameras in mobile robots and edge devices.
Phase retrieval beyond the homogeneous object assumption for X-ray in-line holographic imaging
Mar 01, 2024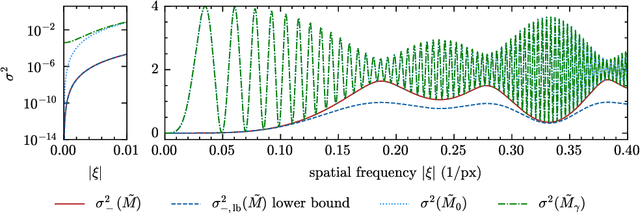



X-ray near field holography has proven to be a powerful 2D and 3D imaging technique with applications ranging from biomedical research to material sciences. To reconstruct meaningful and quantitative images from the measurement intensities, however, it relies on computational phase retrieval which in many cases assumes the phase-shift and attenuation coefficient of the sample to be proportional. Here, we demonstrate an efficient phase retrieval algorithm that does not rely on this homogeneous-object assumption and is a generalization of the well-established contrast-transfer-function (CTF) approach. We then investigate its stability and present an experimental study comparing the proposed algorithm with established methods. The algorithm shows superior reconstruction quality compared to the established CTF-based method at similar computational cost. Our analysis provides a deeper fundamental understanding of the homogeneous object assumption and the proposed algorithm will help improve the image quality for near-field holography in biomedical applications
A Large-scale Evaluation of Pretraining Paradigms for the Detection of Defects in Electroluminescence Solar Cell Images
Feb 27, 2024Pretraining has been shown to improve performance in many domains, including semantic segmentation, especially in domains with limited labelled data. In this work, we perform a large-scale evaluation and benchmarking of various pretraining methods for Solar Cell Defect Detection (SCDD) in electroluminescence images, a field with limited labelled datasets. We cover supervised training with semantic segmentation, semi-supervised learning, and two self-supervised techniques. We also experiment with both in-distribution and out-of-distribution (OOD) pretraining and observe how this affects downstream performance. The results suggest that supervised training on a large OOD dataset (COCO), self-supervised pretraining on a large OOD dataset (ImageNet), and semi-supervised pretraining (CCT) all yield statistically equivalent performance for mean Intersection over Union (mIoU). We achieve a new state-of-the-art for SCDD and demonstrate that certain pretraining schemes result in superior performance on underrepresented classes. Additionally, we provide a large-scale unlabelled EL image dataset of $22000$ images, and a $642$-image labelled semantic segmentation EL dataset, for further research in developing self- and semi-supervised training techniques in this domain.
PHNet: Patch-based Normalization for Portrait Harmonization
Feb 27, 2024A common problem for composite images is the incompatibility of their foreground and background components. Image harmonization aims to solve this problem, making the whole image look more authentic and coherent. Most existing solutions predict lookup tables (LUTs) or reconstruct images, utilizing various attributes of composite images. Recent approaches have primarily focused on employing global transformations like normalization and color curve rendering to achieve visual consistency, and they often overlook the importance of local visual coherence. We present a patch-based harmonization network consisting of novel Patch-based normalization (PN) blocks and a feature extractor based on statistical color transfer. Extensive experiments demonstrate the network's high generalization capability for different domains. Our network achieves state-of-the-art results on the iHarmony4 dataset. Also, we created a new human portrait harmonization dataset based on FFHQ and checked the proposed method to show the generalization ability by achieving the best metrics on it. The benchmark experiments confirm that the suggested patch-based normalization block and feature extractor effectively improve the network's capability to harmonize portraits. Our code and model baselines are publicly available.
Structure-Guided Adversarial Training of Diffusion Models
Feb 27, 2024Diffusion models have demonstrated exceptional efficacy in various generative applications. While existing models focus on minimizing a weighted sum of denoising score matching losses for data distribution modeling, their training primarily emphasizes instance-level optimization, overlooking valuable structural information within each mini-batch, indicative of pair-wise relationships among samples. To address this limitation, we introduce Structure-guided Adversarial training of Diffusion Models (SADM). In this pioneering approach, we compel the model to learn manifold structures between samples in each training batch. To ensure the model captures authentic manifold structures in the data distribution, we advocate adversarial training of the diffusion generator against a novel structure discriminator in a minimax game, distinguishing real manifold structures from the generated ones. SADM substantially improves existing diffusion transformers (DiT) and outperforms existing methods in image generation and cross-domain fine-tuning tasks across 12 datasets, establishing a new state-of-the-art FID of 1.58 and 2.11 on ImageNet for class-conditional image generation at resolutions of 256x256 and 512x512, respectively.
CCC: Color Classified Colorization
Mar 03, 2024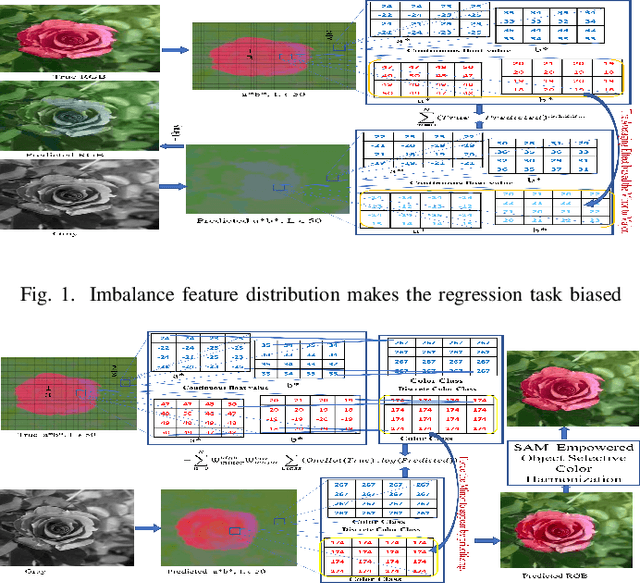
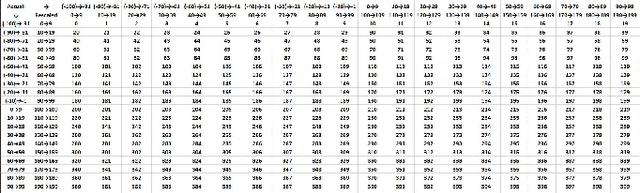
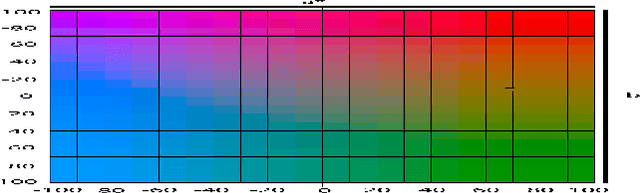
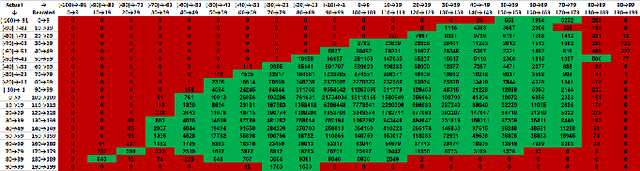
Automatic colorization of gray images with objects of different colors and sizes is challenging due to inter- and intra-object color variation and the small area of the main objects due to extensive backgrounds. The learning process often favors dominant features, resulting in a biased model. In this paper, we formulate the colorization problem into a multinomial classification problem and then apply a weighted function to classes. We propose a set of formulas to transform color values into color classes and vice versa. Class optimization and balancing feature distribution are the keys for good performance. Observing class appearance on various extremely large-scale real-time images in practice, we propose 215 color classes for our colorization task. During training, we propose a class-weighted function based on true class appearance in each batch to ensure proper color saturation of individual objects. We establish a trade-off between major and minor classes to provide orthodox class prediction by eliminating major classes' dominance over minor classes. As we apply regularization to enhance the stability of the minor class, occasional minor noise may appear at the object's edges. We propose a novel object-selective color harmonization method empowered by the SAM to refine and enhance these edges. We propose a new color image evaluation metric, the Chromatic Number Ratio (CNR), to quantify the richness of color components. We compare our proposed model with state-of-the-art models using five different datasets: ADE, Celeba, COCO, Oxford 102 Flower, and ImageNet, in both qualitative and quantitative approaches. The experimental results show that our proposed model outstrips other models in visualization and CNR measurement criteria while maintaining satisfactory performance in regression (MSE, PSNR), similarity (SSIM, LPIPS, UIQI), and generative criteria (FID).
Training-free image style alignment for self-adapting domain shift on handheld ultrasound devices
Feb 17, 2024Handheld ultrasound devices face usage limitations due to user inexperience and cannot benefit from supervised deep learning without extensive expert annotations. Moreover, the models trained on standard ultrasound device data are constrained by training data distribution and perform poorly when directly applied to handheld device data. In this study, we propose the Training-free Image Style Alignment (TISA) framework to align the style of handheld device data to those of standard devices. The proposed TISA can directly infer handheld device images without extra training and is suited for clinical applications. We show that TISA performs better and more stably in medical detection and segmentation tasks for handheld device data. We further validate TISA as the clinical model for automatic measurements of spinal curvature and carotid intima-media thickness. The automatic measurements agree well with manual measurements made by human experts and the measurement errors remain within clinically acceptable ranges. We demonstrate the potential for TISA to facilitate automatic diagnosis on handheld ultrasound devices and expedite their eventual widespread use.
Anatomically-Controllable Medical Image Generation with Segmentation-Guided Diffusion Models
Feb 09, 2024Diffusion models have enabled remarkably high-quality medical image generation, which can help mitigate the expenses of acquiring and annotating new images by supplementing small or imbalanced datasets, along with other applications. However, these are hampered by the challenge of enforcing global anatomical realism in generated images. To this end, we propose a diffusion model for anatomically-controlled medical image generation. Our model follows a multi-class anatomical segmentation mask at each sampling step and incorporates a \textit{random mask ablation} training algorithm, to enable conditioning on a selected combination of anatomical constraints while allowing flexibility in other anatomical areas. This also improves the network's learning of anatomical realism for the completely unconditional (unconstrained generation) case. Comparative evaluation on breast MRI and abdominal/neck-to-pelvis CT datasets demonstrates superior anatomical realism and input mask faithfulness over state-of-the-art models. We also offer an accessible codebase and release a dataset of generated paired breast MRIs. Our approach facilitates diverse applications, including pre-registered image generation, counterfactual scenarios, and others.