 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXPR: An Extensible Cross-Platform Point-Based Differentiable Renderer
Jun 10, 2026Point-based differentiable rendering underpins modern 3D reconstruction, novel-view synthesis, and learning-based graphics pipelines, but developing new rendering methods often requires extensive low-level implementation, hardware-specific kernels, and manually written backward passes. This limits rapid prototyping, reproducibility, exploration, and deployment, especially across diverse hardware platforms. This paper presents XPR, an extensible cross-platform framework for point-based differentiable rendering. XPR introduces a high-level programming interface that separates method-specific logic from the shared rendering pipeline, allowing users to implement new methods in a few lines of code. Its pipeline decomposes rendering into modular, statically shaped parallel operations that can be lowered by a cross-platform compiler to GPUs, TPUs, CPUs, and other ML accelerators. We demonstrate implementations of 3DGS, 3DGUT, and LinPrim, with only a few 100s lines of Python code, each of which can be compiled to a range of hardware platforms with the XLA compiler. These results show that XPR enables fast experimentation and portable execution for emerging point-based differentiable rendering systems.
A Tensor Compiler for Processing-In-Memory Architectures
Nov 19, 2025Processing-In-Memory (PIM) devices integrated with high-performance Host processors (e.g., GPUs) can accelerate memory-intensive kernels in Machine Learning (ML) models, including Large Language Models (LLMs), by leveraging high memory bandwidth at PIM cores. However, Host processors and PIM cores require different data layouts: Hosts need consecutive elements distributed across DRAM banks, while PIM cores need them within local banks. This necessitates data rearrangements in ML kernel execution that pose significant performance and programmability challenges, further exacerbated by the need to support diverse PIM backends. Current compilation approaches lack systematic optimization for diverse ML kernels across multiple PIM backends and may largely ignore data rearrangements during compute code optimization. We demonstrate that data rearrangements and compute code optimization are interdependent, and need to be jointly optimized during the tuning process. To address this, we design DCC, the first data-centric ML compiler for PIM systems that jointly co-optimizes data rearrangements and compute code in a unified tuning process. DCC integrates a multi-layer PIM abstraction that enables various data distribution and processing strategies on different PIM backends. DCC enables effective co-optimization by mapping data partitioning strategies to compute loop partitions, applying PIM-specific code optimizations and leveraging a fast and accurate performance prediction model to select optimal configurations. Our evaluations in various individual ML kernels demonstrate that DCC achieves up to 7.68x speedup (2.7x average) on HBM-PIM and up to 13.17x speedup (5.75x average) on AttAcc PIM backend over GPU-only execution. In end-to-end LLM inference, DCC on AttAcc accelerates GPT-3 and LLaMA-2 by up to 7.71x (4.88x average) over GPU.
ContraGS: Codebook-Condensed and Trainable Gaussian Splatting for Fast, Memory-Efficient Reconstruction
Sep 03, 20253D Gaussian Splatting (3DGS) is a state-of-art technique to model real-world scenes with high quality and real-time rendering. Typically, a higher quality representation can be achieved by using a large number of 3D Gaussians. However, using large 3D Gaussian counts significantly increases the GPU device memory for storing model parameters. A large model thus requires powerful GPUs with high memory capacities for training and has slower training/rendering latencies due to the inefficiencies of memory access and data movement. In this work, we introduce ContraGS, a method to enable training directly on compressed 3DGS representations without reducing the Gaussian Counts, and thus with a little loss in model quality. ContraGS leverages codebooks to compactly store a set of Gaussian parameter vectors throughout the training process, thereby significantly reducing memory consumption. While codebooks have been demonstrated to be highly effective at compressing fully trained 3DGS models, directly training using codebook representations is an unsolved challenge. ContraGS solves the problem of learning non-differentiable parameters in codebook-compressed representations by posing parameter estimation as a Bayesian inference problem. To this end, ContraGS provides a framework that effectively uses MCMC sampling to sample over a posterior distribution of these compressed representations. With ContraGS, we demonstrate that ContraGS significantly reduces the peak memory during training (on average 3.49X) and accelerated training and rendering (1.36X and 1.88X on average, respectively), while retraining close to state-of-art quality.
Squeeze3D: Your 3D Generation Model is Secretly an Extreme Neural Compressor
Jun 09, 2025



We propose Squeeze3D, a novel framework that leverages implicit prior knowledge learnt by existing pre-trained 3D generative models to compress 3D data at extremely high compression ratios. Our approach bridges the latent spaces between a pre-trained encoder and a pre-trained generation model through trainable mapping networks. Any 3D model represented as a mesh, point cloud, or a radiance field is first encoded by the pre-trained encoder and then transformed (i.e. compressed) into a highly compact latent code. This latent code can effectively be used as an extremely compressed representation of the mesh or point cloud. A mapping network transforms the compressed latent code into the latent space of a powerful generative model, which is then conditioned to recreate the original 3D model (i.e. decompression). Squeeze3D is trained entirely on generated synthetic data and does not require any 3D datasets. The Squeeze3D architecture can be flexibly used with existing pre-trained 3D encoders and existing generative models. It can flexibly support different formats, including meshes, point clouds, and radiance fields. Our experiments demonstrate that Squeeze3D achieves compression ratios of up to 2187x for textured meshes, 55x for point clouds, and 619x for radiance fields while maintaining visual quality comparable to many existing methods. Squeeze3D only incurs a small compression and decompression latency since it does not involve training object-specific networks to compress an object.
DISORF: A Distributed Online NeRF Training and Rendering Framework for Mobile Robots
Mar 01, 2024



We present a framework, DISORF, to enable online 3D reconstruction and visualization of scenes captured by resource-constrained mobile robots and edge devices. To address the limited compute capabilities of edge devices and potentially limited network availability, we design a framework that efficiently distributes computation between the edge device and remote server. We leverage on-device SLAM systems to generate posed keyframes and transmit them to remote servers that can perform high quality 3D reconstruction and visualization at runtime by leveraging NeRF models. We identify a key challenge with online NeRF training where naive image sampling strategies can lead to significant degradation in rendering quality. We propose a novel shifted exponential frame sampling method that addresses this challenge for online NeRF training. We demonstrate the effectiveness of our framework in enabling high-quality real-time reconstruction and visualization of unknown scenes as they are captured and streamed from cameras in mobile robots and edge devices.
EvConv: Fast CNN Inference on Event Camera Inputs For High-Speed Robot Perception
Mar 08, 2023



Event cameras capture visual information with a high temporal resolution and a wide dynamic range. This enables capturing visual information at fine time granularities (e.g., microseconds) in rapidly changing environments. This makes event cameras highly useful for high-speed robotics tasks involving rapid motion, such as high-speed perception, object tracking, and control. However, convolutional neural network inference on event camera streams cannot currently perform real-time inference at the high speeds at which event cameras operate - current CNN inference times are typically closer in order of magnitude to the frame rates of regular frame-based cameras. Real-time inference at event camera rates is necessary to fully leverage the high frequency and high temporal resolution that event cameras offer. This paper presents EvConv, a new approach to enable fast inference on CNNs for inputs from event cameras. We observe that consecutive inputs to the CNN from an event camera have only small differences between them. Thus, we propose to perform inference on the difference between consecutive input tensors, or the increment. This enables a significant reduction in the number of floating-point operations required (and thus the inference latency) because increments are very sparse. We design EvConv to leverage the irregular sparsity in increments from event cameras and to retain the sparsity of these increments across all layers of the network. We demonstrate a reduction in the number of floating operations required in the forward pass by up to 98%. We also demonstrate a speedup of up to 1.6X for inference using CNNs for tasks such as depth estimation, object recognition, and optical flow estimation, with almost no loss in accuracy.
VoxelCache: Accelerating Online Mapping in Robotics and 3D Reconstruction Tasks
Oct 17, 2022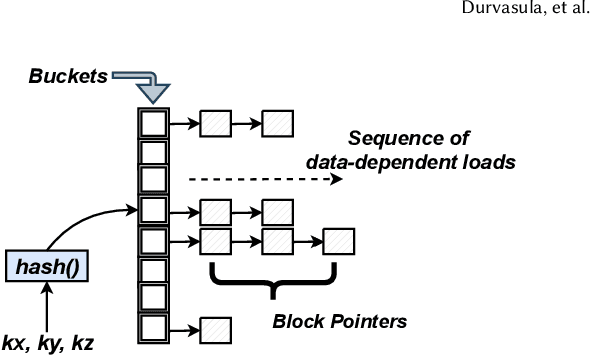
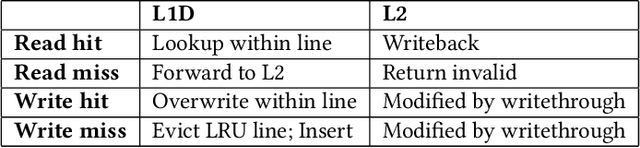
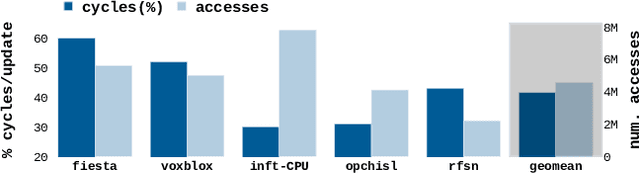
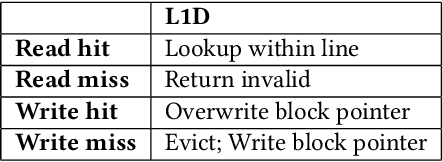
Real-time 3D mapping is a critical component in many important applications today including robotics, AR/VR, and 3D visualization. 3D mapping involves continuously fusing depth maps obtained from depth sensors in phones, robots, and autonomous vehicles into a single 3D representative model of the scene. Many important applications, e.g., global path planning and trajectory generation in micro aerial vehicles, require the construction of large maps at high resolutions. In this work, we identify mapping, i.e., construction and updates of 3D maps to be a critical bottleneck in these applications. The memory required and access times of these maps limit the size of the environment and the resolution with which the environment can be feasibly mapped, especially in resource constrained environments such as autonomous robot platforms and portable devices. To address this challenge, we propose VoxelCache: a hardware-software technique to accelerate map data access times in 3D mapping applications. We observe that mapping applications typically access voxels in the map that are spatially co-located to each other. We leverage this temporal locality in voxel accesses to cache indices to blocks of voxels to enable quick lookup and avoid expensive access times. We evaluate VoxelCache on popularly used mapping and reconstruction applications on both GPUs and CPUs. We demonstrate an average speedup of 1.47X (up to 1.66X) and 1.79X (up to 1.91X) on CPUs and GPUs respectively.