 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cross-lingual Adaptation for Recipe Retrieval with Mixup
May 08, 2022
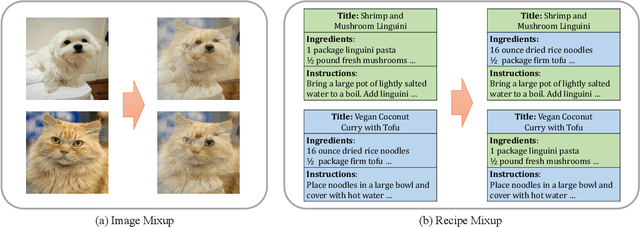
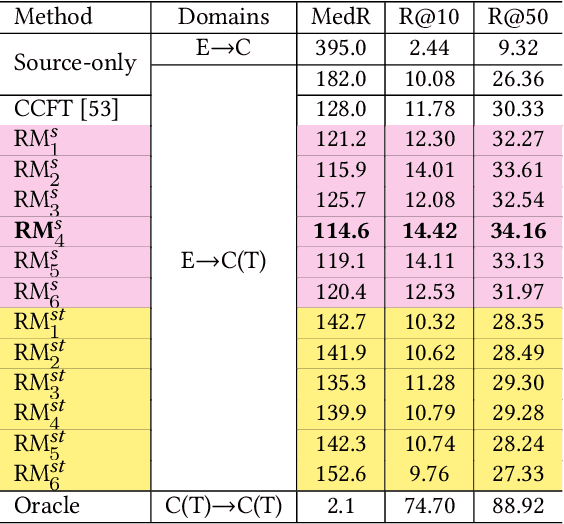
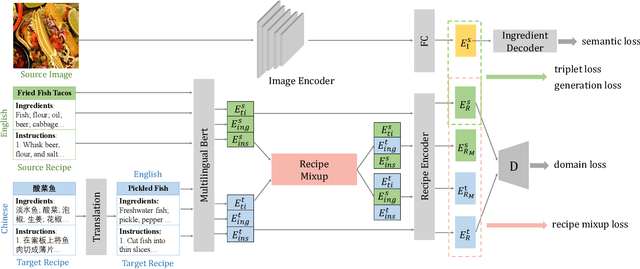
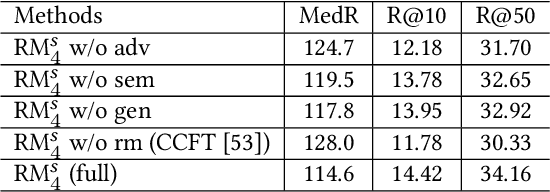
Cross-modal recipe retrieval has attracted research attention in recent years, thanks to the availability of large-scale paired data for training. Nevertheless, obtaining adequate recipe-image pairs covering the majority of cuisines for supervised learning is difficult if not impossible. By transferring knowledge learnt from a data-rich cuisine to a data-scarce cuisine, domain adaptation sheds light on this practical problem. Nevertheless, existing works assume recipes in source and target domains are mostly originated from the same cuisine and written in the same language. This paper studies unsupervised domain adaptation for image-to-recipe retrieval, where recipes in source and target domains are in different languages. Moreover, only recipes are available for training in the target domain. A novel recipe mixup method is proposed to learn transferable embedding features between the two domains. Specifically, recipe mixup produces mixed recipes to form an intermediate domain by discretely exchanging the section(s) between source and target recipes. To bridge the domain gap, recipe mixup loss is proposed to enforce the intermediate domain to locate in the shortest geodesic path between source and target domains in the recipe embedding space. By using Recipe 1M dataset as source domain (English) and Vireo-FoodTransfer dataset as target domain (Chinese), empirical experiments verify the effectiveness of recipe mixup for cross-lingual adaptation in the context of image-to-recipe retrieval.
p-Meta: Towards On-device Deep Model Adaptation
Jun 25, 2022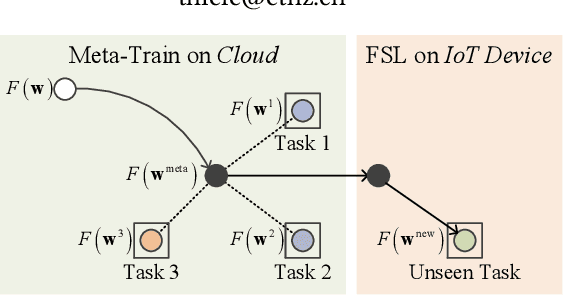

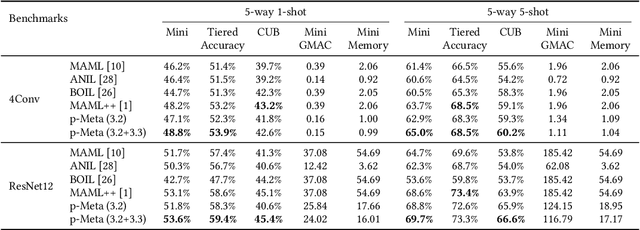
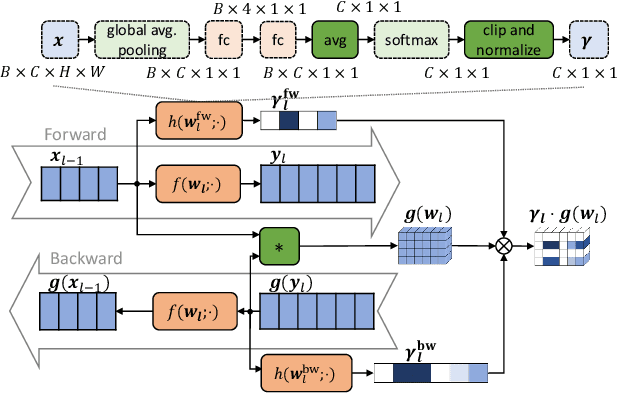
Data collected by IoT devices are often private and have a large diversity across users. Therefore, learning requires pre-training a model with available representative data samples, deploying the pre-trained model on IoT devices, and adapting the deployed model on the device with local data. Such an on-device adaption for deep learning empowered applications demands data and memory efficiency. However, existing gradient-based meta learning schemes fail to support memory-efficient adaptation. To this end, we propose p-Meta, a new meta learning method that enforces structure-wise partial parameter updates while ensuring fast generalization to unseen tasks. Evaluations on few-shot image classification and reinforcement learning tasks show that p-Meta not only improves the accuracy but also substantially reduces the peak dynamic memory by a factor of 2.5 on average compared to state-of-the-art few-shot adaptation methods.
Epicardial Adipose Tissue Segmentation from CT Images with A Semi-3D Neural Network
Apr 27, 2022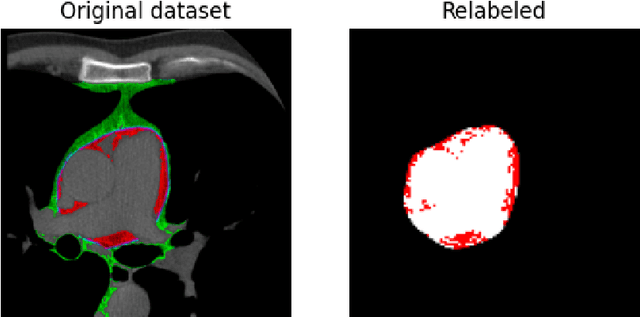


Epicardial adipose tissue is a type of adipose tissue located between the heart wall and a protective layer around the heart called the pericardium. The volume and thickness of epicardial adipose tissue are linked to various cardiovascular diseases. It is shown to be an independent cardiovascular disease risk factor. Fully automatic and reliable measurements of epicardial adipose tissue from CT scans could provide better disease risk assessment and enable the processing of large CT image data sets for a systemic epicardial adipose tissue study. This paper proposes a method for fully automatic semantic segmentation of epicardial adipose tissue from CT images using a deep neural network. The proposed network uses a U-Net-based architecture with slice depth information embedded in the input image to segment a pericardium region of interest, which is used to obtain an epicardial adipose tissue segmentation. Image augmentation is used to increase model robustness. Cross-validation of the proposed method yields a Dice score of 0.86 on the CT scans of 20 patients.
Object-Aware Self-supervised Multi-Label Learning
May 14, 2022

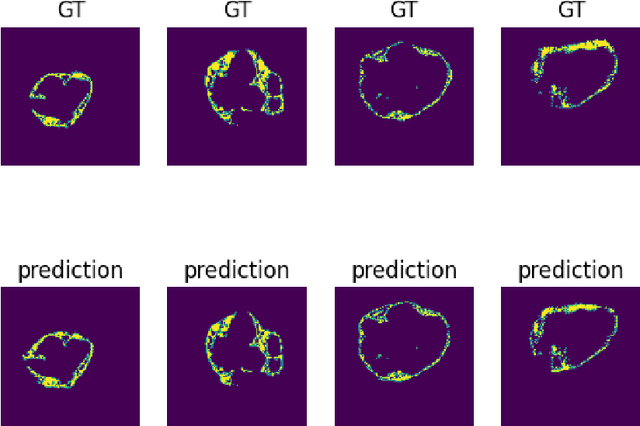
Multi-label Learning on Image data has been widely exploited with deep learning models. However, supervised training on deep CNN models often cannot discover sufficient discriminative features for classification. As a result, numerous self-supervision methods are proposed to learn more robust image representations. However, most self-supervised approaches focus on single-instance single-label data and fall short on more complex images with multiple objects. Therefore, we propose an Object-Aware Self-Supervision (OASS) method to obtain more fine-grained representations for multi-label learning, dynamically generating auxiliary tasks based on object locations. Secondly, the robust representation learned by OASS can be leveraged to efficiently generate Class-Specific Instances (CSI) in a proposal-free fashion to better guide multi-label supervision signal transfer to instances. Extensive experiments on the VOC2012 dataset for multi-label classification demonstrate the effectiveness of the proposed method against the state-of-the-art counterparts.
Efficient Self-supervised Vision Pretraining with Local Masked Reconstruction
Jun 01, 2022
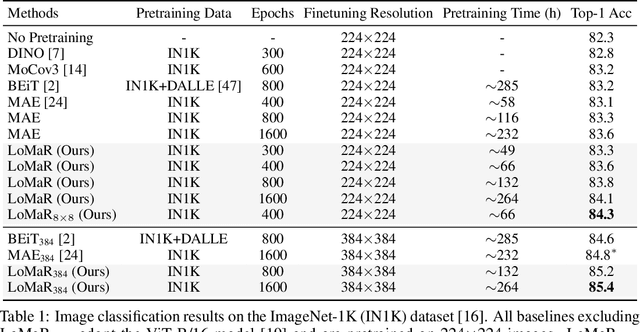
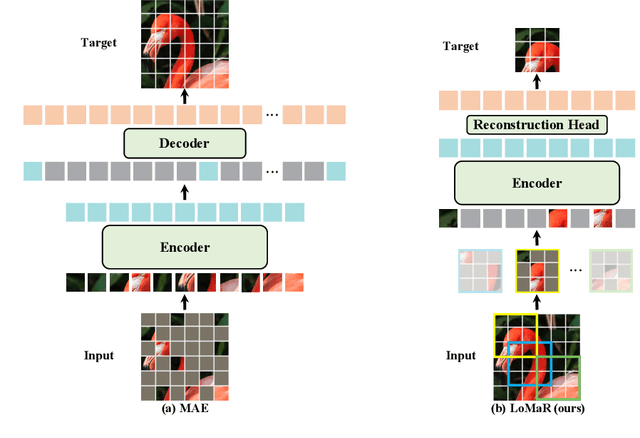
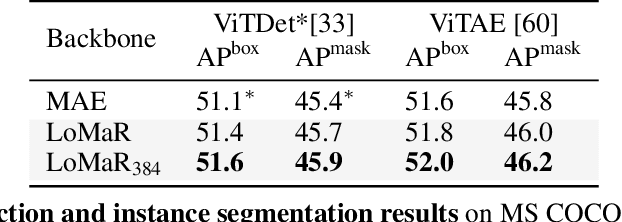
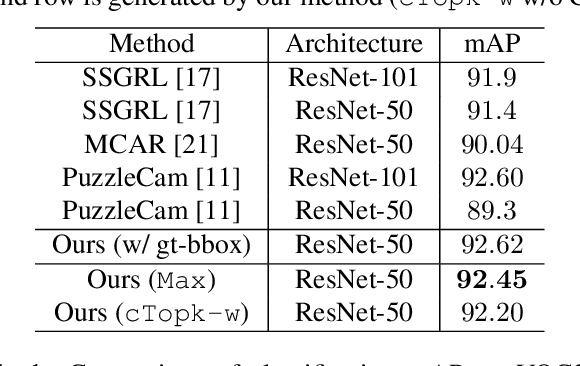
Self-supervised learning for computer vision has achieved tremendous progress and improved many downstream vision tasks such as image classification, semantic segmentation, and object detection. Among these, generative self-supervised vision learning approaches such as MAE and BEiT show promising performance. However, their global masked reconstruction mechanism is computationally demanding. To address this issue, we propose local masked reconstruction (LoMaR), a simple yet effective approach that performs masked reconstruction within a small window of 7$\times$7 patches on a simple Transformer encoder, improving the trade-off between efficiency and accuracy compared to global masked reconstruction over the entire image. Extensive experiments show that LoMaR reaches 84.1% top-1 accuracy on ImageNet-1K classification, outperforming MAE by 0.5%. After finetuning the pretrained LoMaR on 384$\times$384 images, it can reach 85.4% top-1 accuracy, surpassing MAE by 0.6%. On MS COCO, LoMaR outperforms MAE by 0.5 $\text{AP}^\text{box}$ on object detection and 0.5 $\text{AP}^\text{mask}$ on instance segmentation. LoMaR is especially more computation-efficient on pretraining high-resolution images, e.g., it is 3.1$\times$ faster than MAE with 0.2% higher classification accuracy on pretraining 448$\times$448 images. This local masked reconstruction learning mechanism can be easily integrated into any other generative self-supervised learning approach. Our code will be publicly available.
Dual-branch Hybrid Learning Network for Unbiased Scene Graph Generation
Jul 16, 2022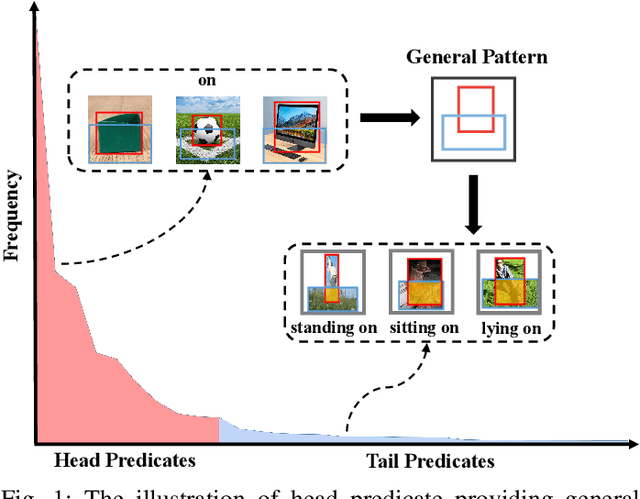
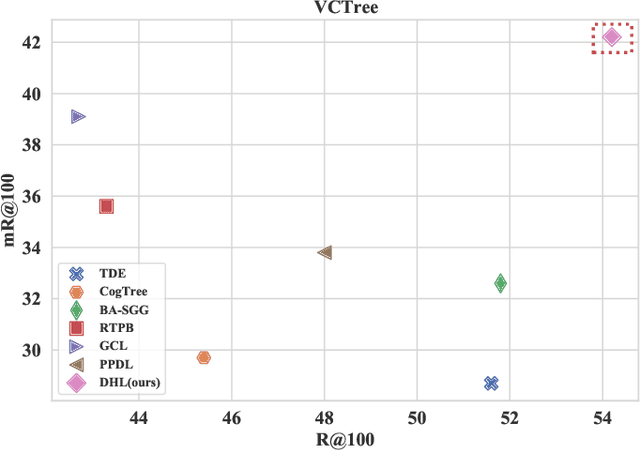
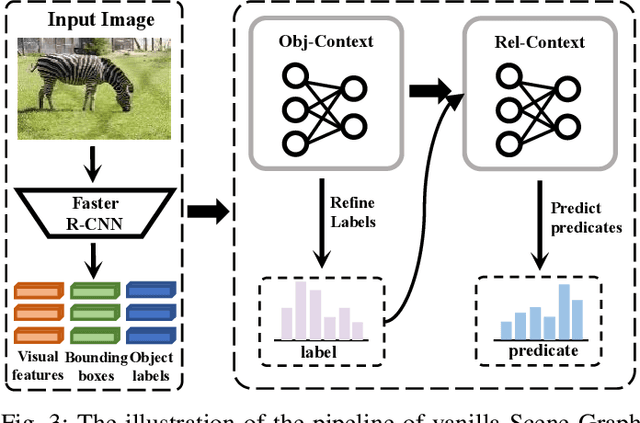
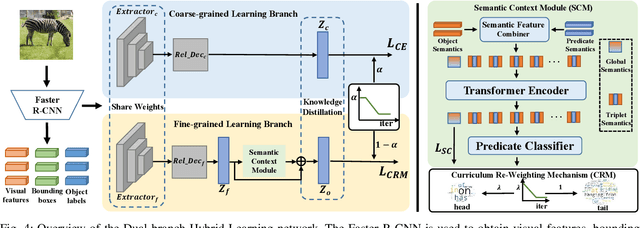
The current studies of Scene Graph Generation (SGG) focus on solving the long-tailed problem for generating unbiased scene graphs. However, most de-biasing methods overemphasize the tail predicates and underestimate head ones throughout training, thereby wrecking the representation ability of head predicate features. Furthermore, these impaired features from head predicates harm the learning of tail predicates. In fact, the inference of tail predicates heavily depends on the general patterns learned from head ones, e.g., "standing on" depends on "on". Thus, these de-biasing SGG methods can neither achieve excellent performance on tail predicates nor satisfying behaviors on head ones. To address this issue, we propose a Dual-branch Hybrid Learning network (DHL) to take care of both head predicates and tail ones for SGG, including a Coarse-grained Learning Branch (CLB) and a Fine-grained Learning Branch (FLB). Specifically, the CLB is responsible for learning expertise and robust features of head predicates, while the FLB is expected to predict informative tail predicates. Furthermore, DHL is equipped with a Branch Curriculum Schedule (BCS) to make the two branches work well together. Experiments show that our approach achieves a new state-of-the-art performance on VG and GQA datasets and makes a trade-off between the performance of tail predicates and head ones. Moreover, extensive experiments on two downstream tasks (i.e., Image Captioning and Sentence-to-Graph Retrieval) further verify the generalization and practicability of our method.
Study of the performance and scalability of federated learning for medical imaging with intermittent clients
Jul 19, 2022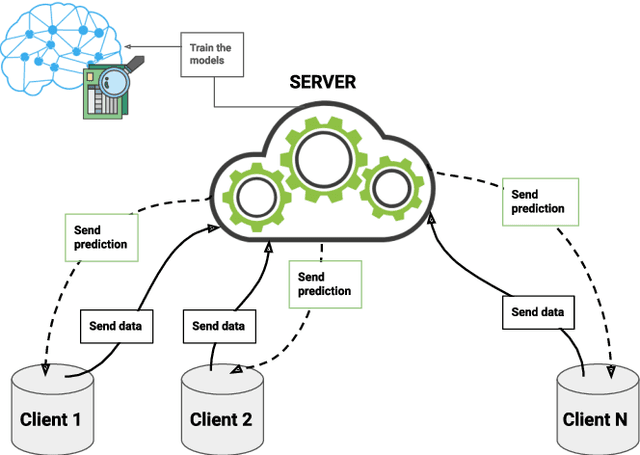
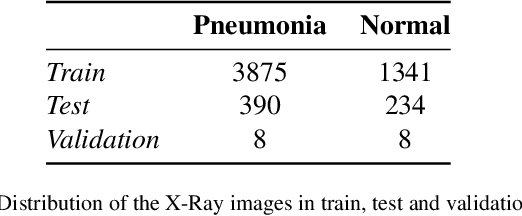
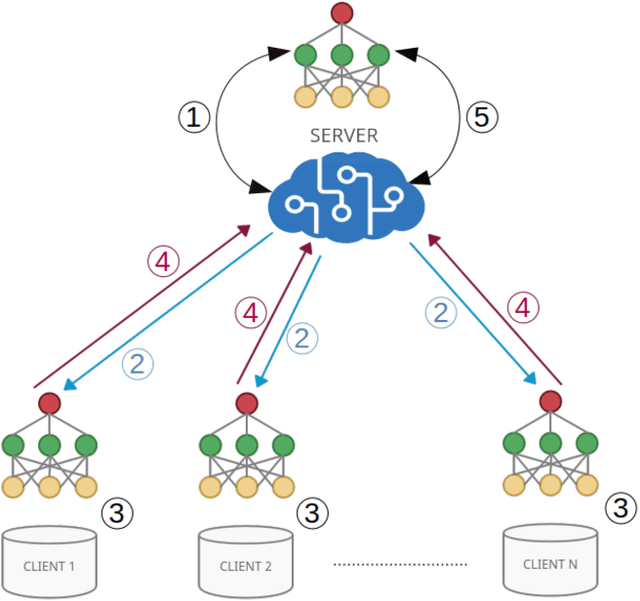
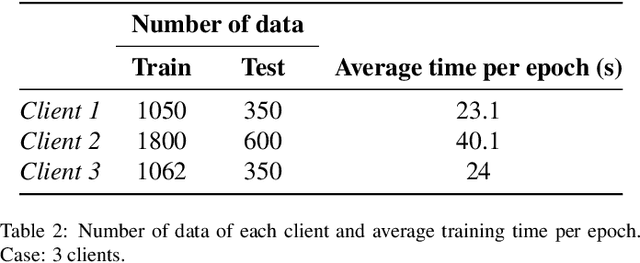
Federated learning is a data decentralization privacy-preserving technique used to perform machine or deep learning in a secure way. In this paper we present theoretical aspects about federated learning, such as the presentation of an aggregation operator, different types of federated learning, and issues to be taken into account in relation to the distribution of data from the clients, together with the exhaustive analysis of a use case where the number of clients varies. Specifically, a use case of medical image analysis is proposed, using chest X-ray images obtained from an open data repository. In addition to the advantages related to privacy, improvements in predictions (in terms of accuracy and area under the curve) and reduction of execution times will be studied with respect to the classical case (the centralized approach). Different clients will be simulated from the training data, selected in an unbalanced manner, i.e., they do not all have the same number of data. The results of considering three or ten clients are exposed and compared between them and against the centralized case. Two approaches to follow will be analyzed in the case of intermittent clients, as in a real scenario some clients may leave the training, and some new ones may enter the training. The evolution of the results for the test set in terms of accuracy, area under the curve and execution time is shown as the number of clients into which the original data is divided increases. Finally, improvements and future work in the field are proposed.
SynthTIGER: Synthetic Text Image GEneratoR Towards Better Text Recognition Models
Jul 20, 2021

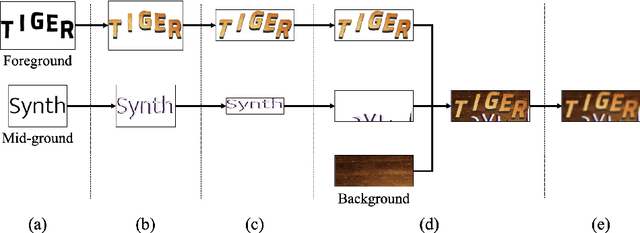
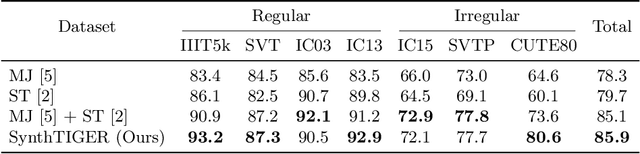
For successful scene text recognition (STR) models, synthetic text image generators have alleviated the lack of annotated text images from the real world. Specifically, they generate multiple text images with diverse backgrounds, font styles, and text shapes and enable STR models to learn visual patterns that might not be accessible from manually annotated data. In this paper, we introduce a new synthetic text image generator, SynthTIGER, by analyzing techniques used for text image synthesis and integrating effective ones under a single algorithm. Moreover, we propose two techniques that alleviate the long-tail problem in length and character distributions of training data. In our experiments, SynthTIGER achieves better STR performance than the combination of synthetic datasets, MJSynth (MJ) and SynthText (ST). Our ablation study demonstrates the benefits of using sub-components of SynthTIGER and the guideline on generating synthetic text images for STR models. Our implementation is publicly available at https://github.com/clovaai/synthtiger.
Multi-scale Network with Attentional Multi-resolution Fusion for Point Cloud Semantic Segmentation
Jun 27, 2022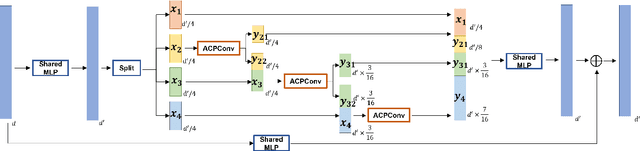
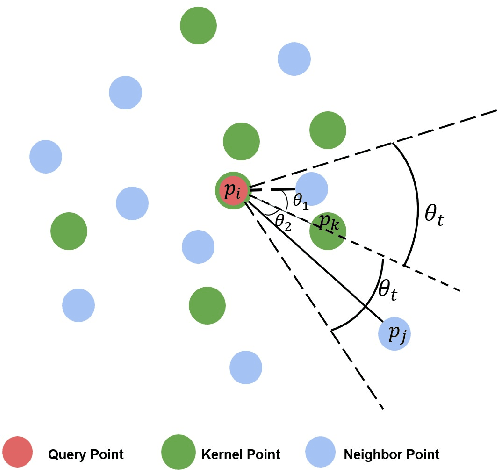
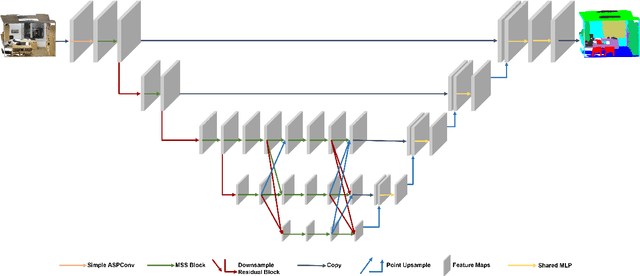
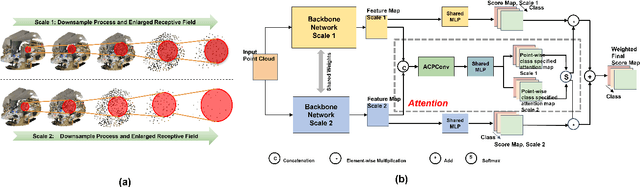
In this paper, we present a comprehensive point cloud semantic segmentation network that aggregates both local and global multi-scale information. First, we propose an Angle Correlation Point Convolution (ACPConv) module to effectively learn the local shapes of points. Second, based upon ACPConv, we introduce a local multi-scale split (MSS) block that hierarchically connects features within one single block and gradually enlarges the receptive field which is beneficial for exploiting the local context. Third, inspired by HRNet which has excellent performance on 2D image vision tasks, we build an HRNet customized for point cloud to learn global multi-scale context. Lastly, we introduce a point-wise attention fusion approach that fuses multi-resolution predictions and further improves point cloud semantic segmentation performance. Our experimental results and ablations on several benchmark datasets show that our proposed method is effective and able to achieve state-of-the-art performances compared to existing methods.
Unsupervised Image Decomposition with Phase-Correlation Networks
Oct 08, 2021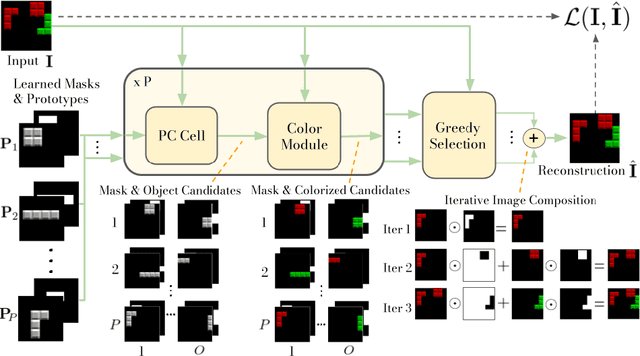
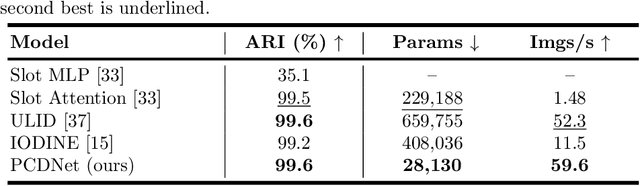
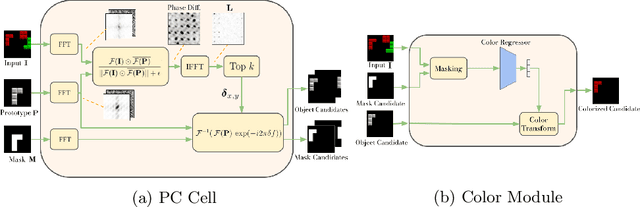

The ability to decompose scenes into their object components is a desired property for autonomous agents, allowing them to reason and act in their surroundings. Recently, different methods have been proposed to learn object-centric representations from data in an unsupervised manner. These methods often rely on latent representations learned by deep neural networks, hence requiring high computational costs and large amounts of curated data. Such models are also difficult to interpret. To address these challenges, we propose the Phase-Correlation Decomposition Network (PCDNet), a novel model that decomposes a scene into its object components, which are represented as transformed versions of a set of learned object prototypes. The core building block in PCDNet is the Phase-Correlation Cell (PC Cell), which exploits the frequency-domain representation of the images in order to estimate the transformation between an object prototype and its transformed version in the image. In our experiments, we show how PCDNet outperforms state-of-the-art methods for unsupervised object discovery and segmentation on simple benchmark datasets and on more challenging data, while using a small number of learnable parameters and being fully interpretable.