 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColorimeter-Supervised Skin Tone Estimation from Dermatoscopic Images for Fairness Auditing
Feb 10, 2026Neural-network-based diagnosis from dermatoscopic images is increasingly used for clinical decision support, yet studies report performance disparities across skin tones. Fairness auditing of these models is limited by the lack of reliable skin-tone annotations in public dermatoscopy datasets. We address this gap with neural networks that predict Fitzpatrick skin type via ordinal regression and the Individual Typology Angle (ITA) via color regression, using in-person Fitzpatrick labels and colorimeter measurements as targets. We further leverage extensive pretraining on synthetic and real dermatoscopic and clinical images. The Fitzpatrick model achieves agreement comparable to human crowdsourced annotations, and ITA predictions show high concordance with colorimeter-derived ITA, substantially outperforming pixel-averaging approaches. Applying these estimators to ISIC 2020 and MILK10k, we find that fewer than 1% of subjects belong to Fitzpatrick types V and VI. We release code and pretrained models as an open-source tool for rapid skin-tone annotation and bias auditing. This is, to our knowledge, the first dermatoscopic skin-tone estimation neural network validated against colorimeter measurements, and it supports growing evidence of clinically relevant performance gaps across skin-tone groups.
Skin Color Measurement from Dermatoscopic Images: An Evaluation on a Synthetic Dataset
Apr 06, 2025


This paper presents a comprehensive evaluation of skin color measurement methods from dermatoscopic images using a synthetic dataset (S-SYNTH) with controlled ground-truth melanin content, lesion shapes, hair models, and 18 distinct lighting conditions. This allows for rigorous assessment of the robustness and invariance to lighting conditions. We assess four classes of image colorimetry approaches: segmentation-based, patch-based, color quantization, and neural networks. We use these methods to estimate the Individual Typology Angle (ITA) and Fitzpatrick types from dermatoscopic images. Our results show that segmentation-based and color quantization methods yield robust, lighting-invariant estimates, whereas patch-based approaches exhibit significant lighting-dependent biases that require calibration. Furthermore, neural network models, particularly when combined with heavy blurring to reduce overfitting, can provide light-invariant Fitzpatrick predictions, although their generalization to real-world images remains unverified. We conclude with practical recommendations for designing fair and reliable skin color estimation methods.
Evaluation Framework for Computer Vision-Based Guidance of the Visually Impaired
Sep 20, 2022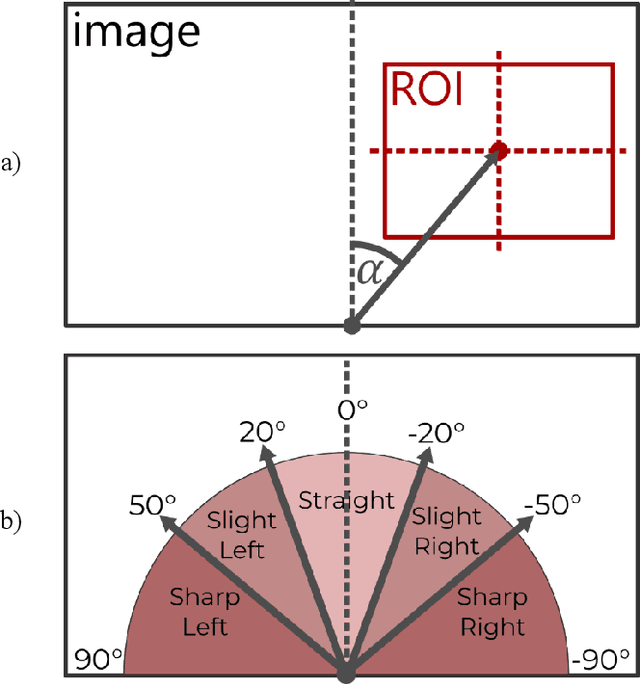
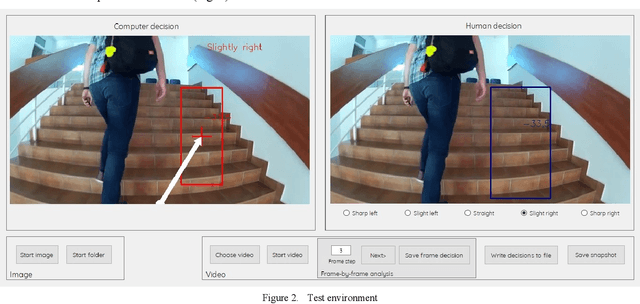
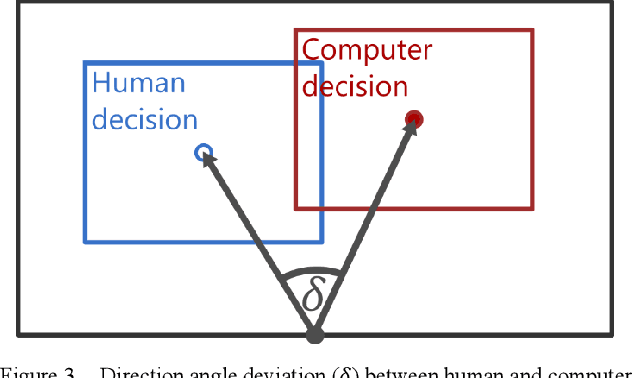
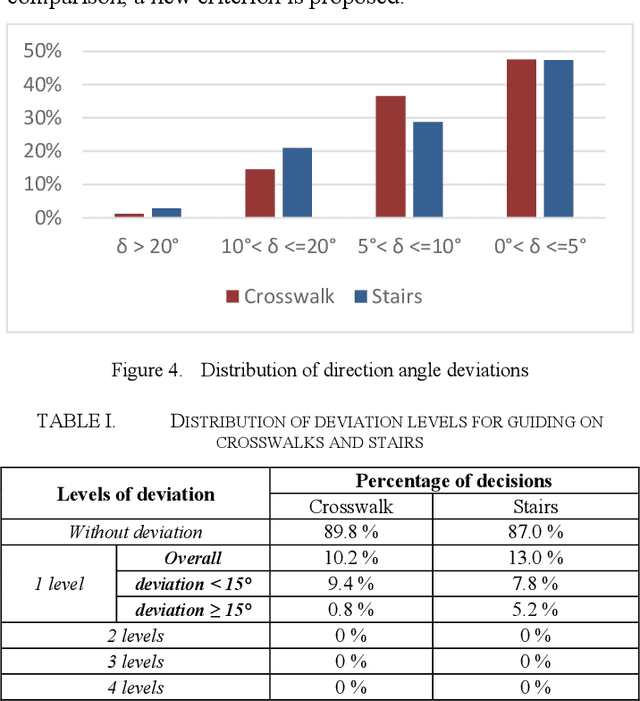
Visually impaired persons have significant problems in their everyday movement. Therefore, some of our previous work involves computer vision in developing assistance systems for guiding the visually impaired in critical situations. Some of those situations includes crosswalks on road crossings and stairs in indoor and outdoor environment. This paper presents an evaluation framework for computer vision-based guiding of the visually impaired persons in such critical situations. Presented framework includes the interface for labeling and storing referent human decisions for guiding directions and compares them to computer vision-based decisions. Since strict evaluation methodology in this research field is not clearly defined and due to the specifics of the transfer of information to visually impaired persons, evaluation criterion for specific simplified guiding instructions is proposed.
Using the Polar Transform for Efficient Deep Learning-Based Aorta Segmentation in CTA Images
Jun 21, 2022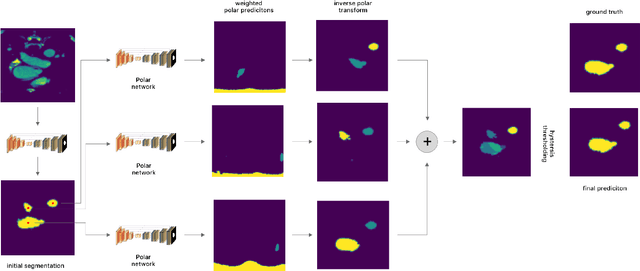
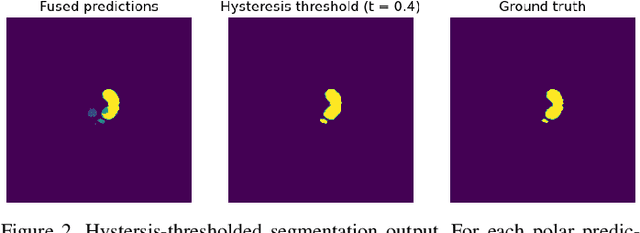
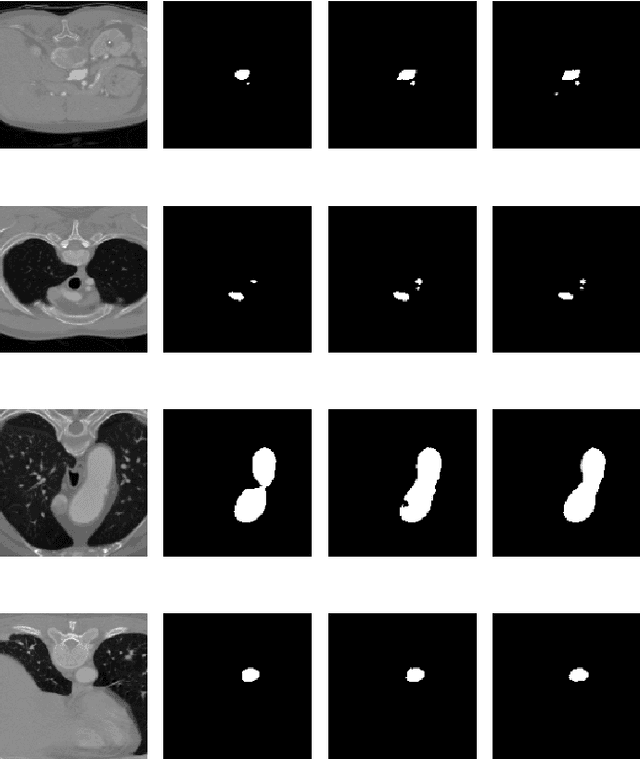
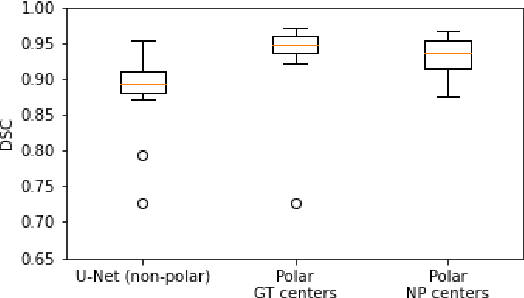
Medical image segmentation often requires segmenting multiple elliptical objects on a single image. This includes, among other tasks, segmenting vessels such as the aorta in axial CTA slices. In this paper, we present a general approach to improving the semantic segmentation performance of neural networks in these tasks and validate our approach on the task of aorta segmentation. We use a cascade of two neural networks, where one performs a rough segmentation based on the U-Net architecture and the other performs the final segmentation on polar image transformations of the input. Connected component analysis of the rough segmentation is used to construct the polar transformations, and predictions on multiple transformations of the same image are fused using hysteresis thresholding. We show that this method improves aorta segmentation performance without requiring complex neural network architectures. In addition, we show that our approach improves robustness and pixel-level recall while achieving segmentation performance in line with the state of the art.
Self-Supervised Learning as a Means To Reduce the Need for Labeled Data in Medical Image Analysis
Jun 01, 2022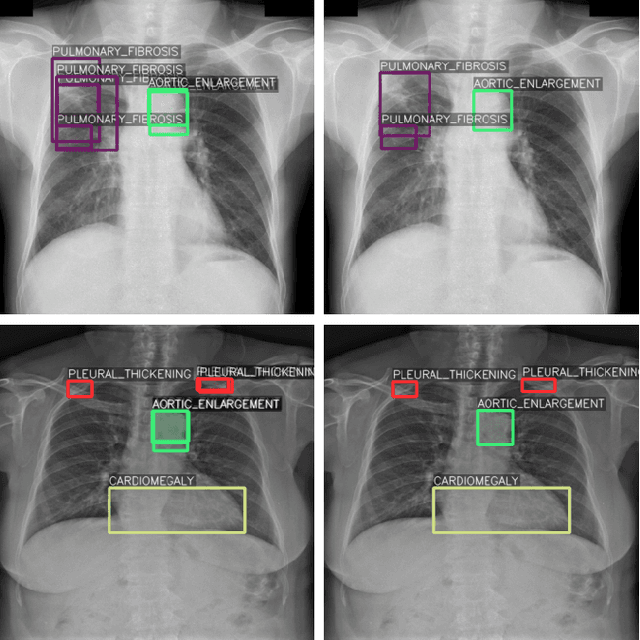
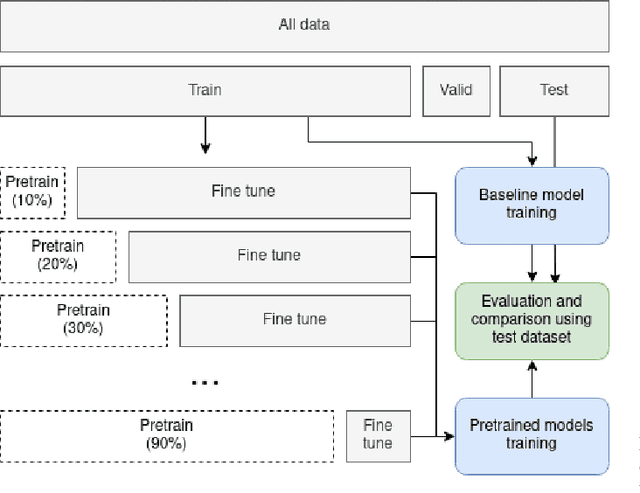
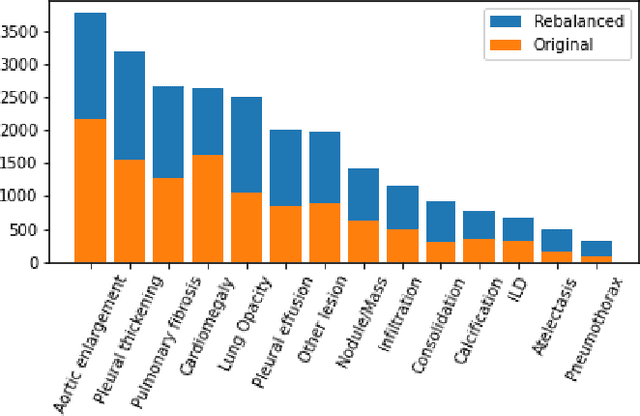
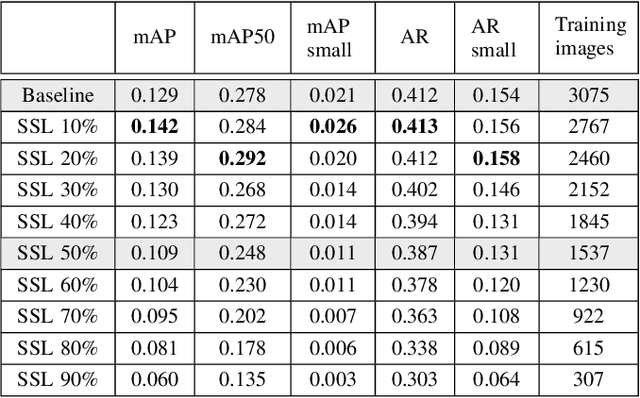
One of the largest problems in medical image processing is the lack of annotated data. Labeling medical images often requires highly trained experts and can be a time-consuming process. In this paper, we evaluate a method of reducing the need for labeled data in medical image object detection by using self-supervised neural network pretraining. We use a dataset of chest X-ray images with bounding box labels for 13 different classes of anomalies. The networks are pretrained on a percentage of the dataset without labels and then fine-tuned on the rest of the dataset. We show that it is possible to achieve similar performance to a fully supervised model in terms of mean average precision and accuracy with only 60\% of the labeled data. We also show that it is possible to increase the maximum performance of a fully-supervised model by adding a self-supervised pretraining step, and this effect can be observed with even a small amount of unlabeled data for pretraining.
A Survey of Left Atrial Appendage Segmentation and Analysis in 3D and 4D Medical Images
May 13, 2022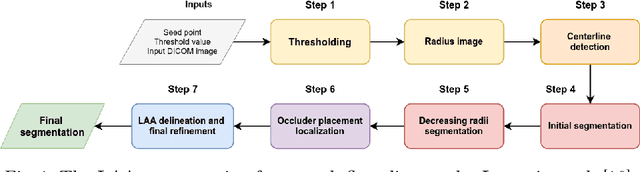
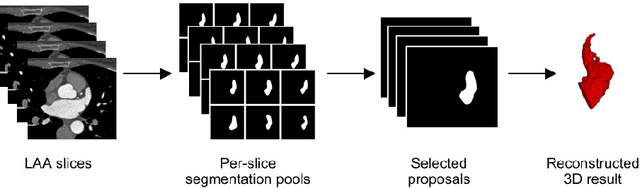
Atrial fibrillation (AF) is a cardiovascular disease identified as one of the main risk factors for stroke. The majority of strokes due to AF are caused by clots originating in the left atrial appendage (LAA). LAA occlusion is an effective procedure for reducing stroke risk. Planning the procedure using pre-procedural imaging and analysis has shown benefits. The analysis is commonly done by manually segmenting the appendage on 2D slices. Automatic LAA segmentation methods could save an expert's time and provide insightful 3D visualizations and accurate automatic measurements to aid in medical procedures. Several semi- and fully-automatic methods for segmenting the appendage have been proposed. This paper provides a review of automatic LAA segmentation methods on 3D and 4D medical images, including CT, MRI, and echocardiogram images. We classify methods into heuristic and model-based methods, as well as into semi- and fully-automatic methods. We summarize and compare the proposed methods, evaluate their effectiveness, and present current challenges in the field and approaches to overcome them.
Epicardial Adipose Tissue Segmentation from CT Images with A Semi-3D Neural Network
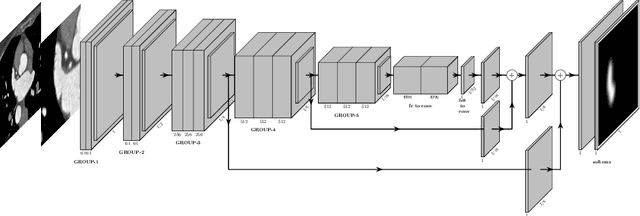
Apr 27, 2022


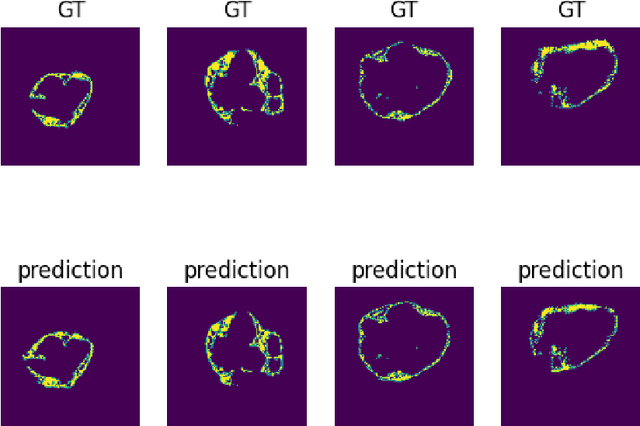
Epicardial adipose tissue is a type of adipose tissue located between the heart wall and a protective layer around the heart called the pericardium. The volume and thickness of epicardial adipose tissue are linked to various cardiovascular diseases. It is shown to be an independent cardiovascular disease risk factor. Fully automatic and reliable measurements of epicardial adipose tissue from CT scans could provide better disease risk assessment and enable the processing of large CT image data sets for a systemic epicardial adipose tissue study. This paper proposes a method for fully automatic semantic segmentation of epicardial adipose tissue from CT images using a deep neural network. The proposed network uses a U-Net-based architecture with slice depth information embedded in the input image to segment a pericardium region of interest, which is used to obtain an epicardial adipose tissue segmentation. Image augmentation is used to increase model robustness. Cross-validation of the proposed method yields a Dice score of 0.86 on the CT scans of 20 patients.