 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Self-supervised Correlation Mining Network for Person Image Generation
Nov 29, 2021
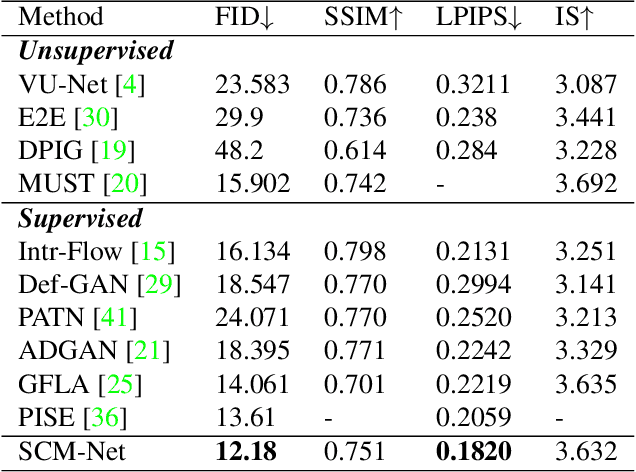
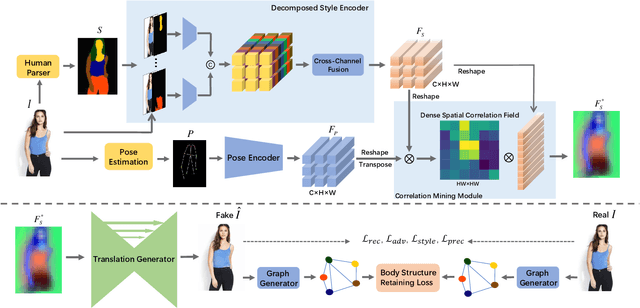
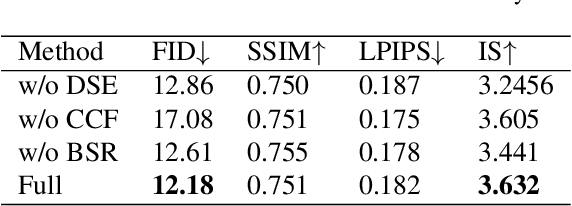

Person image generation aims to perform non-rigid deformation on source images, which generally requires unaligned data pairs for training. Recently, self-supervised methods express great prospects in this task by merging the disentangled representations for self-reconstruction. However, such methods fail to exploit the spatial correlation between the disentangled features. In this paper, we propose a Self-supervised Correlation Mining Network (SCM-Net) to rearrange the source images in the feature space, in which two collaborative modules are integrated, Decomposed Style Encoder (DSE) and Correlation Mining Module (CMM). Specifically, the DSE first creates unaligned pairs at the feature level. Then, the CMM establishes the spatial correlation field for feature rearrangement. Eventually, a translation module transforms the rearranged features to realistic results. Meanwhile, for improving the fidelity of cross-scale pose transformation, we propose a graph based Body Structure Retaining Loss (BSR Loss) to preserve reasonable body structures on half body to full body generation. Extensive experiments conducted on DeepFashion dataset demonstrate the superiority of our method compared with other supervised and unsupervised approaches. Furthermore, satisfactory results on face generation show the versatility of our method in other deformation tasks.
Pyramid Hybrid Pooling Quantization for Efficient Fine-Grained Image Retrieval
Sep 11, 2021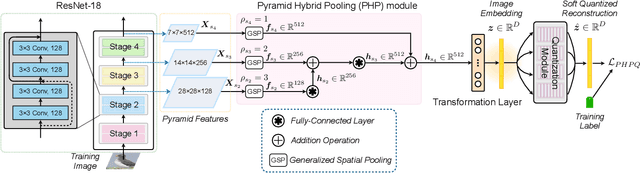
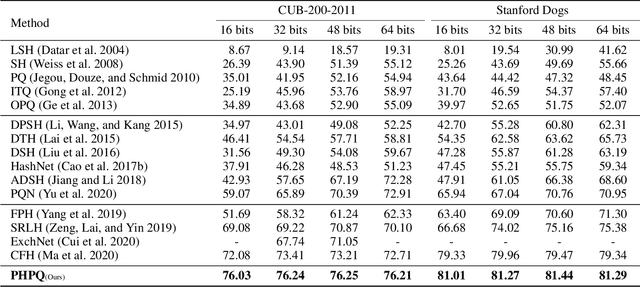
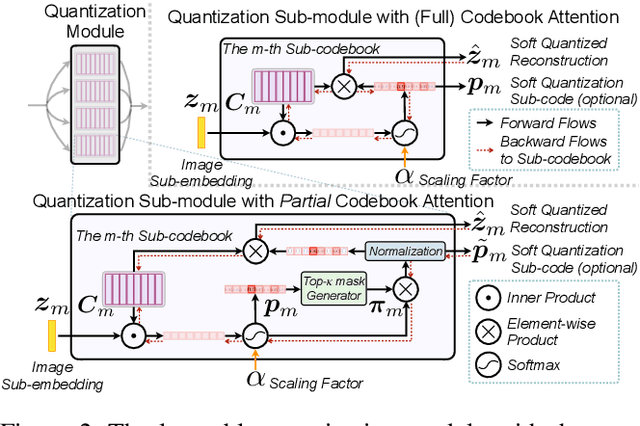
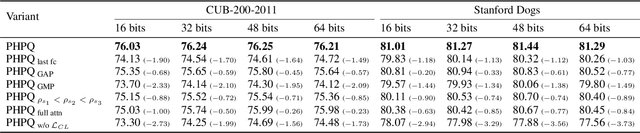
Deep hashing approaches, including deep quantization and deep binary hashing, have become a common solution to large-scale image retrieval due to high computation and storage efficiency. Most existing hashing methods can not produce satisfactory results for fine-grained retrieval, because they usually adopt the outputs of the last CNN layer to generate binary codes, which is less effective to capture subtle but discriminative visual details. To improve fine-grained image hashing, we propose Pyramid Hybrid Pooling Quantization (PHPQ). Specifically, we propose a Pyramid Hybrid Pooling (PHP) module to capture and preserve fine-grained semantic information from multi-level features. Besides, we propose a learnable quantization module with a partial attention mechanism, which helps to optimize the most relevant codewords and improves the quantization. Comprehensive experiments demonstrate that PHPQ outperforms state-of-the-art methods.
Human Saliency-Driven Patch-based Matching for Interpretable Post-mortem Iris Recognition
Aug 03, 2022
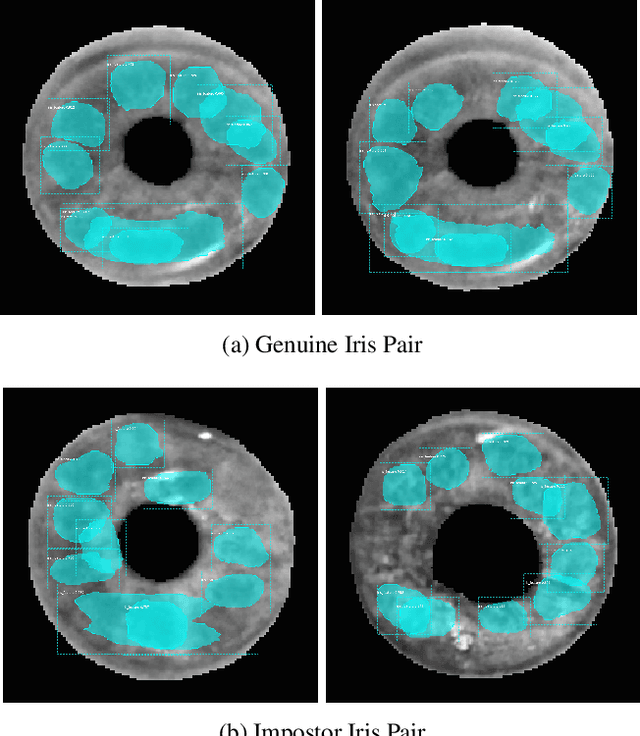
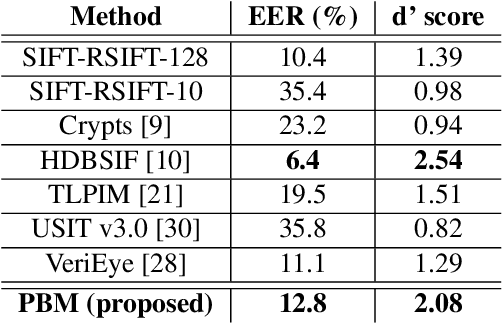
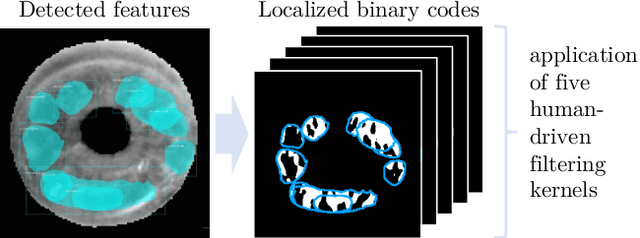
Forensic iris recognition, as opposed to live iris recognition, is an emerging research area that leverages the discriminative power of iris biometrics to aid human examiners in their efforts to identify deceased persons. As a machine learning-based technique in a predominantly human-controlled task, forensic recognition serves as "back-up" to human expertise in the task of post-mortem identification. As such, the machine learning model must be (a) interpretable, and (b) post-mortem-specific, to account for changes in decaying eye tissue. In this work, we propose a method that satisfies both requirements, and that approaches the creation of a post-mortem-specific feature extractor in a novel way employing human perception. We first train a deep learning-based feature detector on post-mortem iris images, using annotations of image regions highlighted by humans as salient for their decision making. In effect, the method learns interpretable features directly from humans, rather than purely data-driven features. Second, regional iris codes (again, with human-driven filtering kernels) are used to pair detected iris patches, which are translated into pairwise, patch-based comparison scores. In this way, our method presents human examiners with human-understandable visual cues in order to justify the identification decision and corresponding confidence score. When tested on a dataset of post-mortem iris images collected from 259 deceased subjects, the proposed method places among the three best iris matchers, demonstrating better results than the commercial (non-human-interpretable) VeriEye approach. We propose a unique post-mortem iris recognition method trained with human saliency to give fully-interpretable comparison outcomes for use in the context of forensic examination, achieving state-of-the-art recognition performance.
Co-Training for Unsupervised Domain Adaptation of Semantic Segmentation Models
May 31, 2022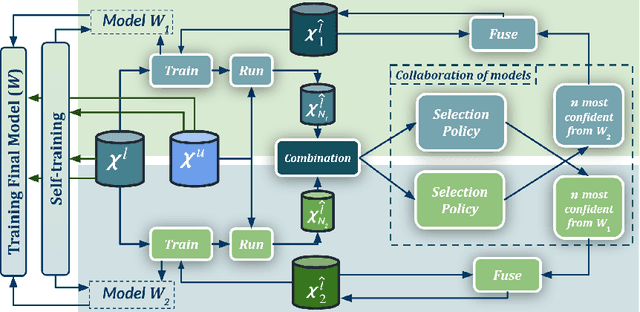

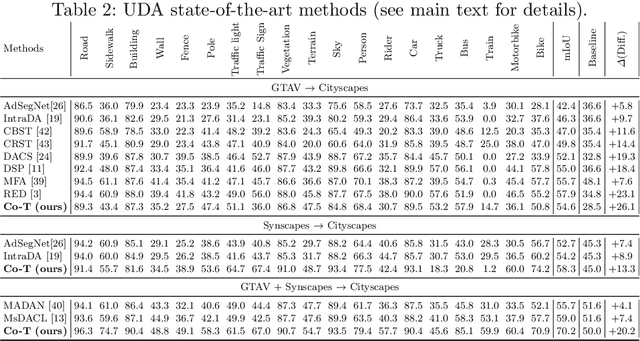
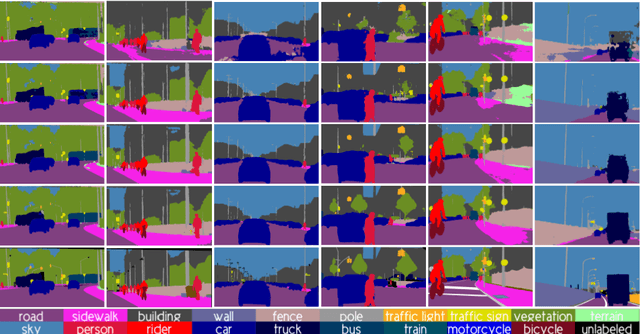
Semantic image segmentation is addressed by training deep models. Since supervised training draws to a curse of human-based image labeling, using synthetic images with automatically generated ground truth together with unlabeled real-world images is a promising alternative. This implies to address an unsupervised domain adaptation (UDA) problem. In this paper, we proposed a new co-training process for synth-to-real UDA of semantic segmentation models. First, we design a self-training procedure which provides two initial models. Then, we keep training these models in a collaborative manner for obtaining the final model. The overall process treats the deep models as black boxes and drives their collaboration at the level of pseudo-labeled target images, {\ie}, neither modifying loss functions is required, nor explicit feature alignment. We test our proposal on standard synthetic and real-world datasets. Our co-training shows improvements of 15-20 percentage points of mIoU over baselines, so establishing new state-of-the-art results.
LAViTeR: Learning Aligned Visual and Textual Representations Assisted by Image and Caption Generation
Sep 04, 2021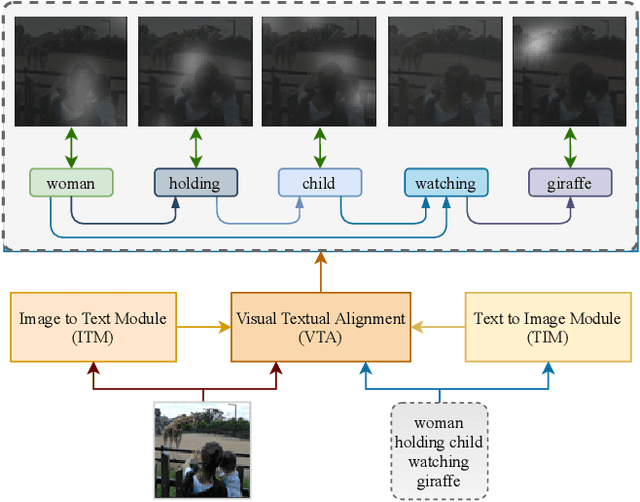
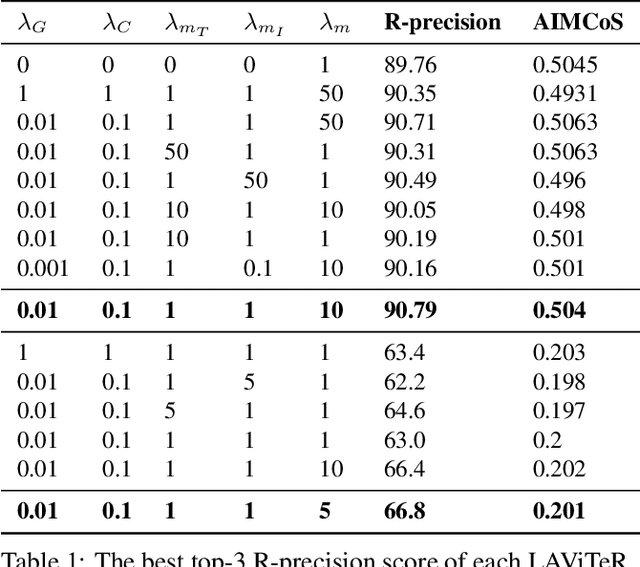
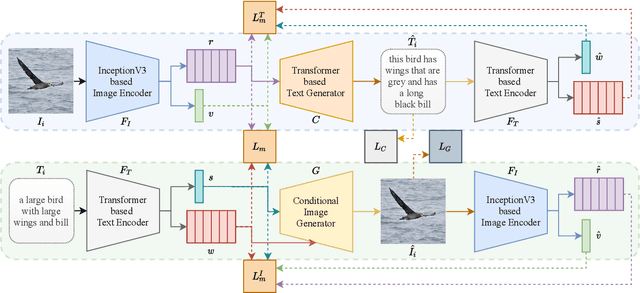
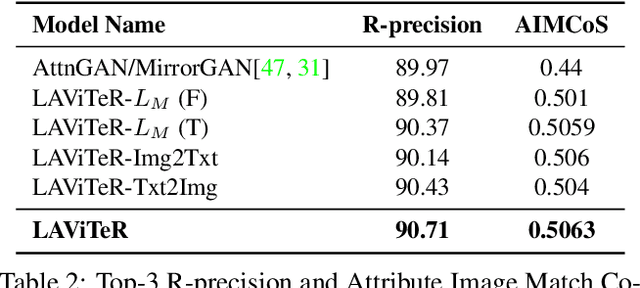
Pre-training visual and textual representations from large-scale image-text pairs is becoming a standard approach for many downstream vision-language tasks. The transformer-based models learn inter and intra-modal attention through a list of self-supervised learning tasks. This paper proposes LAViTeR, a novel architecture for visual and textual representation learning. The main module, Visual Textual Alignment (VTA) will be assisted by two auxiliary tasks, GAN-based image synthesis and Image Captioning. We also propose a new evaluation metric measuring the similarity between the learnt visual and textual embedding. The experimental results on two public datasets, CUB and MS-COCO, demonstrate superior visual and textual representation alignment in the joint feature embedding space
Class-Difficulty Based Methods for Long-Tailed Visual Recognition
Jul 29, 2022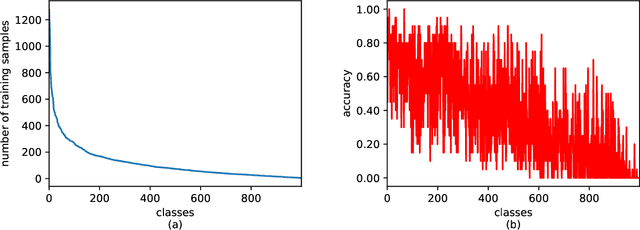
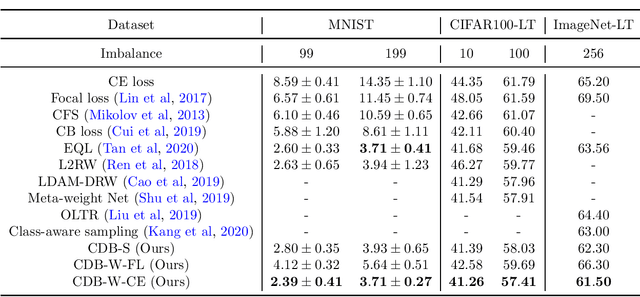
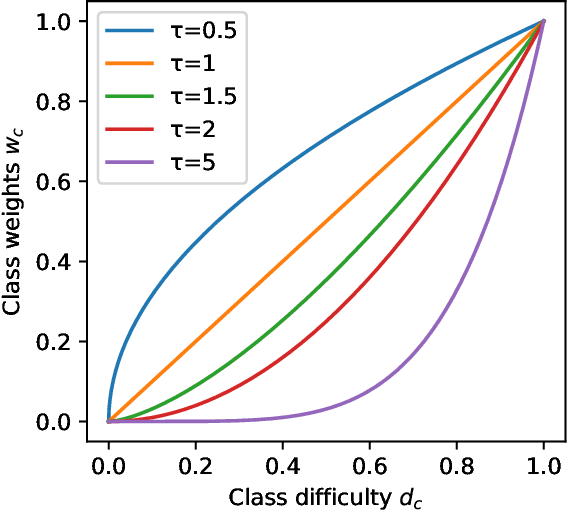
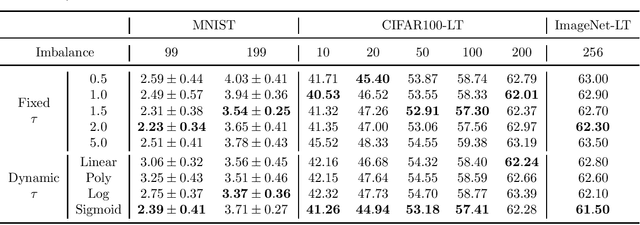
Long-tailed datasets are very frequently encountered in real-world use cases where few classes or categories (known as majority or head classes) have higher number of data samples compared to the other classes (known as minority or tail classes). Training deep neural networks on such datasets gives results biased towards the head classes. So far, researchers have come up with multiple weighted loss and data re-sampling techniques in efforts to reduce the bias. However, most of such techniques assume that the tail classes are always the most difficult classes to learn and therefore need more weightage or attention. Here, we argue that the assumption might not always hold true. Therefore, we propose a novel approach to dynamically measure the instantaneous difficulty of each class during the training phase of the model. Further, we use the difficulty measures of each class to design a novel weighted loss technique called `class-wise difficulty based weighted (CDB-W) loss' and a novel data sampling technique called `class-wise difficulty based sampling (CDB-S)'. To verify the wide-scale usability of our CDB methods, we conducted extensive experiments on multiple tasks such as image classification, object detection, instance segmentation and video-action classification. Results verified that CDB-W loss and CDB-S could achieve state-of-the-art results on many class-imbalanced datasets such as ImageNet-LT, LVIS and EGTEA, that resemble real-world use cases.
Image Based Reconstruction of Liquids from 2D Surface Detections
Nov 22, 2021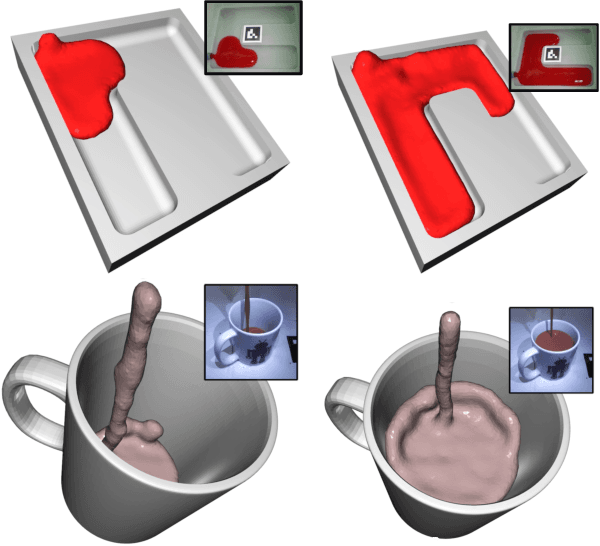
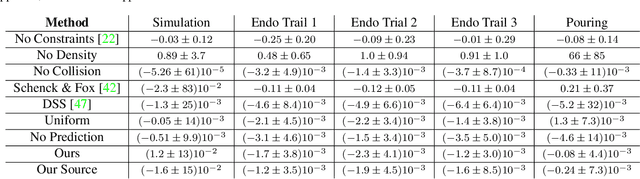
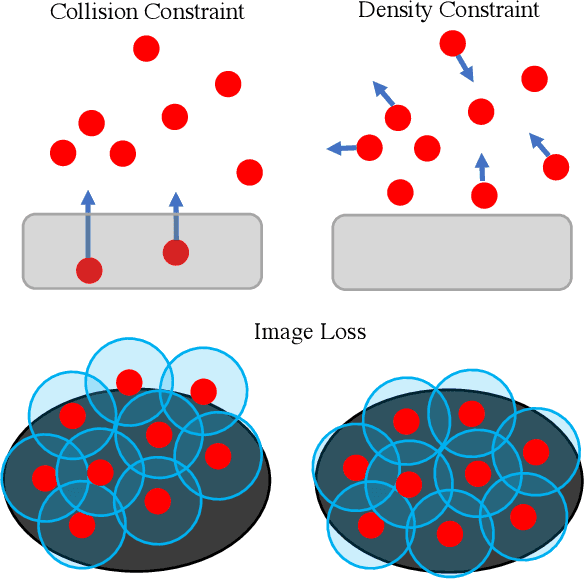
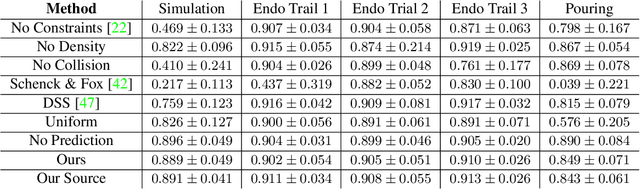
In this work, we present a solution to the challenging problem of reconstructing liquids from image data. The challenges in reconstructing liquids, which is not faced in previous reconstruction works on rigid and deforming surfaces, lies in the inability to use depth sensing and color features due the variable index of refraction, opacity, and environmental reflections. Therefore, we limit ourselves to only surface detections (i.e. binary mask) of liquids as observations and do not assume any prior knowledge on the liquids properties. A novel optimization problem is posed which reconstructs the liquid as particles by minimizing the error between a rendered surface from the particles and the surface detections while satisfying liquid constraints. Our solvers to this optimization problem are presented and no training data is required to apply them. We also propose a dynamic prediction to seed the reconstruction optimization from the previous time-step. We test our proposed methods in simulation and on two new liquid datasets which we open source so the broader research community can continue developing in this under explored area.
Entropy Regularized Iterative Weighted Shrinkage-Thresholding Algorithm (ERIWSTA): An Application to CT Image Restoration
Dec 22, 2021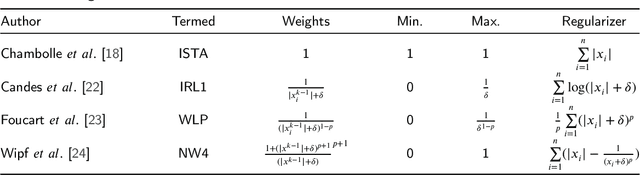
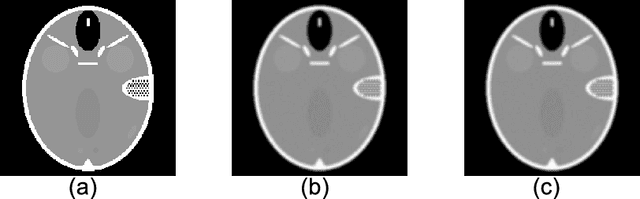
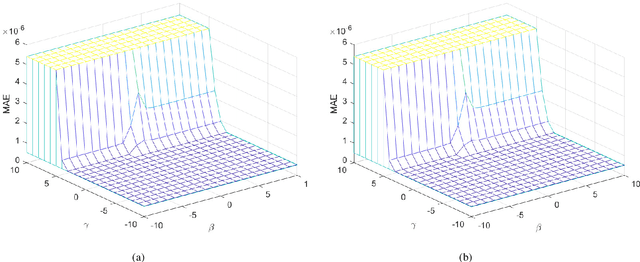

The iterative weighted shrinkage-thresholding algorithm (IWSTA) has shown superiority to the classic unweighted iterative shrinkage-thresholding algorithm (ISTA) for solving linear inverse problems, which address the attributes differently. This paper proposes a new entropy regularized IWSTA (ERIWSTA) that adds an entropy regularizer to the cost function to measure the uncertainty of the weights to stimulate attributes to participate in problem solving. Then, the weights are solved with a Lagrange multiplier method to obtain a simple iterative update. The weights can be explained as the probability of the contribution of an attribute to the problem solution. Experimental results on CT image restoration show that the proposed method has better performance in terms of convergence speed and restoration accuracy than the existing methods.
MIRST-DM: Multi-Instance RST with Drop-Max Layer for Robust Classification of Breast Cancer
May 02, 2022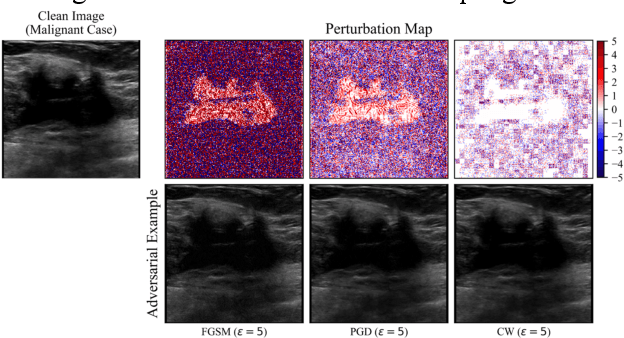
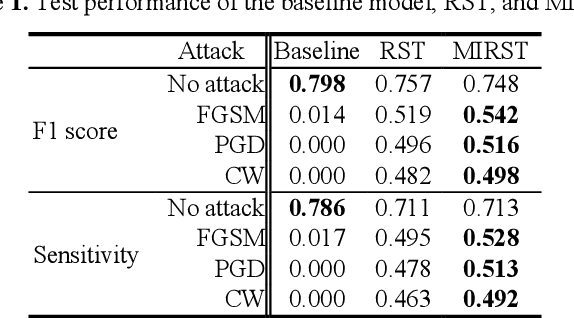
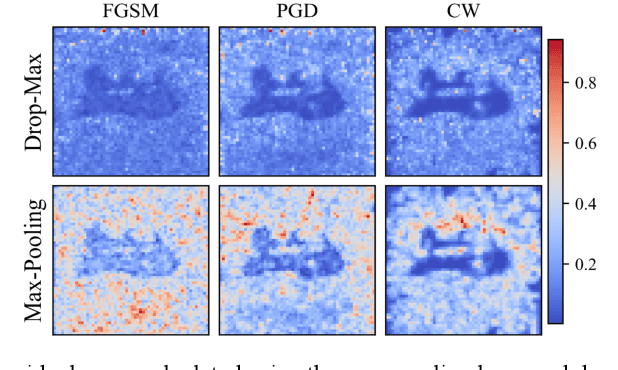
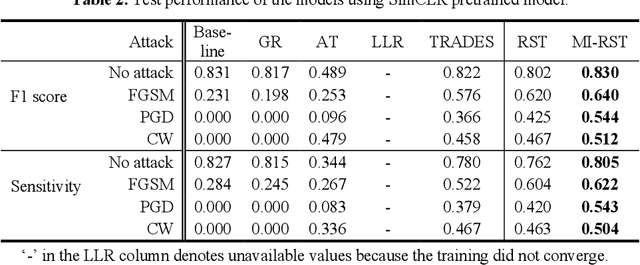
Robust self-training (RST) can augment the adversarial robustness of image classification models without significantly sacrificing models' generalizability. However, RST and other state-of-the-art defense approaches failed to preserve the generalizability and reproduce their good adversarial robustness on small medical image sets. In this work, we propose the Multi-instance RST with a drop-max layer, namely MIRST-DM, which involves a sequence of iteratively generated adversarial instances during training to learn smoother decision boundaries on small datasets. The proposed drop-max layer eliminates unstable features and helps learn representations that are robust to image perturbations. The proposed approach was validated using a small breast ultrasound dataset with 1,190 images. The results demonstrate that the proposed approach achieves state-of-the-art adversarial robustness against three prevalent attacks.
Improvement of image classification by multiple optical scattering
Jul 12, 2021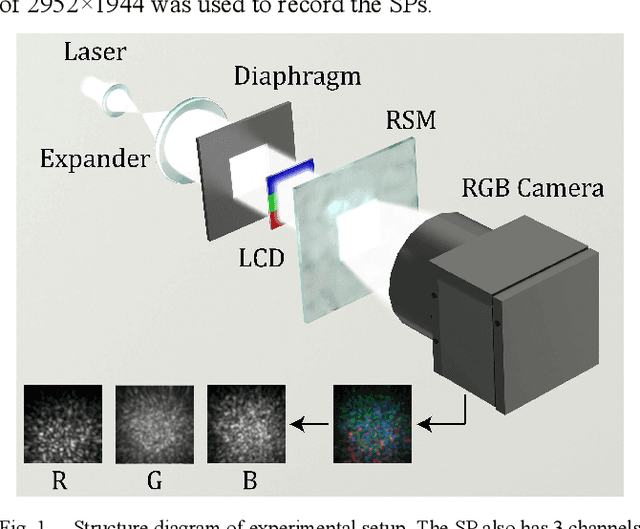
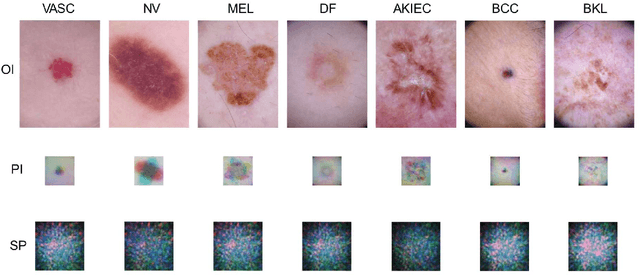
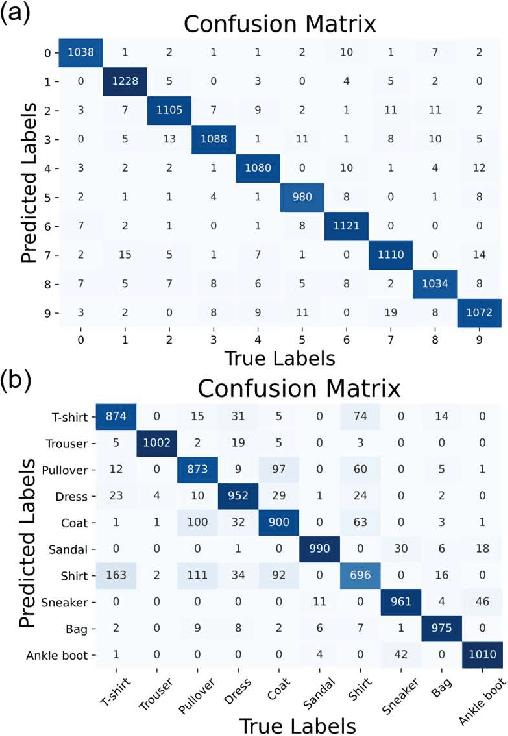
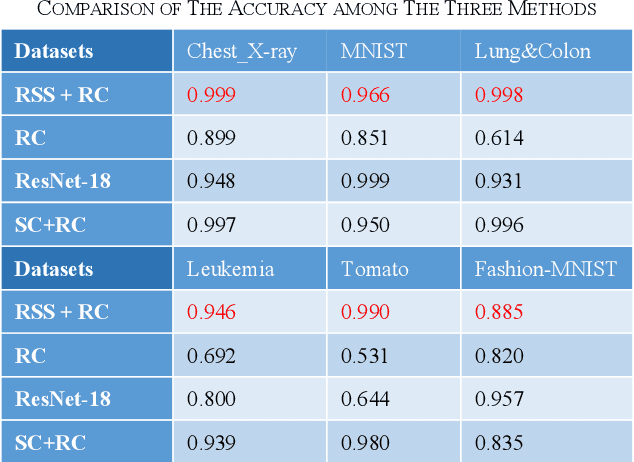
Multiple optical scattering occurs when light propagates in a non-uniform medium. During the multiple scattering, images were distorted and the spatial information they carried became scrambled. However, the image information is not lost but presents in the form of speckle patterns (SPs). In this study, we built up an optical random scattering system based on an LCD and an RGB laser source. We found that the image classification can be improved by the help of random scattering which is considered as a feedforward neural network to extracts features from image. Along with the ridge classification deployed on computer, we achieved excellent classification accuracy higher than 94%, for a variety of data sets covering medical, agricultural, environmental protection and other fields. In addition, the proposed optical scattering system has the advantages of high speed, low power consumption, and miniaturization, which is suitable for deploying in edge computing applications.