 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Visualizing and Understanding Self-Supervised Vision Learning
Jun 20, 2022
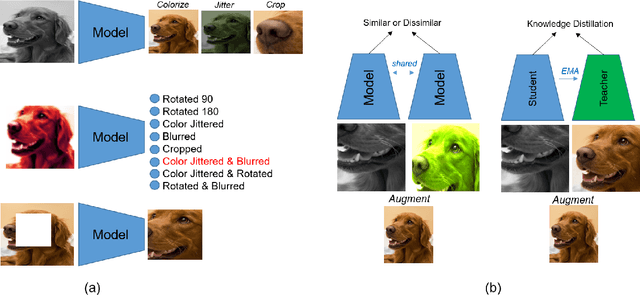
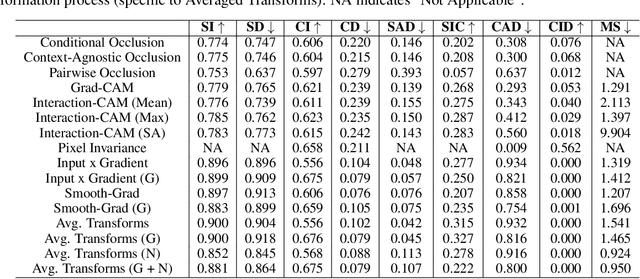
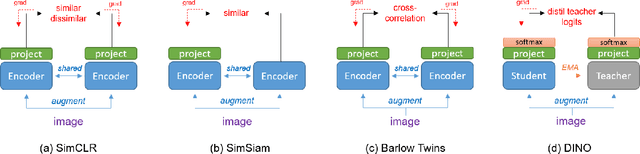
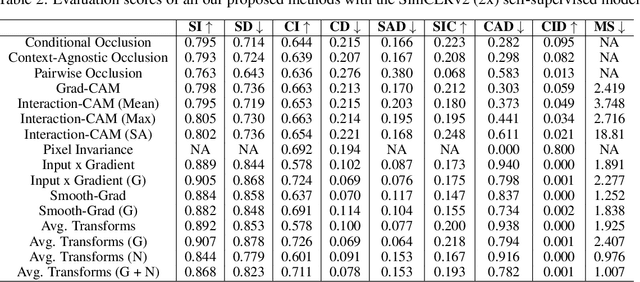
Self-Supervised vision learning has revolutionized deep learning, becoming the next big challenge in the domain and rapidly closing the gap with supervised methods on large computer vision benchmarks. With current models and training data exponentially growing, explaining and understanding these models becomes pivotal. We study the problem of explainable artificial intelligence in the domain of self-supervised learning for vision tasks, and present methods to understand networks trained with self-supervision and their inner workings. Given the huge diversity of self-supervised vision pretext tasks, we narrow our focus on understanding paradigms which learn from two views of the same image, and mainly aim to understand the pretext task. Our work focuses on explaining similarity learning, and is easily extendable to all other pretext tasks. We study two popular self-supervised vision models: SimCLR and Barlow Twins. We develop a total of six methods for visualizing and understanding these models: Perturbation-based methods (conditional occlusion, context-agnostic conditional occlusion and pairwise occlusion), Interaction-CAM, Feature Visualization, Model Difference Visualization, Averaged Transforms and Pixel Invaraince. Finally, we evaluate these explanations by translating well-known evaluation metrics tailored towards supervised image classification systems involving a single image, into the domain of self-supervised learning where two images are involved. Code is at: https://github.com/fawazsammani/xai-ssl
Fast optical refocusing through multimode fiber bend using Cake-Cutting Hadamard encoding algorithm to improve robustness
Jul 27, 2022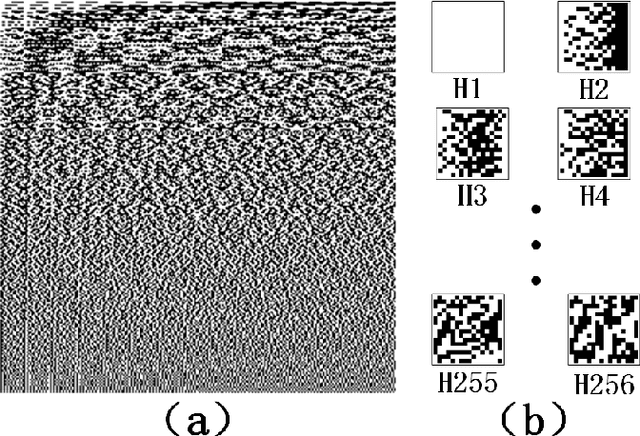

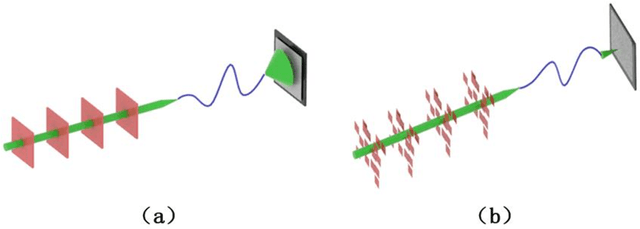
Multimode fibres offer the advantages of high resolution and miniaturization over single mode fibers in the field of optical imaging. However, multimode fibre's imaging is susceptible to perturbations of MMF that can lead to secondary spatial distortions in the transmitted image. Perturbations include random disturbances in the fiber as well as environmental noise. Here, we exploit the fast focusing capability of the Cake-Cutting Hadamard coding algorithm to counteract the effects of perturbations and improve the system's robustness. Simulation shows that it can approach the theoretical enhancement at 2000 measurements. Experimental results show that the algorithm can help the system to refocus in a short time when MMFs are perturbed. This research will further contribute to using multimode fibres in medicine, communication, and detection.
A Streaming Volumetric Image Generation Framework for Development and Evaluation of Out-of-Core Methods
Dec 18, 2021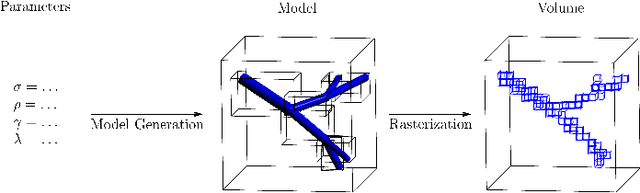
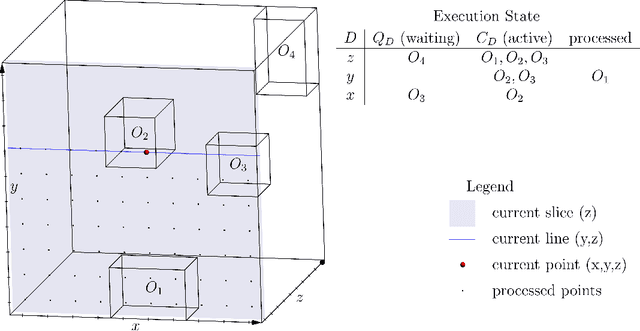
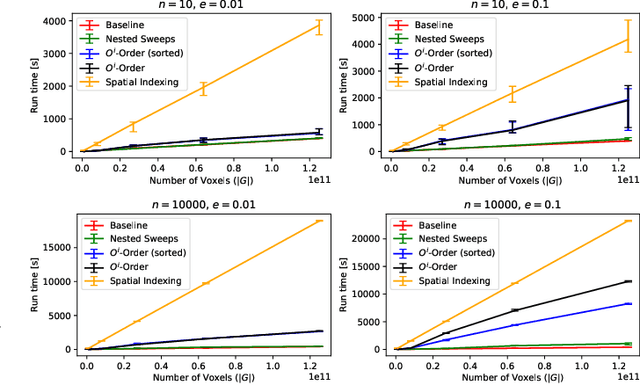
Advances in 3D imaging technology in recent years have allowed for increasingly high resolution volumetric images of large specimen. The resulting datasets of hundreds of Gigabytes in size call for new scalable and memory efficient approaches in the field of image processing, where some progress has been made already. At the same time, quantitative evaluation of these new methods is difficult both in terms of the availability of specific data sizes and in the generation of associated ground truth data. In this paper we present an algorithmic framework that can be used to efficiently generate test (and ground truth) volume data, optionally even in a streaming fashion. As the proposed nested sweeps algorithm is fast, it can be used to generate test data on demand. We analyze the asymptotic run time of the presented algorithm and compare it experimentally to alternative approaches as well as a hypothetical best-case baseline method. In a case study, the framework is applied to the popular VascuSynth software for vascular image generation, making it capable of efficiently producing larger-than-main memory volumes which is demonstrated by generating a trillion voxel (1TB) image. Implementations of the presented framework are available online in the form of the modified version of Vascusynth and the code used for the experimental evaluation. In addition, the test data generation procedure has been integrated into the popular volume rendering and processing framework Voreen.
Blockwise Temporal-Spatial Pathway Network
Aug 05, 2022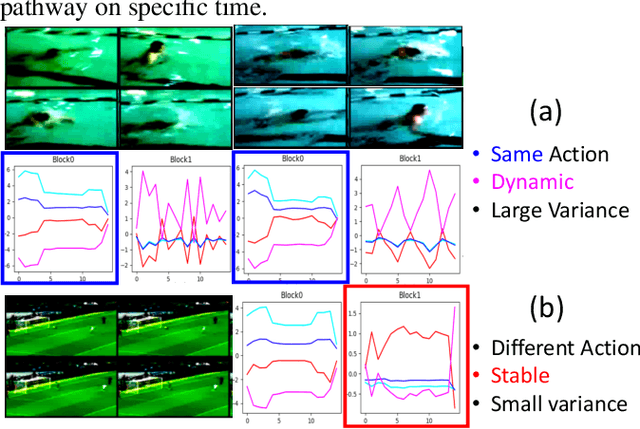
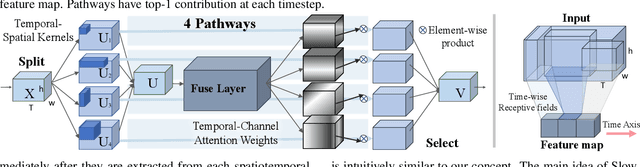
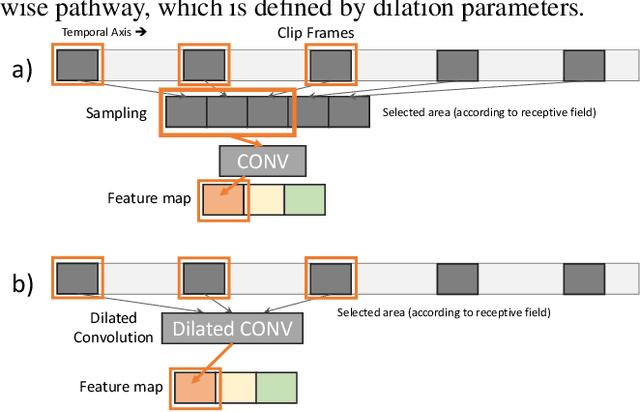
Algorithms for video action recognition should consider not only spatial information but also temporal relations, which remains challenging. We propose a 3D-CNN-based action recognition model, called the blockwise temporal-spatial path-way network (BTSNet), which can adjust the temporal and spatial receptive fields by multiple pathways. We designed a novel model inspired by an adaptive kernel selection-based model, which is an architecture for effective feature encoding that adaptively chooses spatial receptive fields for image recognition. Expanding this approach to the temporal domain, our model extracts temporal and channel-wise attention and fuses information on various candidate operations. For evaluation, we tested our proposed model on UCF-101, HMDB-51, SVW, and Epic-Kitchen datasets and showed that it generalized well without pretraining. BTSNet also provides interpretable visualization based on spatiotemporal channel-wise attention. We confirm that the blockwise temporal-spatial pathway supports a better representation for 3D convolutional blocks based on this visualization.
Backdoor Attacks on Crowd Counting
Jul 12, 2022
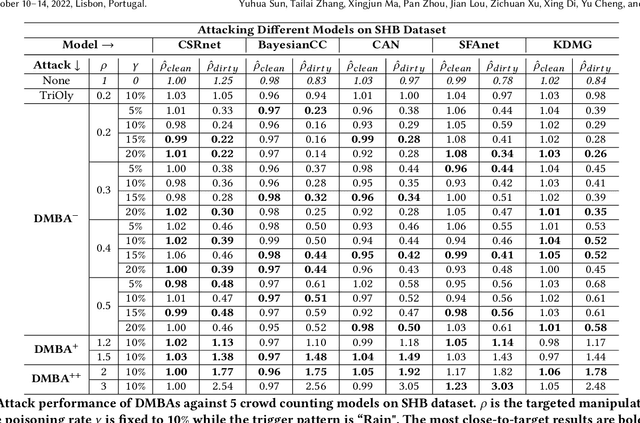
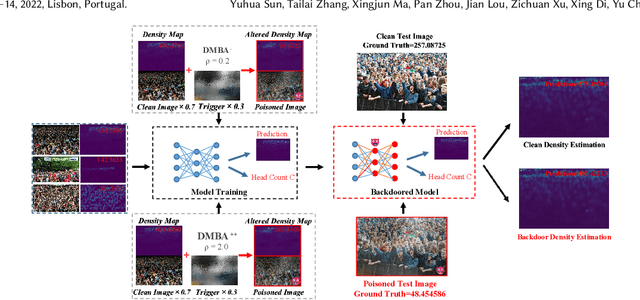
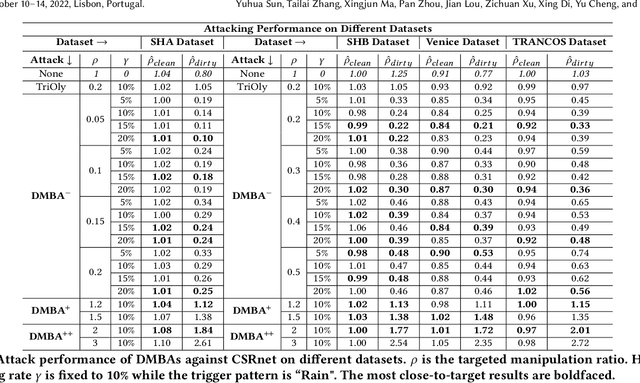
Crowd counting is a regression task that estimates the number of people in a scene image, which plays a vital role in a range of safety-critical applications, such as video surveillance, traffic monitoring and flow control. In this paper, we investigate the vulnerability of deep learning based crowd counting models to backdoor attacks, a major security threat to deep learning. A backdoor attack implants a backdoor trigger into a target model via data poisoning so as to control the model's predictions at test time. Different from image classification models on which most of existing backdoor attacks have been developed and tested, crowd counting models are regression models that output multi-dimensional density maps, thus requiring different techniques to manipulate. In this paper, we propose two novel Density Manipulation Backdoor Attacks (DMBA$^{-}$ and DMBA$^{+}$) to attack the model to produce arbitrarily large or small density estimations. Experimental results demonstrate the effectiveness of our DMBA attacks on five classic crowd counting models and four types of datasets. We also provide an in-depth analysis of the unique challenges of backdooring crowd counting models and reveal two key elements of effective attacks: 1) full and dense triggers and 2) manipulation of the ground truth counts or density maps. Our work could help evaluate the vulnerability of crowd counting models to potential backdoor attacks.
TransMatting: Enhancing Transparent Objects Matting with Transformers
Aug 05, 2022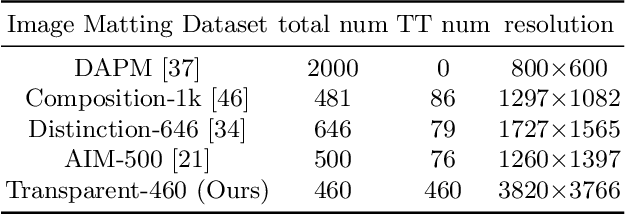
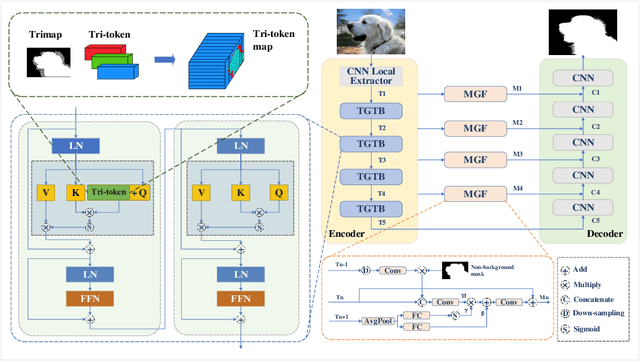
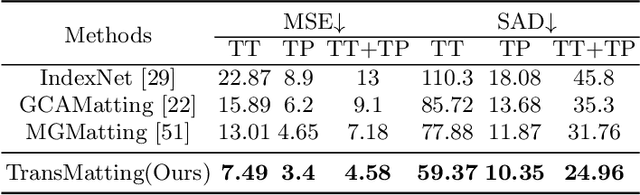

Image matting refers to predicting the alpha values of unknown foreground areas from natural images. Prior methods have focused on propagating alpha values from known to unknown regions. However, not all natural images have a specifically known foreground. Images of transparent objects, like glass, smoke, web, etc., have less or no known foreground. In this paper, we propose a Transformer-based network, TransMatting, to model transparent objects with a big receptive field. Specifically, we redesign the trimap as three learnable tri-tokens for introducing advanced semantic features into the self-attention mechanism. A small convolutional network is proposed to utilize the global feature and non-background mask to guide the multi-scale feature propagation from encoder to decoder for maintaining the contexture of transparent objects. In addition, we create a high-resolution matting dataset of transparent objects with small known foreground areas. Experiments on several matting benchmarks demonstrate the superiority of our proposed method over the current state-of-the-art methods.
Gradient Obfuscation Gives a False Sense of Security in Federated Learning
Jun 08, 2022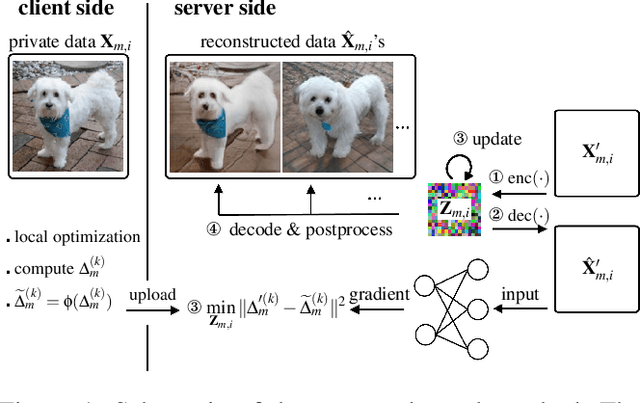


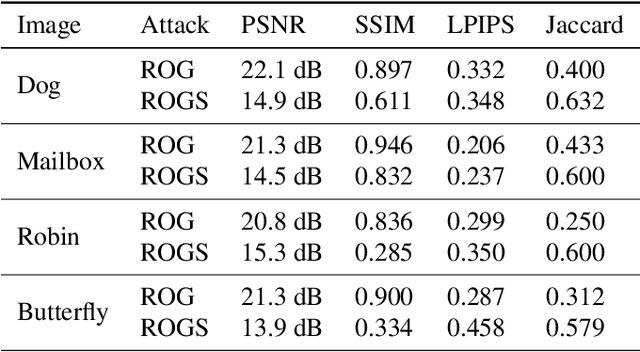
Federated learning has been proposed as a privacy-preserving machine learning framework that enables multiple clients to collaborate without sharing raw data. However, client privacy protection is not guaranteed by design in this framework. Prior work has shown that the gradient sharing strategies in federated learning can be vulnerable to data reconstruction attacks. In practice, though, clients may not transmit raw gradients considering the high communication cost or due to privacy enhancement requirements. Empirical studies have demonstrated that gradient obfuscation, including intentional obfuscation via gradient noise injection and unintentional obfuscation via gradient compression, can provide more privacy protection against reconstruction attacks. In this work, we present a new data reconstruction attack framework targeting the image classification task in federated learning. We show that commonly adopted gradient postprocessing procedures, such as gradient quantization, gradient sparsification, and gradient perturbation, may give a false sense of security in federated learning. Contrary to prior studies, we argue that privacy enhancement should not be treated as a byproduct of gradient compression. Additionally, we design a new method under the proposed framework to reconstruct the image at the semantic level. We quantify the semantic privacy leakage and compare with conventional based on image similarity scores. Our comparisons challenge the image data leakage evaluation schemes in the literature. The results emphasize the importance of revisiting and redesigning the privacy protection mechanisms for client data in existing federated learning algorithms.
Forensic License Plate Recognition with Compression-Informed Transformers
Jul 29, 2022
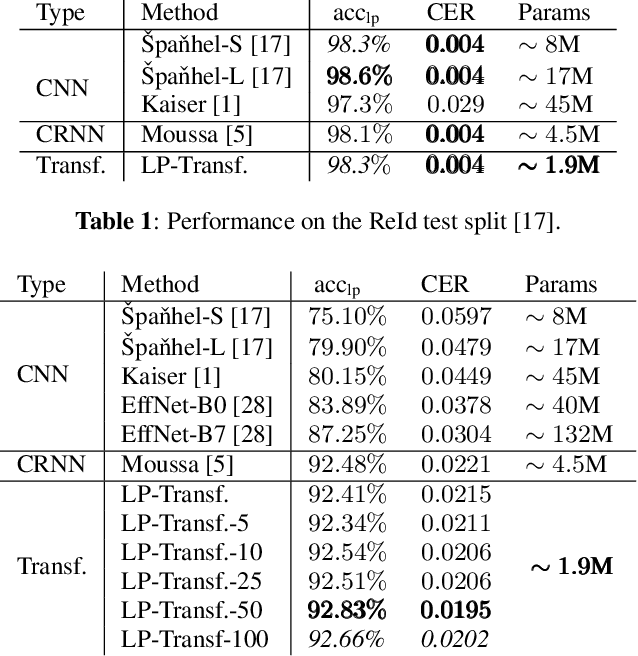

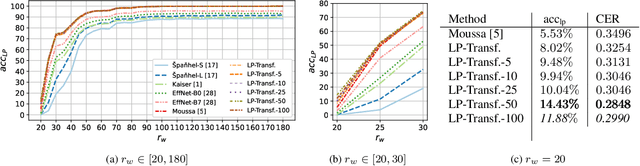
Forensic license plate recognition (FLPR) remains an open challenge in legal contexts such as criminal investigations, where unreadable license plates (LPs) need to be deciphered from highly compressed and/or low resolution footage, e.g., from surveillance cameras. In this work, we propose a side-informed Transformer architecture that embeds knowledge on the input compression level to improve recognition under strong compression. We show the effectiveness of Transformers for license plate recognition (LPR) on a low-quality real-world dataset. We also provide a synthetic dataset that includes strongly degraded, illegible LP images and analyze the impact of knowledge embedding on it. The network outperforms existing FLPR methods and standard state-of-the art image recognition models while requiring less parameters. For the severest degraded images, we can improve recognition by up to 8.9 percent points.
Assessing Privacy Leakage in Synthetic 3-D PET Imaging using Transversal GAN
Jun 13, 2022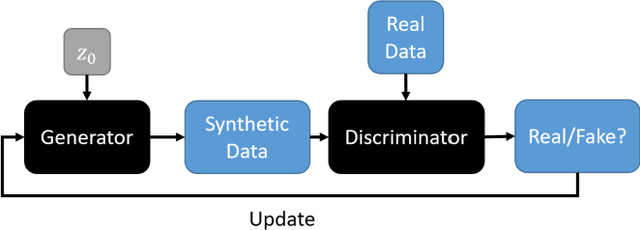
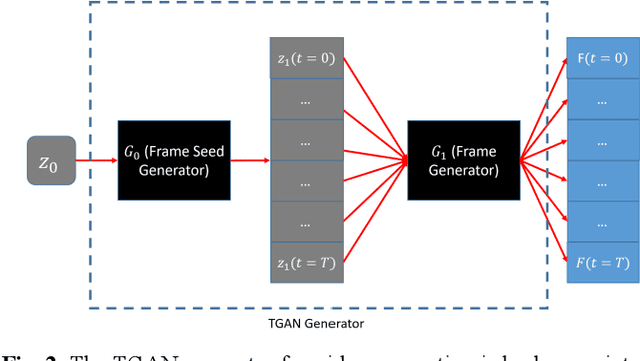
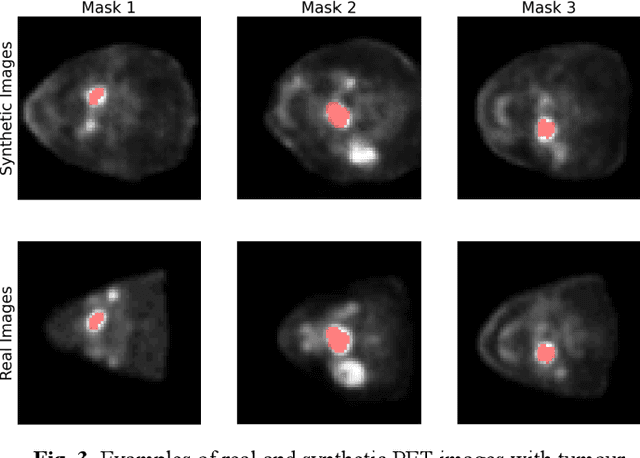
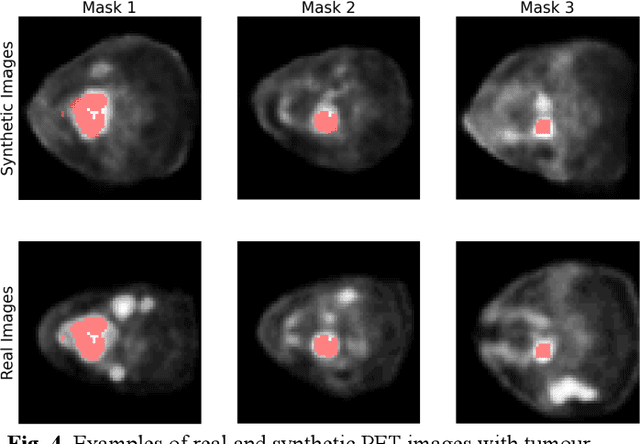
Training computer-vision related algorithms on medical images for disease diagnosis or image segmentation is difficult in large part due to privacy concerns. For this reason, generative image models are highly sought after to facilitate data sharing. However, 3-D generative models are understudied, and investigation of their privacy leakage is needed. We introduce our 3-D generative model, Transversal GAN (TrGAN), using head & neck PET images which are conditioned on tumour masks as a case study. We define quantitative measures of image fidelity, utility and privacy for our model. These metrics are evaluated in the course of training to identify ideal fidelity, utility and privacy trade-offs and establish the relationships between these parameters. We show that the discriminator of the TrGAN is vulnerable to attack, and that an attacker can identify which samples were used in training with almost perfect accuracy (AUC = 0.99). We also show that an attacker with access to only the generator cannot reliably classify whether a sample had been used for training (AUC = 0.51). This suggests that TrGAN generators, but not discriminators, may be used for sharing synthetic 3-D PET data with minimal privacy risk while maintaining good utility and fidelity.
The Winning Solution to the iFLYTEK Challenge 2021 Cultivated Land Extraction from High-Resolution Remote Sensing Image
Feb 25, 2022
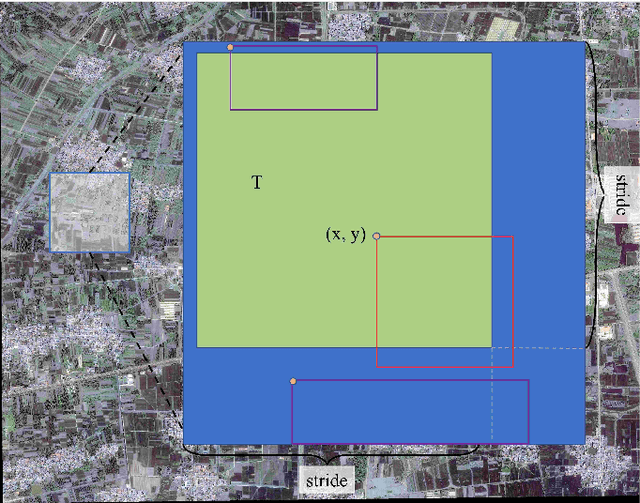
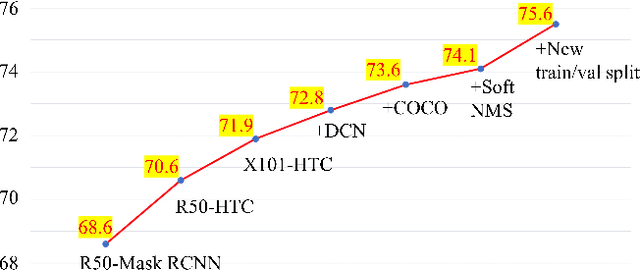
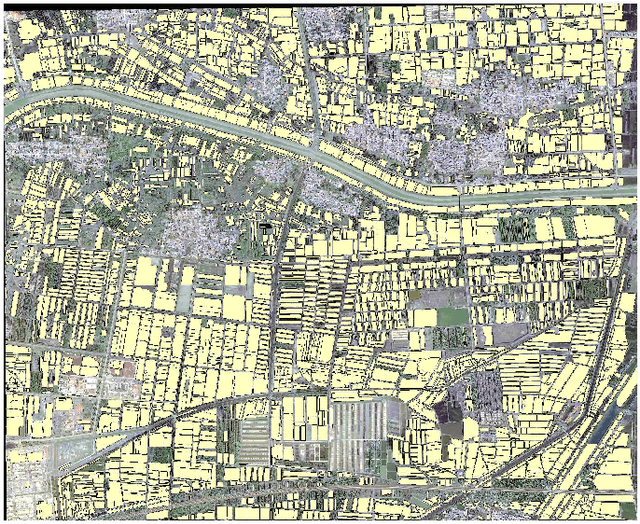
Extracting cultivated land accurately from high-resolution remote images is a basic task for precision agriculture. This report introduces our solution to the iFLYTEK challenge 2021 cultivated land extraction from high-resolution remote sensing image. The challenge requires segmenting cultivated land objects in very high-resolution multispectral remote sensing images. We established a highly effective and efficient pipeline to solve this problem. We first divided the original images into small tiles and separately performed instance segmentation on each tile. We explored several instance segmentation algorithms that work well on natural images and developed a set of effective methods that are applicable to remote sensing images. Then we merged the prediction results of all small tiles into seamless, continuous segmentation results through our proposed overlap-tile fusion strategy. We achieved the first place among 486 teams in the challenge.