 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Detection and Classification of Brain tumors Using Deep Convolutional Neural Networks
Aug 28, 2022
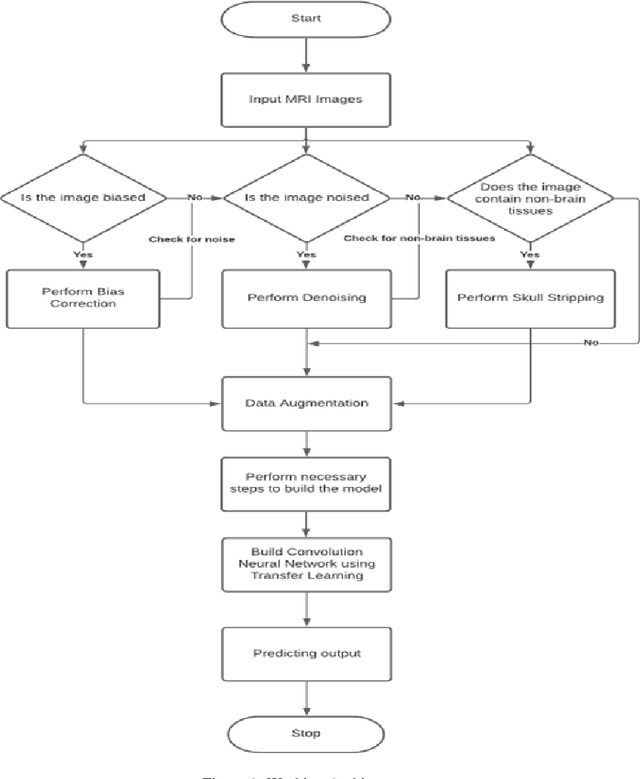
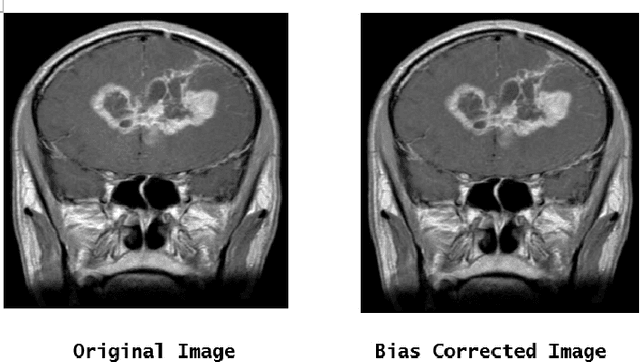
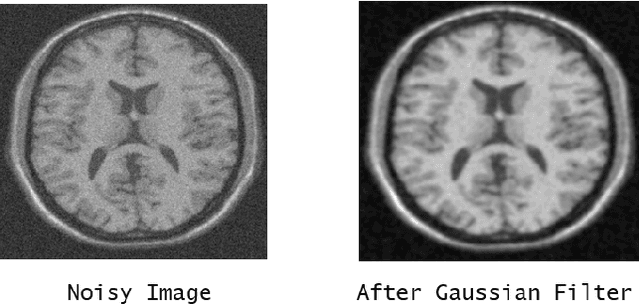
Abnormal development of tissues in the body as a result of swelling and morbid enlargement is known as a tumor. They are mainly classified as Benign and Malignant. Tumour in the brain is fatal as it may be cancerous, so it can feed on healthy cells nearby and keep increasing in size. This may affect the soft tissues, nerve cells, and small blood vessels in the brain. Hence there is a need to detect and classify them during the early stages with utmost precision. There are different sizes and locations of brain tumors which makes it difficult to understand their nature. The process of detection and classification of brain tumors can prove to be an onerous task even with advanced MRI (Magnetic Resonance Imaging) techniques due to the similarities between the healthy cells nearby and the tumor. In this paper, we have used Keras and Tensorflow to implement state-of-the-art Convolutional Neural Network (CNN) architectures, like EfficientNetB0, ResNet50, Xception, MobileNetV2, and VGG16, using Transfer Learning to detect and classify three types of brain tumors namely - Glioma, Meningioma, and Pituitary. The dataset we used consisted of 3264 2-D magnetic resonance images and 4 classes. Due to the small size of the dataset, various data augmentation techniques were used to increase the size of the dataset. Our proposed methodology not only consists of data augmentation, but also various image denoising techniques, skull stripping, cropping, and bias correction. In our proposed work EfficientNetB0 architecture performed the best giving an accuracy of 97.61%. The aim of this paper is to differentiate between normal and abnormal pixels and also classify them with better accuracy.
Perceptually Optimized Deep High-Dynamic-Range Image Tone Mapping
Sep 02, 2021
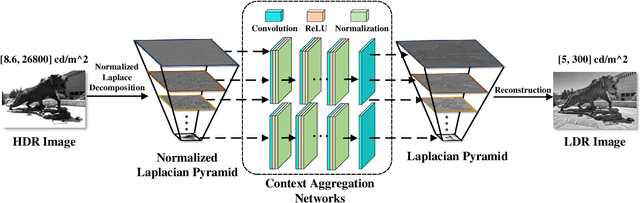


We describe a deep high-dynamic-range (HDR) image tone mapping operator that is computationally efficient and perceptually optimized. We first decompose an HDR image into a normalized Laplacian pyramid, and use two deep neural networks (DNNs) to estimate the Laplacian pyramid of the desired tone-mapped image from the normalized representation. We then end-to-end optimize the entire method over a database of HDR images by minimizing the normalized Laplacian pyramid distance (NLPD), a recently proposed perceptual metric. Qualitative and quantitative experiments demonstrate that our method produces images with better visual quality, and runs the fastest among existing local tone mapping algorithms.
Global Speed-of-Sound Prediction Using Transmission Geometry
Aug 17, 2022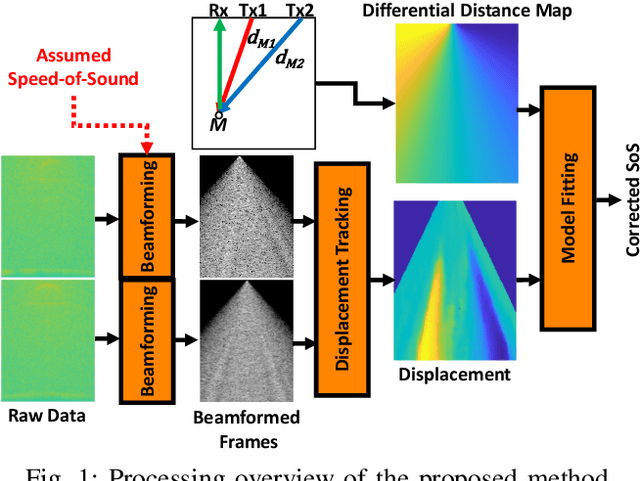
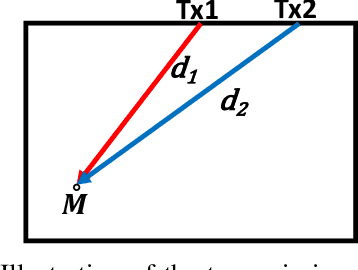
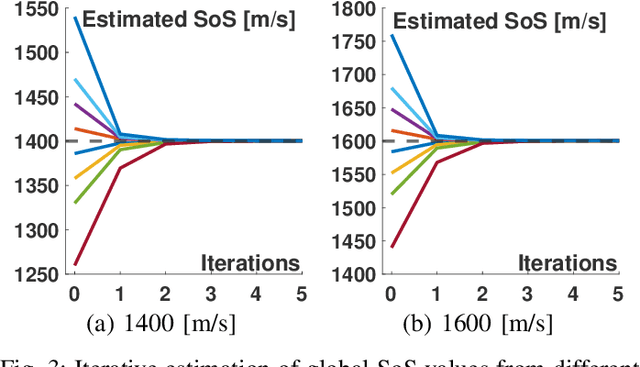
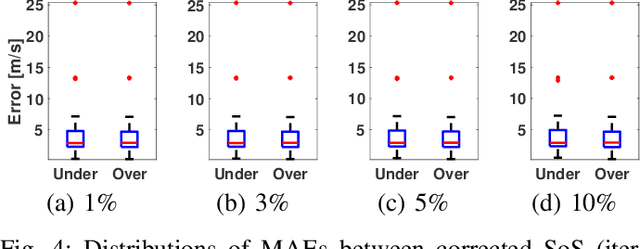
Most ultrasound (US) imaging techniques use spatially-constant speed-of-sound (SoS) values for beamforming. Having a discrepancy between the actual and used SoS value leads to aberration artifacts, e.g., reducing the image resolution, which may affect diagnostic usability. Accuracy and quality of different US imaging modalities, such as tomographic reconstruction of local SoS maps, also depend on a good initial beamforming SoS. In this work, we develop an analytical method for estimating mean SoS in an imaged medium. We show that the relative shifts between beamformed frames depend on the SoS offset and the geometric disparities in transmission paths. Using this relation, we estimate a correction factor and hence a corrected mean SoS in the medium. We evaluated our proposed method on a set of numerical simulations, demonstrating its utility both for global SoS prediction and for local SoS tomographic reconstruction. For our evaluation dataset, for an initial SoS under- and over-assumption of 5% the medium SoS, our method is able to predict the actual mean SoS within 0.3% accuracy. For the tomographic reconstruction of local SoS maps, the reconstruction accuracy is improved on average by 78.5% and 87%, respectively, compared to an initial SoS under- and over-assumption of 5%.
Pre-Trained Language Transformers are Universal Image Classifiers
Jan 25, 2022Facial images disclose many hidden personal traits such as age, gender, race, health, emotion, and psychology. Understanding these traits will help to classify the people in different attributes. In this paper, we have presented a novel method for classifying images using a pretrained transformer model. We apply the pretrained transformer for the binary classification of facial images in criminal and non-criminal classes. The pretrained transformer of GPT-2 is trained to generate text and then fine-tuned to classify facial images. During the finetuning process with images, most of the layers of GT-2 are frozen during backpropagation and the model is frozen pretrained transformer (FPT). The FPT acts as a universal image classifier, and this paper shows the application of FPT on facial images. We also use our FPT on encrypted images for classification. Our FPT shows high accuracy on both raw facial images and encrypted images. We hypothesize the meta-learning capacity FPT gained because of its large size and trained on a large size with theory and experiments. The GPT-2 trained to generate a single word token at a time, through the autoregressive process, forced to heavy-tail distribution. Then the FPT uses the heavy-tail property as its meta-learning capacity for classifying images. Our work shows one way to avoid bias during the machine classification of images.The FPT encodes worldly knowledge because of the pretraining of one text, which it uses during the classification. The statistical error of classification is reduced because of the added context gained from the text.Our paper shows the ethical dimension of using encrypted data for classification.Criminal images are sensitive to share across the boundary but encrypted largely evades ethical concern.FPT showing good classification accuracy on encrypted images shows promise for further research on privacy-preserving machine learning.
Two-Stage Architectural Fine-Tuning with Neural Architecture Search using Early-Stopping in Image Classification
Feb 18, 2022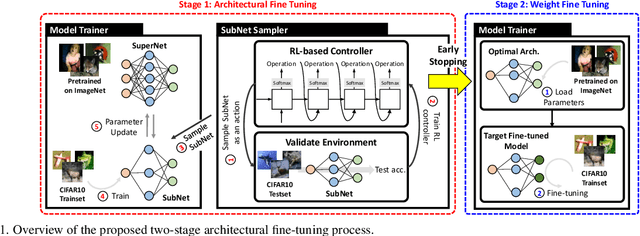

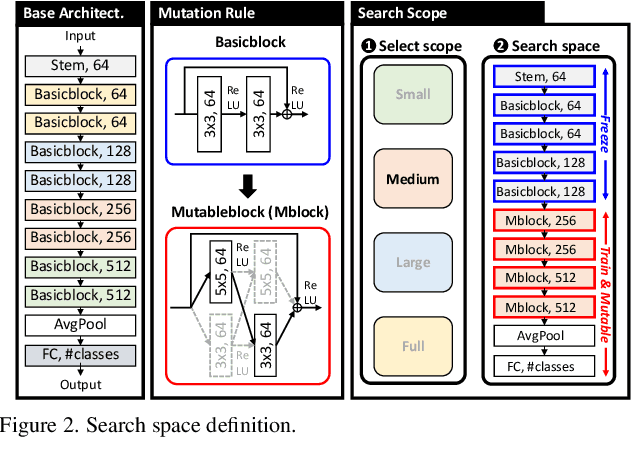
Deep neural networks (NN) perform well in various tasks (e.g., computer vision) because of the convolutional neural networks (CNN). However, the difficulty of gathering quality data in the industry field hinders the practical use of NN. To cope with this issue, the concept of transfer learning (TL) has emerged, which leverages the fine-tuning of NNs trained on large-scale datasets in data-scarce situations. Therefore, this paper suggests a two-stage architectural fine-tuning method for image classification, inspired by the concept of neural architecture search (NAS). One of the main ideas of our proposed method is a mutation with base architectures, which reduces the search cost by using given architectural information. Moreover, an early-stopping is also considered which directly reduces NAS costs. Experimental results verify that our proposed method reduces computational and searching costs by up to 28.2% and 22.3%, compared to existing methods.
Universal Deep Network for Steganalysis of Color Image based on Channel Representation
Nov 24, 2021Up to now, most existing steganalytic methods are designed for grayscale images, and they are not suitable for color images that are widely used in current social networks. In this paper, we design a universal color image steganalysis network (called UCNet) in spatial and JPEG domains. The proposed method includes preprocessing, convolutional, and classification modules. To preserve the steganographic artifacts in each color channel, in preprocessing module, we firstly separate the input image into three channels according to the corresponding embedding spaces (i.e. RGB for spatial steganography and YCbCr for JPEG steganography), and then extract the image residuals with 62 fixed high-pass filters, finally concatenate all truncated residuals for subsequent analysis rather than adding them together with normal convolution like existing CNN-based steganalyzers. To accelerate the network convergence and effectively reduce the number of parameters, in convolutional module, we carefully design three types of layers with different shortcut connections and group convolution structures to further learn high-level steganalytic features. In classification module, we employ a global average pooling and fully connected layer for classification. We conduct extensive experiments on ALASKA II to demonstrate that the proposed method can achieve state-of-the-art results compared with the modern CNN-based steganalyzers (e.g., SRNet and J-YeNet) in both spatial and JPEG domains, while keeping relatively few memory requirements and training time. Furthermore, we also provide necessary descriptions and many ablation experiments to verify the rationality of the network design.
CrAM: A Compression-Aware Minimizer
Jul 28, 2022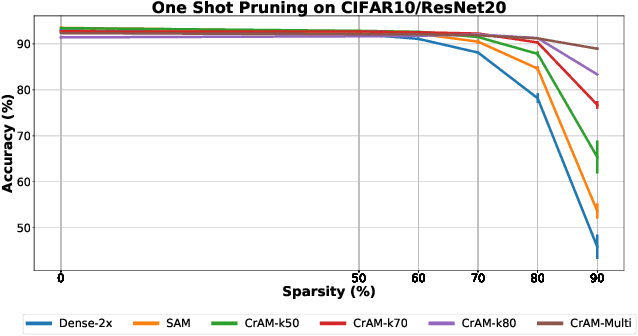

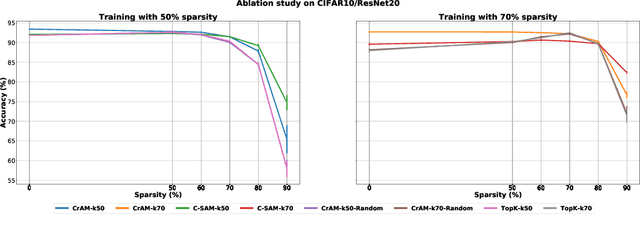
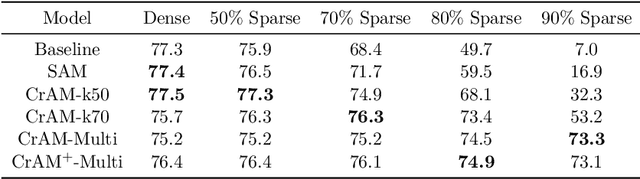
We examine the question of whether SGD-based optimization of deep neural networks (DNNs) can be adapted to produce models which are both highly-accurate and easily-compressible. We propose a new compression-aware minimizer dubbed CrAM, which modifies the SGD training iteration in a principled way, in order to produce models whose local loss behavior is stable under compression operations such as weight pruning or quantization. Experimental results on standard image classification tasks show that CrAM produces dense models that can be more accurate than standard SGD-type baselines, but which are surprisingly stable under weight pruning: for instance, for ResNet50 on ImageNet, CrAM-trained models can lose up to 70% of their weights in one shot with only minor accuracy loss.
Domain Adaptation Meets Zero-Shot Learning: An Annotation-Efficient Approach to Multi-Modality Medical Image Segmentation
Mar 19, 2022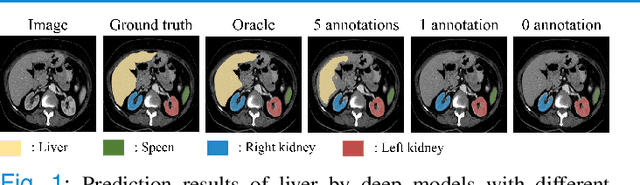
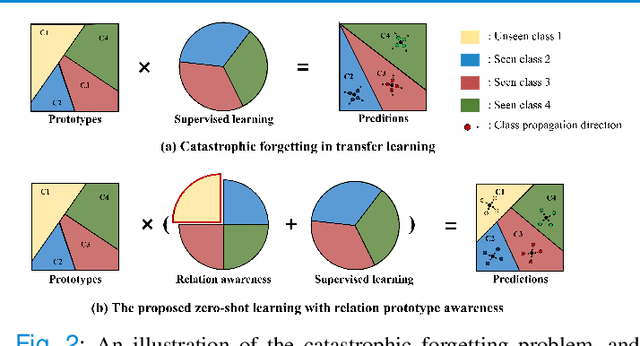
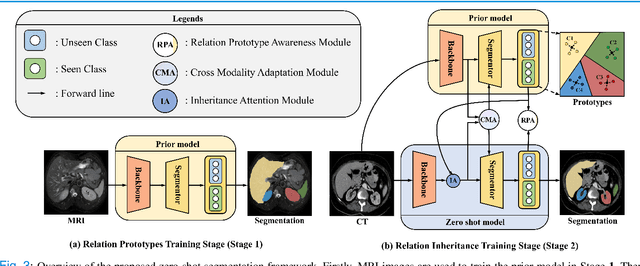
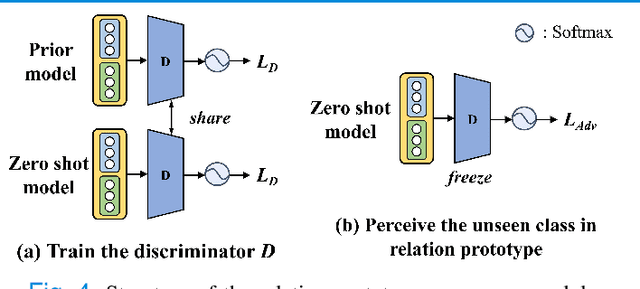
Due to the lack of properly annotated medical data, exploring the generalization capability of the deep model is becoming a public concern. Zero-shot learning (ZSL) has emerged in recent years to equip the deep model with the ability to recognize unseen classes. However, existing studies mainly focus on natural images, which utilize linguistic models to extract auxiliary information for ZSL. It is impractical to apply the natural image ZSL solutions directly to medical images, since the medical terminology is very domain-specific, and it is not easy to acquire linguistic models for the medical terminology. In this work, we propose a new paradigm of ZSL specifically for medical images utilizing cross-modality information. We make three main contributions with the proposed paradigm. First, we extract the prior knowledge about the segmentation targets, called relation prototypes, from the prior model and then propose a cross-modality adaptation module to inherit the prototypes to the zero-shot model. Second, we propose a relation prototype awareness module to make the zero-shot model aware of information contained in the prototypes. Last but not least, we develop an inheritance attention module to recalibrate the relation prototypes to enhance the inheritance process. The proposed framework is evaluated on two public cross-modality datasets including a cardiac dataset and an abdominal dataset. Extensive experiments show that the proposed framework significantly outperforms the state of the arts.
Sparse Nonnegative Tucker Decomposition and Completion under Noisy Observations
Aug 17, 2022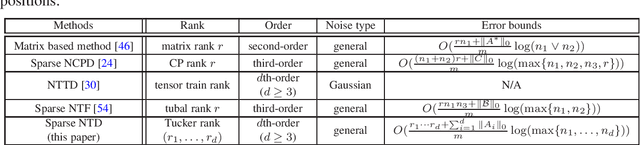
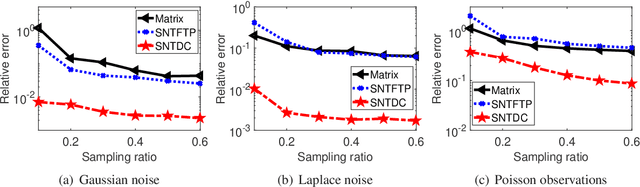
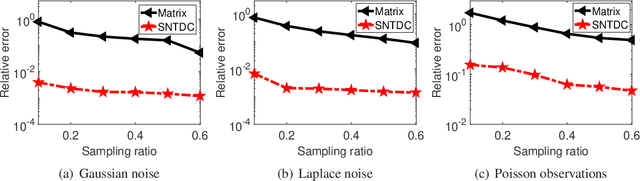
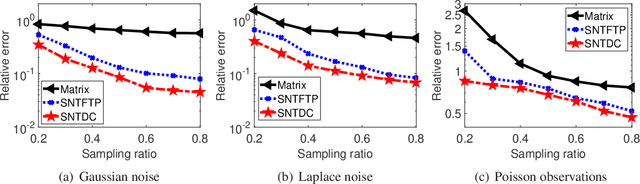
Tensor decomposition is a powerful tool for extracting physically meaningful latent factors from multi-dimensional nonnegative data, and has been an increasing interest in a variety of fields such as image processing, machine learning, and computer vision. In this paper, we propose a sparse nonnegative Tucker decomposition and completion method for the recovery of underlying nonnegative data under noisy observations. Here the underlying nonnegative data tensor is decomposed into a core tensor and several factor matrices with all entries being nonnegative and the factor matrices being sparse. The loss function is derived by the maximum likelihood estimation of the noisy observations, and the $\ell_0$ norm is employed to enhance the sparsity of the factor matrices. We establish the error bound of the estimator of the proposed model under generic noise scenarios, which is then specified to the observations with additive Gaussian noise, additive Laplace noise, and Poisson observations, respectively. Our theoretical results are better than those by existing tensor-based or matrix-based methods. Moreover, the minimax lower bounds are shown to be matched with the derived upper bounds up to logarithmic factors. Numerical examples on both synthetic and real-world data sets demonstrate the superiority of the proposed method for nonnegative tensor data completion.
DAE-GAN: Dynamic Aspect-aware GAN for Text-to-Image Synthesis
Aug 27, 2021
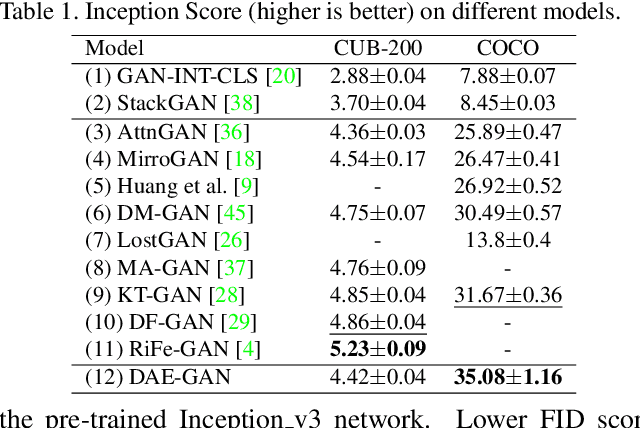
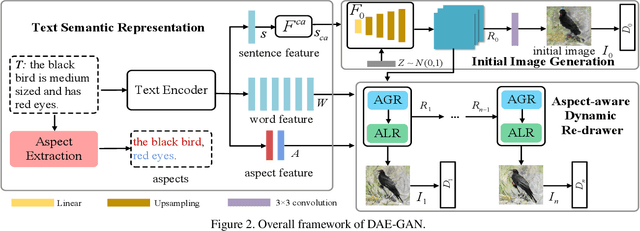
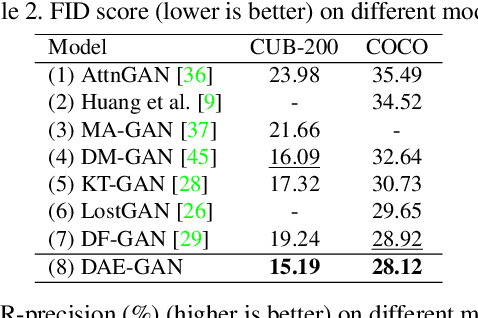
Text-to-image synthesis refers to generating an image from a given text description, the key goal of which lies in photo realism and semantic consistency. Previous methods usually generate an initial image with sentence embedding and then refine it with fine-grained word embedding. Despite the significant progress, the 'aspect' information (e.g., red eyes) contained in the text, referring to several words rather than a word that depicts 'a particular part or feature of something', is often ignored, which is highly helpful for synthesizing image details. How to make better utilization of aspect information in text-to-image synthesis still remains an unresolved challenge. To address this problem, in this paper, we propose a Dynamic Aspect-awarE GAN (DAE-GAN) that represents text information comprehensively from multiple granularities, including sentence-level, word-level, and aspect-level. Moreover, inspired by human learning behaviors, we develop a novel Aspect-aware Dynamic Re-drawer (ADR) for image refinement, in which an Attended Global Refinement (AGR) module and an Aspect-aware Local Refinement (ALR) module are alternately employed. AGR utilizes word-level embedding to globally enhance the previously generated image, while ALR dynamically employs aspect-level embedding to refine image details from a local perspective. Finally, a corresponding matching loss function is designed to ensure the text-image semantic consistency at different levels. Extensive experiments on two well-studied and publicly available datasets (i.e., CUB-200 and COCO) demonstrate the superiority and rationality of our method.