 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Nonlinear Intensity Underwater Sonar Image Matching Method Based on Phase Information and Deep Convolution Features
Nov 29, 2021
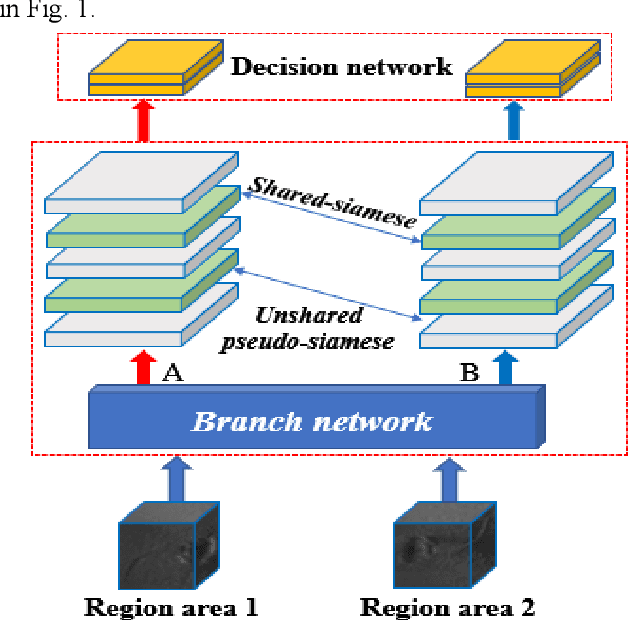
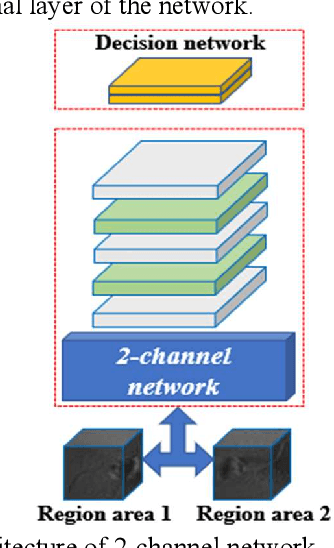
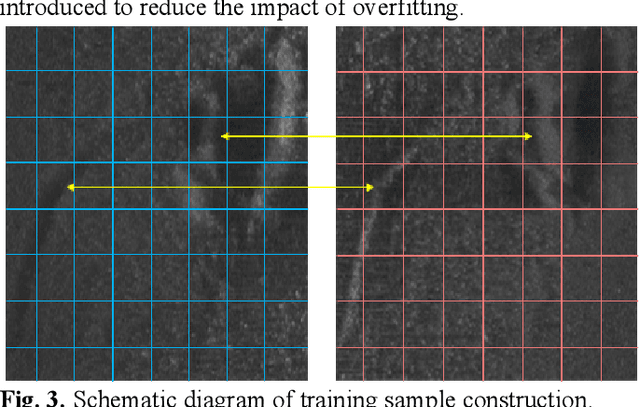
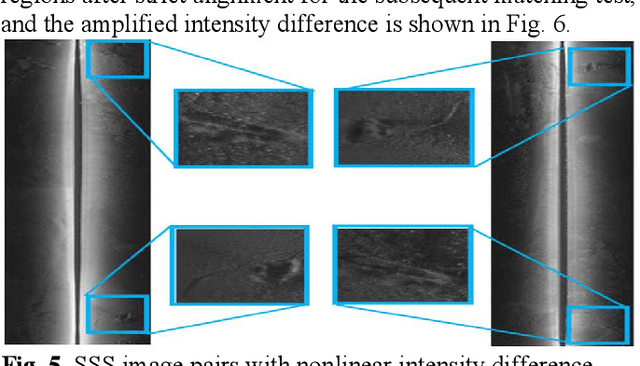
In the field of deep-sea exploration, sonar is presently the only efficient long-distance sensing device. The complicated underwater environment, such as noise interference, low target intensity or background dynamics, has brought many negative effects on sonar imaging. Among them, the problem of nonlinear intensity is extremely prevalent. It is also known as the anisotropy of acoustic sensor imaging, that is, when autonomous underwater vehicles (AUVs) carry sonar to detect the same target from different angles, the intensity variation between image pairs is sometimes very large, which makes the traditional matching algorithm almost ineffective. However, image matching is the basis of comprehensive tasks such as navigation, positioning, and mapping. Therefore, it is very valuable to obtain robust and accurate matching results. This paper proposes a combined matching method based on phase information and deep convolution features. It has two outstanding advantages: one is that the deep convolution features could be used to measure the similarity of the local and global positions of the sonar image; the other is that local feature matching could be performed at the key target position of the sonar image. This method does not need complex manual designs, and completes the matching task of nonlinear intensity sonar images in a close end-to-end manner. Feature matching experiments are carried out on the deep-sea sonar images captured by AUVs, and the results show that our proposal has preeminent matching accuracy and robustness.
Single Image Texture Translation for Data Augmentation
Jun 25, 2021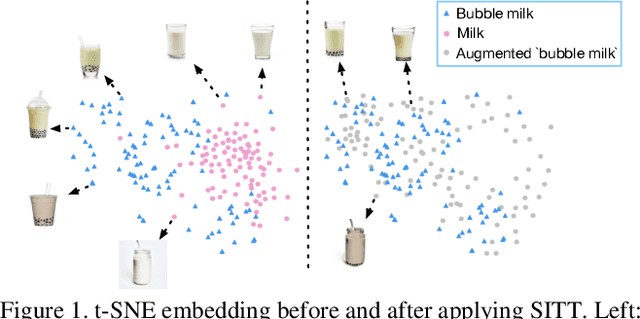
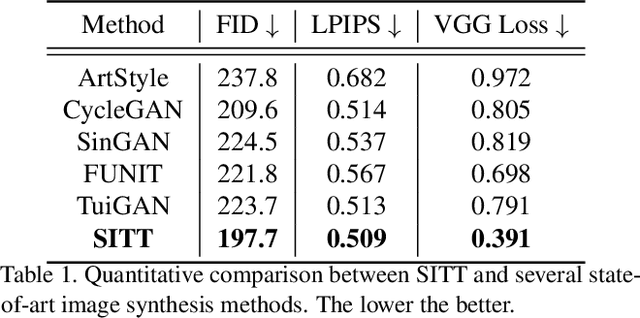
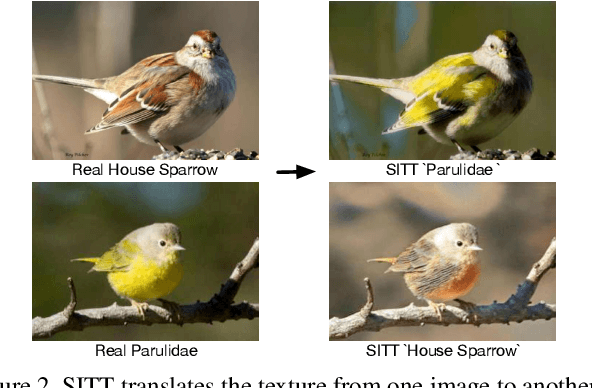
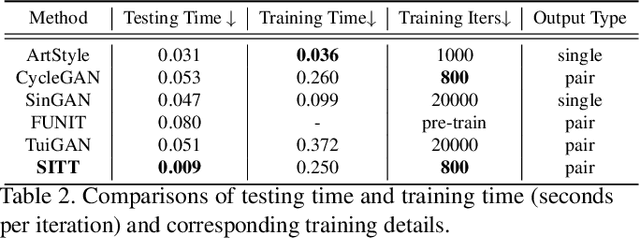
Recent advances in image synthesis enables one to translate images by learning the mapping between a source domain and a target domain. Existing methods tend to learn the distributions by training a model on a variety of datasets, with results evaluated largely in a subjective manner. Relatively few works in this area, however, study the potential use of semantic image translation methods for image recognition tasks. In this paper, we explore the use of Single Image Texture Translation (SITT) for data augmentation. We first propose a lightweight model for translating texture to images based on a single input of source texture, allowing for fast training and testing. Based on SITT, we then explore the use of augmented data in long-tailed and few-shot image classification tasks. We find the proposed method is capable of translating input data into a target domain, leading to consistent improved image recognition performance. Finally, we examine how SITT and related image translation methods can provide a basis for a data-efficient, augmentation engineering approach to model training.
BayesCap: Bayesian Identity Cap for Calibrated Uncertainty in Frozen Neural Networks
Jul 14, 2022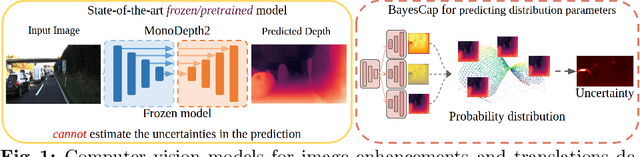
High-quality calibrated uncertainty estimates are crucial for numerous real-world applications, especially for deep learning-based deployed ML systems. While Bayesian deep learning techniques allow uncertainty estimation, training them with large-scale datasets is an expensive process that does not always yield models competitive with non-Bayesian counterparts. Moreover, many of the high-performing deep learning models that are already trained and deployed are non-Bayesian in nature and do not provide uncertainty estimates. To address these issues, we propose BayesCap that learns a Bayesian identity mapping for the frozen model, allowing uncertainty estimation. BayesCap is a memory-efficient method that can be trained on a small fraction of the original dataset, enhancing pretrained non-Bayesian computer vision models by providing calibrated uncertainty estimates for the predictions without (i) hampering the performance of the model and (ii) the need for expensive retraining the model from scratch. The proposed method is agnostic to various architectures and tasks. We show the efficacy of our method on a wide variety of tasks with a diverse set of architectures, including image super-resolution, deblurring, inpainting, and crucial application such as medical image translation. Moreover, we apply the derived uncertainty estimates to detect out-of-distribution samples in critical scenarios like depth estimation in autonomous driving. Code is available at https://github.com/ExplainableML/BayesCap.
Identifying and Combating Bias in Segmentation Networks by leveraging multiple resolutions
Jun 29, 2022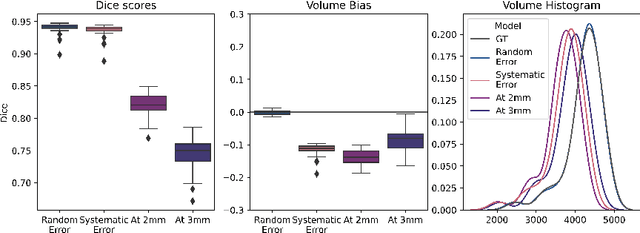
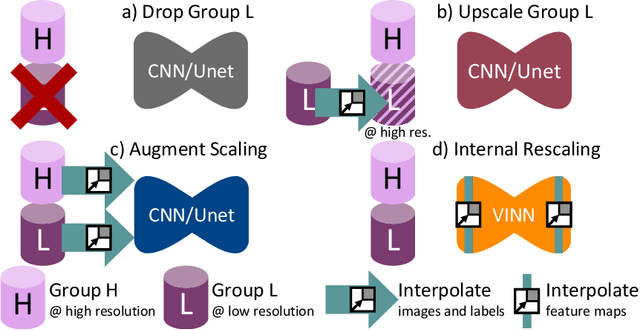
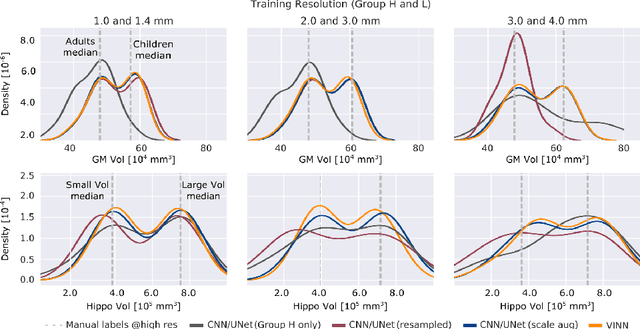
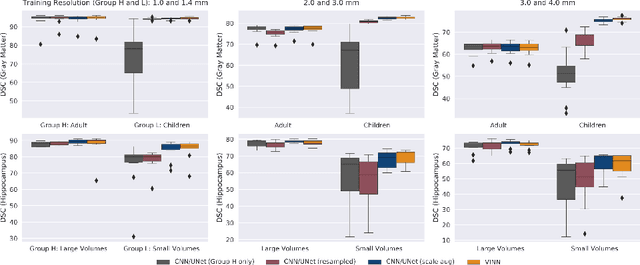
Exploration of bias has significant impact on the transparency and applicability of deep learning pipelines in medical settings, yet is so far woefully understudied. In this paper, we consider two separate groups for which training data is only available at differing image resolutions. For group H, available images and labels are at the preferred high resolution while for group L only deprecated lower resolution data exist. We analyse how this resolution-bias in the data distribution propagates to systematically biased predictions for group L at higher resolutions. Our results demonstrate that single-resolution training settings result in significant loss of volumetric group differences that translate to erroneous segmentations as measured by DSC and subsequent classification failures on the low resolution group. We further explore how training data across resolutions can be used to combat this systematic bias. Specifically, we investigate the effect of image resampling, scale augmentation and resolution independence and demonstrate that biases can effectively be reduced with multi-resolution approaches.
Multi-Label Retinal Disease Classification using Transformers
Jul 07, 2022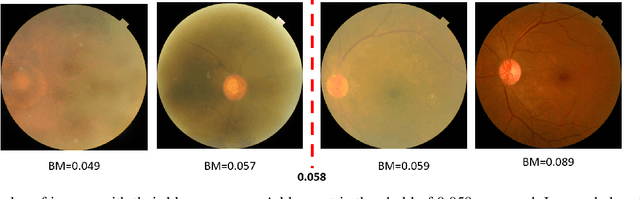
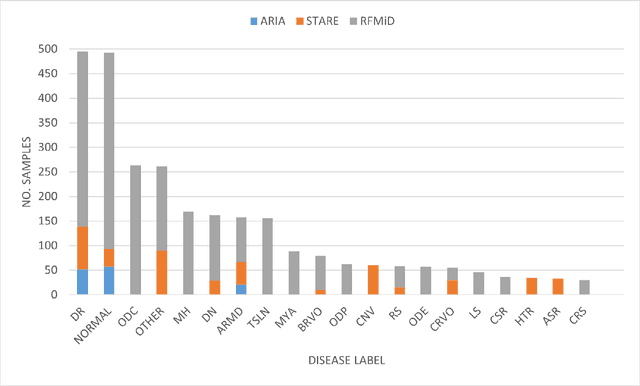
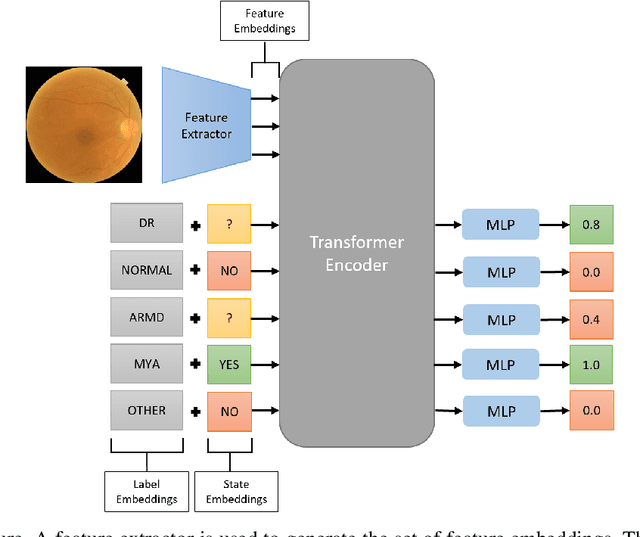
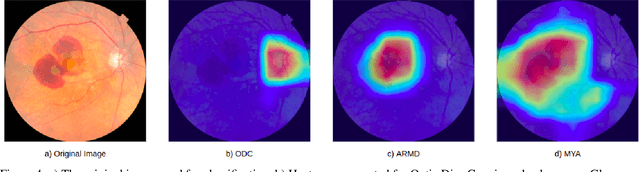
Early detection of retinal diseases is one of the most important means of preventing partial or permanent blindness in patients. In this research, a novel multi-label classification system is proposed for the detection of multiple retinal diseases, using fundus images collected from a variety of sources. First, a new multi-label retinal disease dataset, the MuReD dataset, is constructed, using a number of publicly available datasets for fundus disease classification. Next, a sequence of post-processing steps is applied to ensure the quality of the image data and the range of diseases, present in the dataset. For the first time in fundus multi-label disease classification, a transformer-based model optimized through extensive experimentation is used for image analysis and decision making. Numerous experiments are performed to optimize the configuration of the proposed system. It is shown that the approach performs better than state-of-the-art works on the same task by 7.9% and 8.1% in terms of AUC score for disease detection and disease classification, respectively. The obtained results further support the potential applications of transformer-based architectures in the medical imaging field.
From WSI-level to Patch-level: Structure Prior Guided Binuclear Cell Fine-grained Detection
Aug 26, 2022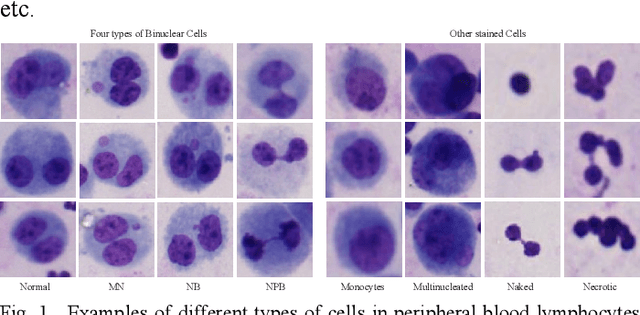
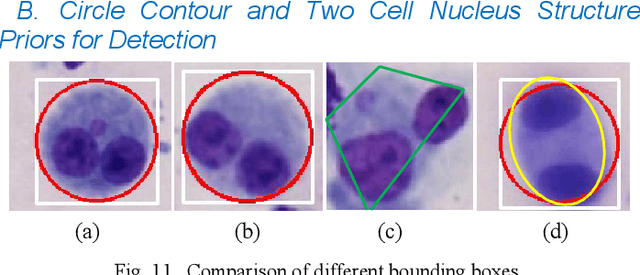
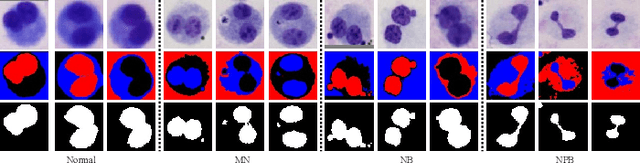
Accurately and quickly binuclear cell (BC) detection plays a significant role in predicting the risk of leukemia and other malignant tumors. However, manual microscopy counting is time-consuming and lacks objectivity. Moreover, with the limitation of staining quality and diversity of morphology features in BC microscopy whole slide images (WSIs), traditional image processing approaches are helpless. To overcome this challenge, we propose a two-stage detection method inspired by the structure prior of BC based on deep learning, which cascades to implement BCs coarse detection at the WSI-level and fine-grained classification in patch-level. The coarse detection network is a multi-task detection framework based on circular bounding boxes for cells detection, and central key points for nucleus detection. The circle representation reduces the degrees of freedom, mitigates the effect of surrounding impurities compared to usual rectangular boxes and can be rotation invariant in WSI. Detecting key points in the nucleus can assist network perception and be used for unsupervised color layer segmentation in later fine-grained classification. The fine classification network consists of a background region suppression module based on color layer mask supervision and a key region selection module based on a transformer due to its global modeling capability. Additionally, an unsupervised and unpaired cytoplasm generator network is firstly proposed to expand the long-tailed distribution dataset. Finally, experiments are performed on BC multicenter datasets. The proposed BC fine detection method outperforms other benchmarks in almost all the evaluation criteria, providing clarification and support for tasks such as cancer screenings.
The 2021 Image Similarity Dataset and Challenge
Jun 17, 2021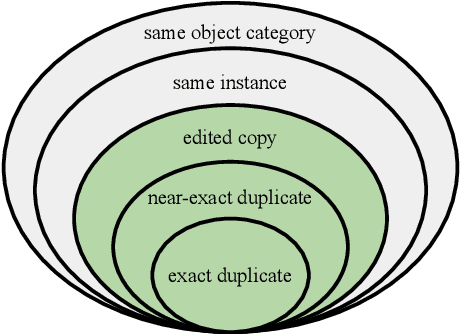
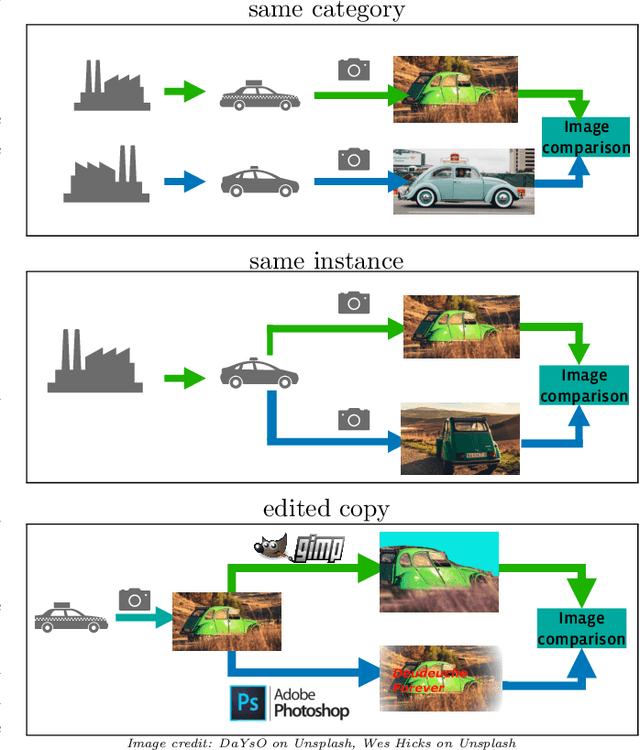

This paper introduces a new benchmark for large-scale image similarity detection. This benchmark is used for the Image Similarity Challenge at NeurIPS'21 (ISC2021). The goal is to determine whether a query image is a modified copy of any image in a reference corpus of size 1~million. The benchmark features a variety of image transformations such as automated transformations, hand-crafted image edits and machine-learning based manipulations. This mimics real-life cases appearing in social media, for example for integrity-related problems dealing with misinformation and objectionable content. The strength of the image manipulations, and therefore the difficulty of the benchmark, is calibrated according to the performance of a set of baseline approaches. Both the query and reference set contain a majority of ``distractor'' images that do not match, which corresponds to a real-life needle-in-haystack setting, and the evaluation metric reflects that. We expect the DISC21 benchmark to promote image copy detection as an important and challenging computer vision task and refresh the state of the art.
Two-stage Visual Cues Enhancement Network for Referring Image Segmentation
Oct 09, 2021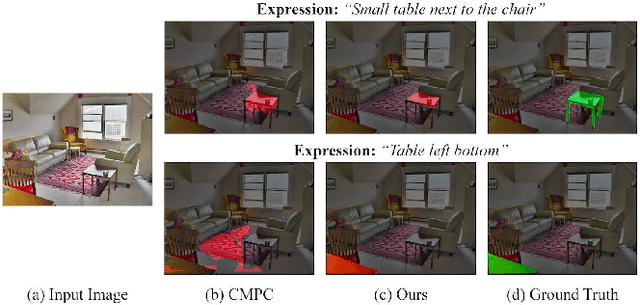
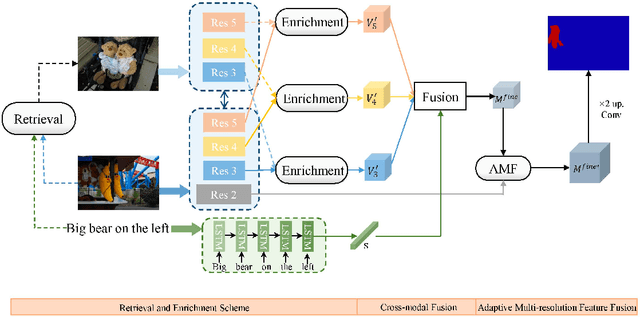
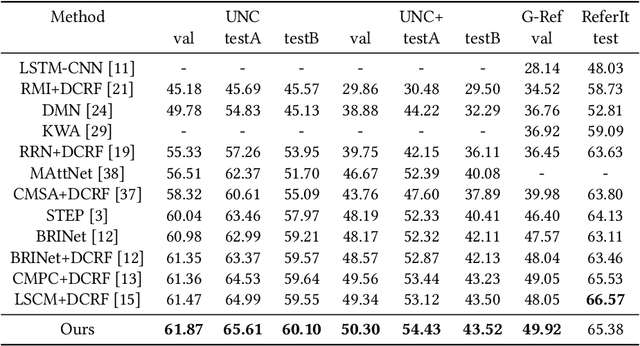
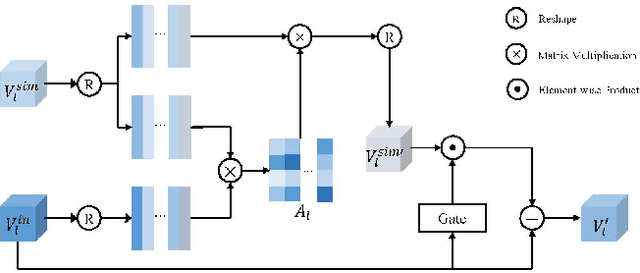
Referring Image Segmentation (RIS) aims at segmenting the target object from an image referred by one given natural language expression. The diverse and flexible expressions as well as complex visual contents in the images raise the RIS model with higher demands for investigating fine-grained matching behaviors between words in expressions and objects presented in images. However, such matching behaviors are hard to be learned and captured when the visual cues of referents (i.e. referred objects) are insufficient, as the referents with weak visual cues tend to be easily confused by cluttered background at boundary or even overwhelmed by salient objects in the image. And the insufficient visual cues issue can not be handled by the cross-modal fusion mechanisms as done in previous work. In this paper, we tackle this problem from a novel perspective of enhancing the visual information for the referents by devising a Two-stage Visual cues enhancement Network (TV-Net), where a novel Retrieval and Enrichment Scheme (RES) and an Adaptive Multi-resolution feature Fusion (AMF) module are proposed. Through the two-stage enhancement, our proposed TV-Net enjoys better performances in learning fine-grained matching behaviors between the natural language expression and image, especially when the visual information of the referent is inadequate, thus produces better segmentation results. Extensive experiments are conducted to validate the effectiveness of the proposed method on the RIS task, with our proposed TV-Net surpassing the state-of-the-art approaches on four benchmark datasets.
StarEnhancer: Learning Real-Time and Style-Aware Image Enhancement
Jul 28, 2021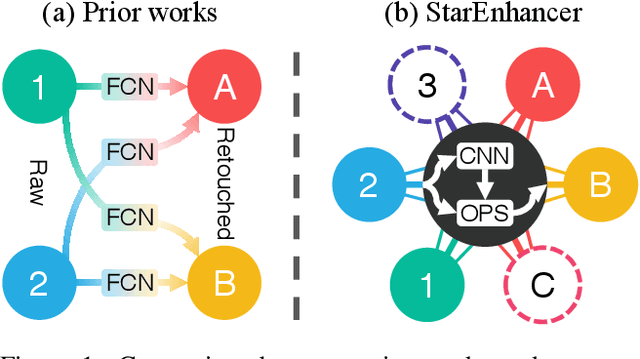
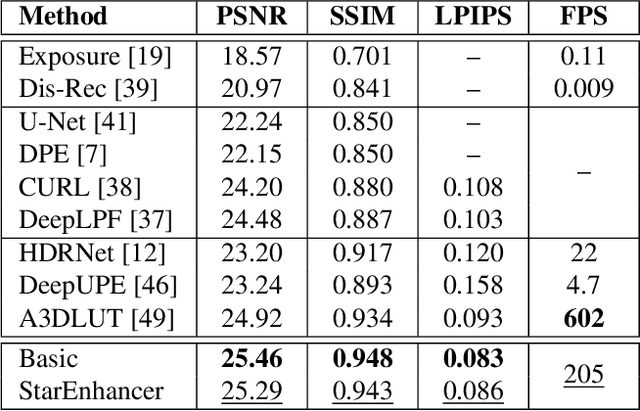
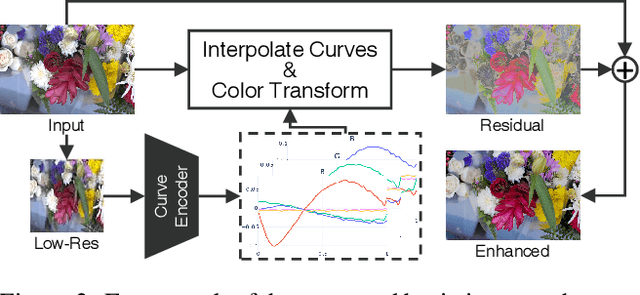
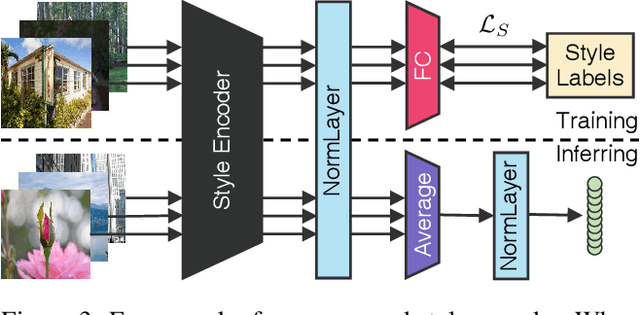
Image enhancement is a subjective process whose targets vary with user preferences. In this paper, we propose a deep learning-based image enhancement method covering multiple tonal styles using only a single model dubbed StarEnhancer. It can transform an image from one tonal style to another, even if that style is unseen. With a simple one-time setting, users can customize the model to make the enhanced images more in line with their aesthetics. To make the method more practical, we propose a well-designed enhancer that can process a 4K-resolution image over 200 FPS but surpasses the contemporaneous single style image enhancement methods in terms of PSNR, SSIM, and LPIPS. Finally, our proposed enhancement method has good interactability, which allows the user to fine-tune the enhanced image using intuitive options.
Perceptually Optimized Deep High-Dynamic-Range Image Tone Mapping
Sep 02, 2021
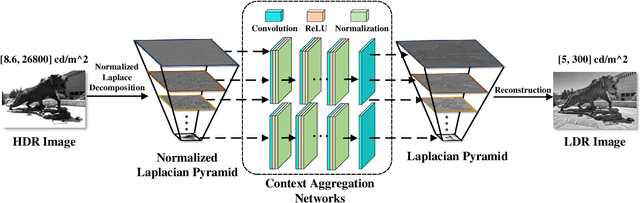


We describe a deep high-dynamic-range (HDR) image tone mapping operator that is computationally efficient and perceptually optimized. We first decompose an HDR image into a normalized Laplacian pyramid, and use two deep neural networks (DNNs) to estimate the Laplacian pyramid of the desired tone-mapped image from the normalized representation. We then end-to-end optimize the entire method over a database of HDR images by minimizing the normalized Laplacian pyramid distance (NLPD), a recently proposed perceptual metric. Qualitative and quantitative experiments demonstrate that our method produces images with better visual quality, and runs the fastest among existing local tone mapping algorithms.