 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DPIT: Dual-Pipeline Integrated Transformer for Human Pose Estimation
Sep 02, 2022
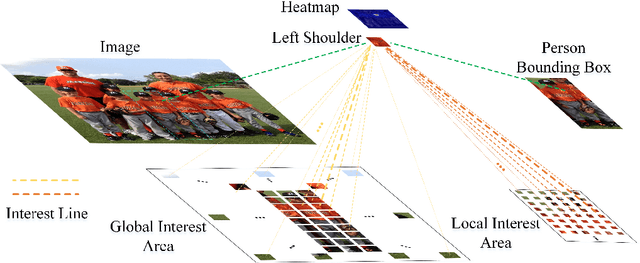
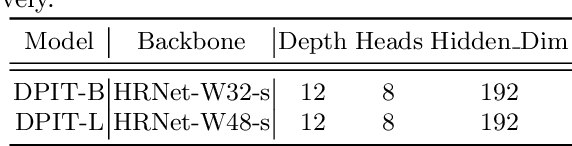
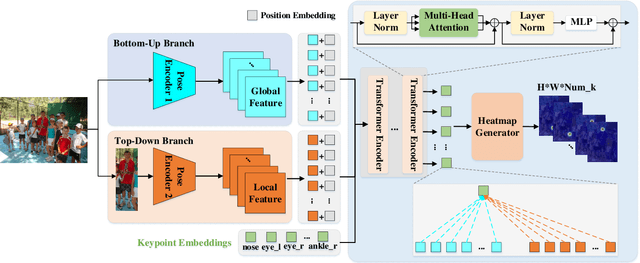
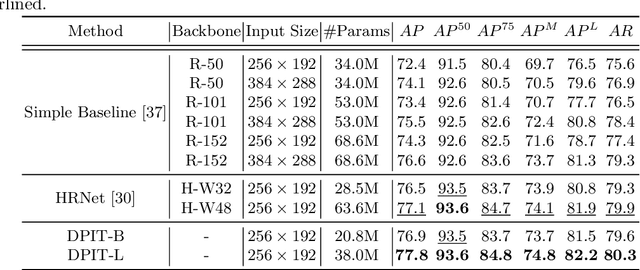
Human pose estimation aims to figure out the keypoints of all people in different scenes. Current approaches still face some challenges despite promising results. Existing top-down methods deal with a single person individually, without the interaction between different people and the scene they are situated in. Consequently, the performance of human detection degrades when serious occlusion happens. On the other hand, existing bottom-up methods consider all people at the same time and capture the global knowledge of the entire image. However, they are less accurate than the top-down methods due to the scale variation. To address these problems, we propose a novel Dual-Pipeline Integrated Transformer (DPIT) by integrating top-down and bottom-up pipelines to explore the visual clues of different receptive fields and achieve their complementarity. Specifically, DPIT consists of two branches, the bottom-up branch deals with the whole image to capture the global visual information, while the top-down branch extracts the feature representation of local vision from the single-human bounding box. Then, the extracted feature representations from bottom-up and top-down branches are fed into the transformer encoder to fuse the global and local knowledge interactively. Moreover, we define the keypoint queries to explore both full-scene and single-human posture visual clues to realize the mutual complementarity of the two pipelines. To the best of our knowledge, this is one of the first works to integrate the bottom-up and top-down pipelines with transformers for human pose estimation. Extensive experiments on COCO and MPII datasets demonstrate that our DPIT achieves comparable performance to the state-of-the-art methods.
Adaptive Multi-stage Density Ratio Estimation for Learning Latent Space Energy-based Model
Sep 19, 2022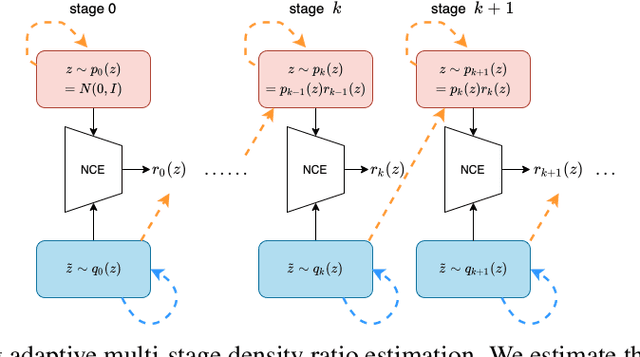
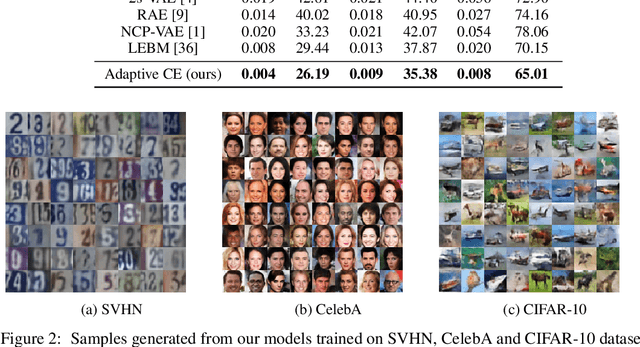
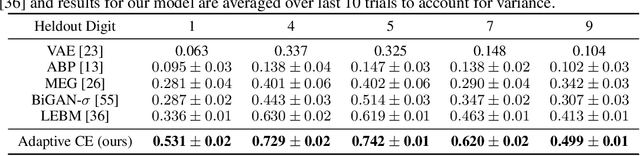

This paper studies the fundamental problem of learning energy-based model (EBM) in the latent space of the generator model. Learning such prior model typically requires running costly Markov Chain Monte Carlo (MCMC). Instead, we propose to use noise contrastive estimation (NCE) to discriminatively learn the EBM through density ratio estimation between the latent prior density and latent posterior density. However, the NCE typically fails to accurately estimate such density ratio given large gap between two densities. To effectively tackle this issue and learn more expressive prior models, we develop the adaptive multi-stage density ratio estimation which breaks the estimation into multiple stages and learn different stages of density ratio sequentially and adaptively. The latent prior model can be gradually learned using ratio estimated in previous stage so that the final latent space EBM prior can be naturally formed by product of ratios in different stages. The proposed method enables informative and much sharper prior than existing baselines, and can be trained efficiently. Our experiments demonstrate strong performances in image generation and reconstruction as well as anomaly detection.
Photoacoustic vector tomography for deep hemodynamic imaging
Sep 19, 2022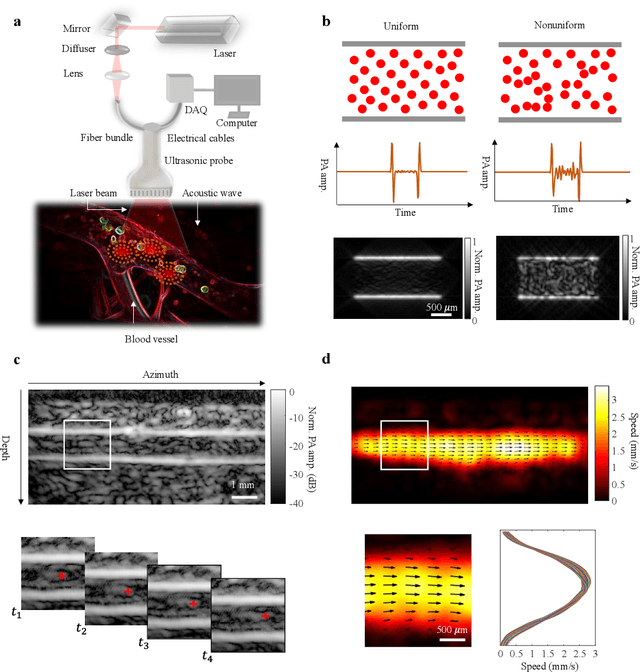
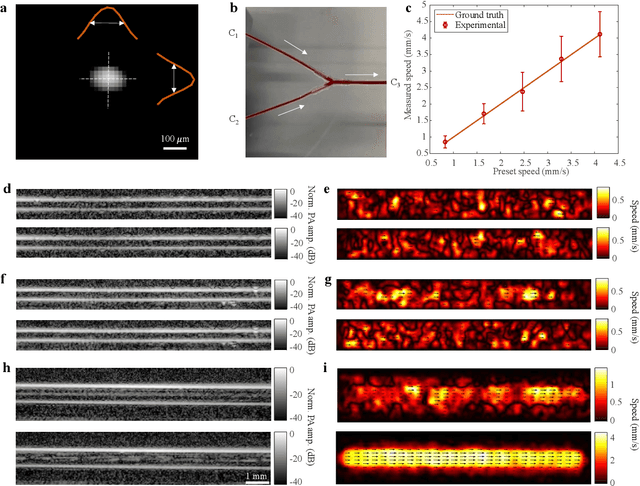
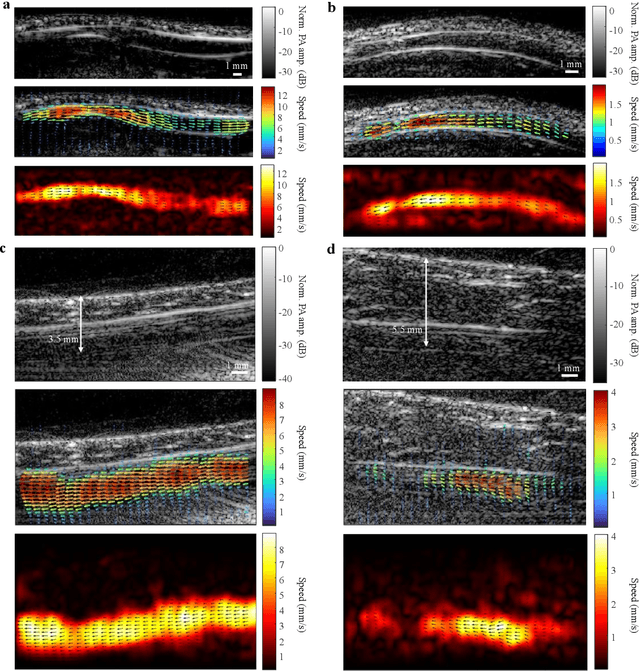
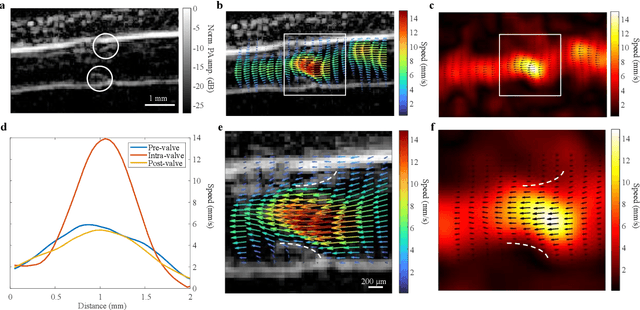
Non-invasive imaging of deep blood vessels for mapping hemodynamics remains an open quest in biomedical optical imaging. Although pure optical imaging techniques offer rich optical contrast of blood and have been reported to measure blood flow, they are generally limited to surface imaging within the optical diffusion limit of about one millimeter. Herein, we present photoacoustic vector tomography (PAVT), breaking through the optical diffusion limit to image deep blood flow with speed and direction quantification. PAVT synergizes the spatial heterogeneity of blood and the photoacoustic contrast; it compiles successive single-shot, wide-field photoacoustic images to directly visualize the frame-to-frame propagation of the blood with pixel-wise flow velocity estimation. We demonstrated in vivo that PAVT allows hemodynamic quantification of deep blood vessels at five times the optical diffusion limit (more than five millimeters), leading to vector mapping of blood flow in humans. By offering the capability for deep hemodynamic imaging with optical contrast, PAVT may become a powerful tool for monitoring and diagnosing vascular diseases and mapping circulatory system function.
Number of Attention Heads vs Number of Transformer-Encoders in Computer Vision
Sep 15, 2022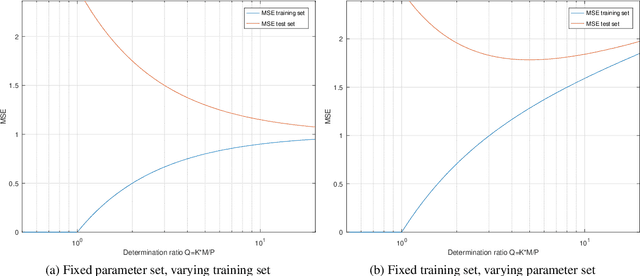
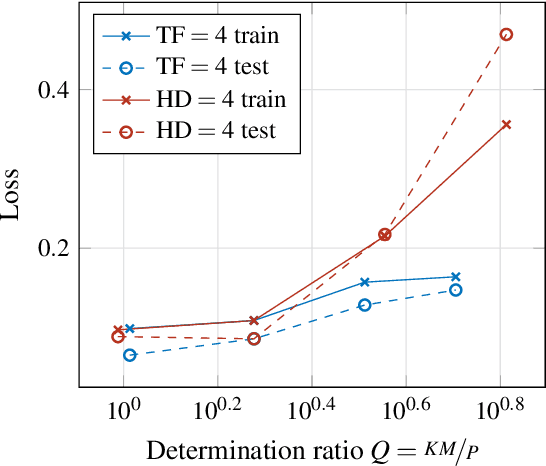
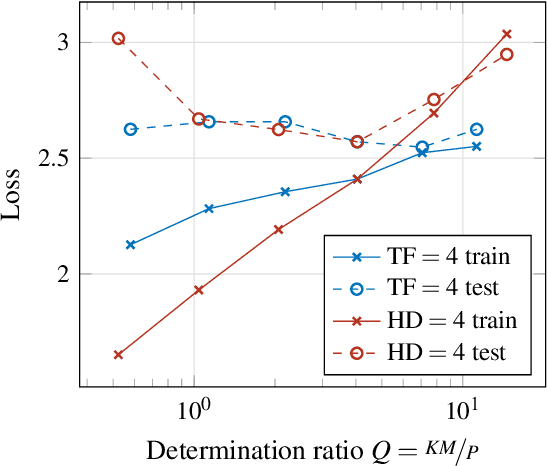
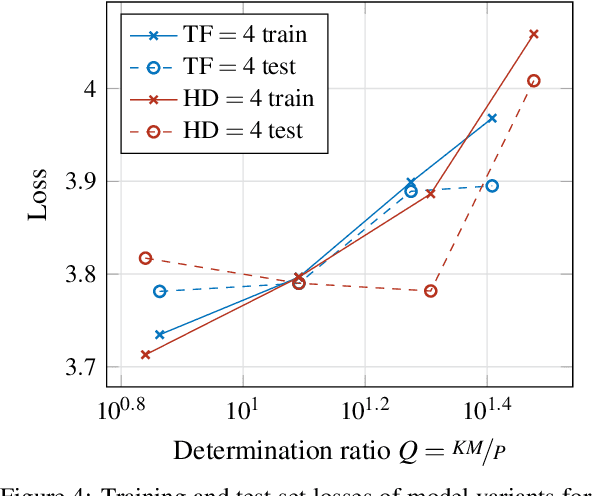
Determining an appropriate number of attention heads on one hand and the number of transformer-encoders, on the other hand, is an important choice for Computer Vision (CV) tasks using the Transformer architecture. Computing experiments confirmed the expectation that the total number of parameters has to satisfy the condition of overdetermination (i.e., number of constraints significantly exceeding the number of parameters). Then, good generalization performance can be expected. This sets the boundaries within which the number of heads and the number of transformers can be chosen. If the role of context in images to be classified can be assumed to be small, it is favorable to use multiple transformers with a low number of heads (such as one or two). In classifying objects whose class may heavily depend on the context within the image (i.e., the meaning of a patch being dependent on other patches), the number of heads is equally important as that of transformers.
Uncertainty Aware Multitask Pyramid Vision Transformer For UAV-Based Object Re-Identification
Sep 19, 2022
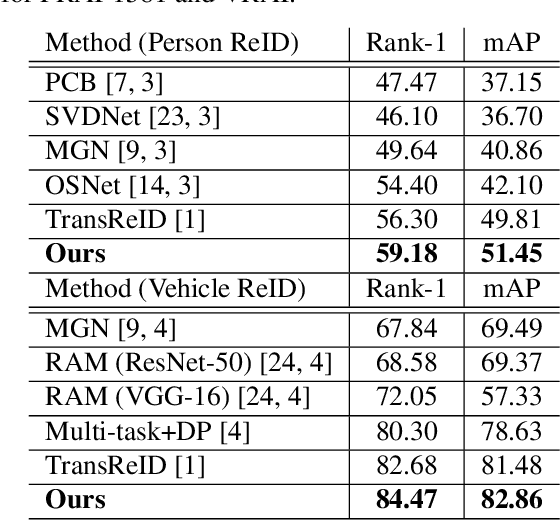
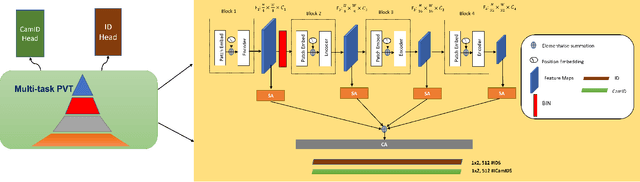
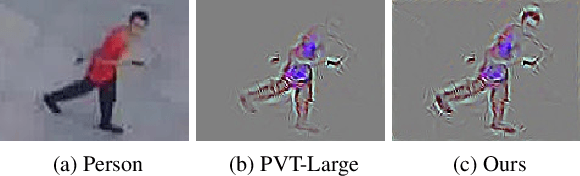
Object Re-IDentification (ReID), one of the most significant problems in biometrics and surveillance systems, has been extensively studied by image processing and computer vision communities in the past decades. Learning a robust and discriminative feature representation is a crucial challenge for object ReID. The problem is even more challenging in ReID based on Unmanned Aerial Vehicle (UAV) as the images are characterized by continuously varying camera parameters (e.g., view angle, altitude, etc.) of a flying drone. To address this challenge, multiscale feature representation has been considered to characterize images captured from UAV flying at different altitudes. In this work, we propose a multitask learning approach, which employs a new multiscale architecture without convolution, Pyramid Vision Transformer (PVT), as the backbone for UAV-based object ReID. By uncertainty modeling of intraclass variations, our proposed model can be jointly optimized using both uncertainty-aware object ID and camera ID information. Experimental results are reported on PRAI and VRAI, two ReID data sets from aerial surveillance, to verify the effectiveness of our proposed approach
3D Cartoon Face Generation with Controllable Expressions from a Single GAN Image
Jul 29, 2022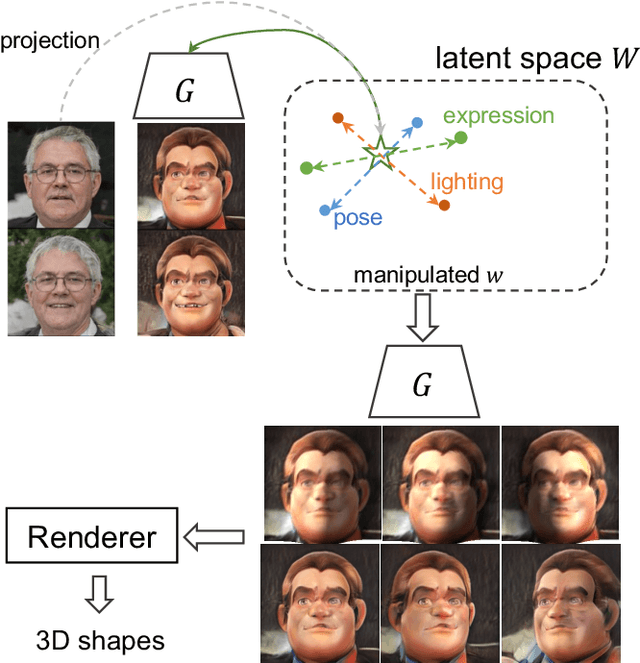


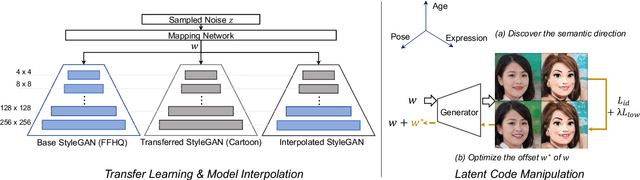
In this paper, we investigate an open research task of generating 3D cartoon face shapes from single 2D GAN generated human faces and without 3D supervision, where we can also manipulate the facial expressions of the 3D shapes. To this end, we discover the semantic meanings of StyleGAN latent space, such that we are able to produce face images of various expressions, poses, and lighting by controlling the latent codes. Specifically, we first finetune the pretrained StyleGAN face model on the cartoon datasets. By feeding the same latent codes to face and cartoon generation models, we aim to realize the translation from 2D human face images to cartoon styled avatars. We then discover semantic directions of the GAN latent space, in an attempt to change the facial expressions while preserving the original identity. As we do not have any 3D annotations for cartoon faces, we manipulate the latent codes to generate images with different poses and lighting, such that we can reconstruct the 3D cartoon face shapes. We validate the efficacy of our method on three cartoon datasets qualitatively and quantitatively.
VS-CAM: Vertex Semantic Class Activation Mapping to Interpret Vision Graph Neural Network
Sep 15, 2022

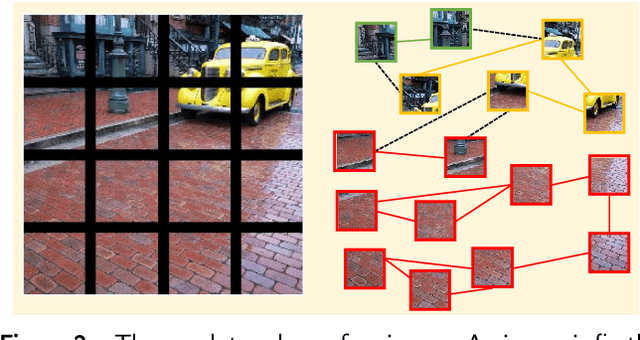

Graph convolutional neural network (GCN) has drawn increasing attention and attained good performance in various computer vision tasks, however, there lacks a clear interpretation of GCN's inner mechanism. For standard convolutional neural networks (CNNs), class activation mapping (CAM) methods are commonly used to visualize the connection between CNN's decision and image region by generating a heatmap. Nonetheless, such heatmap usually exhibits semantic-chaos when these CAMs are applied to GCN directly. In this paper, we proposed a novel visualization method particularly applicable to GCN, Vertex Semantic Class Activation Mapping (VS-CAM). VS-CAM includes two independent pipelines to produce a set of semantic-probe maps and a semantic-base map, respectively. Semantic-probe maps are used to detect the semantic information from semantic-base map to aggregate a semantic-aware heatmap. Qualitative results show that VS-CAM can obtain heatmaps where the highlighted regions match the objects much more precisely than CNN-based CAM. The quantitative evaluation further demonstrates the superiority of VS-CAM.
FedMed-GAN: Federated Multi-Modal Unsupervised Brain Image Synthesis
Jan 22, 2022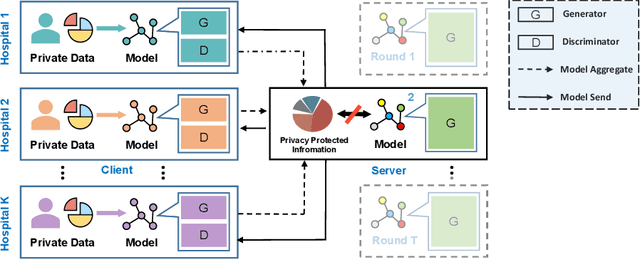

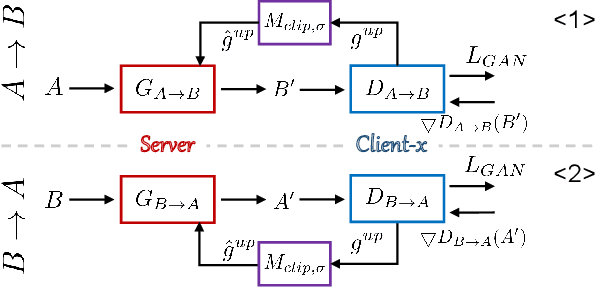
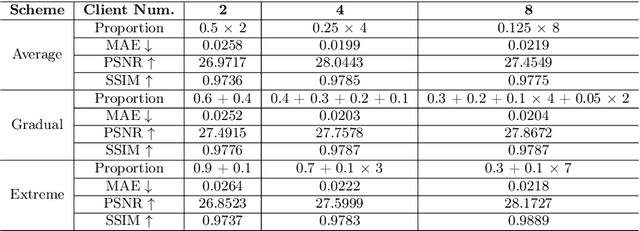
Utilizing the paired multi-modal neuroimaging data has been proved to be effective to investigate human cognitive activities and certain pathologies. However, it is not practical to obtain the full set of paired neuroimaging data centrally since the collection faces several constraints, e.g., high examination costs, long acquisition time, and even image corruption. In addition, most of the paired neuroimaging data are dispersed into different medical institutions and cannot group together for centralized training considering the privacy issues. Under the circumstance, there is a clear need to launch federated learning and facilitate the integration of other unpaired data from different hospitals or data owners. In this paper, we build up a new benchmark for federated multi-modal unsupervised brain image synthesis (termed as FedMed-GAN) to bridge the gap between federated learning and medical GAN. Moreover, based on the similarity of edge information across multi-modal neuroimaging data, we propose a novel edge loss to solve the generative mode collapse issue of FedMed-GAN and mitigate the performance drop resulting from differential privacy. Compared with the state-of-the-art method shown in our built benchmark, our novel edge loss could significantly speed up the generator convergence rate without sacrificing performance under different unpaired data distribution settings.
A detail-enhanced sampling strategy in Hadamard single-pixel imaging
Sep 09, 2022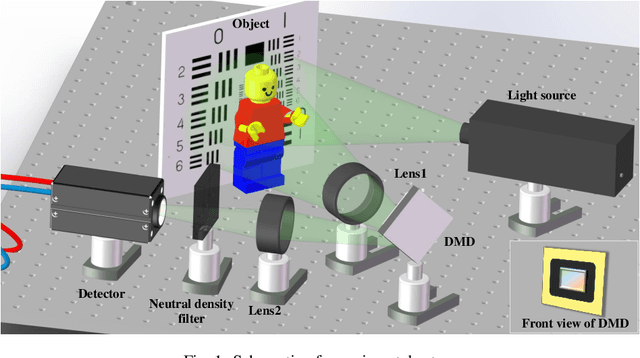
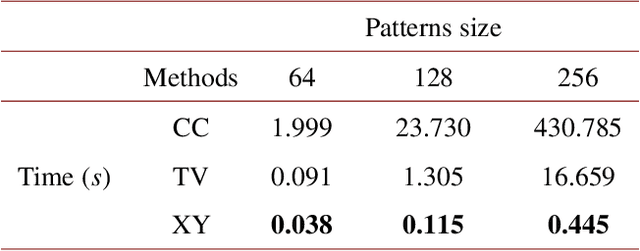
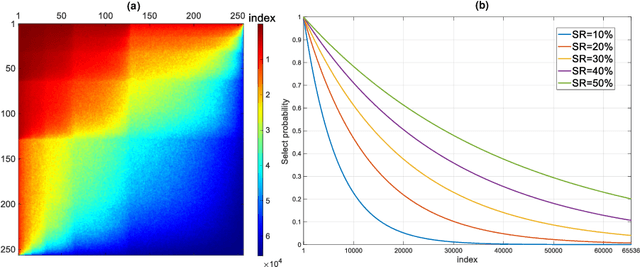
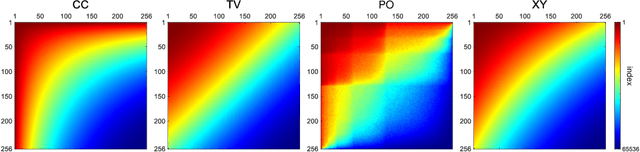
Hadamard single-pixel imaging (HSI) is an appealing imaging technique due to its features of low hardware complexity and industrial cost. To improve imaging efficiency, many studies have focused on sorting Hadamard patterns to obtain reliable reconstructed images with very few samples. In this study, we present an efficient HSI imaging method that employs an exponential probability function to sample Hadamard spectra along a direction with better energy concentration for obtaining Hadamard patterns. We also propose an XY order to further optimize the pattern-selection method with extremely fast Hadamard order generation while retaining the original performance. We used the compressed sensing algorithm for image reconstruction. The simulation and experimental results show that these pattern-selection method reliably reconstructs objects and preserves the edge and details of images.
Random Data Augmentation based Enhancement: A Generalized Enhancement Approach for Medical Datasets
Oct 03, 2022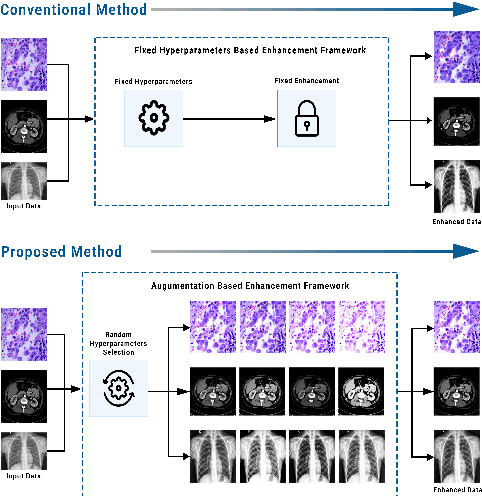

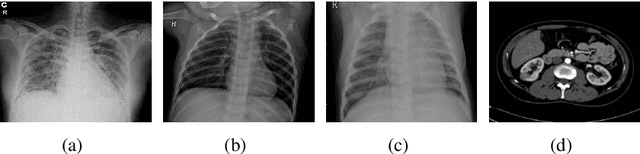

Over the years, the paradigm of medical image analysis has shifted from manual expertise to automated systems, often using deep learning (DL) systems. The performance of deep learning algorithms is highly dependent on data quality. Particularly for the medical domain, it is an important aspect as medical data is very sensitive to quality and poor quality can lead to misdiagnosis. To improve the diagnostic performance, research has been done both in complex DL architectures and in improving data quality using dataset dependent static hyperparameters. However, the performance is still constrained due to data quality and overfitting of hyperparameters to a specific dataset. To overcome these issues, this paper proposes random data augmentation based enhancement. The main objective is to develop a generalized, data-independent and computationally efficient enhancement approach to improve medical data quality for DL. The quality is enhanced by improving the brightness and contrast of images. In contrast to the existing methods, our method generates enhancement hyperparameters randomly within a defined range, which makes it robust and prevents overfitting to a specific dataset. To evaluate the generalization of the proposed method, we use four medical datasets and compare its performance with state-of-the-art methods for both classification and segmentation tasks. For grayscale imagery, experiments have been performed with: COVID-19 chest X-ray, KiTS19, and for RGB imagery with: LC25000 datasets. Experimental results demonstrate that with the proposed enhancement methodology, DL architectures outperform other existing methods. Our code is publicly available at: https://github.com/aleemsidra/Augmentation-Based-Generalized-Enhancement