 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Look where you look! Saliency-guided Q-networks for visual RL tasks
Sep 16, 2022
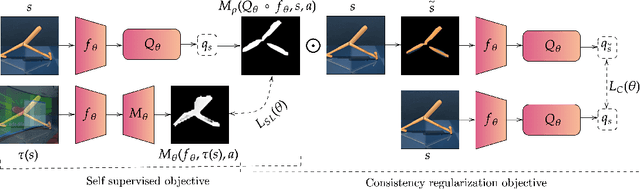
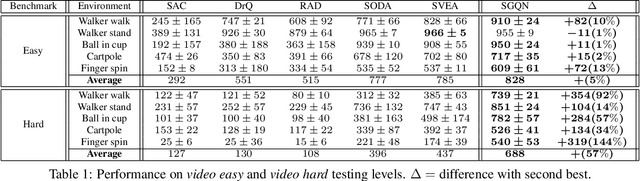

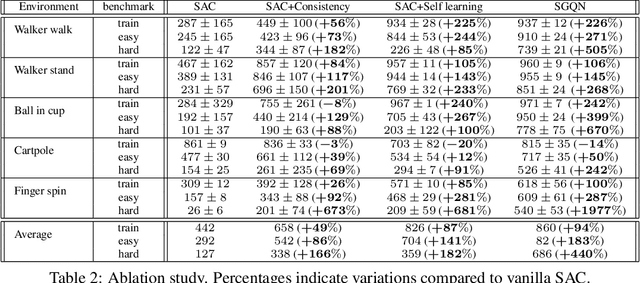
Deep reinforcement learning policies, despite their outstanding efficiency in simulated visual control tasks, have shown disappointing ability to generalize across disturbances in the input training images. Changes in image statistics or distracting background elements are pitfalls that prevent generalization and real-world applicability of such control policies. We elaborate on the intuition that a good visual policy should be able to identify which pixels are important for its decision, and preserve this identification of important sources of information across images. This implies that training of a policy with small generalization gap should focus on such important pixels and ignore the others. This leads to the introduction of saliency-guided Q-networks (SGQN), a generic method for visual reinforcement learning, that is compatible with any value function learning method. SGQN vastly improves the generalization capability of Soft Actor-Critic agents and outperforms existing stateof-the-art methods on the Deepmind Control Generalization benchmark, setting a new reference in terms of training efficiency, generalization gap, and policy interpretability.
DPICT: Deep Progressive Image Compression Using Trit-Planes
Dec 12, 2021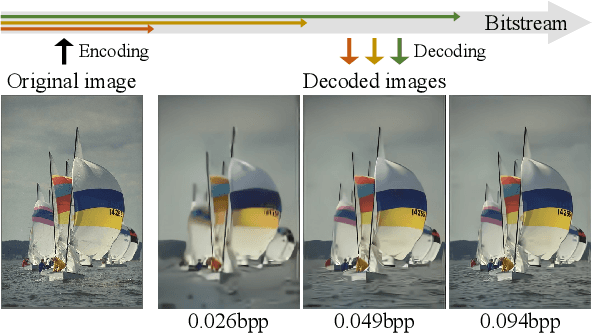
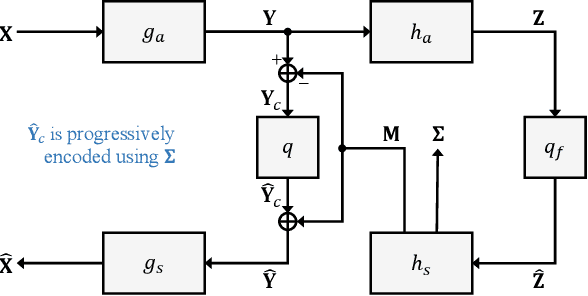
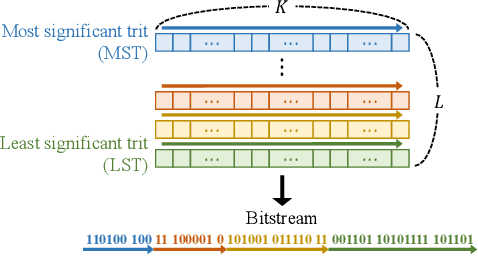
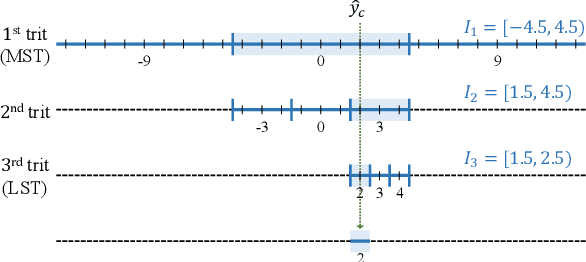
We propose the deep progressive image compression using trit-planes (DPICT) algorithm, which is the first learning-based codec supporting fine granular scalability (FGS). First, we transform an image into a latent tensor using an analysis network. Then, we represent the latent tensor in ternary digits (trits) and encode it into a compressed bitstream trit-plane by trit-plane in the decreasing order of significance. Moreover, within each trit-plane, we sort the trits according to their rate-distortion priorities and transmit more important information first. Since the compression network is less optimized for the cases of using fewer trit-planes, we develop a postprocessing network for refining reconstructed images at low rates. Experimental results show that DPICT outperforms conventional progressive codecs significantly, while enabling FGS transmission.
Automatic Ultrasound Image Segmentation of Supraclavicular Nerve Using Dilated U-Net Deep Learning Architecture
Aug 09, 2022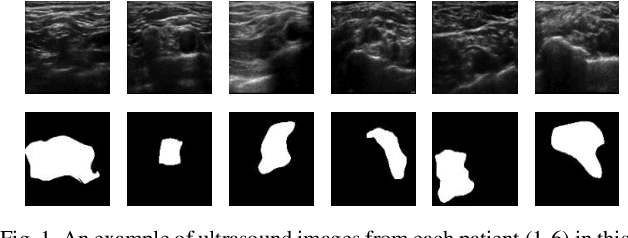
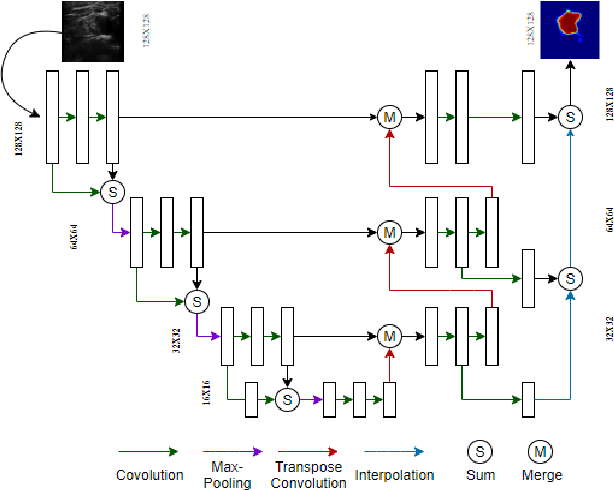
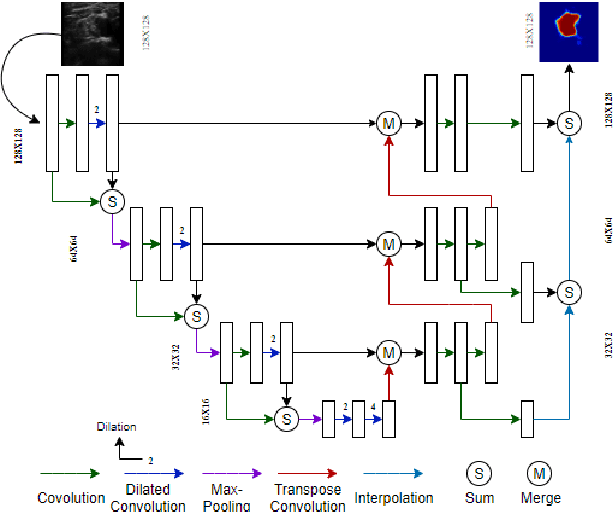

Automated object recognition in medical images can facilitate medical diagnosis and treatment. In this paper, we automatically segmented supraclavicular nerves in ultrasound images to assist in injecting peripheral nerve blocks. Nerve blocks are generally used for pain treatment after surgery, where ultrasound guidance is used to inject local anesthetics next to target nerves. This treatment blocks the transmission of pain signals to the brain, which can help improve the rate of recovery from surgery and significantly decrease the requirement for postoperative opioids. However, Ultrasound Guided Regional Anesthesia (UGRA) requires anesthesiologists to visually recognize the actual nerve position in the ultrasound images. This is a complex task given the myriad visual presentations of nerves in ultrasound images, and their visual similarity to many neighboring tissues. In this study, we used an automated nerve detection system for the UGRA Nerve Block treatment. The system can recognize the position of the nerve in ultrasound images using Deep Learning techniques. We developed a model to capture features of nerves by training two deep neural networks with skip connections: two extended U-Net architectures with and without dilated convolutions. This solution could potentially lead to an improved blockade of targeted nerves in regional anesthesia.
TAD: A Large-Scale Benchmark for Traffic Accidents Detection from Video Surveillance
Sep 26, 2022


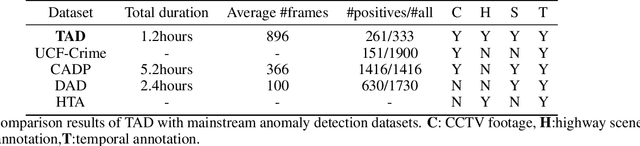
Automatic traffic accidents detection has appealed to the machine vision community due to its implications on the development of autonomous intelligent transportation systems (ITS) and importance to traffic safety. Most previous studies on efficient analysis and prediction of traffic accidents, however, have used small-scale datasets with limited coverage, which limits their effect and applicability. Existing datasets in traffic accidents are either small-scale, not from surveillance cameras, not open-sourced, or not built for freeway scenes. Since accidents happened in freeways tend to cause serious damage and are too fast to catch the spot. An open-sourced datasets targeting on freeway traffic accidents collected from surveillance cameras is in great need and of practical importance. In order to help the vision community address these shortcomings, we endeavor to collect video data of real traffic accidents that covered abundant scenes. After integration and annotation by various dimensions, a large-scale traffic accidents dataset named TAD is proposed in this work. Various experiments on image classification, object detection, and video classification tasks, using public mainstream vision algorithms or frameworks are conducted in this work to demonstrate performance of different methods. The proposed dataset together with the experimental results are presented as a new benchmark to improve computer vision research, especially in ITS.
V2HDM-Mono: A Framework of Building a Marking-Level HD Map with One or More Monocular Cameras
Sep 16, 2022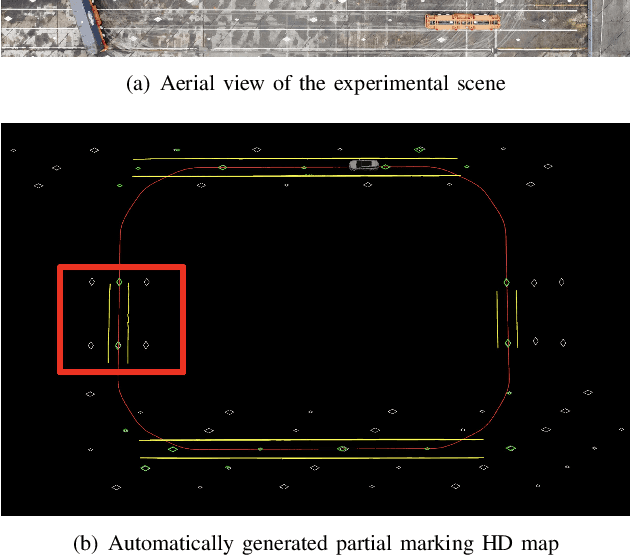
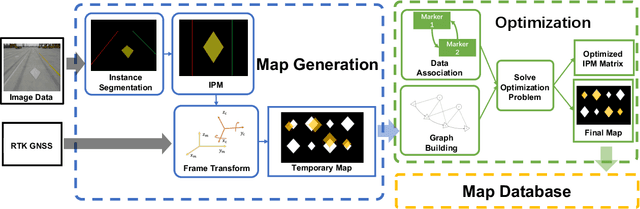

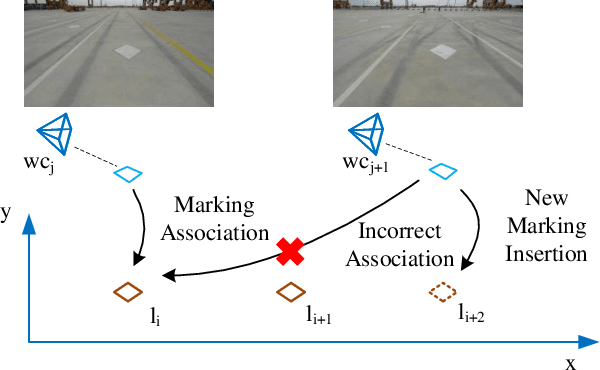
Marking-level high-definition maps (HD maps) are of great significance for autonomous vehicles, especially in large-scale, appearance-changing scenarios where autonomous vehicles rely on markings for localization and lanes for safe driving. In this paper, we propose a highly feasible framework for automatically building a marking-level HD map using a simple sensor setup (one or more monocular cameras). We optimize the position of the marking corners to fit the result of marking segmentation and simultaneously optimize the inverse perspective mapping (IPM) matrix of the corresponding camera to obtain an accurate transformation from the front view image to the bird's-eye view (BEV). In the quantitative evaluation, the built HD map almost attains centimeter-level accuracy. The accuracy of the optimized IPM matrix is similar to that of the manual calibration. The method can also be generalized to build HD maps in a broader sense by increasing the types of recognizable markings.
Forensicability Assessment of Questioned Images in Recapturing Detection
Sep 05, 2022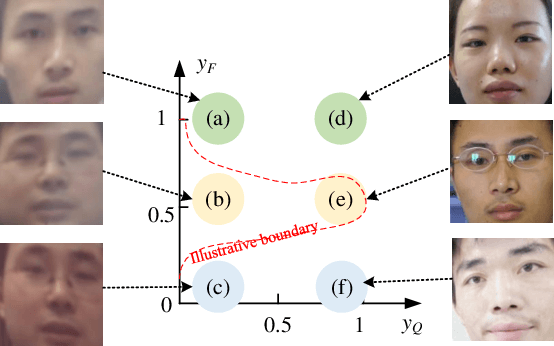

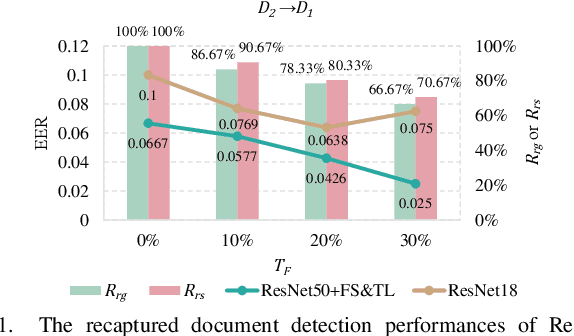
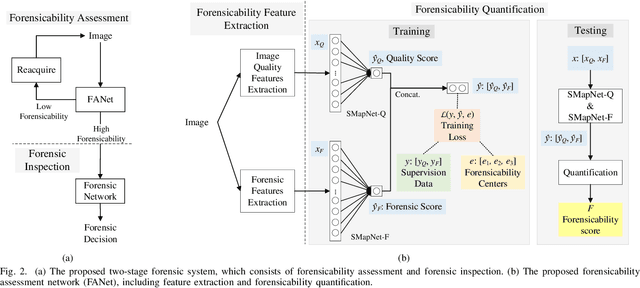
Recapture detection of face and document images is an important forensic task. With deep learning, the performances of face anti-spoofing (FAS) and recaptured document detection have been improved significantly. However, the performances are not yet satisfactory on samples with weak forensic cues. The amount of forensic cues can be quantified to allow a reliable forensic result. In this work, we propose a forensicability assessment network to quantify the forensicability of the questioned samples. The low-forensicability samples are rejected before the actual recapturing detection process to improve the efficiency of recapturing detection systems. We first extract forensicability features related to both image quality assessment and forensic tasks. By exploiting domain knowledge of the forensic application in image quality and forensic features, we define three task-specific forensicability classes and the initialized locations in the feature space. Based on the extracted features and the defined centers, we train the proposed forensic assessment network (FANet) with cross-entropy loss and update the centers with a momentum-based update method. We integrate the trained FANet with practical recapturing detection schemes in face anti-spoofing and recaptured document detection tasks. Experimental results show that, for a generic CNN-based FAS scheme, FANet reduces the EERs from 33.75% to 19.23% under ROSE to IDIAP protocol by rejecting samples with the lowest 30% forensicability scores. The performance of FAS schemes is poor in the rejected samples, with EER as high as 56.48%. Similar performances in rejecting low-forensicability samples have been observed for the state-of-the-art approaches in FAS and recaptured document detection tasks. To the best of our knowledge, this is the first work that assesses the forensicability of recaptured document images and improves the system efficiency.
Preserving Privacy in Federated Learning with Ensemble Cross-Domain Knowledge Distillation
Sep 10, 2022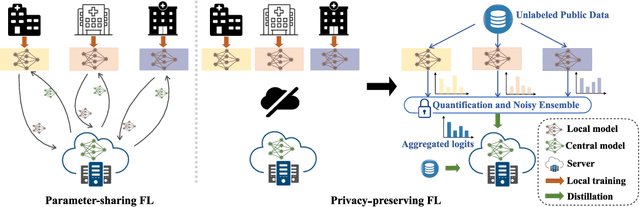
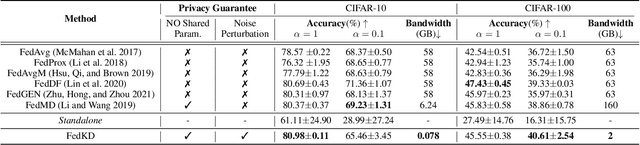
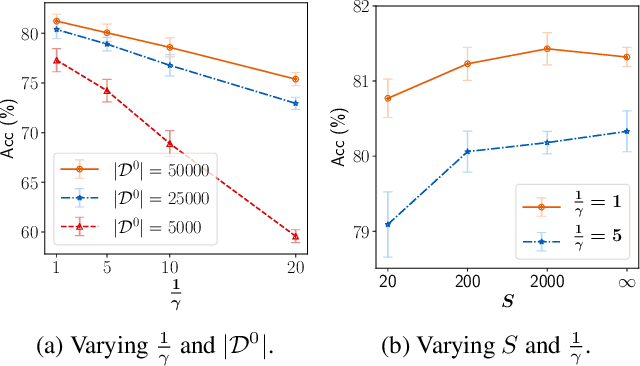
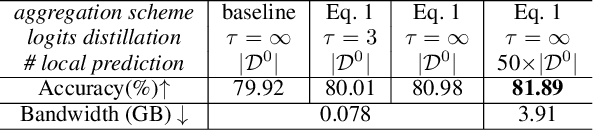
Federated Learning (FL) is a machine learning paradigm where local nodes collaboratively train a central model while the training data remains decentralized. Existing FL methods typically share model parameters or employ co-distillation to address the issue of unbalanced data distribution. However, they suffer from communication bottlenecks. More importantly, they risk privacy leakage. In this work, we develop a privacy preserving and communication efficient method in a FL framework with one-shot offline knowledge distillation using unlabeled, cross-domain public data. We propose a quantized and noisy ensemble of local predictions from completely trained local models for stronger privacy guarantees without sacrificing accuracy. Based on extensive experiments on image classification and text classification tasks, we show that our privacy-preserving method outperforms baseline FL algorithms with superior performance in both accuracy and communication efficiency.
A Secure and Efficient Multi-Object Grasping Detection Approach for Robotic Arms
Sep 08, 2022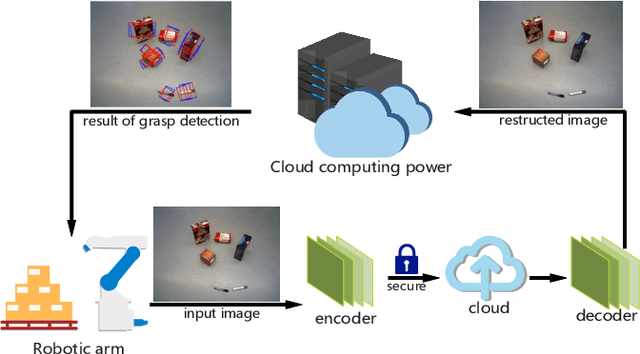



Robotic arms are widely used in automatic industries. However, with wide applications of deep learning in robotic arms, there are new challenges such as the allocation of grasping computing power and the growing demand for security. In this work, we propose a robotic arm grasping approach based on deep learning and edge-cloud collaboration. This approach realizes the arbitrary grasp planning of the robot arm and considers the grasp efficiency and information security. In addition, the encoder and decoder trained by GAN enable the images to be encrypted while compressing, which ensures the security of privacy. The model achieves 92% accuracy on the OCID dataset, the image compression ratio reaches 0.03%, and the structural difference value is higher than 0.91.
The Role Of Biology In Deep Learning
Sep 07, 2022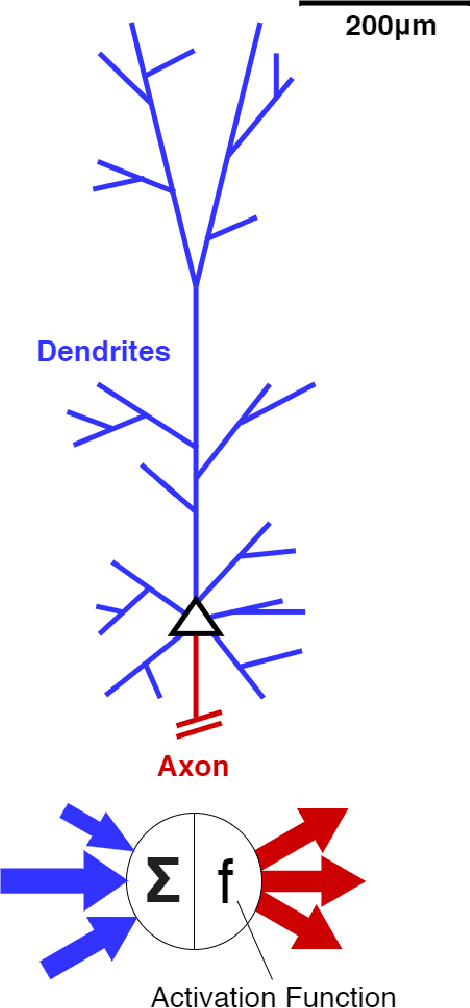
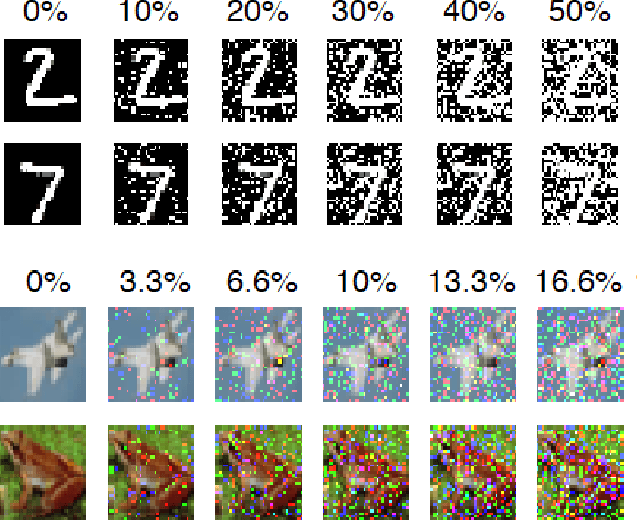
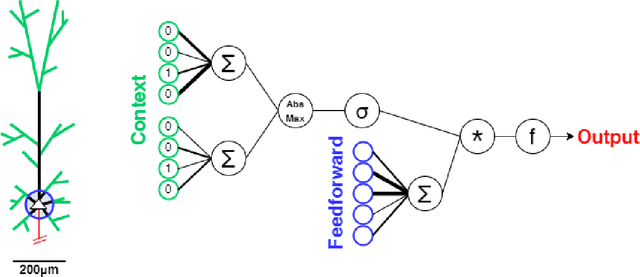
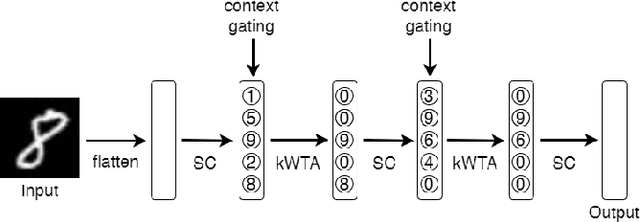
Artificial neural networks took a lot of inspiration from their biological counterparts in becoming our best machine perceptual systems. This work summarizes some of that history and incorporates modern theoretical neuroscience into experiments with artificial neural networks from the field of deep learning. Specifically, iterative magnitude pruning is used to train sparsely connected networks with 33x fewer weights without loss in performance. These are used to test and ultimately reject the hypothesis that weight sparsity alone improves image noise robustness. Recent work mitigated catastrophic forgetting using weight sparsity, activation sparsity, and active dendrite modeling. This paper replicates those findings, and extends the method to train convolutional neural networks on a more challenging continual learning task. The code has been made publicly available.
Fairness Testing of Deep Image Classification with Adequacy Metrics
Dec 01, 2021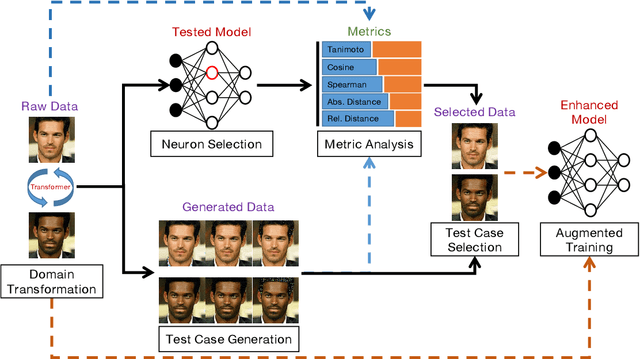

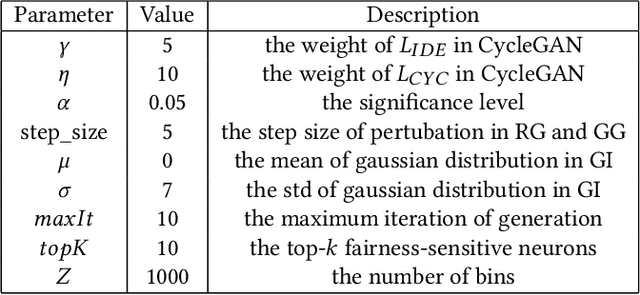
As deep image classification applications, e.g., face recognition, become increasingly prevalent in our daily lives, their fairness issues raise more and more concern. It is thus crucial to comprehensively test the fairness of these applications before deployment. Existing fairness testing methods suffer from the following limitations: 1) applicability, i.e., they are only applicable for structured data or text without handling the high-dimensional and abstract domain sampling in the semantic level for image classification applications; 2) functionality, i.e., they generate unfair samples without providing testing criterion to characterize the model's fairness adequacy. To fill the gap, we propose DeepFAIT, a systematic fairness testing framework specifically designed for deep image classification applications. DeepFAIT consists of several important components enabling effective fairness testing of deep image classification applications: 1) a neuron selection strategy to identify the fairness-related neurons; 2) a set of multi-granularity adequacy metrics to evaluate the model's fairness; 3) a test selection algorithm for fixing the fairness issues efficiently. We have conducted experiments on widely adopted large-scale face recognition applications, i.e., VGGFace and FairFace. The experimental results confirm that our approach can effectively identify the fairness-related neurons, characterize the model's fairness, and select the most valuable test cases to mitigate the model's fairness issues.