 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Sample-Then-Optimize Batch Neural Thompson Sampling
Oct 13, 2022
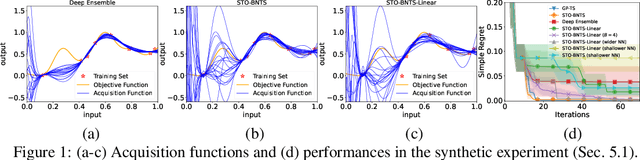
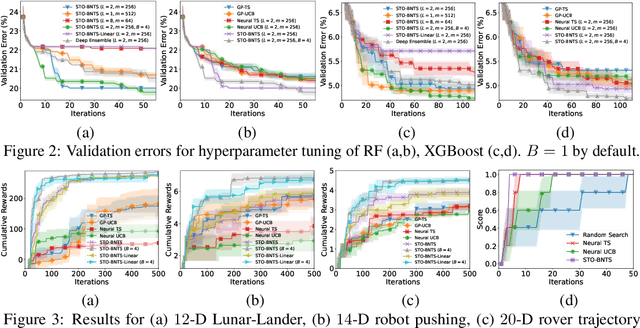
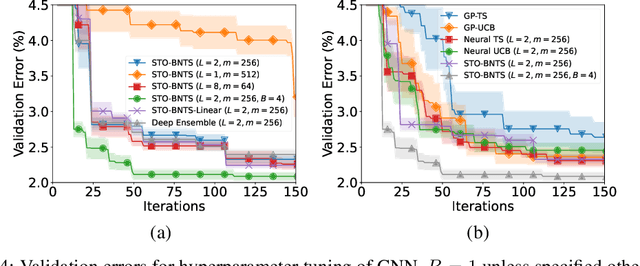
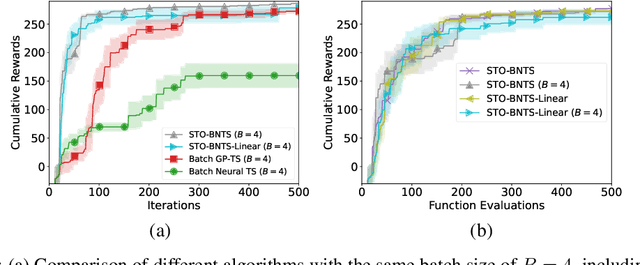
Bayesian optimization (BO), which uses a Gaussian process (GP) as a surrogate to model its objective function, is popular for black-box optimization. However, due to the limitations of GPs, BO underperforms in some problems such as those with categorical, high-dimensional or image inputs. To this end, recent works have used the highly expressive neural networks (NNs) as the surrogate model and derived theoretical guarantees using the theory of neural tangent kernel (NTK). However, these works suffer from the limitations of the requirement to invert an extremely large parameter matrix and the restriction to the sequential (rather than batch) setting. To overcome these limitations, we introduce two algorithms based on the Thompson sampling (TS) policy named Sample-Then-Optimize Batch Neural TS (STO-BNTS) and STO-BNTS-Linear. To choose an input query, we only need to train an NN (resp. a linear model) and then choose the query by maximizing the trained NN (resp. linear model), which is equivalently sampled from the GP posterior with the NTK as the kernel function. As a result, our algorithms sidestep the need to invert the large parameter matrix yet still preserve the validity of the TS policy. Next, we derive regret upper bounds for our algorithms with batch evaluations, and use insights from batch BO and NTK to show that they are asymptotically no-regret under certain conditions. Finally, we verify their empirical effectiveness using practical AutoML and reinforcement learning experiments.
Net2Brain: A Toolbox to compare artificial vision models with human brain responses
Aug 25, 2022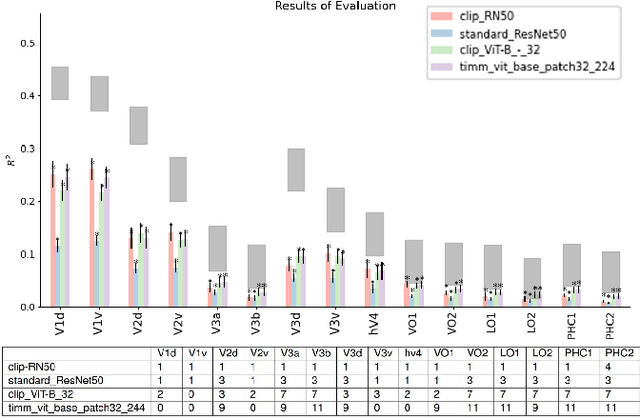
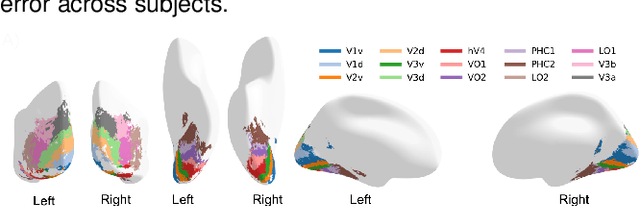
We introduce Net2Brain, a graphical and command-line user interface toolbox for comparing the representational spaces of artificial deep neural networks (DNNs) and human brain recordings. While different toolboxes facilitate only single functionalities or only focus on a small subset of supervised image classification models, Net2Brain allows the extraction of activations of more than 600 DNNs trained to perform a diverse range of vision-related tasks (e.g semantic segmentation, depth estimation, action recognition, etc.), over both image and video datasets. The toolbox computes the representational dissimilarity matrices (RDMs) over those activations and compares them to brain recordings using representational similarity analysis (RSA), weighted RSA, both in specific ROIs and with searchlight search. In addition, it is possible to add a new data set of stimuli and brain recordings to the toolbox for evaluation. We demonstrate the functionality and advantages of Net2Brain with an example showcasing how it can be used to test hypotheses of cognitive computational neuroscience.
A Survey on Deep learning based Document Image Enhancement
Dec 06, 2021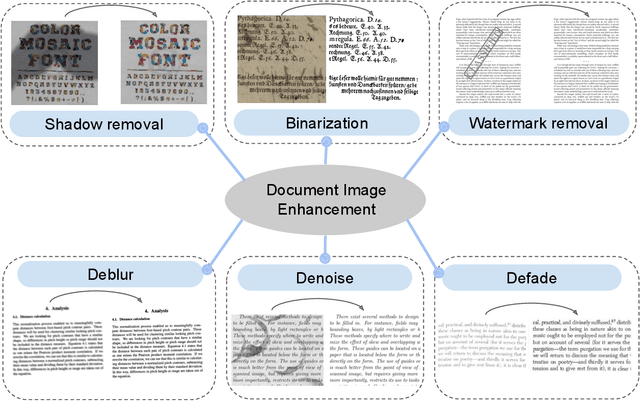
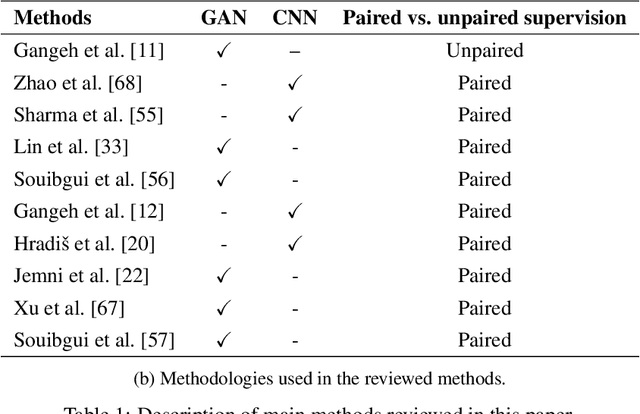


Digitized documents such as scientific articles, tax forms, invoices, contract papers, and historic texts, are widely used nowadays. These images could be degraded or damaged due to various reasons including poor lighting conditions when capturing the image, shadow while scanning them, distortion like noise and blur, aging, ink stain, bleed through, watermark, stamp, etc. Document image enhancement and restoration play a crucial role in many automated document analysis and recognition tasks, such as content extraction using optical character recognition (OCR). With recent advances in deep learning, many methods are proposed to enhance the quality of these document images. In this paper, we review deep learning-based methods, datasets, and metrics for different document image enhancement problems. We provide a comprehensive overview of deep learning-based methods for six different document image enhancement tasks, including binarization, debluring, denoising, defading, watermark removal, and shadow removal. We summarize the main state-of-the-art works for each task and discuss their features, challenges, and limitations. We introduce multiple document image enhancement tasks that have received no to little attention, including over and under exposure correction and bleed-through removal, and identify several other promising research directions and opportunities for future research.
UAS Navigation in the Real World Using Visual Observation
Aug 25, 2022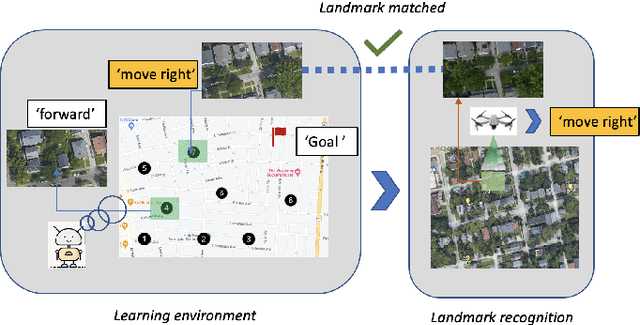
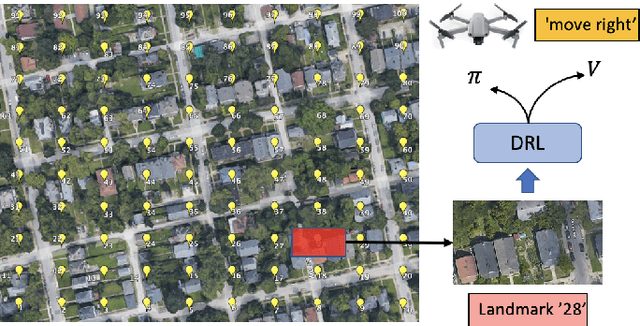

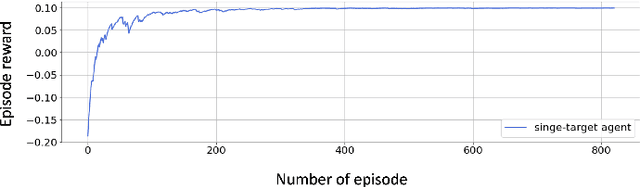
This paper presents a novel end-to-end Unmanned Aerial System (UAS) navigation approach for long-range visual navigation in the real world. Inspired by dual-process visual navigation system of human's instinct: environment understanding and landmark recognition, we formulate the UAS navigation task into two same phases. Our system combines the reinforcement learning (RL) and image matching approaches. First, the agent learns the navigation policy using RL in the specified environment. To achieve this, we design an interactive UASNAV environment for the training process. Once the agent learns the navigation policy, which means 'familiarized themselves with the environment', we let the UAS fly in the real world to recognize the landmarks using image matching method and take action according to the learned policy. During the navigation process, the UAS is embedded with single camera as the only visual sensor. We demonstrate that the UAS can learn navigating to the destination hundreds meters away from the starting point with the shortest path in the real world scenario.
Scaling Up Vision-Language Pre-training for Image Captioning
Nov 24, 2021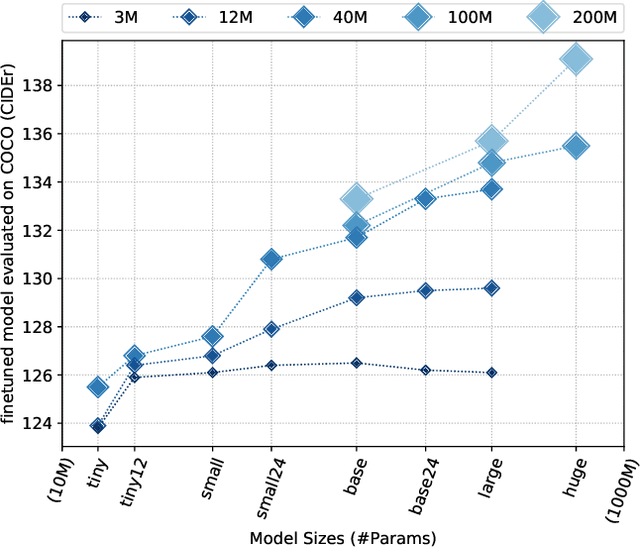

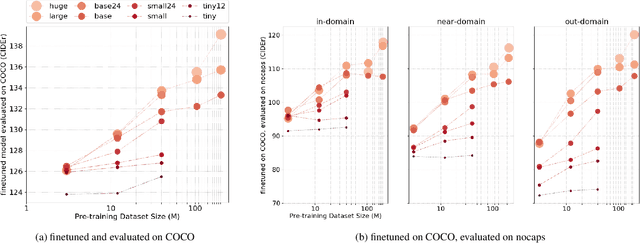
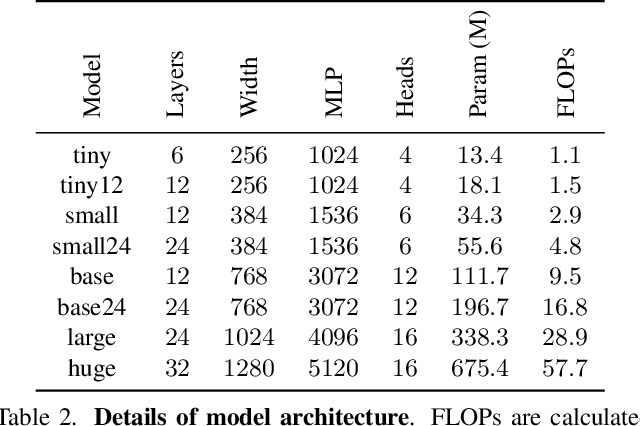
In recent years, we have witnessed significant performance boost in the image captioning task based on vision-language pre-training (VLP). Scale is believed to be an important factor for this advance. However, most existing work only focuses on pre-training transformers with moderate sizes (e.g., 12 or 24 layers) on roughly 4 million images. In this paper, we present LEMON, a LargE-scale iMage captiONer, and provide the first empirical study on the scaling behavior of VLP for image captioning. We use the state-of-the-art VinVL model as our reference model, which consists of an image feature extractor and a transformer model, and scale the transformer both up and down, with model sizes ranging from 13 to 675 million parameters. In terms of data, we conduct experiments with up to 200 million image-text pairs which are automatically collected from web based on the alt attribute of the image (dubbed as ALT200M). Extensive analysis helps to characterize the performance trend as the model size and the pre-training data size increase. We also compare different training recipes, especially for training on large-scale noisy data. As a result, LEMON achieves new state of the arts on several major image captioning benchmarks, including COCO Caption, nocaps, and Conceptual Captions. We also show LEMON can generate captions with long-tail visual concepts when used in a zero-shot manner.
DiRA: Discriminative, Restorative, and Adversarial Learning for Self-supervised Medical Image Analysis
Apr 21, 2022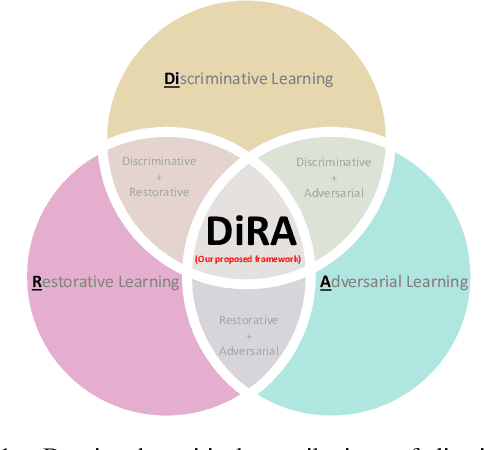

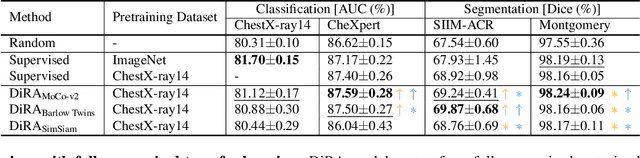
Discriminative learning, restorative learning, and adversarial learning have proven beneficial for self-supervised learning schemes in computer vision and medical imaging. Existing efforts, however, omit their synergistic effects on each other in a ternary setup, which, we envision, can significantly benefit deep semantic representation learning. To realize this vision, we have developed DiRA, the first framework that unites discriminative, restorative, and adversarial learning in a unified manner to collaboratively glean complementary visual information from unlabeled medical images for fine-grained semantic representation learning. Our extensive experiments demonstrate that DiRA (1) encourages collaborative learning among three learning ingredients, resulting in more generalizable representation across organs, diseases, and modalities; (2) outperforms fully supervised ImageNet models and increases robustness in small data regimes, reducing annotation cost across multiple medical imaging applications; (3) learns fine-grained semantic representation, facilitating accurate lesion localization with only image-level annotation; and (4) enhances state-of-the-art restorative approaches, revealing that DiRA is a general mechanism for united representation learning. All code and pre-trained models are available at https: //github.com/JLiangLab/DiRA.
Neural Image Beauty Predictor Based on Bradley-Terry Model
Nov 19, 2021
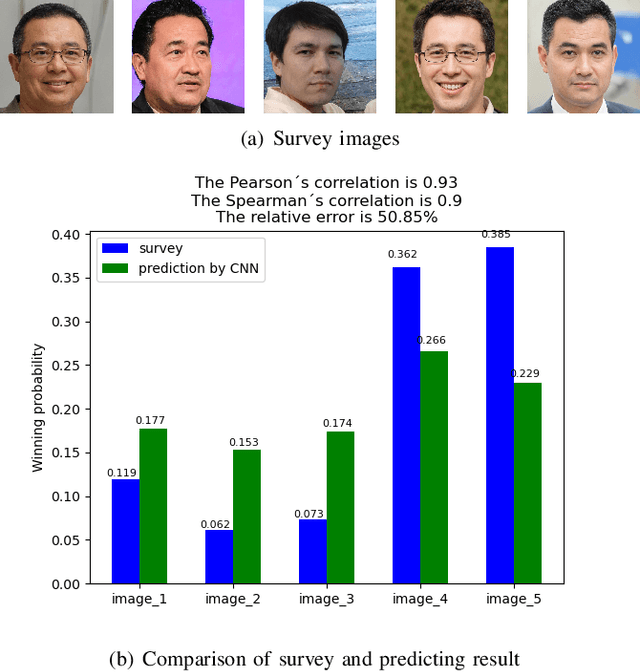
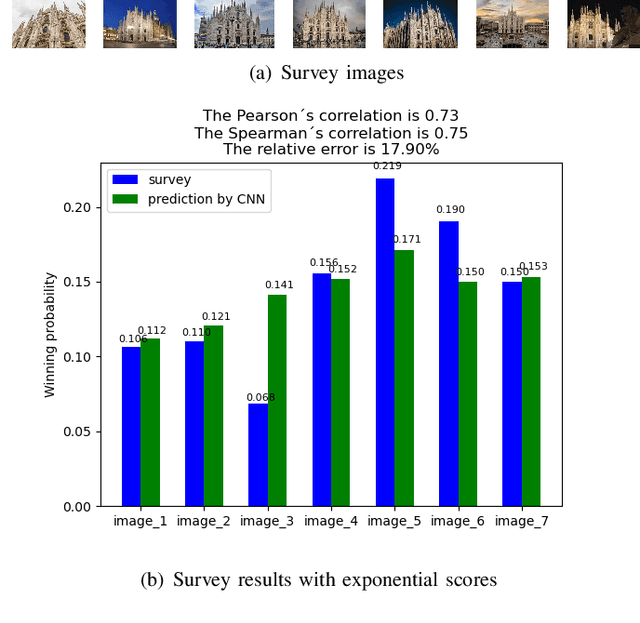
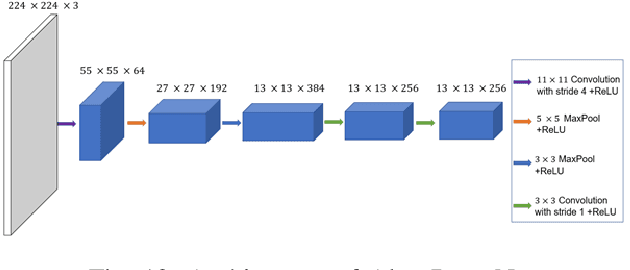
Image beauty assessment is an important subject of computer vision. Therefore, building a model to mimic the image beauty assessment becomes an important task. To better imitate the behaviours of the human visual system (HVS), a complete survey about images of different categories should be implemented. This work focuses on image beauty assessment. In this study, the pairwise evaluation method was used, which is based on the Bradley-Terry model. We believe that this method is more accurate than other image rating methods within an image group. Additionally, Convolution neural network (CNN), which is fit for image quality assessment, is used in this work. The first part of this study is a survey about the image beauty comparison of different images. The Bradley-Terry model is used for the calculated scores, which are the target of CNN model. The second part of this work focuses on the results of the image beauty prediction, including landscape images, architecture images and portrait images. The models are pretrained by the AVA dataset to improve the performance later. Then, the CNN model is trained with the surveyed images and corresponding scores. Furthermore, this work compares the results of four CNN base networks, i.e., Alex net, VGG net, Squeeze net and LSiM net, as discussed in literature. In the end, the model is evaluated by the accuracy in pairs, correlation coefficient and relative error calculated by survey results. Satisfactory results are achieved by our proposed methods with about 70 percent accuracy in pairs. Our work sheds more light on the novel image beauty assessment method. While more studies should be conducted, this method is a promising step.
Image Superresolution using Scale-Recurrent Dense Network
Jan 28, 2022


Recent advances in the design of convolutional neural network (CNN) have yielded significant improvements in the performance of image super-resolution (SR). The boost in performance can be attributed to the presence of residual or dense connections within the intermediate layers of these networks. The efficient combination of such connections can reduce the number of parameters drastically while maintaining the restoration quality. In this paper, we propose a scale recurrent SR architecture built upon units containing series of dense connections within a residual block (Residual Dense Blocks (RDBs)) that allow extraction of abundant local features from the image. Our scale recurrent design delivers competitive performance for higher scale factors while being parametrically more efficient as compared to current state-of-the-art approaches. To further improve the performance of our network, we employ multiple residual connections in intermediate layers (referred to as Multi-Residual Dense Blocks), which improves gradient propagation in existing layers. Recent works have discovered that conventional loss functions can guide a network to produce results which have high PSNRs but are perceptually inferior. We mitigate this issue by utilizing a Generative Adversarial Network (GAN) based framework and deep feature (VGG) losses to train our network. We experimentally demonstrate that different weighted combinations of the VGG loss and the adversarial loss enable our network outputs to traverse along the perception-distortion curve. The proposed networks perform favorably against existing methods, both perceptually and objectively (PSNR-based) with fewer parameters.
Semi-supervised Medical Image Segmentation via Geometry-aware Consistency Training
Feb 12, 2022
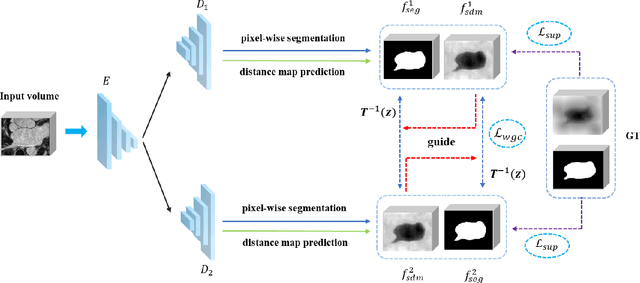
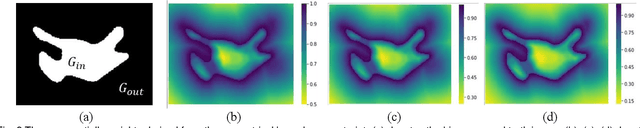
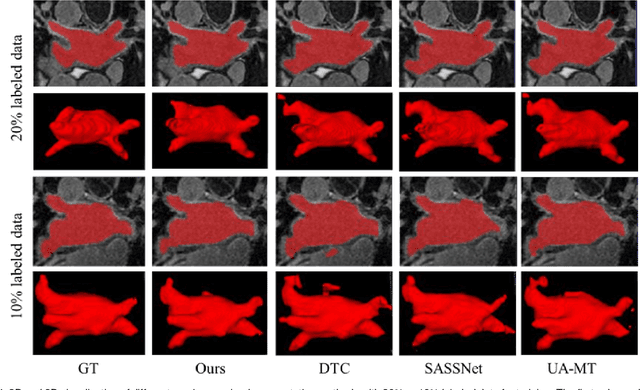
The performance of supervised deep learning methods for medical image segmentation is often limited by the scarcity of labeled data. As a promising research direction, semi-supervised learning addresses this dilemma by leveraging unlabeled data information to assist the learning process. In this paper, a novel geometry-aware semi-supervised learning framework is proposed for medical image segmentation, which is a consistency-based method. Considering that the hard-to-segment regions are mainly located around the object boundary, we introduce an auxiliary prediction task to learn the global geometric information. Based on the geometric constraint, the ambiguous boundary regions are emphasized through an exponentially weighted strategy for the model training to better exploit both labeled and unlabeled data. In addition, a dual-view network is designed to perform segmentation from different perspectives and reduce the prediction uncertainty. The proposed method is evaluated on the public left atrium benchmark dataset and improves fully supervised method by 8.7% in Dice with 10% labeled images, while 4.3% with 20% labeled images. Meanwhile, our framework outperforms six state-of-the-art semi-supervised segmentation methods.
Aplicación de redes neuronales convolucionales profundas al diagnóstico asistido de la enfermedad de Alzheimer
Oct 15, 2022Currently, the diagnosis of Alzheimer's disease is a complex and error-prone process. Improving this diagnosis could allow earlier detection of the disease and improve the quality of life of patients and their families. For this work, we will use 249 brain images from two modalities: PET and MRI, taken from the ADNI database, and labelled into three classes according to the degree of development of Alzheimer's disease. We propose the development of a convolutional neural network to perform the classification of these images, during which, we will study the appropriate depth of the networks for this problem, the importance of pre-processing medical images, the use of transfer learning and data augmentation techniques as tools to reduce the effects of the problem of having too little data, and the simultaneous use of multiple medical imaging modalities. We also propose the application of an evaluation method that guarantees a good degree of repeatability of the results even when using a small dataset. Following this evaluation method, our best final model, which makes use of transfer learning with COVID-19 data, achieves an accuracy d 68\%. In addition, in an independent test set, this same model achieves 70\% accuracy, a promising result given the small size of our dataset. We further conclude that augmenting the depth of the networks helps with this problem, that image pre-processing is a fundamental process to address this type of medical problem, and that the use of data augmentation and the use of pre-trained networks with images of other diseases can provide significant improvements.