 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Compressive Ptychography using Deep Image and Generative Priors
May 05, 2022
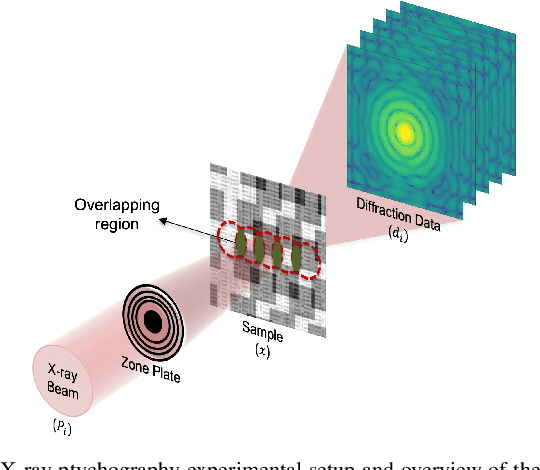


Ptychography is a well-established coherent diffraction imaging technique that enables non-invasive imaging of samples at a nanometer scale. It has been extensively used in various areas such as the defense industry or materials science. One major limitation of ptychography is the long data acquisition time due to mechanical scanning of the sample; therefore, approaches to reduce the scan points are highly desired. However, reconstructions with less number of scan points lead to imaging artifacts and significant distortions, hindering a quantitative evaluation of the results. To address this bottleneck, we propose a generative model combining deep image priors with deep generative priors. The self-training approach optimizes the deep generative neural network to create a solution for a given dataset. We complement our approach with a prior acquired from a previously trained discriminator network to avoid a possible divergence from the desired output caused by the noise in the measurements. We also suggest using the total variation as a complementary before combat artifacts due to measurement noise. We analyze our approach with numerical experiments through different probe overlap percentages and varying noise levels. We also demonstrate improved reconstruction accuracy compared to the state-of-the-art method and discuss the advantages and disadvantages of our approach.
A Visual Tour Of Current Challenges In Multimodal Language Models
Oct 22, 2022



Transformer models trained on massive text corpora have become the de facto models for a wide range of natural language processing tasks. However, learning effective word representations for function words remains challenging. Multimodal learning, which visually grounds transformer models in imagery, can overcome the challenges to some extent; however, there is still much work to be done. In this study, we explore the extent to which visual grounding facilitates the acquisition of function words using stable diffusion models that employ multimodal models for text-to-image generation. Out of seven categories of function words, along with numerous subcategories, we find that stable diffusion models effectively model only a small fraction of function words -- a few pronoun subcategories and relatives. We hope that our findings will stimulate the development of new datasets and approaches that enable multimodal models to learn better representations of function words.
Improving Robustness with Image Filtering
Dec 21, 2021
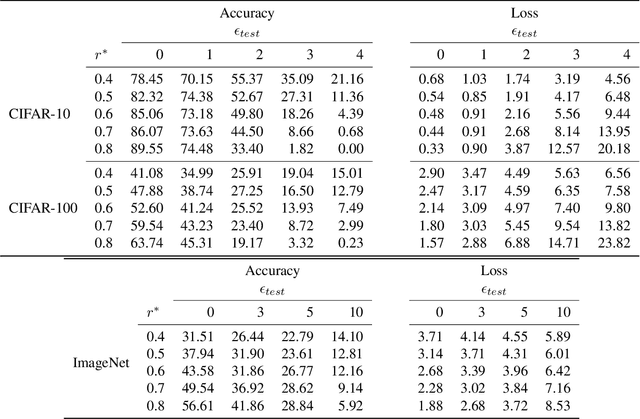
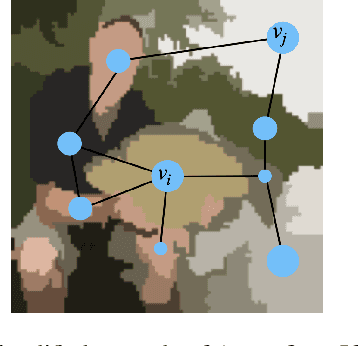
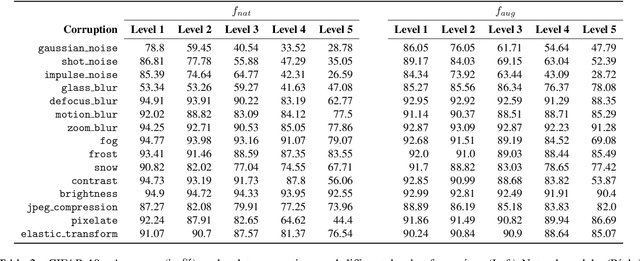
Adversarial robustness is one of the most challenging problems in Deep Learning and Computer Vision research. All the state-of-the-art techniques require a time-consuming procedure that creates cleverly perturbed images. Due to its cost, many solutions have been proposed to avoid Adversarial Training. However, all these attempts proved ineffective as the attacker manages to exploit spurious correlations among pixels to trigger brittle features implicitly learned by the model. This paper first introduces a new image filtering scheme called Image-Graph Extractor (IGE) that extracts the fundamental nodes of an image and their connections through a graph structure. By leveraging the IGE representation, we build a new defense method, Filtering As a Defense, that does not allow the attacker to entangle pixels to create malicious patterns. Moreover, we show that data augmentation with filtered images effectively improves the model's robustness to data corruption. We validate our techniques on CIFAR-10, CIFAR-100, and ImageNet.
Monogenic Wavelet Scattering Network for Texture Image Classification
Feb 25, 2022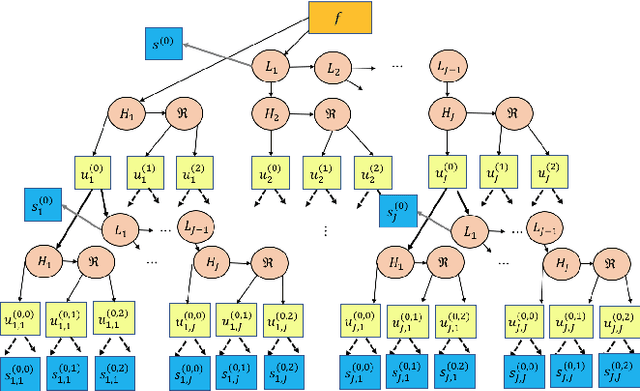
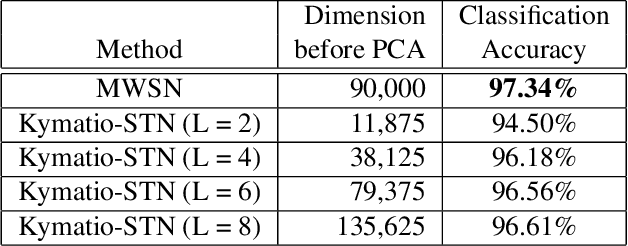


The scattering transform network (STN), which has a similar structure as that of a popular convolutional neural network except its use of predefined convolution filters and a small number of layers, can generates a robust representation of an input signal relative to small deformations. We propose a novel Monogenic Wavelet Scattering Network (MWSN) for 2D texture image classification through a cascade of monogenic wavelet filtering with nonlinear modulus and averaging operators by replacing the 2D Morlet wavelet filtering in the standard STN. Our MWSN can extract useful hierarchical and directional features with interpretable coefficients, which can be further compressed by PCA and fed into a classifier. Using the CUReT texture image database, we demonstrate the superior performance of our MWSN over the standard STN. This performance improvement can be explained by the natural extension of 1D analyticity to 2D monogenicity.
Seamless Satellite-image Synthesis
Nov 05, 2021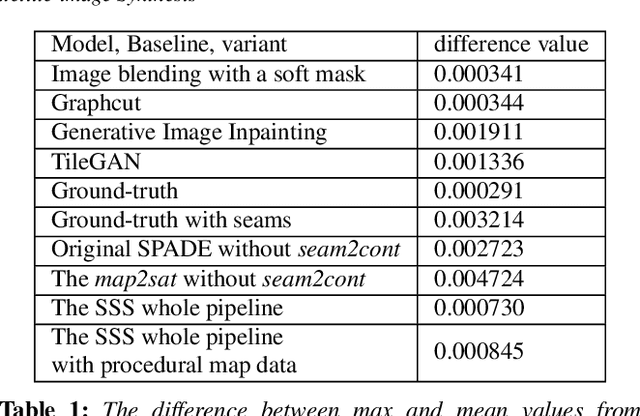
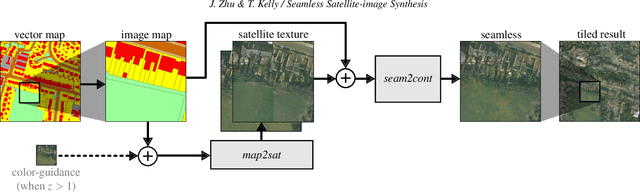
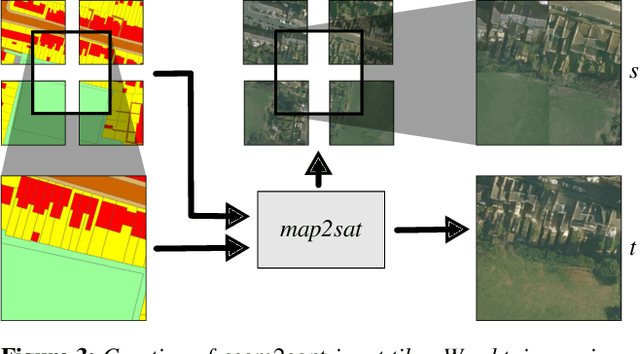

We introduce Seamless Satellite-image Synthesis (SSS), a novel neural architecture to create scale-and-space continuous satellite textures from cartographic data. While 2D map data is cheap and easily synthesized, accurate satellite imagery is expensive and often unavailable or out of date. Our approach generates seamless textures over arbitrarily large spatial extents which are consistent through scale-space. To overcome tile size limitations in image-to-image translation approaches, SSS learns to remove seams between tiled images in a semantically meaningful manner. Scale-space continuity is achieved by a hierarchy of networks conditioned on style and cartographic data. Our qualitative and quantitative evaluations show that our system improves over the state-of-the-art in several key areas. We show applications to texturing procedurally generation maps and interactive satellite image manipulation.
Boosting Multi-Label Image Classification with Complementary Parallel Self-Distillation
May 23, 2022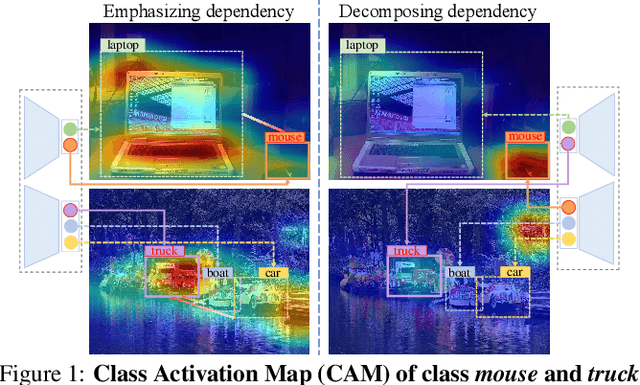
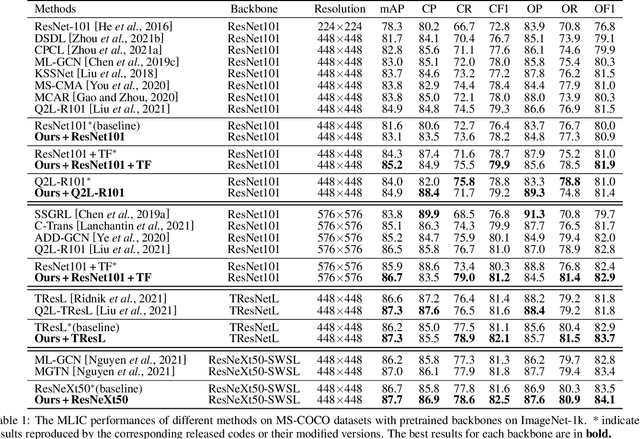
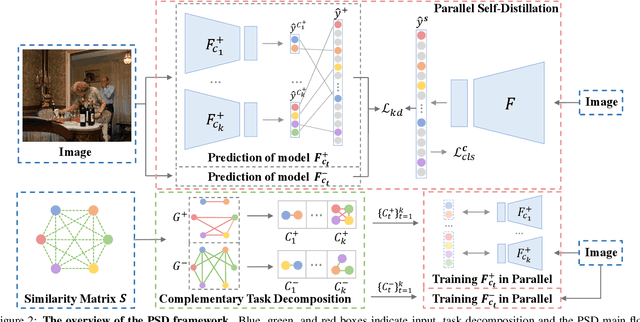
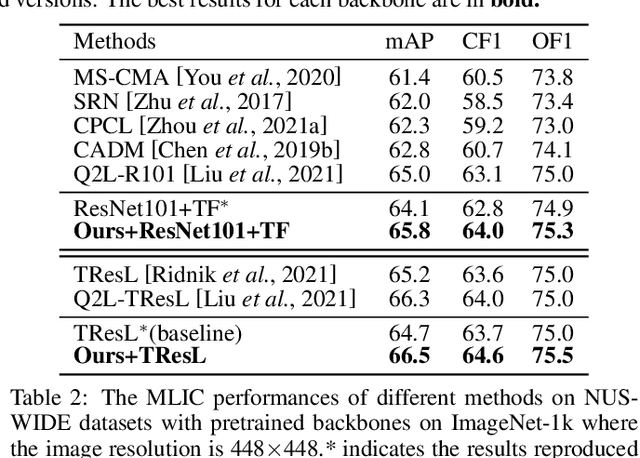
Multi-Label Image Classification (MLIC) approaches usually exploit label correlations to achieve good performance. However, emphasizing correlation like co-occurrence may overlook discriminative features of the target itself and lead to model overfitting, thus undermining the performance. In this study, we propose a generic framework named Parallel Self-Distillation (PSD) for boosting MLIC models. PSD decomposes the original MLIC task into several simpler MLIC sub-tasks via two elaborated complementary task decomposition strategies named Co-occurrence Graph Partition (CGP) and Dis-occurrence Graph Partition (DGP). Then, the MLIC models of fewer categories are trained with these sub-tasks in parallel for respectively learning the joint patterns and the category-specific patterns of labels. Finally, knowledge distillation is leveraged to learn a compact global ensemble of full categories with these learned patterns for reconciling the label correlation exploitation and model overfitting. Extensive results on MS-COCO and NUS-WIDE datasets demonstrate that our framework can be easily plugged into many MLIC approaches and improve performances of recent state-of-the-art approaches. The explainable visual study also further validates that our method is able to learn both the category-specific and co-occurring features. The source code is released at https://github.com/Robbie-Xu/CPSD.
Adversarial amplitude swap towards robust image classifiers
Apr 01, 2022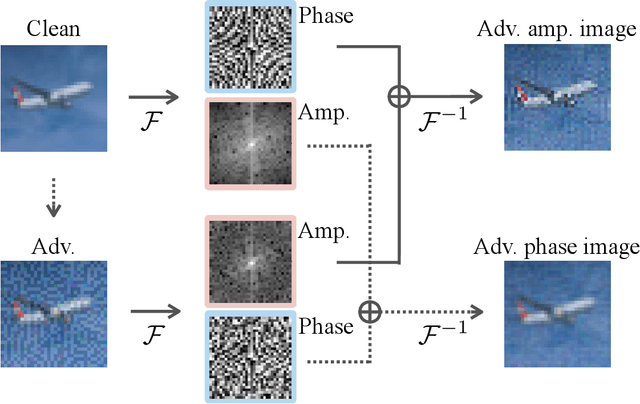
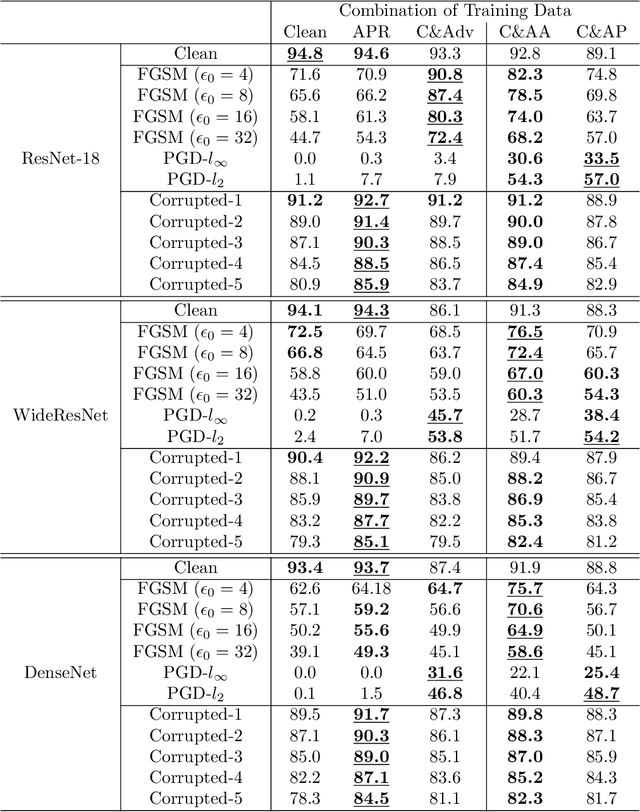
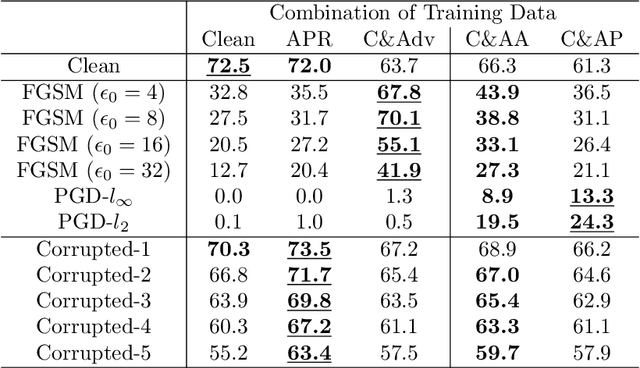
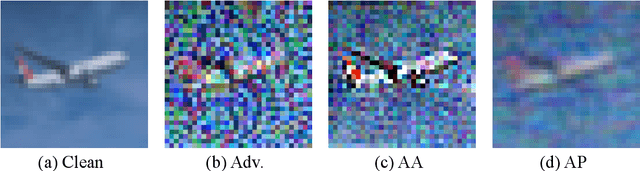
The vulnerability of convolutional neural networks (CNNs) to image perturbations such as common corruptions and adversarial perturbations has recently been investigated from the perspective of frequency. In this study, we investigate the effect of the amplitude and phase spectra of adversarial images on the robustness of CNN classifiers. Extensive experiments revealed that the images generated by combining the amplitude spectrum of adversarial images and the phase spectrum of clean images accommodates moderate and general perturbations, and training with these images equips a CNN classifier with more general robustness, performing well under both common corruptions and adversarial perturbations. We also found that two types of overfitting (catastrophic overfitting and robust overfitting) can be circumvented by the aforementioned spectrum recombination. We believe that these results contribute to the understanding and the training of truly robust classifiers.
Unsupervised Image Deraining: Optimization Model Driven Deep CNN
Mar 25, 2022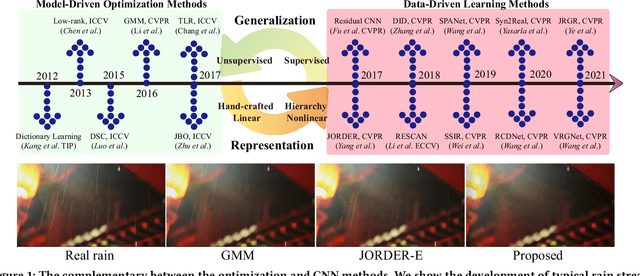

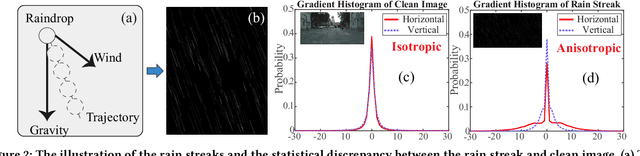
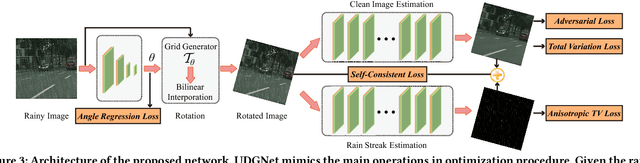
The deep convolutional neural network has achieved significant progress for single image rain streak removal. However, most of the data-driven learning methods are full-supervised or semi-supervised, unexpectedly suffering from significant performance drops when dealing with real rain. These data-driven learning methods are representative yet generalize poor for real rain. The opposite holds true for the model-driven unsupervised optimization methods. To overcome these problems, we propose a unified unsupervised learning framework which inherits the generalization and representation merits for real rain removal. Specifically, we first discover a simple yet important domain knowledge that directional rain streak is anisotropic while the natural clean image is isotropic, and formulate the structural discrepancy into the energy function of the optimization model. Consequently, we design an optimization model-driven deep CNN in which the unsupervised loss function of the optimization model is enforced on the proposed network for better generalization. In addition, the architecture of the network mimics the main role of the optimization models with better feature representation. On one hand, we take advantage of the deep network to improve the representation. On the other hand, we utilize the unsupervised loss of the optimization model for better generalization. Overall, the unsupervised learning framework achieves good generalization and representation: unsupervised training (loss) with only a few real rainy images (input) and physical meaning network (architecture). Extensive experiments on synthetic and real-world rain datasets show the superiority of the proposed method.
Image-to-image Translation as a Unique Source of Knowledge
Dec 09, 2021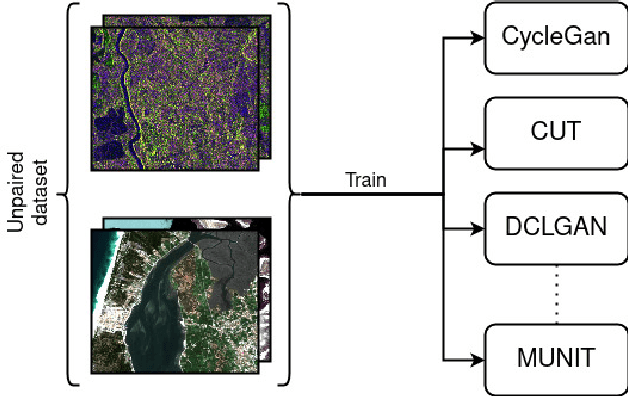
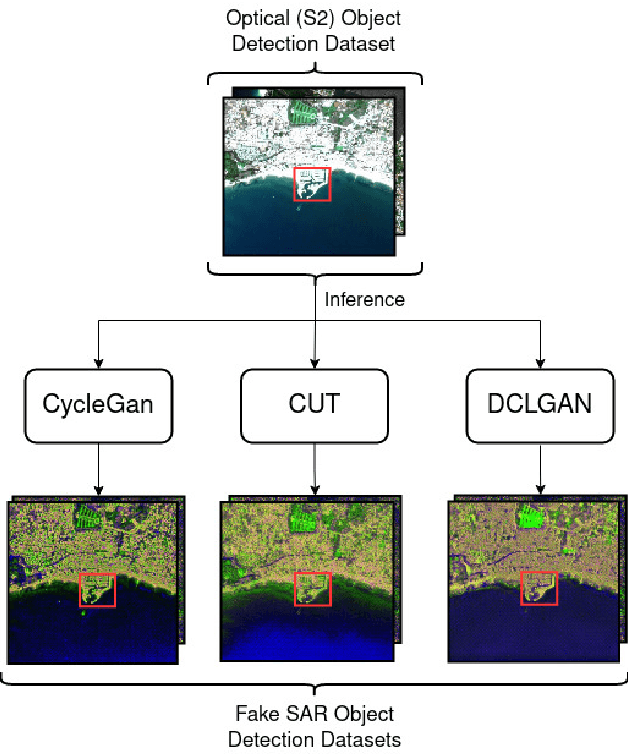
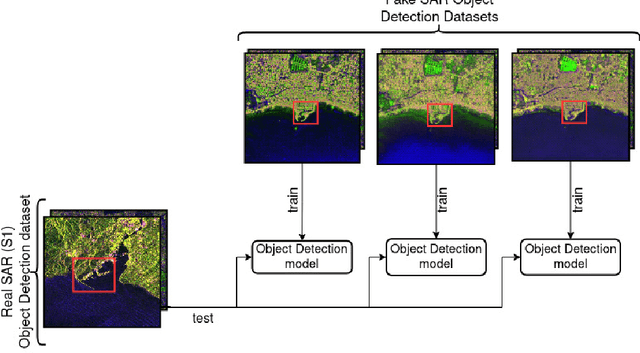
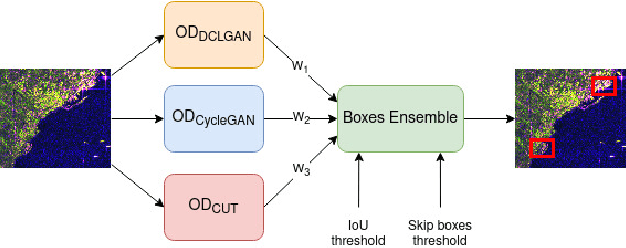
Image-to-image (I2I) translation is an established way of translating data from one domain to another but the usability of the translated images in the target domain when working with such dissimilar domains as the SAR/optical satellite imagery ones and how much of the origin domain is translated to the target domain is still not clear enough. This article address this by performing translations of labelled datasets from the optical domain to the SAR domain with different I2I algorithms from the state-of-the-art, learning from transferred features in the destination domain and evaluating later how much from the original dataset was transferred. Added to this, stacking is proposed as a way of combining the knowledge learned from the different I2I translations and evaluated against single models.
MAXIM: Multi-Axis MLP for Image Processing
Jan 09, 2022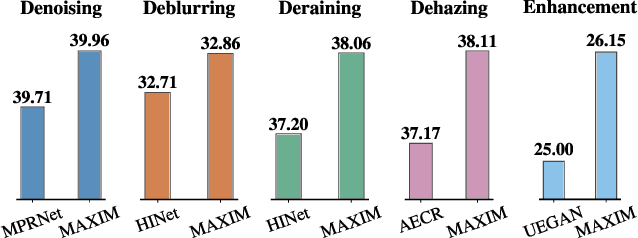
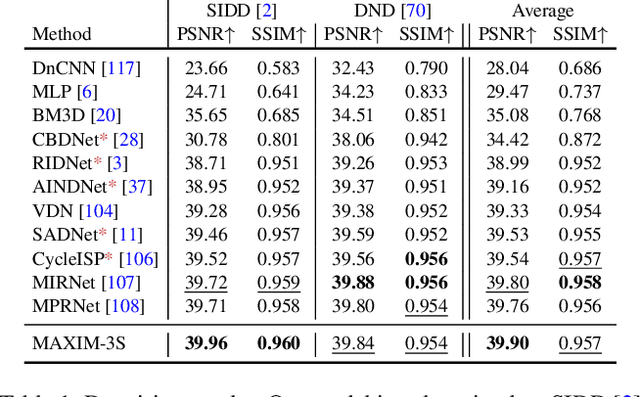
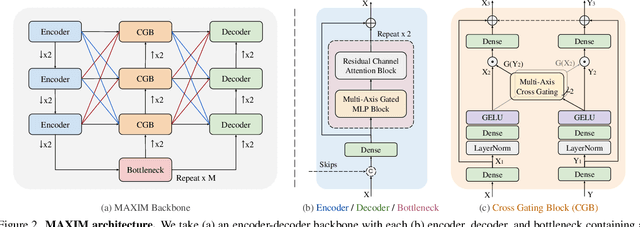
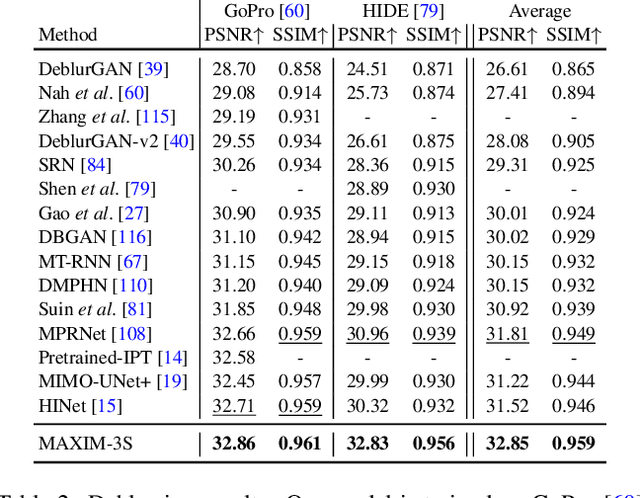
Recent progress on Transformers and multi-layer perceptron (MLP) models provide new network architectural designs for computer vision tasks. Although these models proved to be effective in many vision tasks such as image recognition, there remain challenges in adapting them for low-level vision. The inflexibility to support high-resolution images and limitations of local attention are perhaps the main bottlenecks for using Transformers and MLPs in image restoration. In this work we present a multi-axis MLP based architecture, called MAXIM, that can serve as an efficient and flexible general-purpose vision backbone for image processing tasks. MAXIM uses a UNet-shaped hierarchical structure and supports long-range interactions enabled by spatially-gated MLPs. Specifically, MAXIM contains two MLP-based building blocks: a multi-axis gated MLP that allows for efficient and scalable spatial mixing of local and global visual cues, and a cross-gating block, an alternative to cross-attention, which accounts for cross-feature mutual conditioning. Both these modules are exclusively based on MLPs, but also benefit from being both global and `fully-convolutional', two properties that are desirable for image processing. Our extensive experimental results show that the proposed MAXIM model achieves state-of-the-art performance on more than ten benchmarks across a range of image processing tasks, including denoising, deblurring, deraining, dehazing, and enhancement while requiring fewer or comparable numbers of parameters and FLOPs than competitive models.