 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dr.3D: Adapting 3D GANs to Artistic Drawings
Nov 30, 2022
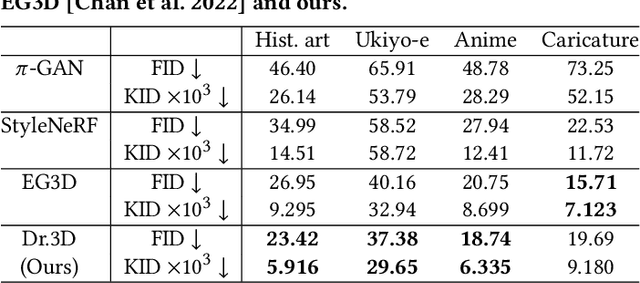
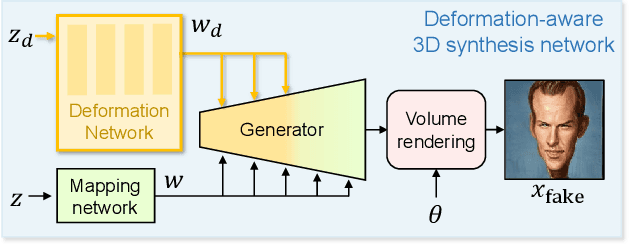
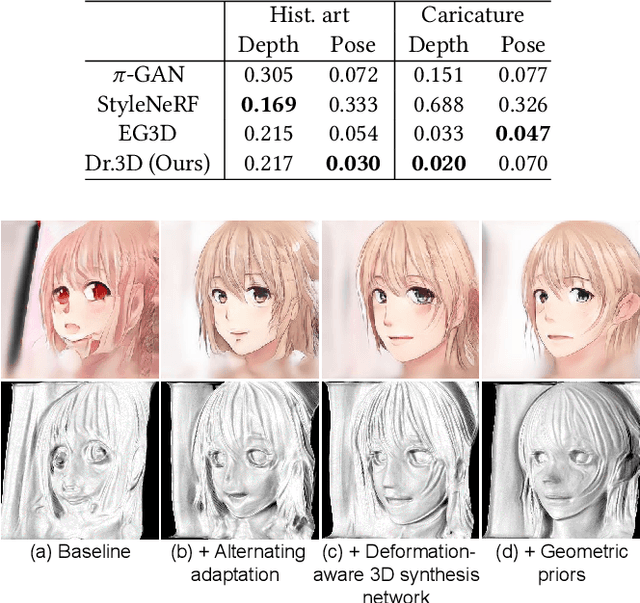
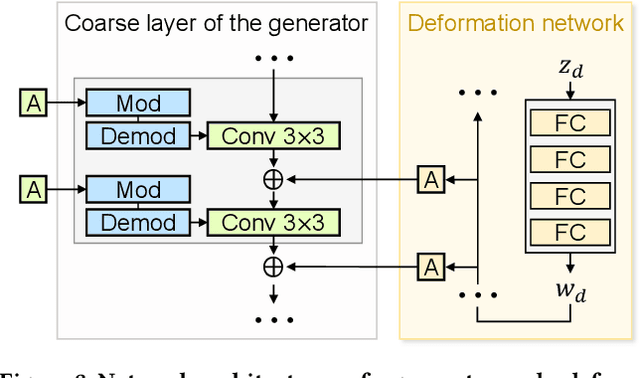
While 3D GANs have recently demonstrated the high-quality synthesis of multi-view consistent images and 3D shapes, they are mainly restricted to photo-realistic human portraits. This paper aims to extend 3D GANs to a different, but meaningful visual form: artistic portrait drawings. However, extending existing 3D GANs to drawings is challenging due to the inevitable geometric ambiguity present in drawings. To tackle this, we present Dr.3D, a novel adaptation approach that adapts an existing 3D GAN to artistic drawings. Dr.3D is equipped with three novel components to handle the geometric ambiguity: a deformation-aware 3D synthesis network, an alternating adaptation of pose estimation and image synthesis, and geometric priors. Experiments show that our approach can successfully adapt 3D GANs to drawings and enable multi-view consistent semantic editing of drawings.
Frequency selective extrapolation with residual filtering for image error concealment
May 16, 2022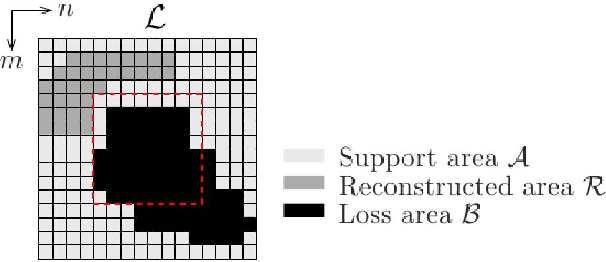
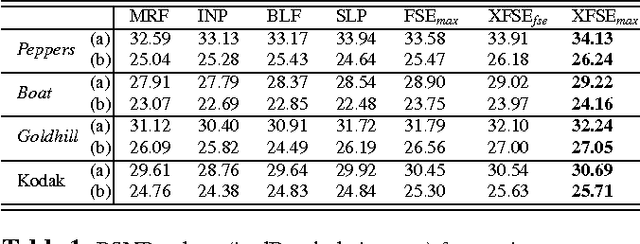
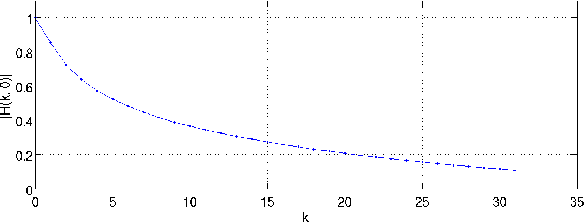
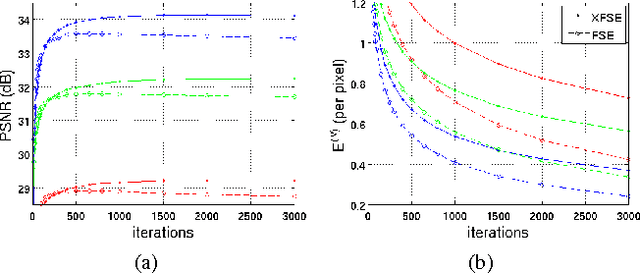
The purpose of signal extrapolation is to estimate unknown signal parts from known samples. This task is especially important for error concealment in image and video communication. For obtaining a high quality reconstruction, assumptions have to be made about the underlying signal in order to solve this underdetermined problem. Among existent reconstruction algorithms, frequency selective extrapolation (FSE) achieves high performance by assuming that image signals can be sparsely represented in the frequency domain. However, FSE does not take into account the low-pass behaviour of natural images. In this paper, we propose a modified FSE that takes this prior knowledge into account for the modelling, yielding significant PSNR gains.
Fully and Weakly Supervised Referring Expression Segmentation with End-to-End Learning
Dec 17, 2022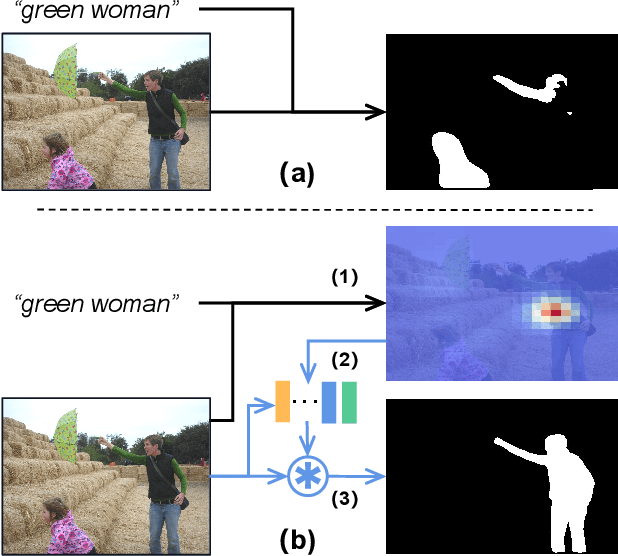

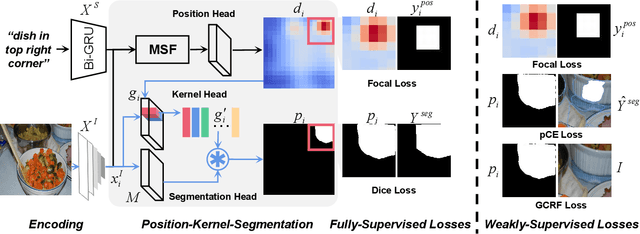
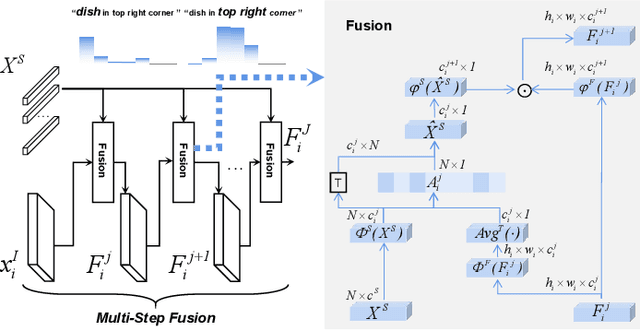
Referring Expression Segmentation (RES), which is aimed at localizing and segmenting the target according to the given language expression, has drawn increasing attention. Existing methods jointly consider the localization and segmentation steps, which rely on the fused visual and linguistic features for both steps. We argue that the conflict between the purpose of identifying an object and generating a mask limits the RES performance. To solve this problem, we propose a parallel position-kernel-segmentation pipeline to better isolate and then interact the localization and segmentation steps. In our pipeline, linguistic information will not directly contaminate the visual feature for segmentation. Specifically, the localization step localizes the target object in the image based on the referring expression, and then the visual kernel obtained from the localization step guides the segmentation step. This pipeline also enables us to train RES in a weakly-supervised way, where the pixel-level segmentation labels are replaced by click annotations on center and corner points. The position head is fully-supervised and trained with the click annotations as supervision, and the segmentation head is trained with weakly-supervised segmentation losses. To validate our framework on a weakly-supervised setting, we annotated three RES benchmark datasets (RefCOCO, RefCOCO+ and RefCOCOg) with click annotations.Our method is simple but surprisingly effective, outperforming all previous state-of-the-art RES methods on fully- and weakly-supervised settings by a large margin. The benchmark code and datasets will be released.
Self-distillation Augmented Masked Autoencoders for Histopathological Image Classification
Mar 31, 2022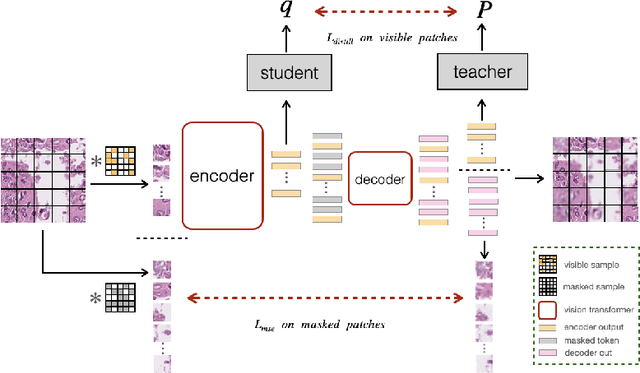
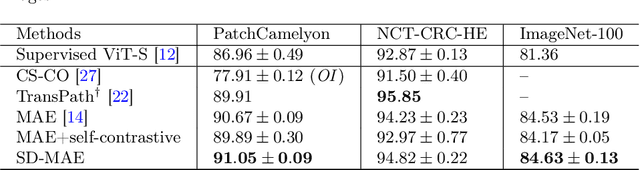
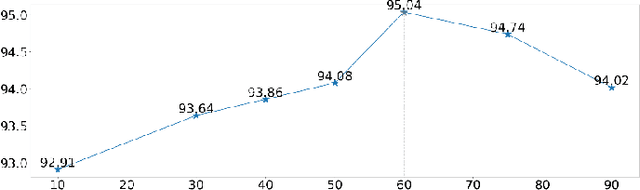

Self-supervised learning (SSL) has drawn increasing attention in pathological image analysis in recent years. However, the prevalent contrastive SSL is suboptimal in feature representation under this scenario due to the homogeneous visual appearance. Alternatively, masked autoencoders (MAE) build SSL from a generative paradigm. They are more friendly to pathological image modeling. In this paper, we firstly introduce MAE to pathological image analysis. A novel SD-MAE model is proposed to enable a self-distillation augmented SSL on top of the raw MAE. Besides the reconstruction loss on masked image patches, SD-MAE further imposes the self-distillation loss on visible patches. It guides the encoder to perceive high-level semantics that benefit downstream tasks. We apply SD-MAE to the image classification task on two pathological and one natural image datasets. Experiments demonstrate that SD-MAE performs highly competitive when compared with leading contrastive SSL methods. The results, which are pre-trained using a moderate size of pathological images, are also comparable to the method pre-trained with two orders of magnitude more images. Our code will be released soon.
A Multi-Modality Ovarian Tumor Ultrasound Image Dataset for Unsupervised Cross-Domain Semantic Segmentation
Jul 14, 2022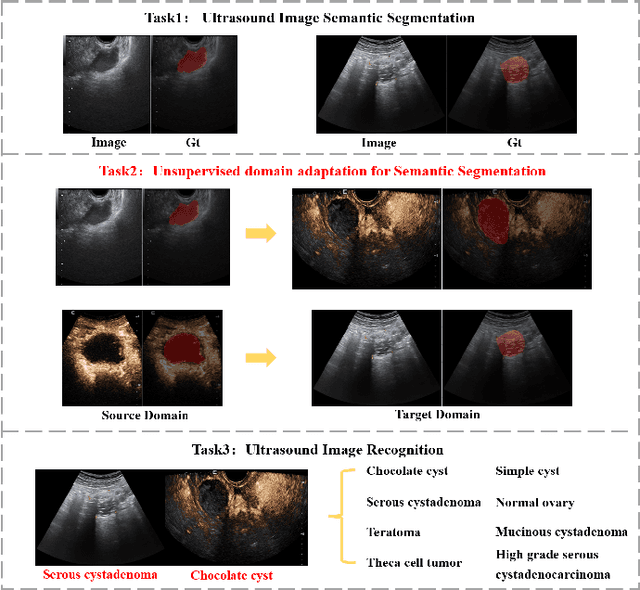
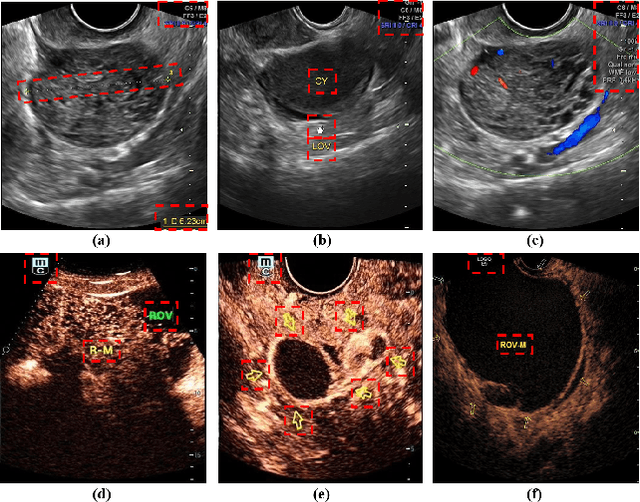
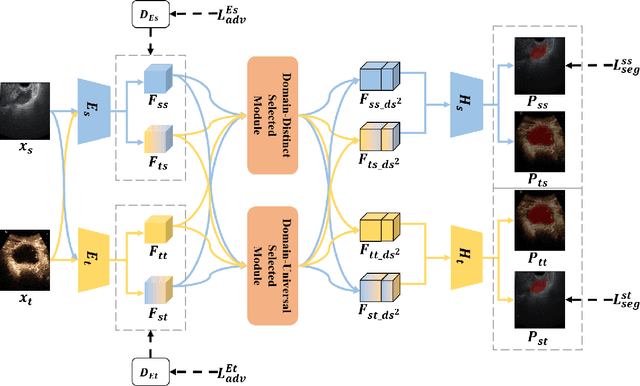
Ovarian cancer is one of the most harmful gynecological diseases. Detecting ovarian tumors in early stage with computer-aided techniques can efficiently decrease the mortality rate. With the improvement of medical treatment standard, ultrasound images are widely applied in clinical treatment. However, recent notable methods mainly focus on single-modality ultrasound ovarian tumor segmentation or recognition, which means there still lacks of researches on exploring the representation capability of multi-modality ultrasound ovarian tumor images. To solve this problem, we propose a Multi-Modality Ovarian Tumor Ultrasound (MMOTU) image dataset containing 1469 2d ultrasound images and 170 contrast enhanced ultrasonography (CEUS) images with pixel-wise and global-wise annotations. Based on MMOTU, we mainly focus on unsupervised cross-domain semantic segmentation task. To solve the domain shift problem, we propose a feature alignment based architecture named Dual-Scheme Domain-Selected Network (DS$^2$Net). Specifically, we first design source-encoder and target-encoder to extract two-style features of source and target images. Then, we propose Domain-Distinct Selected Module (DDSM) and Domain-Universal Selected Module (DUSM) to extract the distinct and universal features in two styles (source-style or target-style). Finally, we fuse these two kinds of features and feed them into the source-decoder and target-decoder to generate final predictions. Extensive comparison experiments and analysis on MMOTU image dataset show that DS$^2$Net can boost the segmentation performance for bidirectional cross-domain adaptation of 2d ultrasound images and CEUS images.
Insurgency as Complex Network: Image Co-Appearance and Hierarchy in the PKK
Jul 14, 2022
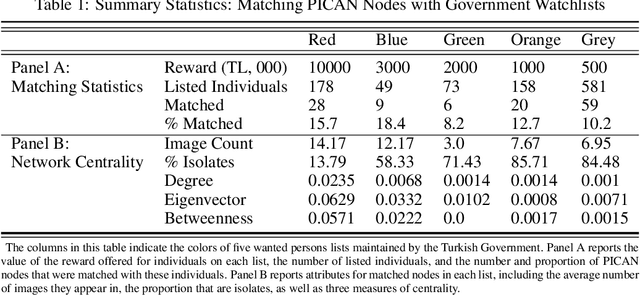
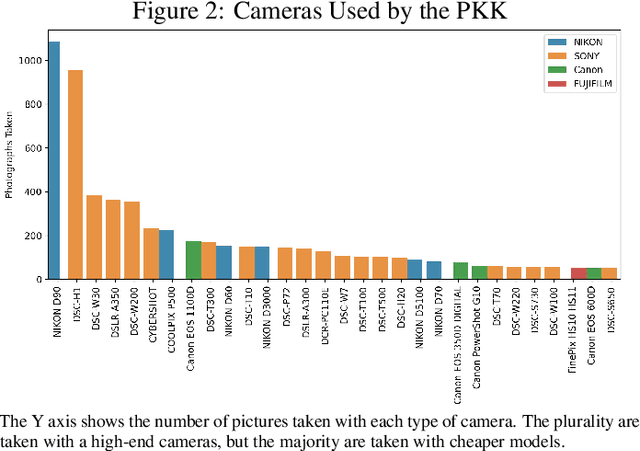
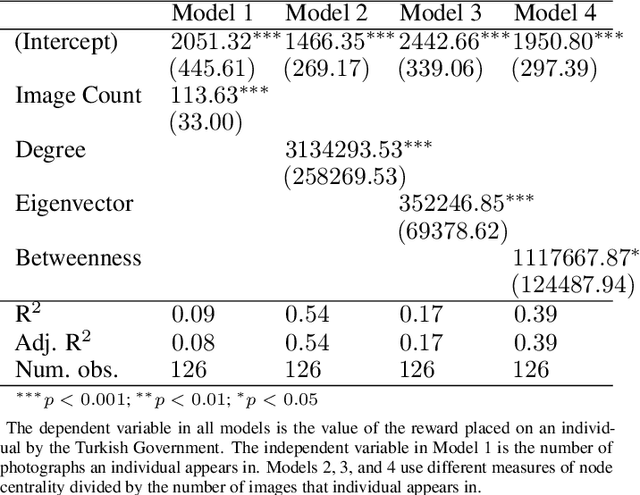
Despite a growing recognition of the importance of insurgent group structure on conflict outcomes, there is very little empirical research thereon. Though this problem is rooted in the inaccessibility of data on militant group structure, insurgents frequently publish large volumes of image data on the internet. In this paper, I develop a new methodology that leverages this abundant but underutilized source of data by automating the creation of a social network graph based on co-appearance in photographs using deep learning. Using a trove of 19,115 obituary images published online by the PKK, a Kurdish militant group in Turkey, I demonstrate that an individual's centrality in the resulting co-appearance network is closely correlated with their rank in the insurgent group.
Graph Neural Networks Extract High-Resolution Cultivated Land Maps from Sentinel-2 Image Series
Aug 03, 2022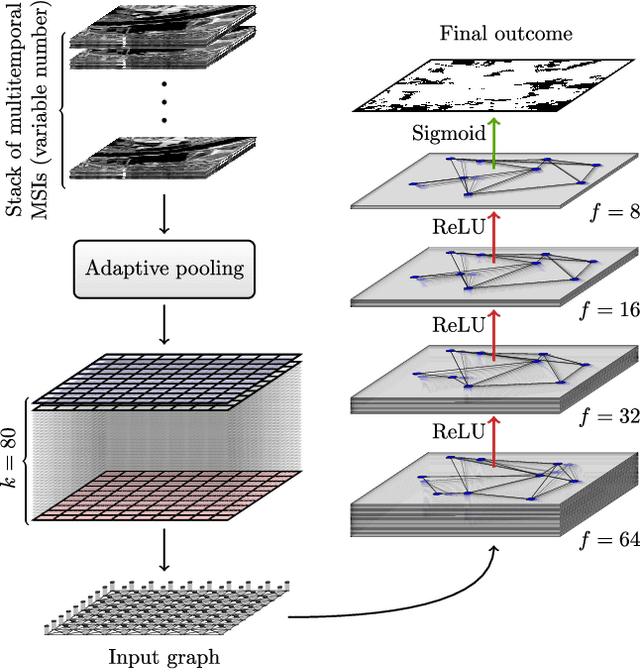

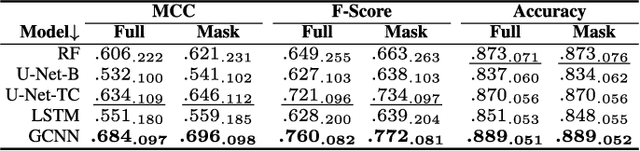
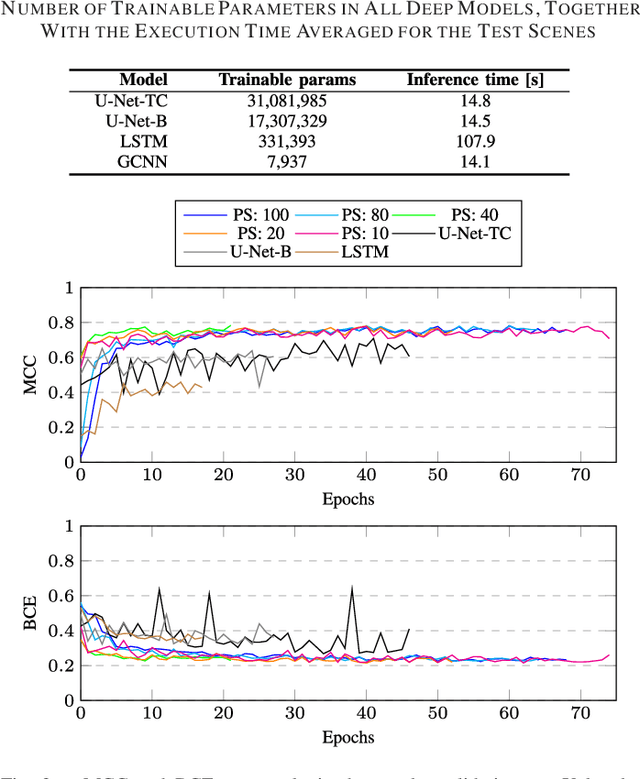
Maintaining farm sustainability through optimizing the agricultural management practices helps build more planet-friendly environment. The emerging satellite missions can acquire multi- and hyperspectral imagery which captures more detailed spectral information concerning the scanned area, hence allows us to benefit from subtle spectral features during the analysis process in agricultural applications. We introduce an approach for extracting 2.5 m cultivated land maps from 10 m Sentinel-2 multispectral image series which benefits from a compact graph convolutional neural network. The experiments indicate that our models not only outperform classical and deep machine learning techniques through delivering higher-quality segmentation maps, but also dramatically reduce the memory footprint when compared to U-Nets (almost 8k trainable parameters of our models, with up to 31M parameters of U-Nets). Such memory frugality is pivotal in the missions which allow us to uplink a model to the AI-powered satellite once it is in orbit, as sending large nets is impossible due to the time constraints.
* 7 pages (including supplementary material), published in IEEE Geoscience and Remote Sensing Letters
Visual Question Answering From Another Perspective: CLEVR Mental Rotation Tests
Dec 03, 2022
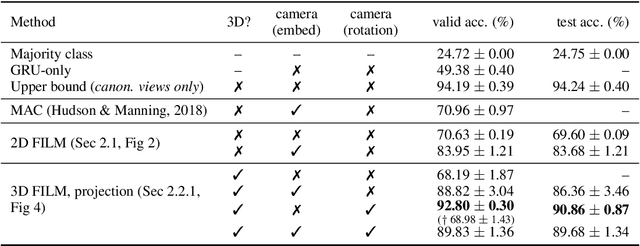
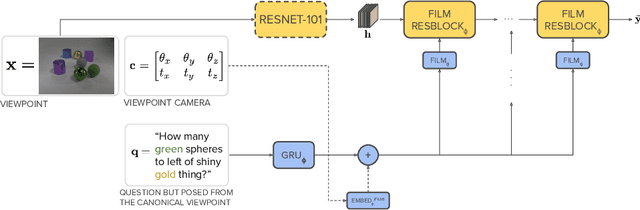
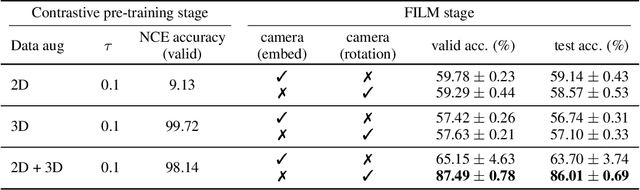
Different types of mental rotation tests have been used extensively in psychology to understand human visual reasoning and perception. Understanding what an object or visual scene would look like from another viewpoint is a challenging problem that is made even harder if it must be performed from a single image. We explore a controlled setting whereby questions are posed about the properties of a scene if that scene was observed from another viewpoint. To do this we have created a new version of the CLEVR dataset that we call CLEVR Mental Rotation Tests (CLEVR-MRT). Using CLEVR-MRT we examine standard methods, show how they fall short, then explore novel neural architectures that involve inferring volumetric representations of a scene. These volumes can be manipulated via camera-conditioned transformations to answer the question. We examine the efficacy of different model variants through rigorous ablations and demonstrate the efficacy of volumetric representations.
Visually Grounded VQA by Lattice-based Retrieval
Nov 15, 2022
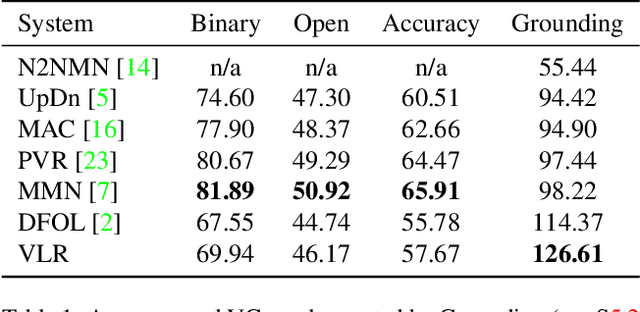

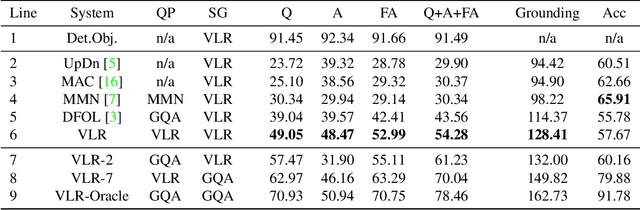
Visual Grounding (VG) in Visual Question Answering (VQA) systems describes how well a system manages to tie a question and its answer to relevant image regions. Systems with strong VG are considered intuitively interpretable and suggest an improved scene understanding. While VQA accuracy performances have seen impressive gains over the past few years, explicit improvements to VG performance and evaluation thereof have often taken a back seat on the road to overall accuracy improvements. A cause of this originates in the predominant choice of learning paradigm for VQA systems, which consists of training a discriminative classifier over a predetermined set of answer options. In this work, we break with the dominant VQA modeling paradigm of classification and investigate VQA from the standpoint of an information retrieval task. As such, the developed system directly ties VG into its core search procedure. Our system operates over a weighted, directed, acyclic graph, a.k.a. "lattice", which is derived from the scene graph of a given image in conjunction with region-referring expressions extracted from the question. We give a detailed analysis of our approach and discuss its distinctive properties and limitations. Our approach achieves the strongest VG performance among examined systems and exhibits exceptional generalization capabilities in a number of scenarios.
Predicting Eye Gaze Location on Websites
Nov 15, 2022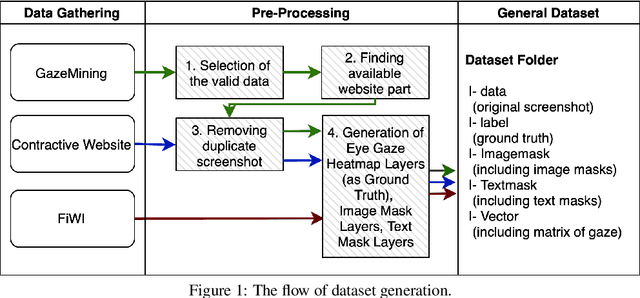
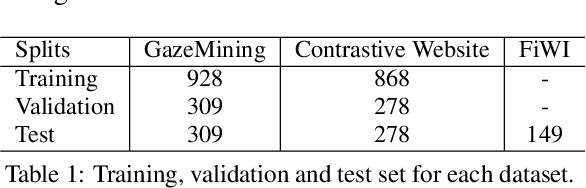
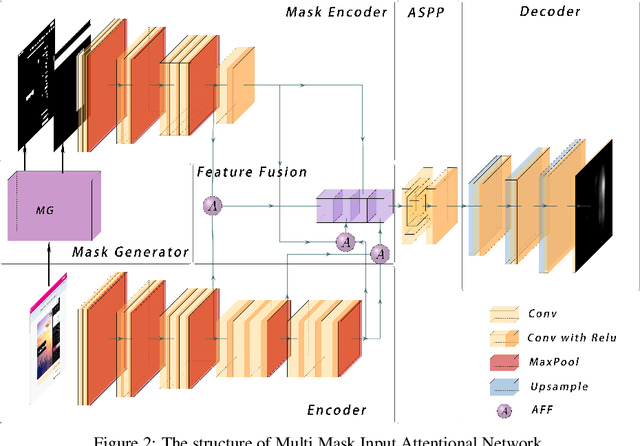
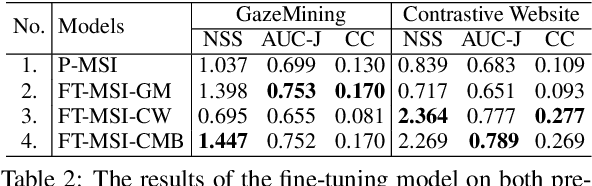
World-wide-web, with the website and webpage as the main interface, facilitates the dissemination of important information. Hence it is crucial to optimize them for better user interaction, which is primarily done by analyzing users' behavior, especially users' eye-gaze locations. However, gathering these data is still considered to be labor and time intensive. In this work, we enable the development of automatic eye-gaze estimations given a website screenshots as the input. This is done by the curation of a unified dataset that consists of website screenshots, eye-gaze heatmap and website's layout information in the form of image and text masks. Our pre-processed dataset allows us to propose an effective deep learning-based model that leverages both image and text spatial location, which is combined through attention mechanism for effective eye-gaze prediction. In our experiment, we show the benefit of careful fine-tuning using our unified dataset to improve the accuracy of eye-gaze predictions. We further observe the capability of our model to focus on the targeted areas (images and text) to achieve high accuracy. Finally, the comparison with other alternatives shows the state-of-the-art result of our model establishing the benchmark for the eye-gaze prediction task.